 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Rethinking materials simulations: Blending direct numerical simulations with neural operators
Dec 08, 2023
Direct numerical simulations (DNS) are accurate but computationally expensive for predicting materials evolution across timescales, due to the complexity of the underlying evolution equations, the nature of multiscale spatio-temporal interactions, and the need to reach long-time integration. We develop a new method that blends numerical solvers with neural operators to accelerate such simulations. This methodology is based on the integration of a community numerical solver with a U-Net neural operator, enhanced by a temporal-conditioning mechanism that enables accurate extrapolation and efficient time-to-solution predictions of the dynamics. We demonstrate the effectiveness of this framework on simulations of microstructure evolution during physical vapor deposition modeled via the phase-field method. Such simulations exhibit high spatial gradients due to the co-evolution of different material phases with simultaneous slow and fast materials dynamics. We establish accurate extrapolation of the coupled solver with up to 16.5$\times$ speed-up compared to DNS. This methodology is generalizable to a broad range of evolutionary models, from solid mechanics, to fluid dynamics, geophysics, climate, and more.
Adapting Vision Transformer for Efficient Change Detection
Dec 08, 2023Most change detection models based on vision transformers currently follow a "pretraining then fine-tuning" strategy. This involves initializing the model weights using large scale classification datasets, which can be either natural images or remote sensing images. However, fully tuning such a model requires significant time and resources. In this paper, we propose an efficient tuning approach that involves freezing the parameters of the pretrained image encoder and introducing additional training parameters. Through this approach, we have achieved competitive or even better results while maintaining extremely low resource consumption across six change detection benchmarks. For example, training time on LEVIR-CD, a change detection benchmark, is only half an hour with 9 GB memory usage, which could be very convenient for most researchers. Additionally, the decoupled tuning framework can be extended to any pretrained model for semantic change detection and multi temporal change detection as well. We hope that our proposed approach will serve as a part of foundational model to inspire more unified training approaches on change detection in the future.
Scientific Preparation for CSST: Classification of Galaxy and Nebula/Star Cluster Based on Deep Learning
Dec 08, 2023The Chinese Space Station Telescope (abbreviated as CSST) is a future advanced space telescope. Real-time identification of galaxy and nebula/star cluster (abbreviated as NSC) images is of great value during CSST survey. While recent research on celestial object recognition has progressed, the rapid and efficient identification of high-resolution local celestial images remains challenging. In this study, we conducted galaxy and NSC image classification research using deep learning methods based on data from the Hubble Space Telescope. We built a Local Celestial Image Dataset and designed a deep learning model named HR-CelestialNet for classifying images of the galaxy and NSC. HR-CelestialNet achieved an accuracy of 89.09% on the testing set, outperforming models such as AlexNet, VGGNet and ResNet, while demonstrating faster recognition speeds. Furthermore, we investigated the factors influencing CSST image quality and evaluated the generalization ability of HR-CelestialNet on the blurry image dataset, demonstrating its robustness to low image quality. The proposed method can enable real-time identification of celestial images during CSST survey mission.
Maximising Quantum-Computing Expressive Power through Randomised Circuits
Dec 04, 2023In the noisy intermediate-scale quantum era, variational quantum algorithms (VQAs) have emerged as a promising avenue to obtain quantum advantage. However, the success of VQAs depends on the expressive power of parameterised quantum circuits, which is constrained by the limited gate number and the presence of barren plateaus. In this work, we propose and numerically demonstrate a novel approach for VQAs, utilizing randomised quantum circuits to generate the variational wavefunction. We parameterize the distribution function of these random circuits using artificial neural networks and optimize it to find the solution. This random-circuit approach presents a trade-off between the expressive power of the variational wavefunction and time cost, in terms of the sampling cost of quantum circuits. Given a fixed gate number, we can systematically increase the expressive power by extending the quantum-computing time. With a sufficiently large permissible time cost, the variational wavefunction can approximate any quantum state with arbitrary accuracy. Furthermore, we establish explicit relationships between expressive power, time cost, and gate number for variational quantum eigensolvers. These results highlight the promising potential of the random-circuit approach in achieving a high expressive power in quantum computing.
Near-Optimal Algorithms for Gaussians with Huber Contamination: Mean Estimation and Linear Regression
Dec 04, 2023We study the fundamental problems of Gaussian mean estimation and linear regression with Gaussian covariates in the presence of Huber contamination. Our main contribution is the design of the first sample near-optimal and almost linear-time algorithms with optimal error guarantees for both of these problems. Specifically, for Gaussian robust mean estimation on $\mathbb{R}^d$ with contamination parameter $\epsilon \in (0, \epsilon_0)$ for a small absolute constant $\epsilon_0$, we give an algorithm with sample complexity $n = \tilde{O}(d/\epsilon^2)$ and almost linear runtime that approximates the target mean within $\ell_2$-error $O(\epsilon)$. This improves on prior work that achieved this error guarantee with polynomially suboptimal sample and time complexity. For robust linear regression, we give the first algorithm with sample complexity $n = \tilde{O}(d/\epsilon^2)$ and almost linear runtime that approximates the target regressor within $\ell_2$-error $O(\epsilon)$. This is the first polynomial sample and time algorithm achieving the optimal error guarantee, answering an open question in the literature. At the technical level, we develop a methodology that yields almost-linear time algorithms for multi-directional filtering that may be of broader interest.
Satellite Imagery and AI: A New Era in Ocean Conservation, from Research to Deployment and Impact
Dec 06, 2023Illegal, unreported, and unregulated (IUU) fishing poses a global threat to ocean habitats. Publicly available satellite data offered by NASA and the European Space Agency (ESA) provide an opportunity to actively monitor this activity. Effectively leveraging satellite data for maritime conservation requires highly reliable machine learning models operating globally with minimal latency. This paper introduces three specialized computer vision models designed for synthetic aperture radar (Sentinel-1), optical imagery (Sentinel-2), and nighttime lights (Suomi-NPP/NOAA-20). It also presents best practices for developing and delivering real-time computer vision services for conservation. These models have been deployed in Skylight, a real time maritime monitoring platform, which is provided at no cost to users worldwide.
Layer-wise Auto-Weighting for Non-Stationary Test-Time Adaptation
Nov 10, 2023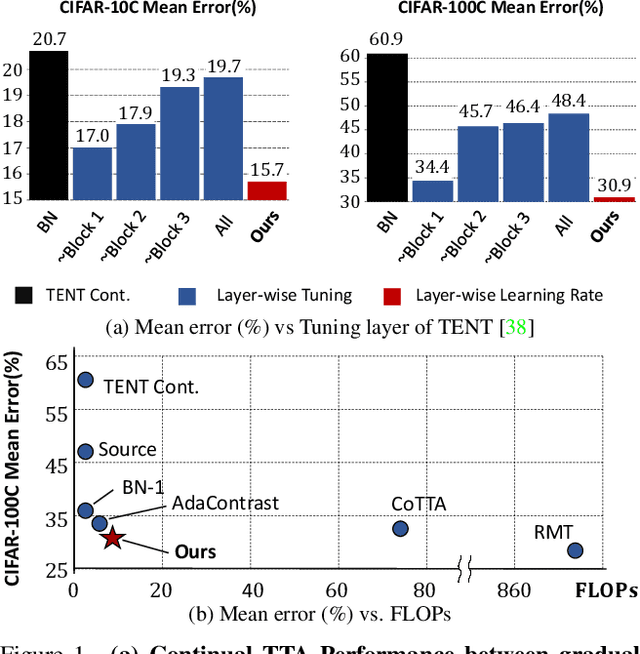

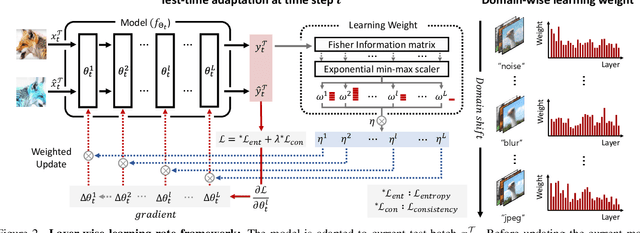
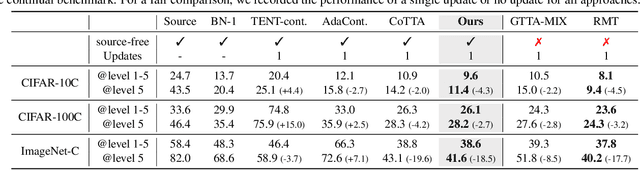
Given the inevitability of domain shifts during inference in real-world applications, test-time adaptation (TTA) is essential for model adaptation after deployment. However, the real-world scenario of continuously changing target distributions presents challenges including catastrophic forgetting and error accumulation. Existing TTA methods for non-stationary domain shifts, while effective, incur excessive computational load, making them impractical for on-device settings. In this paper, we introduce a layer-wise auto-weighting algorithm for continual and gradual TTA that autonomously identifies layers for preservation or concentrated adaptation. By leveraging the Fisher Information Matrix (FIM), we first design the learning weight to selectively focus on layers associated with log-likelihood changes while preserving unrelated ones. Then, we further propose an exponential min-max scaler to make certain layers nearly frozen while mitigating outliers. This minimizes forgetting and error accumulation, leading to efficient adaptation to non-stationary target distribution. Experiments on CIFAR-10C, CIFAR-100C, and ImageNet-C show our method outperforms conventional continual and gradual TTA approaches while significantly reducing computational load, highlighting the importance of FIM-based learning weight in adapting to continuously or gradually shifting target domains.
Predicting the Position Uncertainty at the Time of Closest Approach with Diffusion Models
Nov 15, 2023The risk of collision between resident space objects has significantly increased in recent years. As a result, spacecraft collision avoidance procedures have become an essential part of satellite operations. To ensure safe and effective space activities, satellite owners and operators rely on constantly updated estimates of encounters. These estimates include the uncertainty associated with the position of each object at the expected TCA. These estimates are crucial in planning risk mitigation measures, such as collision avoidance manoeuvres. As the TCA approaches, the accuracy of these estimates improves, as both objects' orbit determination and propagation procedures are made for increasingly shorter time intervals. However, this improvement comes at the cost of taking place close to the critical decision moment. This means that safe avoidance manoeuvres might not be possible or could incur significant costs. Therefore, knowing the evolution of this variable in advance can be crucial for operators. This work proposes a machine learning model based on diffusion models to forecast the position uncertainty of objects involved in a close encounter, particularly for the secondary object (usually debris), which tends to be more unpredictable. We compare the performance of our model with other state-of-the-art solutions and a na\"ive baseline approach, showing that the proposed solution has the potential to significantly improve the safety and effectiveness of spacecraft operations.
Accelerating Neural Network Training: A Brief Review
Dec 15, 2023The process of training a deep neural network is characterized by significant time requirements and associated costs. Although researchers have made considerable progress in this area, further work is still required due to resource constraints. This study examines innovative approaches to expedite the training process of deep neural networks (DNN), with specific emphasis on three state-of-the-art models such as ResNet50, Vision Transformer (ViT), and EfficientNet. The research utilizes sophisticated methodologies, including Gradient Accumulation (GA), Automatic Mixed Precision (AMP), and Pin Memory (PM), in order to optimize performance and accelerate the training procedure. The study examines the effects of these methodologies on the DNN models discussed earlier, assessing their efficacy with regard to training rate and computational efficacy. The study showcases the efficacy of including GA as a strategic approach, resulting in a noteworthy decrease in the duration required for training. This enables the models to converge at a faster pace. The utilization of AMP enhances the speed of computations by taking advantage of the advantages offered by lower precision arithmetic while maintaining the correctness of the model. Furthermore, this study investigates the application of Pin Memory as a strategy to enhance the efficiency of data transmission between the central processing unit and the graphics processing unit, thereby offering a promising opportunity for enhancing overall performance. The experimental findings demonstrate that the combination of these sophisticated methodologies significantly accelerates the training of DNNs, offering vital insights for experts seeking to improve the effectiveness of deep learning processes.
Deep Reinforcement Learning for Joint Cruise Control and Intelligent Data Acquisition in UAVs-Assisted Sensor Networks
Dec 15, 2023Unmanned aerial vehicle (UAV)-assisted sensor networks (UASNets), which play a crucial role in creating new opportunities, are experiencing significant growth in civil applications worldwide. UASNets improve disaster management through timely surveillance and advance precision agriculture with detailed crop monitoring, thereby significantly transforming the commercial economy. UASNets revolutionize the commercial sector by offering greater efficiency, safety, and cost-effectiveness, highlighting their transformative impact. A fundamental aspect of these new capabilities and changes is the collection of data from rugged and remote areas. Due to their excellent mobility and maneuverability, UAVs are employed to collect data from ground sensors in harsh environments, such as natural disaster monitoring, border surveillance, and emergency response monitoring. One major challenge in these scenarios is that the movements of UAVs affect channel conditions and result in packet loss. Fast movements of UAVs lead to poor channel conditions and rapid signal degradation, resulting in packet loss. On the other hand, slow mobility of a UAV can cause buffer overflows of the ground sensors, as newly arrived data is not promptly collected by the UAV. Our proposal to address this challenge is to minimize packet loss by jointly optimizing the velocity controls and data collection schedules of multiple UAVs.Furthermore, in UASNets, swift movements of UAVs result in poor channel conditions and fast signal attenuation, leading to an extended age of information (AoI). In contrast, slow movements of UAVs prolong flight time, thereby extending the AoI of ground sensors.To address this challenge, we propose a new mean-field flight resource allocation optimization to minimize the AoI of sensory data.