 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Emotional-Blinded Face Representations
Sep 18, 2020

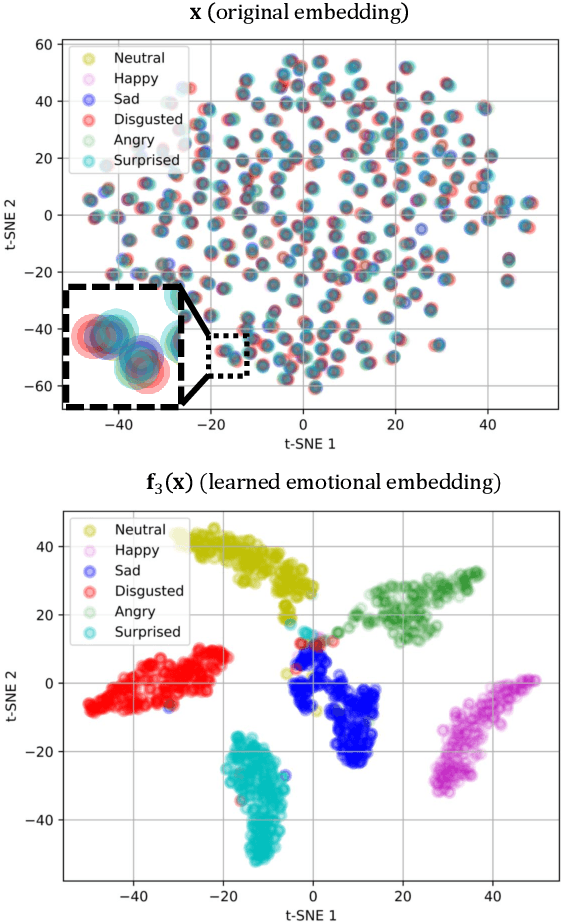
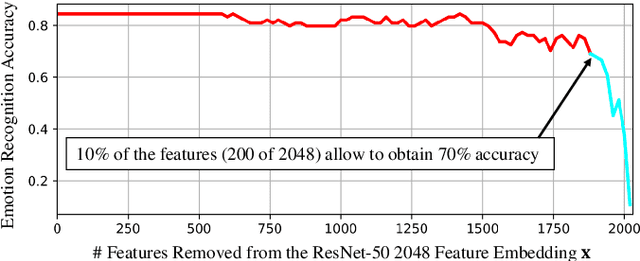
We propose two face representations that are blind to facial expressions associated to emotional responses. This work is in part motivated by new international regulations for personal data protection, which enforce data controllers to protect any kind of sensitive information involved in automatic processes. The advances in Affective Computing have contributed to improve human-machine interfaces but, at the same time, the capacity to monitorize emotional responses triggers potential risks for humans, both in terms of fairness and privacy. We propose two different methods to learn these expression-blinded facial features. We show that it is possible to eliminate information related to emotion recognition tasks, while the performance of subject verification, gender recognition, and ethnicity classification are just slightly affected. We also present an application to train fairer classifiers in a case study of attractiveness classification with respect to a protected facial expression attribute. The results demonstrate that it is possible to reduce emotional information in the face representation while retaining competitive performance in other face-based artificial intelligence tasks.
Optimization for Medical Image Segmentation: Theory and Practice when evaluating with Dice Score or Jaccard Index
Oct 26, 2020
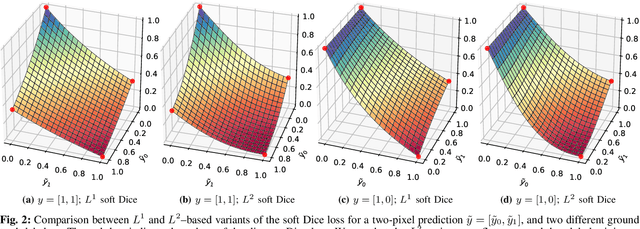
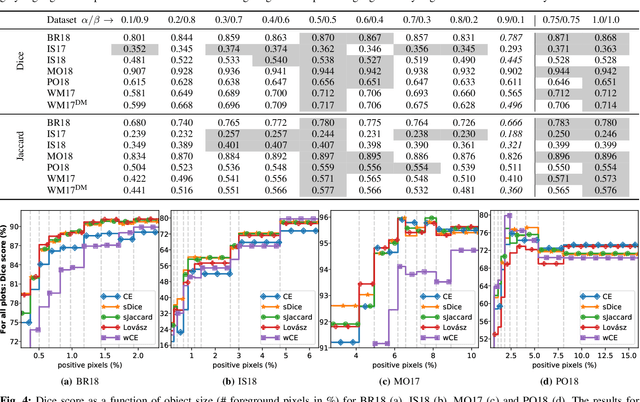
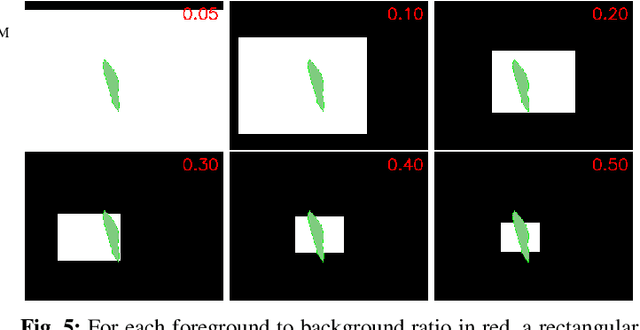
In many medical imaging and classical computer vision tasks, the Dice score and Jaccard index are used to evaluate the segmentation performance. Despite the existence and great empirical success of metric-sensitive losses, i.e. relaxations of these metrics such as soft Dice, soft Jaccard and Lovasz-Softmax, many researchers still use per-pixel losses, such as (weighted) cross-entropy to train CNNs for segmentation. Therefore, the target metric is in many cases not directly optimized. We investigate from a theoretical perspective, the relation within the group of metric-sensitive loss functions and question the existence of an optimal weighting scheme for weighted cross-entropy to optimize the Dice score and Jaccard index at test time. We find that the Dice score and Jaccard index approximate each other relatively and absolutely, but we find no such approximation for a weighted Hamming similarity. For the Tversky loss, the approximation gets monotonically worse when deviating from the trivial weight setting where soft Tversky equals soft Dice. We verify these results empirically in an extensive validation on six medical segmentation tasks and can confirm that metric-sensitive losses are superior to cross-entropy based loss functions in case of evaluation with Dice Score or Jaccard Index. This further holds in a multi-class setting, and across different object sizes and foreground/background ratios. These results encourage a wider adoption of metric-sensitive loss functions for medical segmentation tasks where the performance measure of interest is the Dice score or Jaccard index.
Video-based Facial Expression Recognition using Graph Convolutional Networks
Oct 26, 2020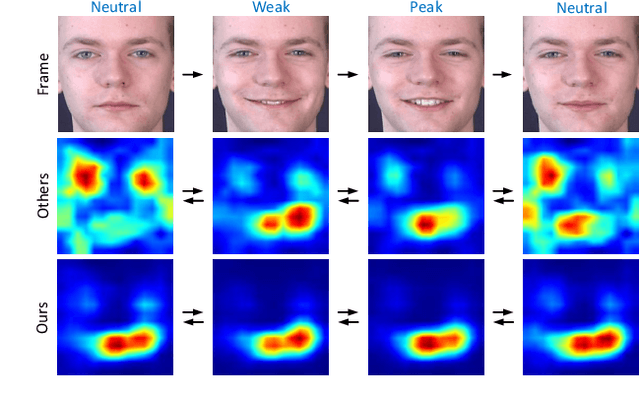
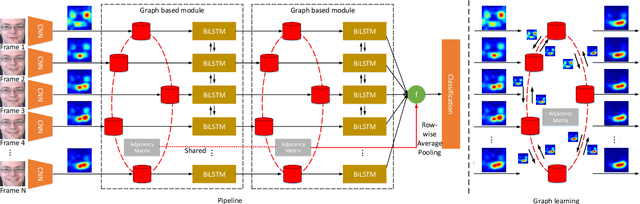

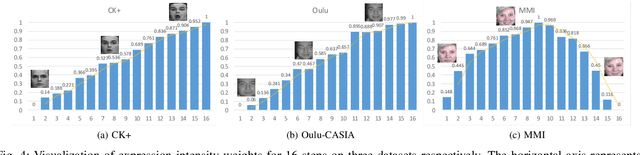
Facial expression recognition (FER), aiming to classify the expression present in the facial image or video, has attracted a lot of research interests in the field of artificial intelligence and multimedia. In terms of video based FER task, it is sensible to capture the dynamic expression variation among the frames to recognize facial expression. However, existing methods directly utilize CNN-RNN or 3D CNN to extract the spatial-temporal features from different facial units, instead of concentrating on a certain region during expression variation capturing, which leads to limited performance in FER. In our paper, we introduce a Graph Convolutional Network (GCN) layer into a common CNN-RNN based model for video-based FER. First, the GCN layer is utilized to learn more significant facial expression features which concentrate on certain regions after sharing information between extracted CNN features of nodes. Then, a LSTM layer is applied to learn long-term dependencies among the GCN learned features to model the variation. In addition, a weight assignment mechanism is also designed to weight the output of different nodes for final classification by characterizing the expression intensities in each frame. To the best of our knowledge, it is the first time to use GCN in FER task. We evaluate our method on three widely-used datasets, CK+, Oulu-CASIA and MMI, and also one challenging wild dataset AFEW8.0, and the experimental results demonstrate that our method has superior performance to existing methods.
Deep Neural Network based Wide-Area Event Classification in Power Systems
Aug 24, 2020
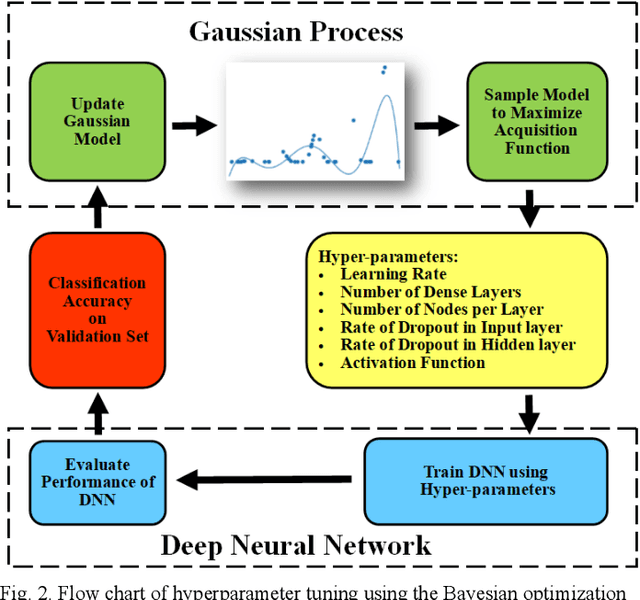
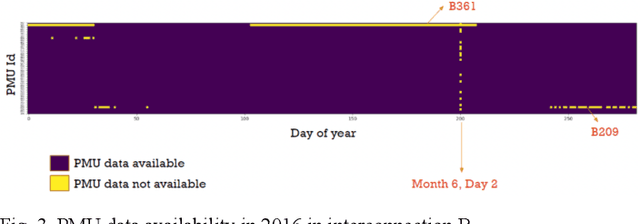
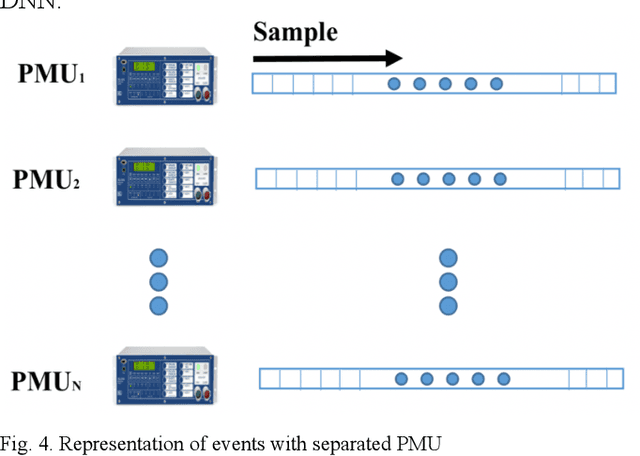
This paper presents a wide-area event classification in transmission power grids. The deep neural network (DNN) based classifier is developed based on the availability of data from time-synchronized phasor measurement units (PMUs). The proposed DNN is trained using Bayesian optimization to search for the best hyperparameters. The effectiveness of the proposed event classification is validated through the real-world dataset of the U.S. transmission grids. This dataset includes line outage, transformer outage, frequency event, and oscillation events. The validation process also includes different PMU outputs, such as voltage magnitude, angle, current magnitude, frequency, and rate of change of frequency (ROCOF). The simulation results show that ROCOF as input feature gives the best classification performance. In addition, it is shown that the classifier trained with higher sampling rate PMUs and a larger dataset has higher accuracy.
Transposer: Universal Texture Synthesis Using Feature Maps as Transposed Convolution Filter
Jul 14, 2020
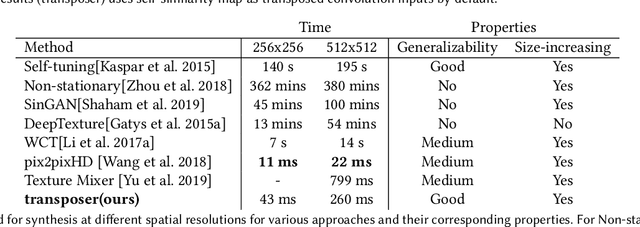

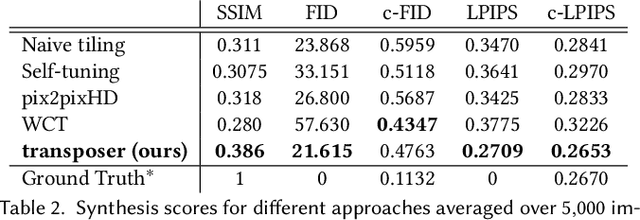
Conventional CNNs for texture synthesis consist of a sequence of (de)-convolution and up/down-sampling layers, where each layer operates locally and lacks the ability to capture the long-term structural dependency required by texture synthesis. Thus, they often simply enlarge the input texture, rather than perform reasonable synthesis. As a compromise, many recent methods sacrifice generalizability by training and testing on the same single (or fixed set of) texture image(s), resulting in huge re-training time costs for unseen images. In this work, based on the discovery that the assembling/stitching operation in traditional texture synthesis is analogous to a transposed convolution operation, we propose a novel way of using transposed convolution operation. Specifically, we directly treat the whole encoded feature map of the input texture as transposed convolution filters and the features' self-similarity map, which captures the auto-correlation information, as input to the transposed convolution. Such a design allows our framework, once trained, to be generalizable to perform synthesis of unseen textures with a single forward pass in nearly real-time. Our method achieves state-of-the-art texture synthesis quality based on various metrics. While self-similarity helps preserve the input textures' regular structural patterns, our framework can also take random noise maps for irregular input textures instead of self-similarity maps as transposed convolution inputs. It allows to get more diverse results as well as generate arbitrarily large texture outputs by directly sampling large noise maps in a single pass as well.
Deep Learning-Based Automatic Detection of Poorly Positioned Mammograms to Minimize Patient Return Visits for Repeat Imaging: A Real-World Application
Sep 28, 2020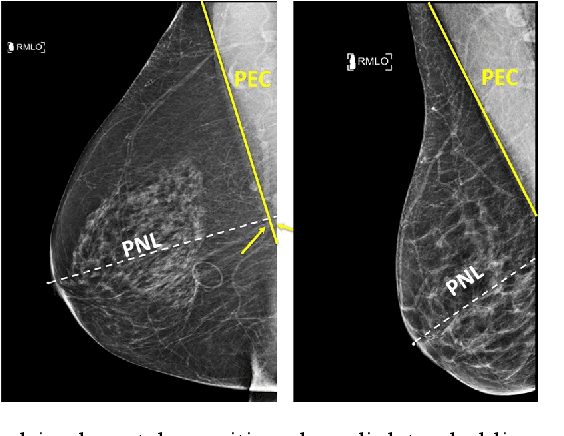
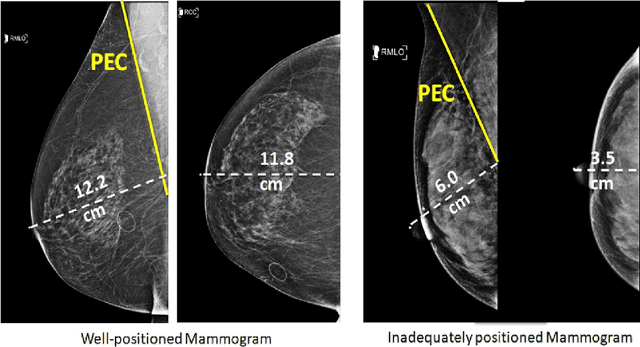
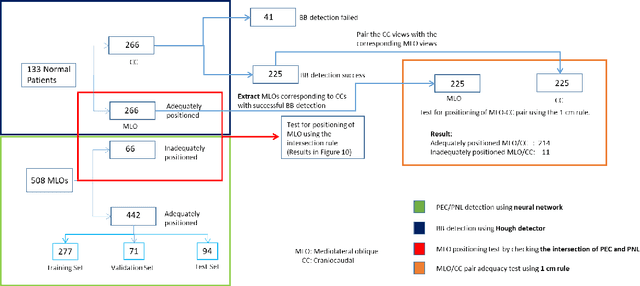

Screening mammograms are a routine imaging exam performed to detect breast cancer in its early stages to reduce morbidity and mortality attributed to this disease. In order to maximize the efficacy of breast cancer screening programs, proper mammographic positioning is paramount. Proper positioning ensures adequate visualization of breast tissue and is necessary for effective breast cancer detection. Therefore, breast-imaging radiologists must assess each mammogram for the adequacy of positioning before providing a final interpretation of the examination; this often necessitates return patient visits for additional imaging. In this paper, we propose a deep learning-algorithm method that mimics and automates this decision-making process to identify poorly positioned mammograms. Our objective for this algorithm is to assist mammography technologists in recognizing inadequately positioned mammograms real-time, improve the quality of mammographic positioning and performance, and ultimately reducing repeat visits for patients with initially inadequate imaging. The proposed model showed a true positive rate for detecting correct positioning of 91.35% in the mediolateral oblique view and 95.11% in the craniocaudal view. In addition to these results, we also present an automatically generated report which can aid the mammography technologist in taking corrective measures during the patient visit.
Psoriasis Severity Assessment with a Similarity-Clustering Machine Learning Approach Reduces Intra- and Inter-observation variation
Sep 28, 2020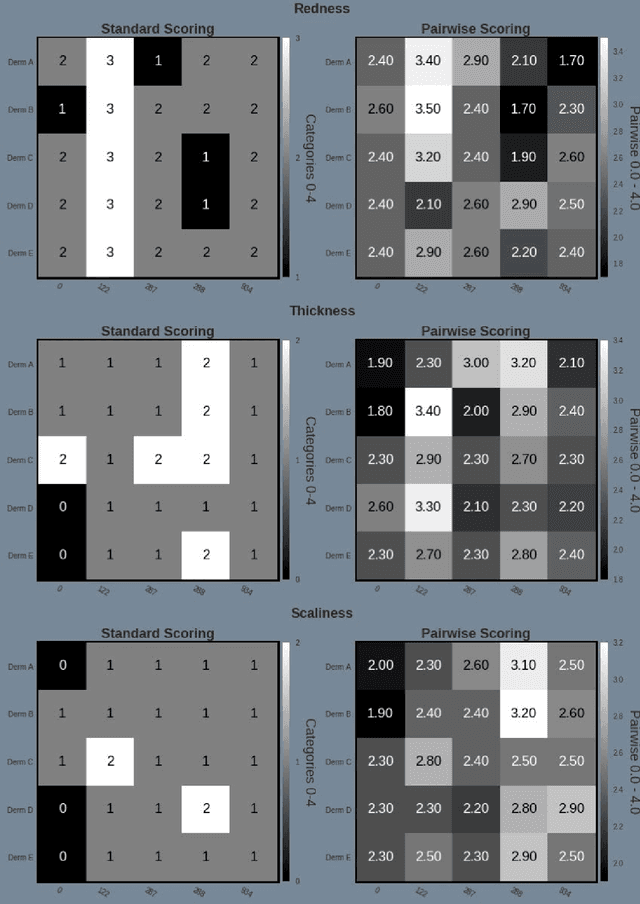
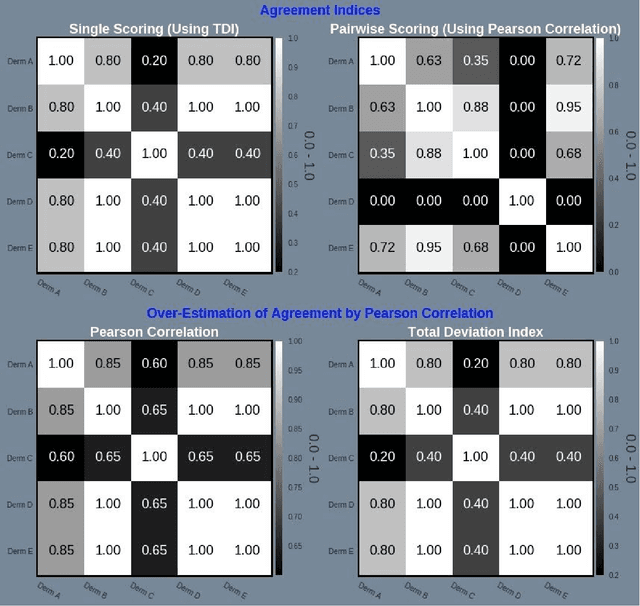
Psoriasis is a complex disease with many variations in genotype and phenotype. General advancements in medicine has further complicated both assessments and treatment for both physicians and dermatologist alike. Even with all of our technological progress we still primarily use the assessment tool Psoriasis Area and Severity Index (PASI) for severity assessments which was developed in the 1970s. In this study we evaluate a method involving digital images, a comparison web application and similarity clustering, developed to improve the assessment tool in terms of intra- and inter-observer variation. Images of patients was collected from a mobile device. Images were captured of the same lesion area taken approximately 1 week apart. Five dermatologists evaluated the severity of psoriasis by modified-PASI, absolute scoring and a relative pairwise PASI scoring using similarity-clustering and conducted using a web-program displaying two images at a time. mPASI scoring of single photos by the same or different dermatologist showed mPASI ratings of 50% to 80%, respectively. Repeated mPASI comparison using similarity clustering showed consistent mPASI ratings > 95%. Pearson correlation between absolute scoring and pairwise scoring progression was 0.72.
Adding Recurrence to Pretrained Transformers for Improved Efficiency and Context Size
Aug 16, 2020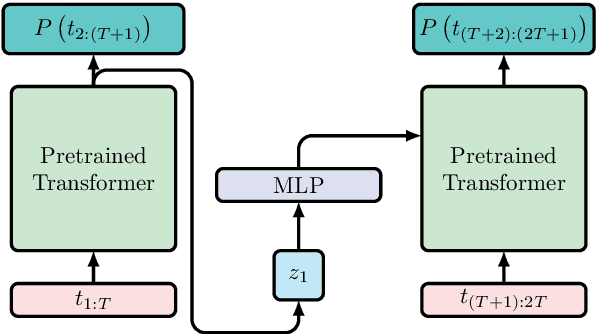
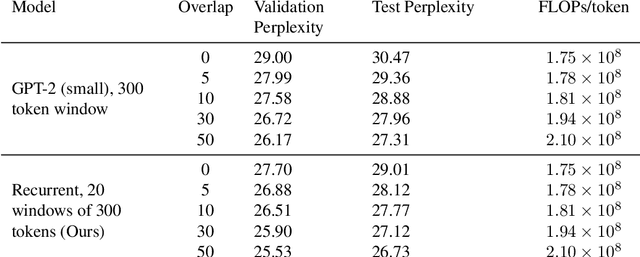
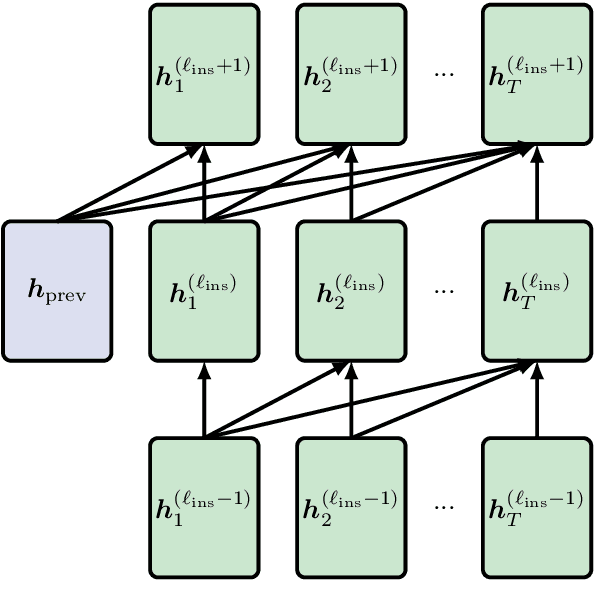
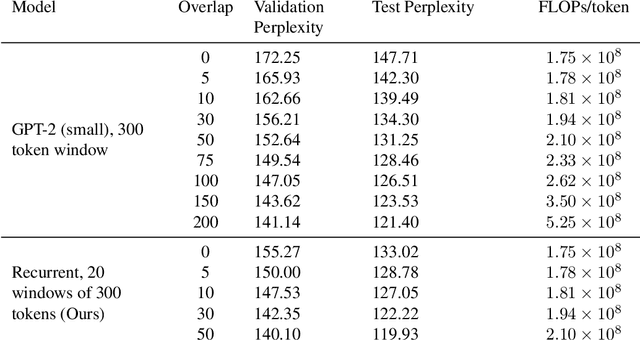
Fine-tuning a pretrained transformer for a downstream task has become a standard method in NLP in the last few years. While the results from these models are impressive, applying them can be extremely computationally expensive, as is pretraining new models with the latest architectures. We present a novel method for applying pretrained transformer language models which lowers their memory requirement both at training and inference time. An additional benefit is that our method removes the fixed context size constraint that most transformer models have, allowing for more flexible use. When applied to the GPT-2 language model, we find that our method attains better perplexity than an unmodified GPT-2 model on the PG-19 and WikiText-103 corpora, for a given amount of computation or memory.
Adaptive Checkpoint Adjoint Method for Gradient Estimation in Neural ODE
Jun 03, 2020
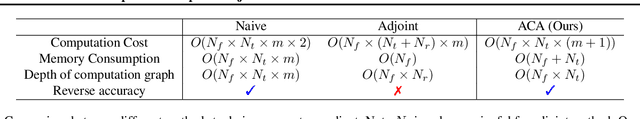
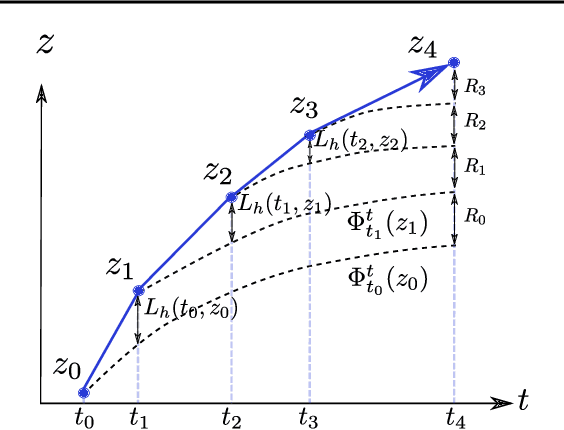

Neural ordinary differential equations (NODEs) have recently attracted increasing attention; however, their empirical performance on benchmark tasks (e.g. image classification) are significantly inferior to discrete-layer models. We demonstrate an explanation for their poorer performance is the inaccuracy of existing gradient estimation methods: the adjoint method has numerical errors in reverse-mode integration; the naive method directly back-propagates through ODE solvers, but suffers from a redundantly deep computation graph when searching for the optimal stepsize. We propose the Adaptive Checkpoint Adjoint (ACA) method: in automatic differentiation, ACA applies a trajectory checkpoint strategy which records the forward-mode trajectory as the reverse-mode trajectory to guarantee accuracy; ACA deletes redundant components for shallow computation graphs; and ACA supports adaptive solvers. On image classification tasks, compared with the adjoint and naive method, ACA achieves half the error rate in half the training time; NODE trained with ACA outperforms ResNet in both accuracy and test-retest reliability. On time-series modeling, ACA outperforms competing methods. Finally, in an example of the three-body problem, we show NODE with ACA can incorporate physical knowledge to achieve better accuracy. We provide the PyTorch implementation of ACA: \url{https://github.com/juntang-zhuang/torch-ACA}.
SeDMiD for Confusion Detection: Uncovering Mind State from Time Series Brain Wave Data
Nov 29, 2016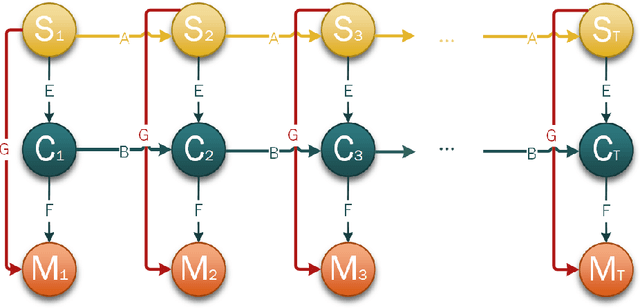

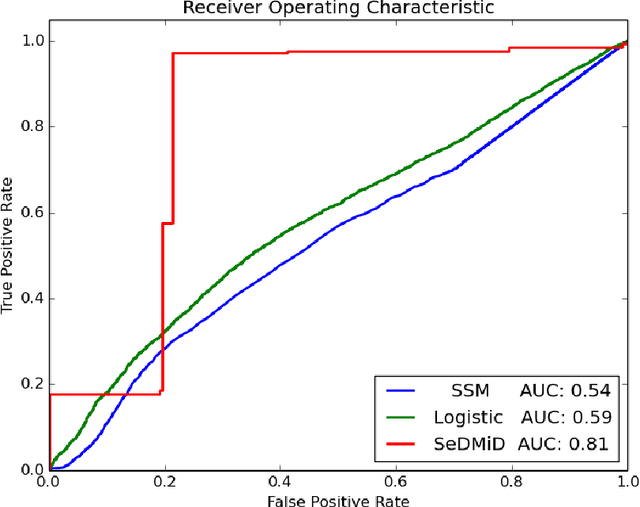
Understanding how brain functions has been an intriguing topic for years. With the recent progress on collecting massive data and developing advanced technology, people have become interested in addressing the challenge of decoding brain wave data into meaningful mind states, with many machine learning models and algorithms being revisited and developed, especially the ones that handle time series data because of the nature of brain waves. However, many of these time series models, like HMM with hidden state in discrete space or State Space Model with hidden state in continuous space, only work with one source of data and cannot handle different sources of information simultaneously. In this paper, we propose an extension of State Space Model to work with different sources of information together with its learning and inference algorithms. We apply this model to decode the mind state of students during lectures based on their brain waves and reach a significant better results compared to traditional methods.