 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Early detection of the advanced persistent threat attack using performance analysis of deep learning
Sep 19, 2020
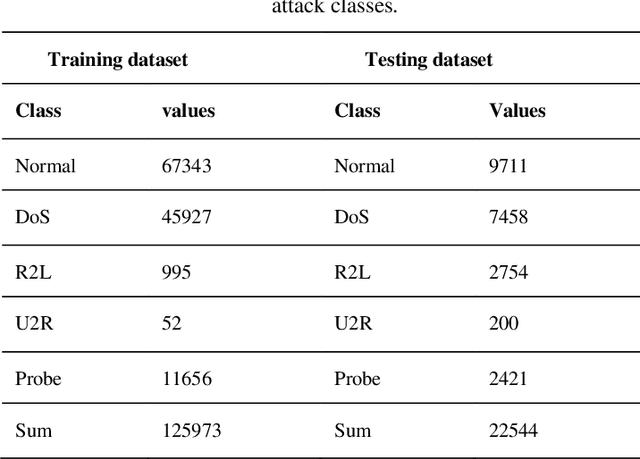
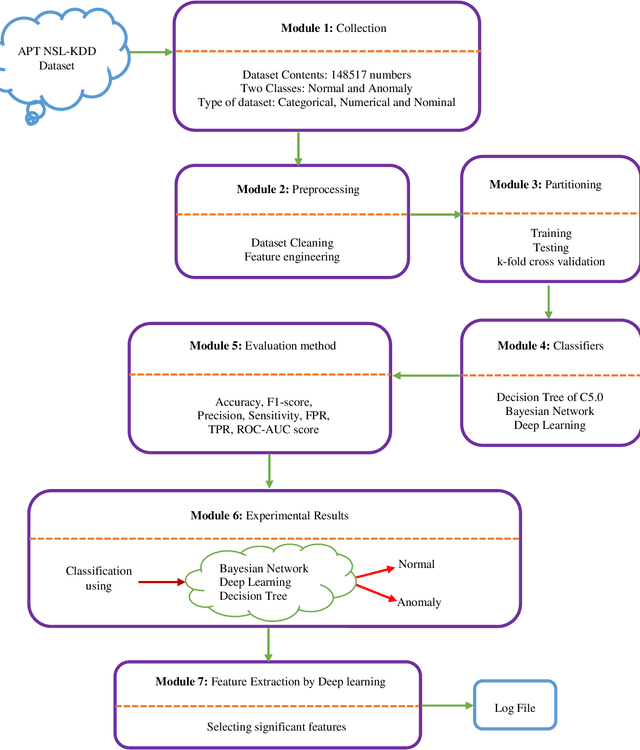
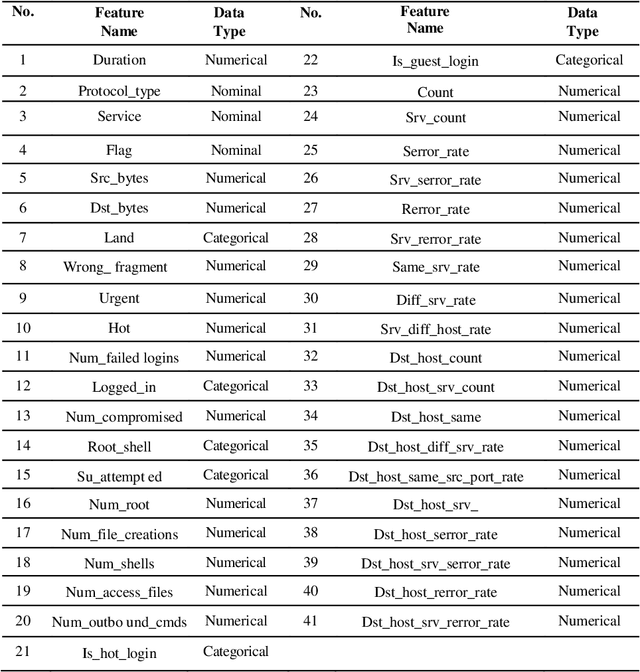
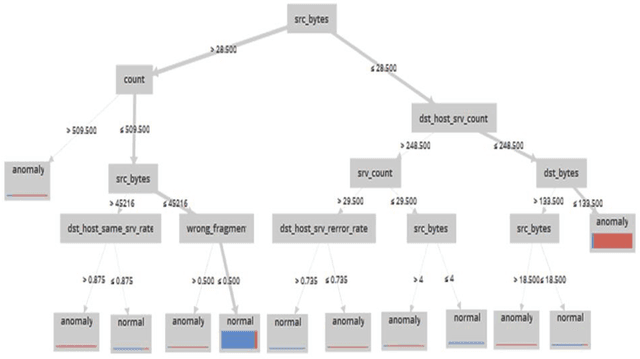
One of the most common and important destructive attacks on the victim system is Advanced Persistent Threat (APT)-attack. The APT attacker can achieve his hostile goals by obtaining information and gaining financial benefits regarding the infrastructure of a network. One of the solutions to detect a secret APT attack is using network traffic. Due to the nature of the APT attack in terms of being on the network for a long time and the fact that the network may crash because of high traffic, it is difficult to detect this type of attack. Hence, in this study, machine learning methods such as C5.0 decision tree, Bayesian network and deep neural network are used for timely detection and classification of APT-attacks on the NSL-KDD dataset. Moreover, 10-fold cross validation method is used to experiment these models. As a result, the accuracy (ACC) of the C5.0 decision tree, Bayesian network and 6-layer deep learning models is obtained as 95.64%, 88.37% and 98.85%, respectively, and also, in terms of the important criterion of the false positive rate (FPR), the FPR value for the C5.0 decision tree, Bayesian network and 6-layer deep learning models is obtained as 2.56, 10.47 and 1.13, respectively. Other criterions such as sensitivity, specificity, accuracy, false negative rate and F-measure are also investigated for the models, and the experimental results show that the deep learning model with automatic multi-layered extraction of features has the best performance for timely detection of an APT-attack comparing to other classification models.
SalsaNext: Fast Semantic Segmentation of LiDAR Point Clouds for Autonomous Driving
Mar 07, 2020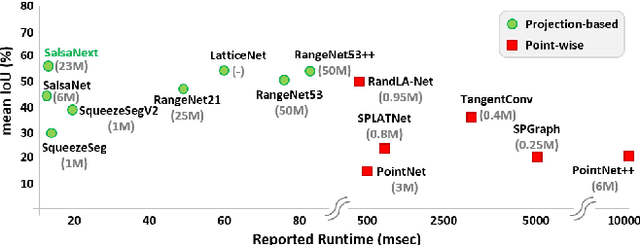
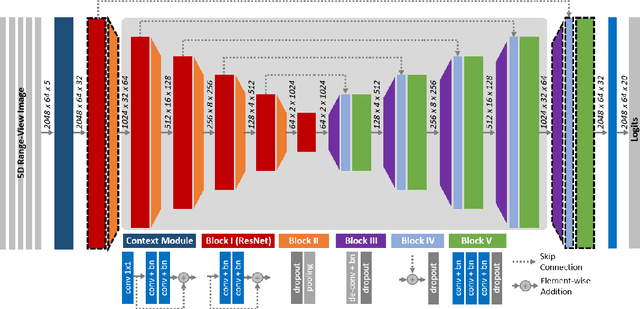

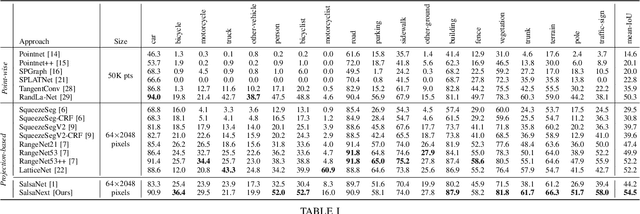
In this paper, we introduce SalsaNext for the semantic segmentation of a full 3D LiDAR point cloud in real-time. SalsaNext is the next version of SalsaNet [1] which has an encoder-decoder architecture where the encoder unit has a set of ResNet blocks and the decoder part combines upsampled features from the residual blocks. In contrast to SalsaNet, we have an additional layer in the encoder and decoder, introduce the context module, switch from stride convolution to average pooling and also apply central dropout treatment. To directly optimize the Jaccard index, we further combine the weighted cross-entropy loss with Lovasz-Softmax loss [2]. We provide a thorough quantitative evaluation on the Semantic-KITTI dataset [3], which demonstrates that the proposed SalsaNext outperforms other state-of-the-art semantic segmentation networks in terms of accuracy and computation time. We also release our source code https://github.com/TiagoCortinhal/SalsaNext.
Self-Loop Uncertainty: A Novel Pseudo-Label for Semi-Supervised Medical Image Segmentation
Jul 20, 2020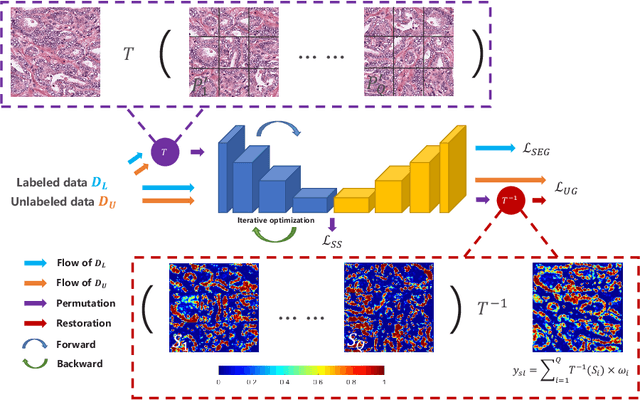

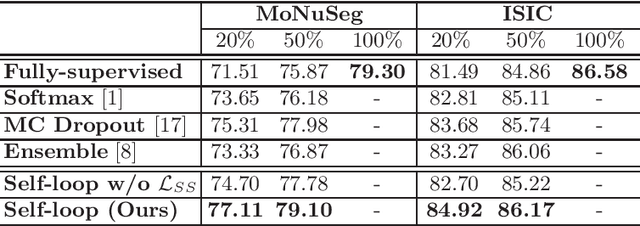
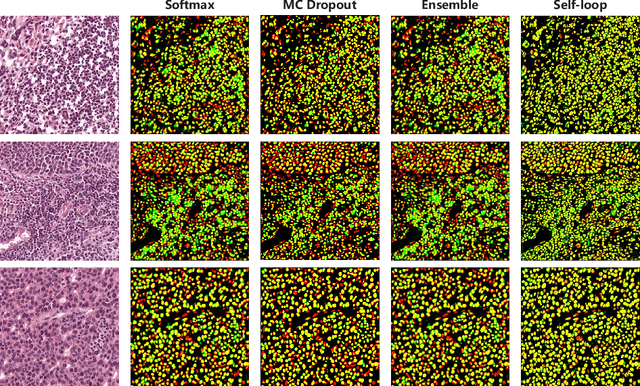
Witnessing the success of deep learning neural networks in natural image processing, an increasing number of studies have been proposed to develop deep-learning-based frameworks for medical image segmentation. However, since the pixel-wise annotation of medical images is laborious and expensive, the amount of annotated data is usually deficient to well-train a neural network. In this paper, we propose a semi-supervised approach to train neural networks with limited labeled data and a large quantity of unlabeled images for medical image segmentation. A novel pseudo-label (namely self-loop uncertainty), generated by recurrently optimizing the neural network with a self-supervised task, is adopted as the ground-truth for the unlabeled images to augment the training set and boost the segmentation accuracy. The proposed self-loop uncertainty can be seen as an approximation of the uncertainty estimation yielded by ensembling multiple models with a significant reduction of inference time. Experimental results on two publicly available datasets demonstrate the effectiveness of our semi-supervied approach.
Combining Reinforcement Learning and Constraint Programming for Combinatorial Optimization
Jun 02, 2020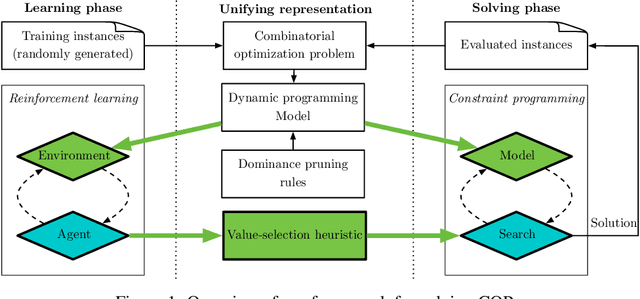
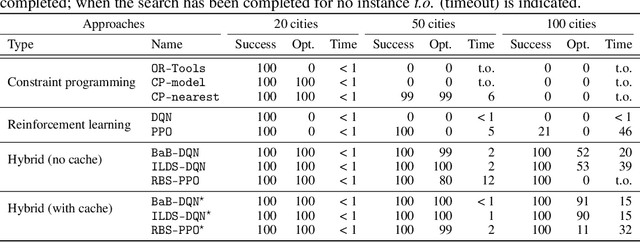
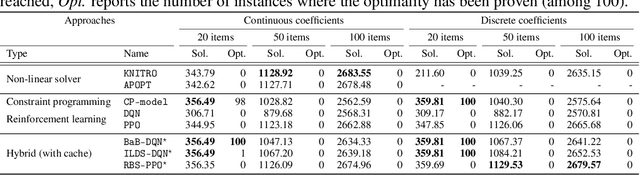
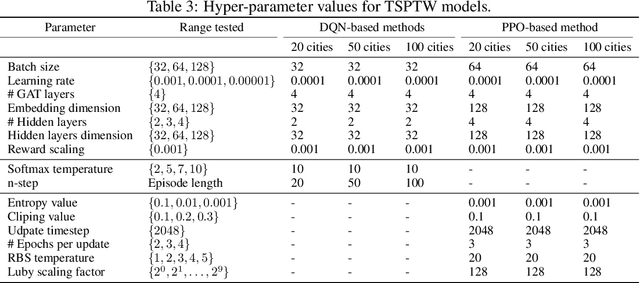
Combinatorial optimization has found applications in numerous fields, from aerospace to transportation planning and economics. The goal is to find an optimal solution among a finite set of possibilities. The well-known challenge one faces with combinatorial optimization is the state-space explosion problem: the number of possibilities grows exponentially with the problem size, which makes solving intractable for large problems. In the last years, deep reinforcement learning (DRL) has shown its promise for designing good heuristics dedicated to solve NP-hard combinatorial optimization problems. However, current approaches have two shortcomings: (1) they mainly focus on the standard travelling salesman problem and they cannot be easily extended to other problems, and (2) they only provide an approximate solution with no systematic ways to improve it or to prove optimality. In another context, constraint programming (CP) is a generic tool to solve combinatorial optimization problems. Based on a complete search procedure, it will always find the optimal solution if we allow an execution time large enough. A critical design choice, that makes CP non-trivial to use in practice, is the branching decision, directing how the search space is explored. In this work, we propose a general and hybrid approach, based on DRL and CP, for solving combinatorial optimization problems. The core of our approach is based on a dynamic programming formulation, that acts as a bridge between both techniques. We experimentally show that our solver is efficient to solve two challenging problems: the traveling salesman problem with time windows, and the 4-moments portfolio optimization problem. Results obtained show that the framework introduced outperforms the stand-alone RL and CP solutions, while being competitive with industrial solvers.
CatGCN: Graph Convolutional Networks with Categorical Node Features
Sep 11, 2020
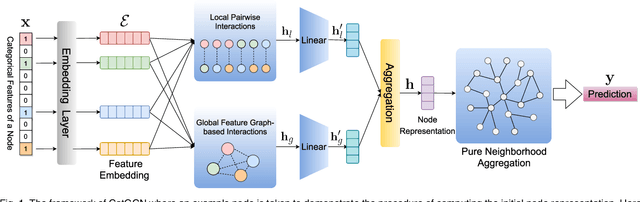
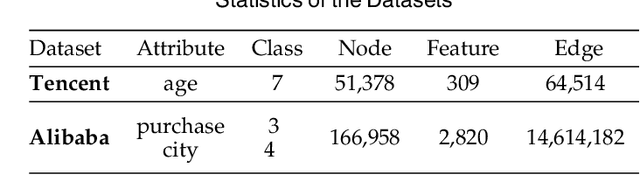
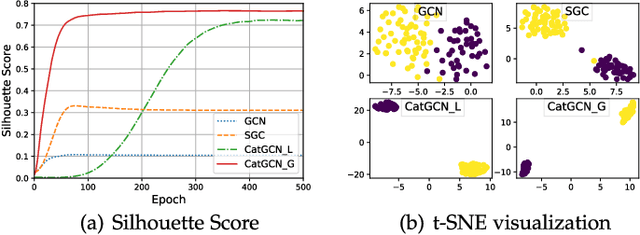
Recent studies on Graph Convolutional Networks (GCNs) reveal that the initial node representations (i.e., the node representations before the first-time graph convolution) largely affect the final model performance. However, when learning the initial representation for a node, most existing work linearly combines the embeddings of node features, without considering the interactions among the features (or feature embeddings). We argue that when the node features are categorical, e.g., in many real-world applications like user profiling and recommender system, feature interactions usually carry important signals for predictive analytics. Ignoring them will result in suboptimal initial node representation and thus weaken the effectiveness of the follow-up graph convolution. In this paper, we propose a new GCN model named CatGCN, which is tailored for graph learning when the node features are categorical. Specifically, we integrate two ways of explicit interaction modeling into the learning of initial node representation, i.e., local interaction modeling on each pair of node features and global interaction modeling on an artificial feature graph. We then refine the enhanced initial node representations with the neighborhood aggregation-based graph convolution. We train CatGCN in an end-to-end fashion and demonstrate it on semi-supervised node classification. Extensive experiments on three tasks of user profiling (the prediction of user age, city, and purchase level) from Tencent and Alibaba datasets validate the effectiveness of CatGCN, especially the positive effect of performing feature interaction modeling before graph convolution.
Visual Localization for Autonomous Driving: Mapping the Accurate Location in the City Maze
Aug 13, 2020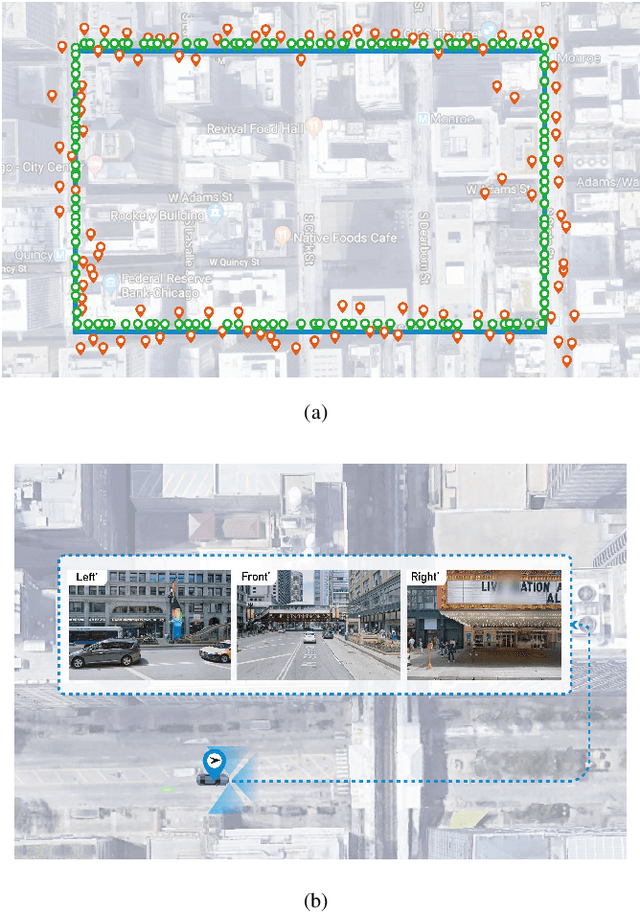
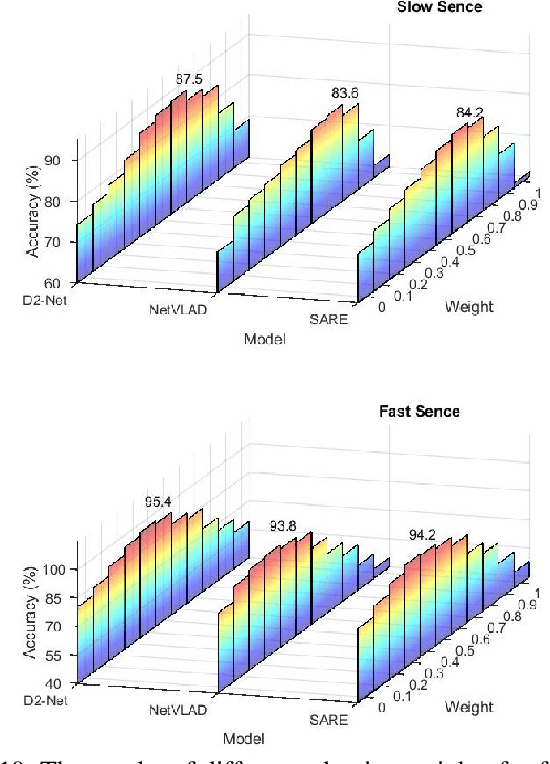
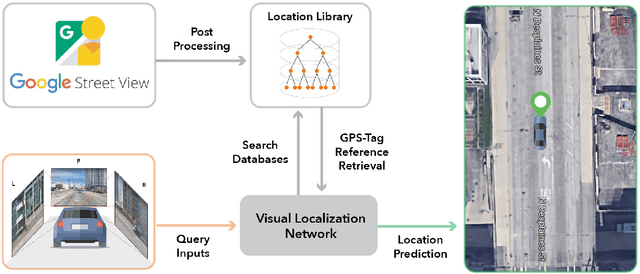
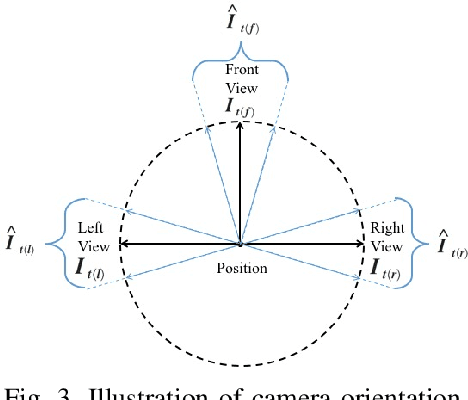
Accurate localization is a foundational capacity, required for autonomous vehicles to accomplish other tasks such as navigation or path planning. It is a common practice for vehicles to use GPS to acquire location information. However, the application of GPS can result in severe challenges when vehicles run within the inner city where different kinds of structures may shadow the GPS signal and lead to inaccurate location results. To address the localization challenges of urban settings, we propose a novel feature voting technique for visual localization. Different from the conventional front-view-based method, our approach employs views from three directions (front, left, and right) and thus significantly improves the robustness of location prediction. In our work, we craft the proposed feature voting method into three state-of-the-art visual localization networks and modify their architectures properly so that they can be applied for vehicular operation. Extensive field test results indicate that our approach can predict location robustly even in challenging inner-city settings. Our research sheds light on using the visual localization approach to help autonomous vehicles to find accurate location information in a city maze, within a desirable time constraint.
Estudo comparativo de meta-heurísticas para problemas de colorações de grafos
Dec 18, 2019A classic graph coloring problem is to assign colors to vertices of any graph so that distinct colors are assigned to adjacent vertices. Optimal graph coloring colors a graph with a minimum number of colors, which is its chromatic number. Finding out the chromatic number is a combinatorial optimization problem proven to be computationally intractable, which implies that no algorithm that computes large instances of the problem in a reasonable time is known. For this reason, approximate methods and metaheuristics form a set of techniques that do not guarantee optimality but obtain good solutions in a reasonable time. This paper reports a comparative study of the Hill-Climbing, Simulated Annealing, Tabu Search, and Iterated Local Search metaheuristics for the classic graph coloring problem considering its time efficiency for processing the DSJC125 and DSJC250 instances of the DIMACS benchmark.
End-to-end Learning for OFDM: From Neural Receivers to Pilotless Communication
Sep 11, 2020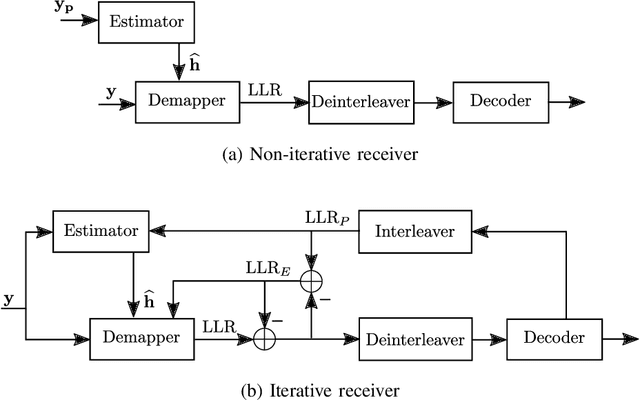
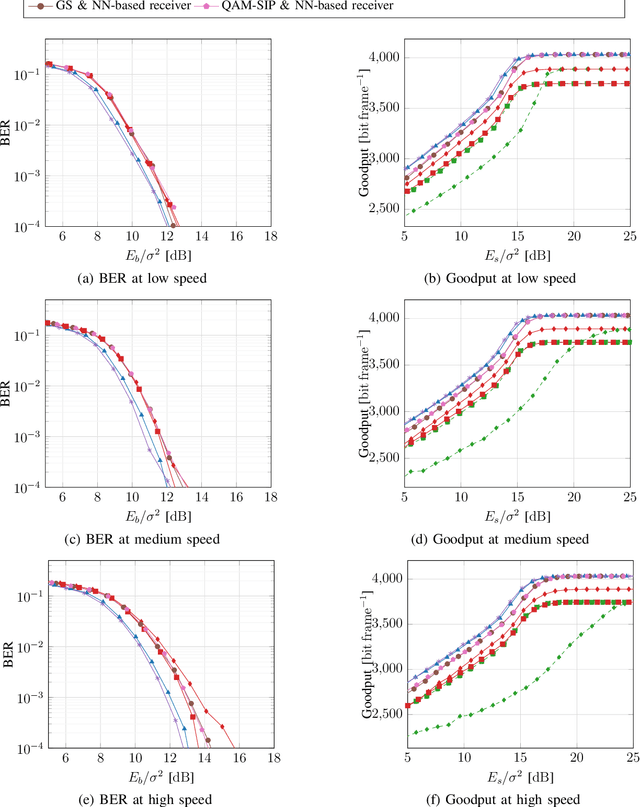
Previous studies have demonstrated that end-to-end learning enables significant shaping gains over additive white Gaussian noise (AWGN) channels. However, its benefits have not yet been quantified over realistic wireless channel models. This work aims to fill this gap by exploring the gains of end-to-end learning over a frequency- and time-selective fading channel using orthogonal frequency division multiplexing (OFDM). With imperfect channel knowledge at the receiver, the shaping gains observed on AWGN channels vanish. Nonetheless, we identify two other sources of performance improvements. The first comes from a neural network (NN)-based receiver operating over a large number of subcarriers and OFDM symbols which allows to significantly reduce the number of orthogonal pilots without loss of bit error rate (BER). The second comes from entirely eliminating orthognal pilots by jointly learning a neural receiver together with either superimposed pilots (SIPs), linearly combined with conventional quadrature amplitude modulation (QAM), or an optimized constellation geometry. The learned geometry works for a wide range of signal-to-noise ratios (SNRs), Doppler and delay spreads, has zero mean and does hence not contain any form of superimposed pilots. Both schemes achieve the same BER as the pilot-based baseline with around 7% higher throughput. Thus, we believe that a jointly learned transmitter and receiver are a very interesting component for beyond-5G communication systems which could remove the need and associated control overhead for demodulation reference signals (DMRSs).
Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching
Dec 18, 2019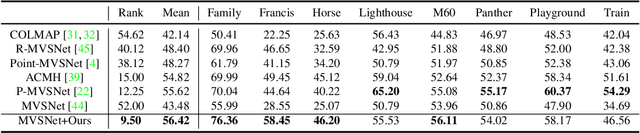
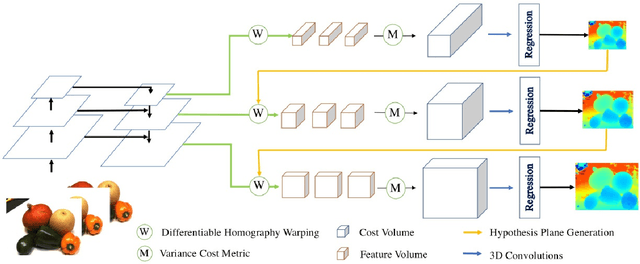
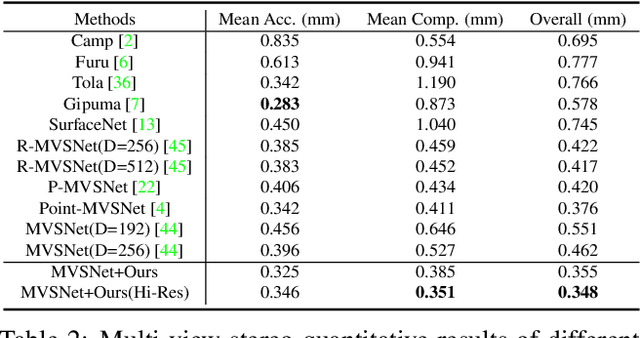
The deep multi-view stereo (MVS) and stereo matching approaches generally construct 3D cost volumes to regularize and regress the output depth or disparity. These methods are limited when high-resolution outputs are needed since the memory and time costs grow cubically as the volume resolution increases. In this paper, we propose a both memory and time efficient cost volume formulation that is complementary to existing multi-view stereo and stereo matching approaches based on 3D cost volumes. First, the proposed cost volume is built upon a standard feature pyramid encoding geometry and context at gradually finer scales. Then, we can narrow the depth (or disparity) range of each stage by the depth (or disparity) map from the previous stage. With gradually higher cost volume resolution and adaptive adjustment of depth (or disparity) intervals, the output is recovered in a coarser to fine manner. We apply the cascade cost volume to the representative MVS-Net, and obtain a 23.1% improvement on DTU benchmark (1st place), with 50.6% and 74.2% reduction in GPU memory and run-time. It is also the state-of-the-art learning-based method on Tanks and Temples benchmark. The statistics of accuracy, run-time and GPU memory on other representative stereo CNNs also validate the effectiveness of our proposed method.
Robust and Sample Optimal Algorithms for PSD Low-Rank Approximation
Dec 09, 2019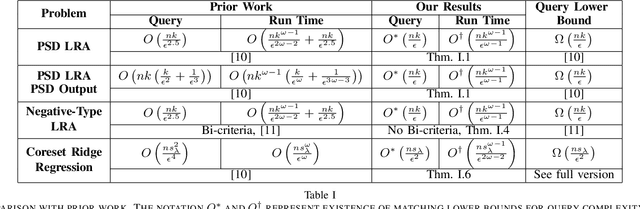
Recently, Musco and Woodruff (FOCS, 2017) showed that given an $n \times n$ positive semidefinite (PSD) matrix $A$, it is possible to compute a relative-error $(1+\epsilon)$-approximate low-rank approximation to $A$ by querying $\widetilde{O}(nk/\epsilon^{2.5})$ entries of $A$ in time $\widetilde{O}(nk/\epsilon^{2.5} +n k^{\omega-1}/\epsilon^{2(\omega-1)})$. They also showed that any relative-error low-rank approximation algorithm must query $\widetilde{\Omega}(nk/\epsilon)$ entries of $A$, and closing this gap is an important open question. Our main result is to resolve this question by showing an algorithm that queries an optimal $\widetilde{O}(nk/\epsilon)$ entries of $A$ and outputs a relative-error low-rank approximation in $\widetilde{O}(n\cdot(k/\epsilon)^{\omega-1})$ time. Note, our running time improves that of Musco and Woodruff, and matches the information-theoretic lower bound if the matrix-multiplication exponent $\omega$ is $2$. Next, we introduce a new robust low-rank approximation model which captures PSD matrices that have been corrupted with noise. We assume that the Frobenius norm of the corruption is bounded. Here, we relax the notion of approximation to additive-error, since it is information-theoretically impossible to obtain a relative-error approximation in this setting. While a sample complexity lower bound precludes sublinear algorithms for arbitrary PSD matices, we provide the first sublinear time and query algorithms when the corruption on the diagonal entries is bounded. As a special case, we show sample-optimal sublinear time algorithms for low-rank approximation of correlation matrices corrupted by noise.