 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurprise: Result List Truncation via Extreme Value Theory
Paper and Code
Oct 19, 2020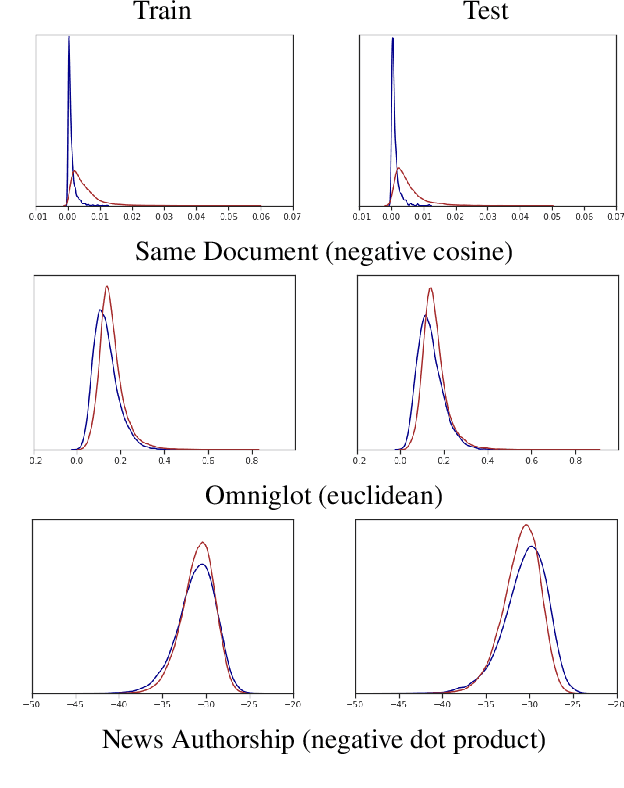
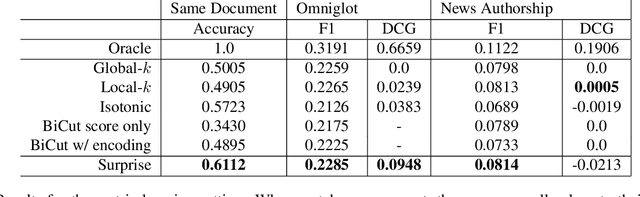
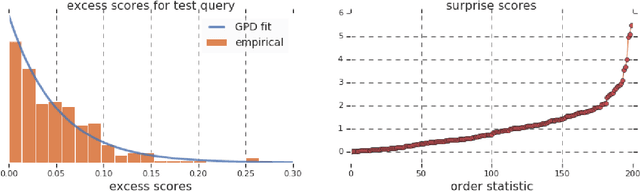
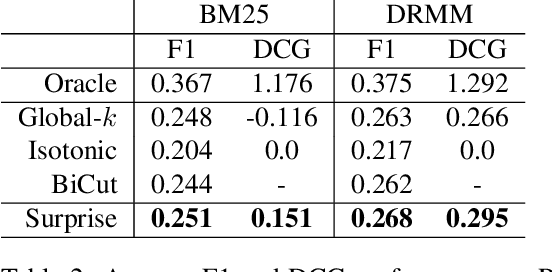
Work in information retrieval has largely been centered around ranking and relevance: given a query, return some number of results ordered by relevance to the user. The problem of result list truncation, or where to truncate the ranked list of results, however, has received less attention despite being crucial in a variety of applications. Such truncation is a balancing act between the overall relevance, or usefulness of the results, with the user cost of processing more results. Result list truncation can be challenging because relevance scores are often not well-calibrated. This is particularly true in large-scale IR systems where documents and queries are embedded in the same metric space and a query's nearest document neighbors are returned during inference. Here, relevance is inversely proportional to the distance between the query and candidate document, but what distance constitutes relevance varies from query to query and changes dynamically as more documents are added to the index. In this work, we propose Surprise scoring, a statistical method that leverages the Generalized Pareto distribution that arises in extreme value theory to produce interpretable and calibrated relevance scores at query time using nothing more than the ranked scores. We demonstrate its effectiveness on the result list truncation task across image, text, and IR datasets and compare it to both classical and recent baselines. We draw connections to hypothesis testing and $p$-values.