 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamically Feasible Deep Reinforcement Learning Policy for Robot Navigation in Dense Mobile Crowds
Oct 28, 2020

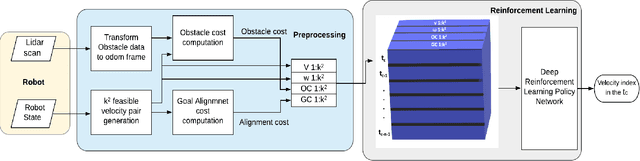
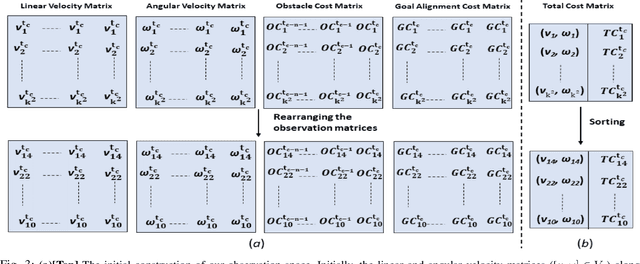
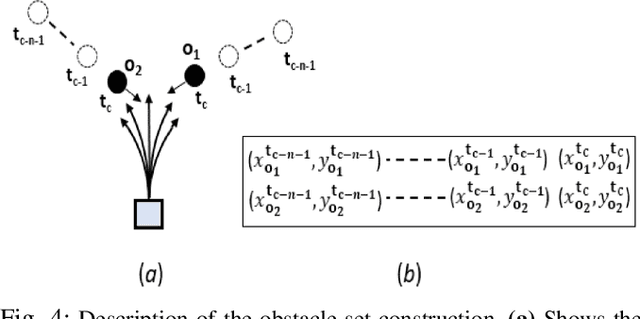
We present a novel Deep Reinforcement Learning (DRL) based policy for mobile robot navigation in dynamic environments that computes dynamically feasible and spatially aware robot velocities. Our method addresses two primary issues associated with the Dynamic Window Approach (DWA) and DRL-based navigation policies and solves them by using the benefits of one method to fix the issues of the other. The issues are: 1. DWA not utilizing the time evolution of the environment while choosing velocities from the dynamically feasible velocity set leading to sub-optimal dynamic collision avoidance behaviors, and 2. DRL-based navigation policies computing velocities that often violate the dynamics constraints such as the non-holonomic and acceleration constraints of the robot. Our DRL-based method generates velocities that are dynamically feasible while accounting for the motion of the obstacles in the environment. This is done by embedding the changes in the environment's state in a novel observation space and a reward function formulation that reinforces spatially aware obstacle avoidance maneuvers. We evaluate our method in realistic 3-D simulation and on a real differential drive robot in challenging indoor scenarios with crowds of varying densities. We make comparisons with traditional and current state-of-the-art collision avoidance methods and observe significant improvements in terms of collision rate, number of dynamics constraint violations and smoothness. We also conduct ablation studies to highlight the advantages and explain the rationale behind our observation space construction, reward structure and network architecture.
Hyperparameter Optimization via Sequential Uniform Designs
Sep 08, 2020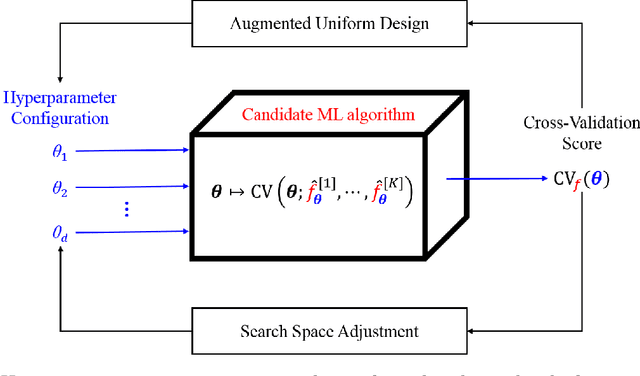
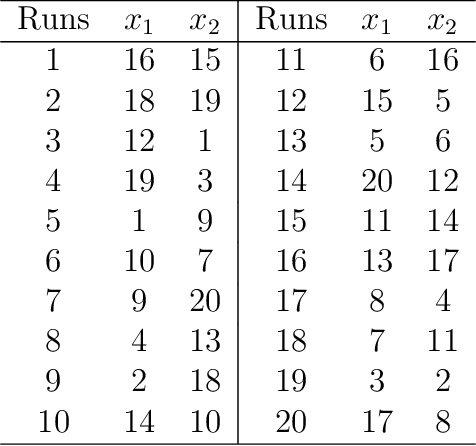
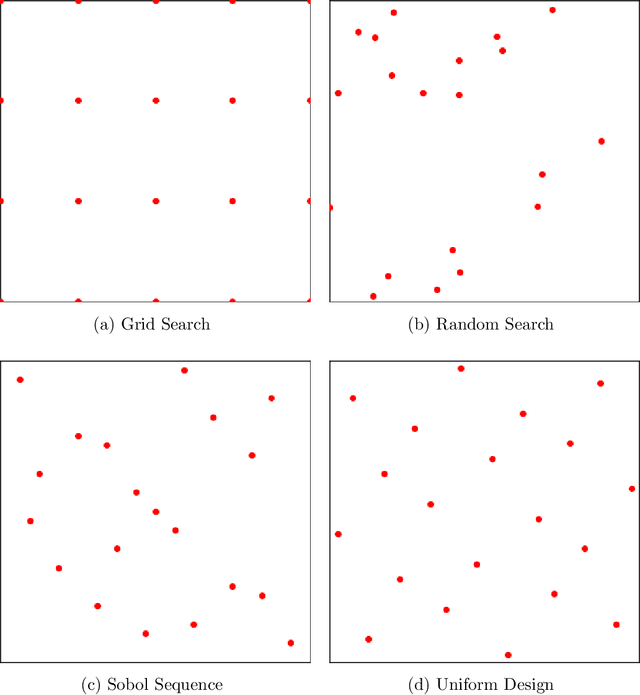
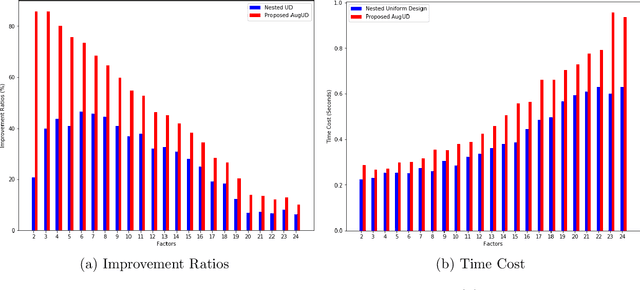
Hyperparameter tuning or optimization plays a central role in the automated machine learning (AutoML) pipeline. It is a challenging task as the response surfaces of hyperparameters are generally unknown, and the evaluation of each experiment is expensive. In this paper, we reformulate hyperparameter optimization as a kind of computer experiment and propose a novel sequential uniform design (SeqUD) for hyperparameter optimization. It is advantageous as a) it adaptively explores the hyperparameter space with evenly spread design points, which is free of the expensive meta-modeling and acquisition optimization procedures in Bayesian optimization; b) sequential design points are generated in batch, which can be easily parallelized; and c) a real-time augmented uniform design (AugUD) algorithm is developed for the efficient generation of new design points. Experiments are conducted on both global optimization tasks and hyperparameter optimization applications. The results show that SeqUD outperforms related hyperparameter optimization methods, which is demonstrated to be a promising and competitive alternative of existing tools.
Climbing down Charney's ladder: Machine Learning and the post-Dennard era of computational climate science
May 24, 2020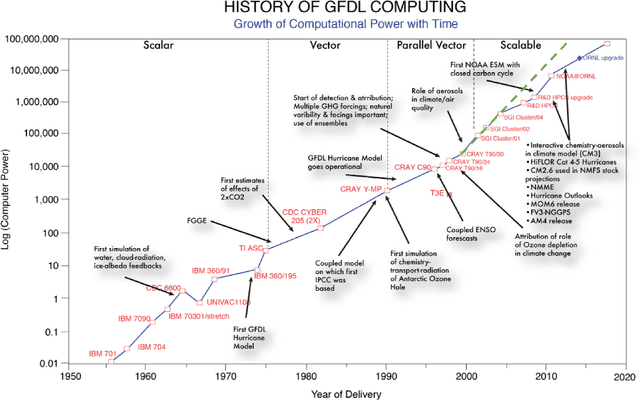
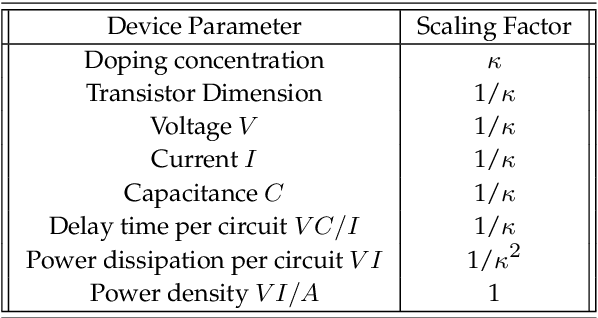

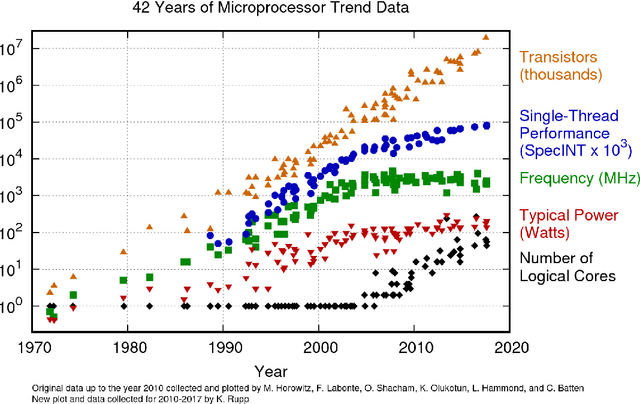
The advent of digital computing in the 1950s sparked a revolution in the science of weather and climate. Meteorology, long practised as an art based on extrapolating patterns in space and time, gave way to computational methods in a decade of advances in numerical weather forecasting. Those same methods also gave rise to computational climate science, studying the behaviour of those same numerical equations over very long time intervals, and changes in external boundary conditions. Several subsequent decades of exponential growth in computational power have brought us to the present day, where models ever grow in resolution and complexity, capable of mastery of many small-scale phenomena with global repercussions, and ever more intricate feedbacks in the Earth system. We have also come to understand the central role played by randomness in an underdetermined physical system. The current juncture in computing, seven decades later, heralds an end to ever smaller computational units and ever faster arithmetic, what is called Dennard scaling. This is prompting a fundamental change in our approach to the simulation of weather and climate, potentially as revolutionary as that wrought by John von Neumann in the 1950s. One approach could return us to an earlier era of pattern recognition and extrapolation, this time aided by computational power. Another approach could lead us to insights that continue to be expressed in mathematical equations. In either approach, or any synthesis of those, it is clearly no longer the steady march of the last few decades, continuing to add detail to ever more elaborate models. In this prospectus, we attempt to show the outlines how this may unfold in the coming decades, a new harnessing of physical knowledge, computation, and data.
Automated Model Compression by Jointly Applied Pruning and Quantization
Nov 12, 2020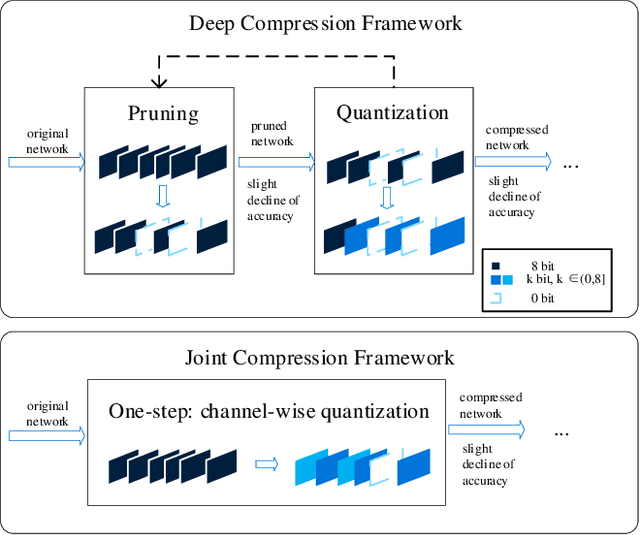
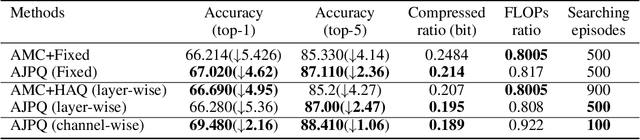
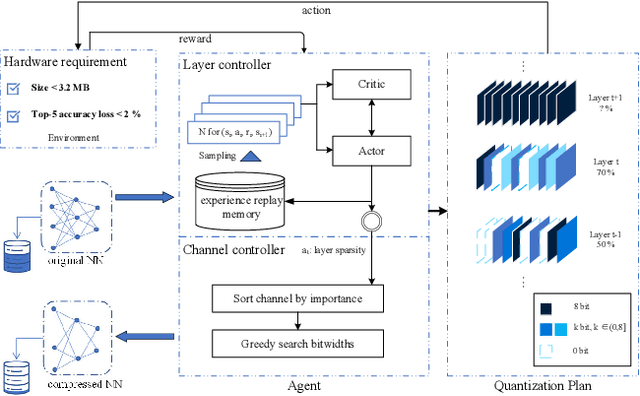
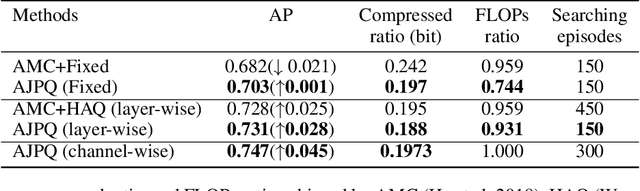
In the traditional deep compression framework, iteratively performing network pruning and quantization can reduce the model size and computation cost to meet the deployment requirements. However, such a step-wise application of pruning and quantization may lead to suboptimal solutions and unnecessary time consumption. In this paper, we tackle this issue by integrating network pruning and quantization as a unified joint compression problem and then use AutoML to automatically solve it. We find the pruning process can be regarded as the channel-wise quantization with 0 bit. Thus, the separate two-step pruning and quantization can be simplified as the one-step quantization with mixed precision. This unification not only simplifies the compression pipeline but also avoids the compression divergence. To implement this idea, we propose the automated model compression by jointly applied pruning and quantization (AJPQ). AJPQ is designed with a hierarchical architecture: the layer controller controls the layer sparsity, and the channel controller decides the bit-width for each kernel. Following the same importance criterion, the layer controller and the channel controller collaboratively decide the compression strategy. With the help of reinforcement learning, our one-step compression is automatically achieved. Compared with the state-of-the-art automated compression methods, our method obtains a better accuracy while reducing the storage considerably. For fixed precision quantization, AJPQ can reduce more than five times model size and two times computation with a slight performance increase for Skynet in remote sensing object detection. When mixed-precision is allowed, AJPQ can reduce five times model size with only 1.06% top-5 accuracy decline for MobileNet in the classification task.
Sequential Subspace Search for Functional Bayesian Optimization Incorporating Experimenter Intuition
Sep 08, 2020
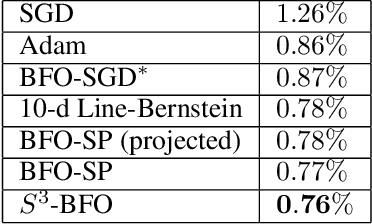

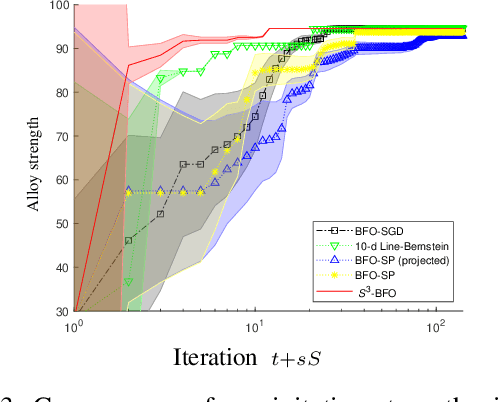
We propose an algorithm for Bayesian functional optimisation - that is, finding the function to optimise a process - guided by experimenter beliefs and intuitions regarding the expected characteristics (length-scale, smoothness, cyclicity etc.) of the optimal solution encoded into the covariance function of a Gaussian Process. Our algorithm generates a sequence of finite-dimensional random subspaces of functional space spanned by a set of draws from the experimenter's Gaussian Process. Standard Bayesian optimisation is applied on each subspace, and the best solution found used as a starting point (origin) for the next subspace. Using the concept of effective dimensionality, we analyse the convergence of our algorithm and provide a regret bound to show that our algorithm converges in sub-linear time provided a finite effective dimension exists. We test our algorithm in simulated and real-world experiments, namely blind function matching, finding the optimal precipitation-strengthening function for an aluminium alloy, and learning rate schedule optimisation for deep networks.
Causal Reasoning in Graphical Time Series Models
Jun 20, 2012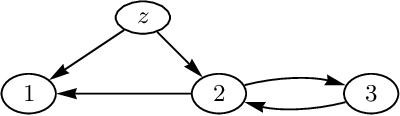


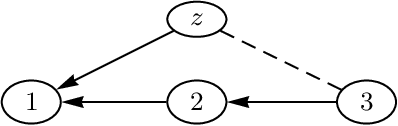
We propose a definition of causality for time series in terms of the effect of an intervention in one component of a multivariate time series on another component at some later point in time. Conditions for identifiability, comparable to the back-door and front-door criteria, are presented and can also be verified graphically. Computation of the causal effect is derived and illustrated for the linear case.
Online probabilistic label trees
Jul 08, 2020
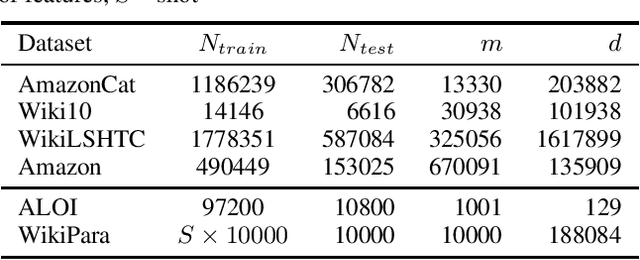
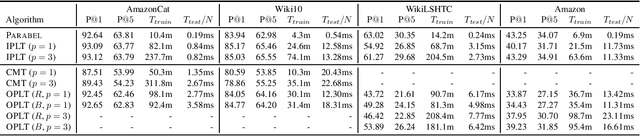
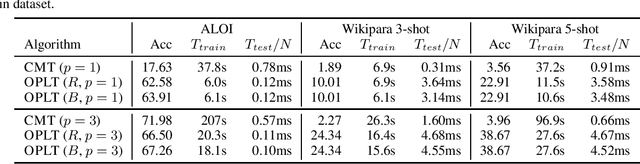
We introduce online probabilistic label trees (OPLTs), an algorithm that trains a label tree classifier in a fully online manner, without any prior knowledge about the number of training instances, their features and labels. OPLTs are characterized by low time and space complexity as well as strong theoretical guarantees. They can be used for online multi-label and multi-class classification, including the very challenging scenarios of one- or few-shot learning. We demonstrate the attractiveness of OPLTs in a wide empirical study on several instances of the tasks mentioned above.
Hybrid Sequence to Sequence Model for Video Object Segmentation
Oct 10, 2020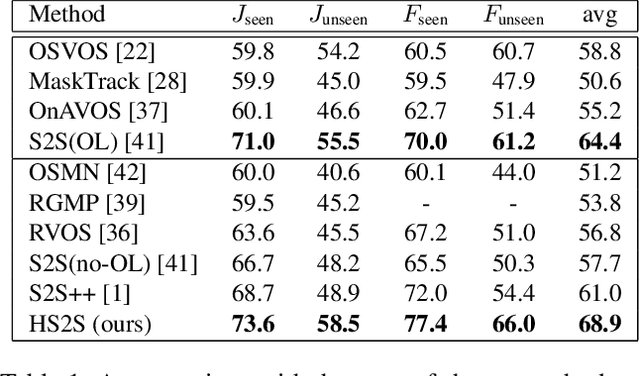
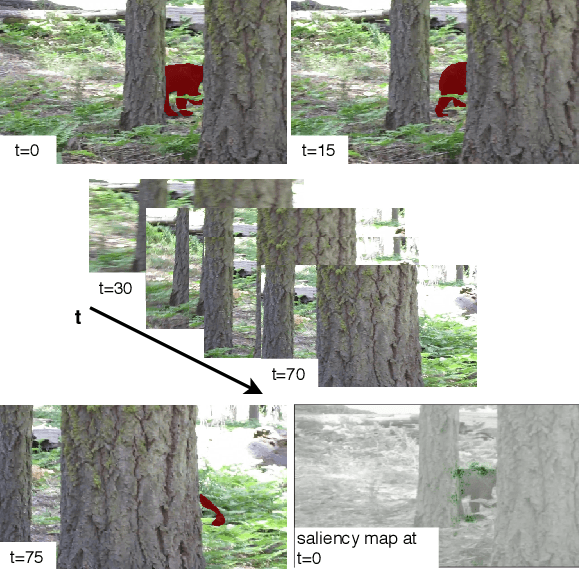

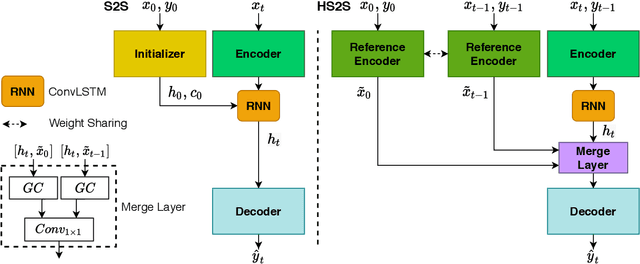
One-shot Video Object Segmentation (VOS) is the task of pixel-wise tracking an object of interest within a video sequence, where the segmentation mask of the first frame is given at inference time. In recent years, Recurrent Neural Networks (RNNs) have been widely used for VOS tasks, but they often suffer from limitations such as drift and error propagation. In this work, we study an RNN-based architecture and address some of these issues by proposing a hybrid sequence-to-sequence architecture named HS2S, utilizing a hybrid mask propagation strategy that allows incorporating the information obtained from correspondence matching. Our experiments show that augmenting the RNN with correspondence matching is a highly effective solution to reduce the drift problem. The additional information helps the model to predict more accurate masks and makes it robust against error propagation. We evaluate our HS2S model on the DAVIS2017 dataset as well as Youtube-VOS. On the latter, we achieve an improvement of 11.2pp in the overall segmentation accuracy over RNN-based state-of-the-art methods in VOS. We analyze our model's behavior in challenging cases such as occlusion and long sequences and show that our hybrid architecture significantly enhances the segmentation quality in these difficult scenarios.
Universal Lower-Bounds on Classification Error under Adversarial Attacks and Random Corruption
Jul 07, 2020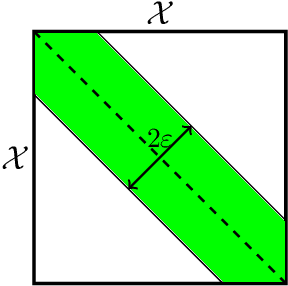
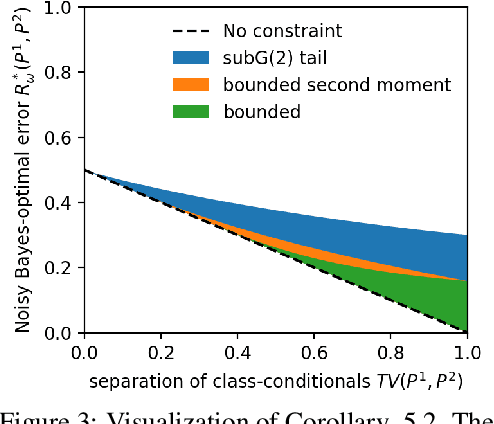
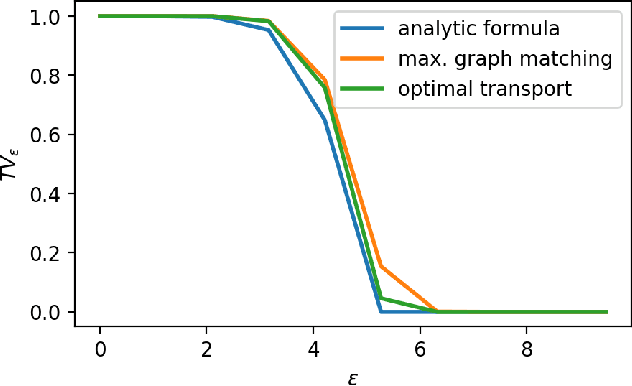
We theoretically analyse the limits of robustness to test-time adversarial and noisy examples in classification. Our work focuses on deriving bounds which uniformly apply to all classifiers (i.e all measurable functions from features to labels) for a given problem. Our contributions are three-fold. (1) In the classical framework of adversarial attacks, we use optimal transport theory to derive variational formulae for the Bayes-optimal error a classifier can make on a given classification problem, subject to adversarial attacks. The optimal adversarial attack is then an optimal transport plan for a certain binary cost-function induced by the specific attack model, and can be computed via a simple algorithm based on maximal matching on bipartite graphs. (2) We derive explicit lower-bounds on the Bayes-optimal error in the case of the popular distance-based attacks. These bounds are universal in the sense that they depend on the geometry of the class-conditional distributions of the data, but not on a particular classifier. Our results are in sharp contrast with the existing literature, wherein adversarial vulnerability of classifiers is derived as a consequence of nonzero ordinary test error. (3) For our third contribution, we study robustness to random noise corruption, wherein the attacker (or nature) is allowed to inject random noise into examples at test time. We establish nonlinear data-processing inequalities induced by such corruptions, and use them to obtain lower-bounds on the Bayes-optimal error for noisy problem.
Surprise: Result List Truncation via Extreme Value Theory
Oct 19, 2020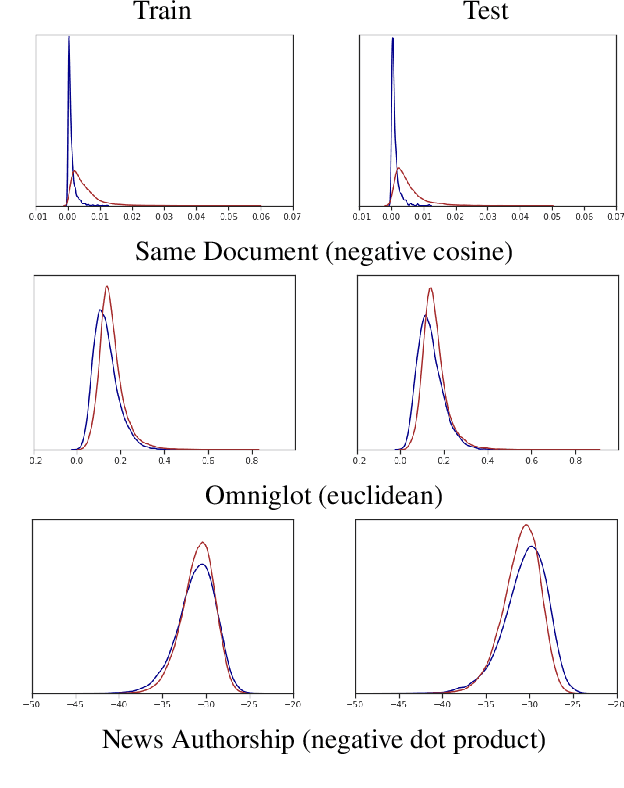
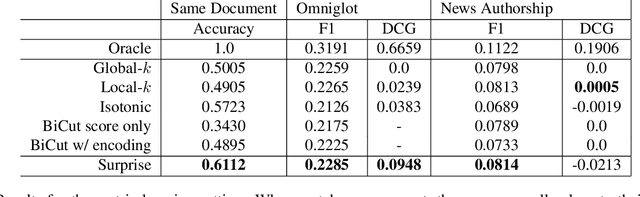
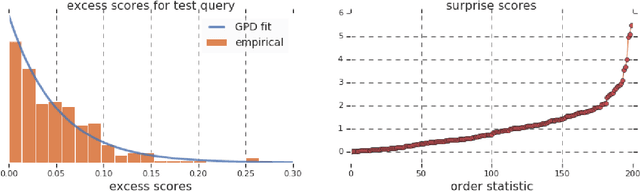
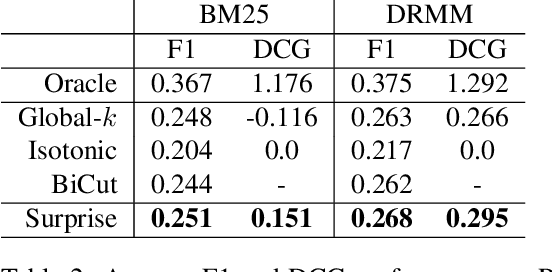
Work in information retrieval has largely been centered around ranking and relevance: given a query, return some number of results ordered by relevance to the user. The problem of result list truncation, or where to truncate the ranked list of results, however, has received less attention despite being crucial in a variety of applications. Such truncation is a balancing act between the overall relevance, or usefulness of the results, with the user cost of processing more results. Result list truncation can be challenging because relevance scores are often not well-calibrated. This is particularly true in large-scale IR systems where documents and queries are embedded in the same metric space and a query's nearest document neighbors are returned during inference. Here, relevance is inversely proportional to the distance between the query and candidate document, but what distance constitutes relevance varies from query to query and changes dynamically as more documents are added to the index. In this work, we propose Surprise scoring, a statistical method that leverages the Generalized Pareto distribution that arises in extreme value theory to produce interpretable and calibrated relevance scores at query time using nothing more than the ranked scores. We demonstrate its effectiveness on the result list truncation task across image, text, and IR datasets and compare it to both classical and recent baselines. We draw connections to hypothesis testing and $p$-values.