 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Primal-Dual $π$ Learning: Sample Complexity and Sublinear Run Time for Ergodic Markov Decision Problems
Oct 17, 2017
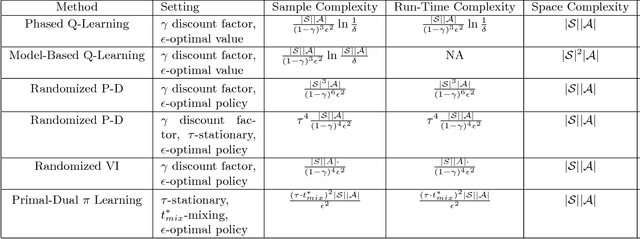
Consider the problem of approximating the optimal policy of a Markov decision process (MDP) by sampling state transitions. In contrast to existing reinforcement learning methods that are based on successive approximations to the nonlinear Bellman equation, we propose a Primal-Dual $\pi$ Learning method in light of the linear duality between the value and policy. The $\pi$ learning method is model-free and makes primal-dual updates to the policy and value vectors as new data are revealed. For infinite-horizon undiscounted Markov decision process with finite state space $S$ and finite action space $A$, the $\pi$ learning method finds an $\epsilon$-optimal policy using the following number of sample transitions $$ \tilde{O}( \frac{(\tau\cdot t^*_{mix})^2 |S| |A| }{\epsilon^2} ),$$ where $t^*_{mix}$ is an upper bound of mixing times across all policies and $\tau$ is a parameter characterizing the range of stationary distributions across policies. The $\pi$ learning method also applies to the computational problem of MDP where the transition probabilities and rewards are explicitly given as the input. In the case where each state transition can be sampled in $\tilde{O}(1)$ time, the $\pi$ learning method gives a sublinear-time algorithm for solving the averaged-reward MDP.
Automatic Pass Annotation from Soccer VideoStreams Based on Object Detection and LSTM
Jul 13, 2020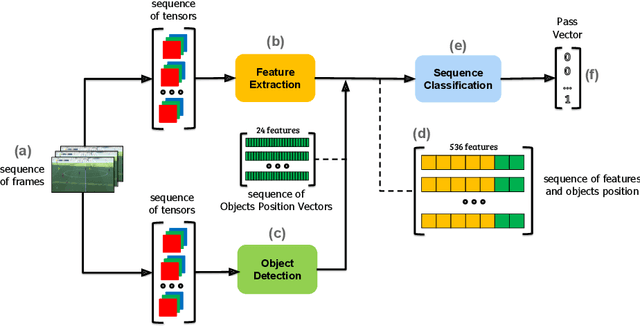
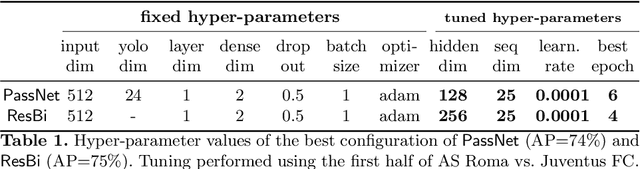


Soccer analytics is attracting increasing interest in academia and industry, thanks to the availability of data that describe all the spatio-temporal events that occur in each match. These events (e.g., passes, shots, fouls) are collected by human operators manually, constituting a considerable cost for data providers in terms of time and economic resources. In this paper, we describe PassNet, a method to recognize the most frequent events in soccer, i.e., passes, from video streams. Our model combines a set of artificial neural networks that perform feature extraction from video streams, object detection to identify the positions of the ball and the players, and classification of frame sequences as passes or not passes. We test PassNet on different scenarios, depending on the similarity of conditions to the match used for training. Our results show good classification results and significant improvement in the accuracy of pass detection with respect to baseline classifiers, even when the match's video conditions of the test and training sets are considerably different. PassNet is the first step towards an automated event annotation system that may break the time and the costs for event annotation, enabling data collections for minor and non-professional divisions, youth leagues and, in general, competitions whose matches are not currently annotated by data providers.
Effect of Different Batch Size Parameters on Predicting of COVID19 Cases
Dec 10, 2020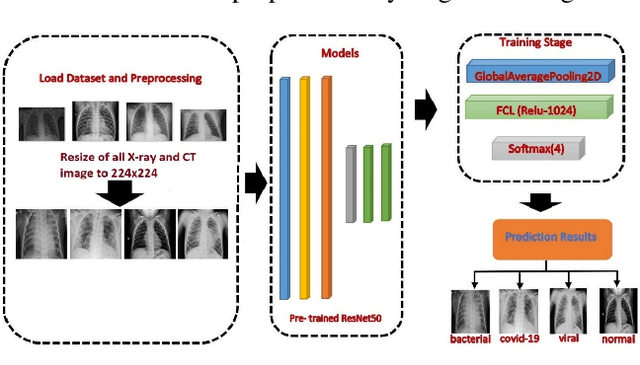
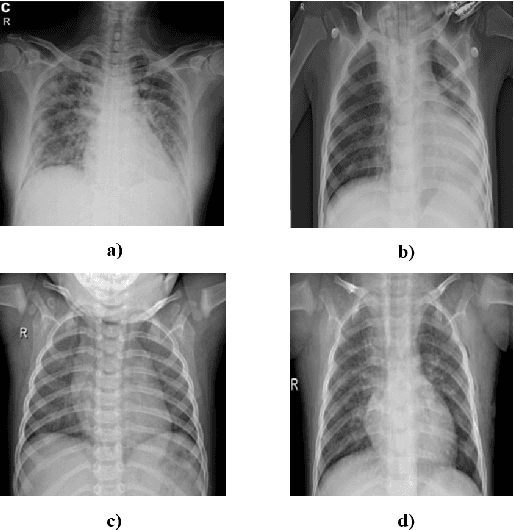
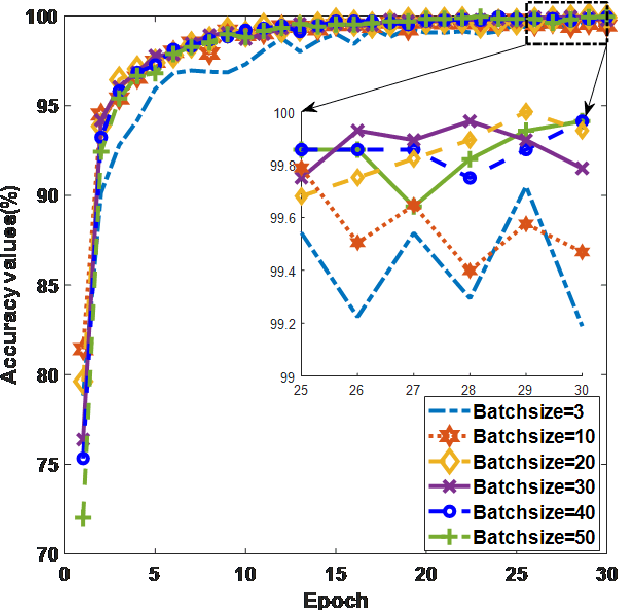
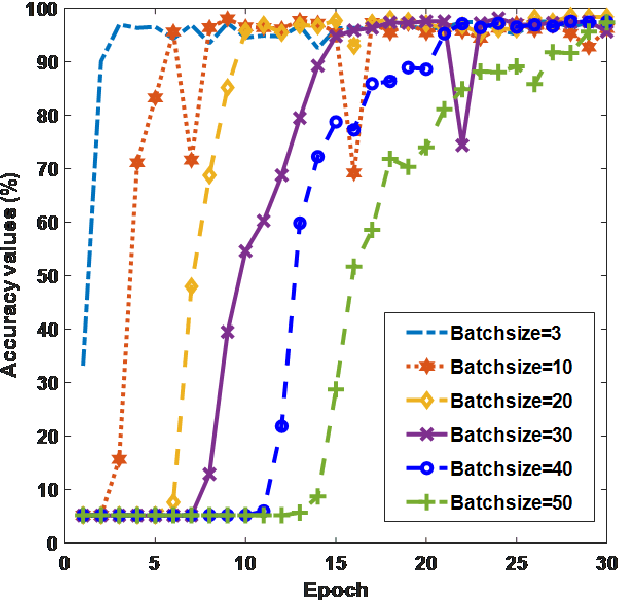
The new coronavirus 2019, also known as COVID19, is a very serious epidemic that has killed thousands or even millions of people since December 2019. It was defined as a pandemic by the world health organization in March 2020. It is stated that this virus is usually transmitted by droplets caused by sneezing or coughing, or by touching infected surfaces. The presence of the virus is detected by real-time reverse transcriptase polymerase chain reaction (rRT-PCR) tests with the help of a swab taken from the nose or throat. In addition, X-ray and CT imaging methods are also used to support this method. Since it is known that the accuracy sensitivity in rRT-PCR test is low, auxiliary diagnostic methods have a very important place. Computer-aided diagnosis and detection systems are developed especially with the help of X-ray and CT images. Studies on the detection of COVID19 in the literature are increasing day by day. In this study, the effect of different batch size (BH=3, 10, 20, 30, 40, and 50) parameter values on their performance in detecting COVID19 and other classes was investigated using data belonging to 4 different (Viral Pneumonia, COVID19, Normal, Bacterial Pneumonia) classes. The study was carried out using a pre-trained ResNet50 convolutional neural network. According to the obtained results, they performed closely on the training and test data. However, it was observed that the steady state in the test data was delayed as the batch size value increased. The highest COVID19 detection was 95.17% for BH = 3, while the overall accuracy value was 97.97% with BH = 20. According to the findings, it can be said that the batch size value does not affect the overall performance significantly, but the increase in the batch size value delays obtaining stable results.
Ant Colony Inspired Machine Learning Algorithm for Identifying and Emulating Virtual Sensors
Nov 02, 2020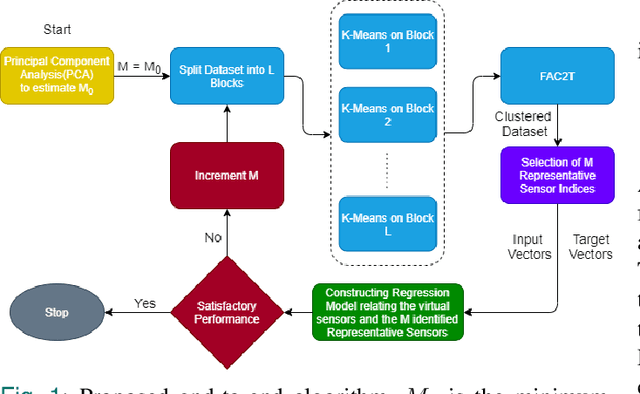
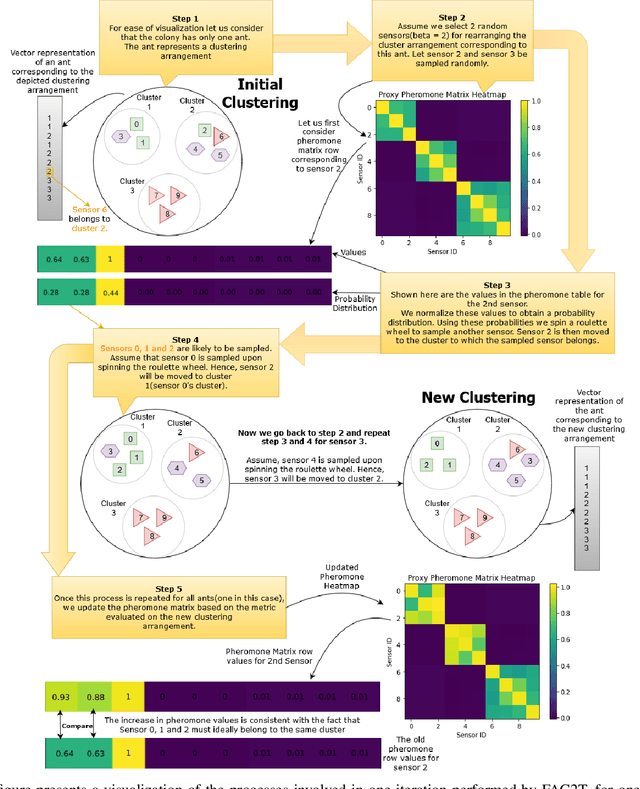
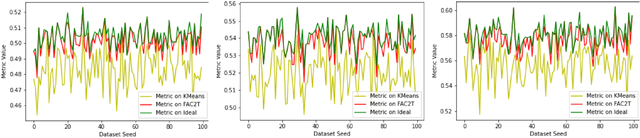
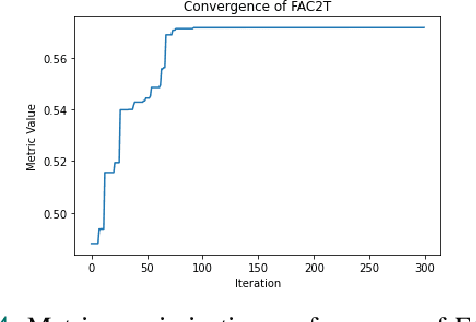
The scale of systems employed in industrial environments demands a large number of sensors to facilitate meticulous monitoring and functioning. These requirements could potentially lead to inefficient system designs. The data coming from various sensors are often correlated due to the underlying relations in the system parameters that the sensors monitor. In theory, it should be possible to emulate the output of certain sensors based on other sensors. Tapping into such possibilities holds tremendous advantages in terms of reducing system design complexity. In order to identify the subset of sensors whose readings can be emulated, the sensors must be grouped into clusters. Complex systems generally have a large quantity of sensors that collect and store data over prolonged periods of time. This leads to the accumulation of massive amounts of data. In this paper we propose an end-to-end algorithmic solution, to realise virtual sensors in such systems. This algorithm splits the dataset into blocks and clusters each of them individually. It then fuses these clustering solutions to obtain a global solution using an Ant Colony inspired technique, FAC2T. Having grouped the sensors into clusters, we select representative sensors from each cluster. These sensors are retained in the system while the other sensors readings are emulated by applying supervised learning algorithms.
VIO-UWB-Based Collaborative Localization and Dense Scene Reconstruction within Heterogeneous Multi-Robot Systems
Nov 02, 2020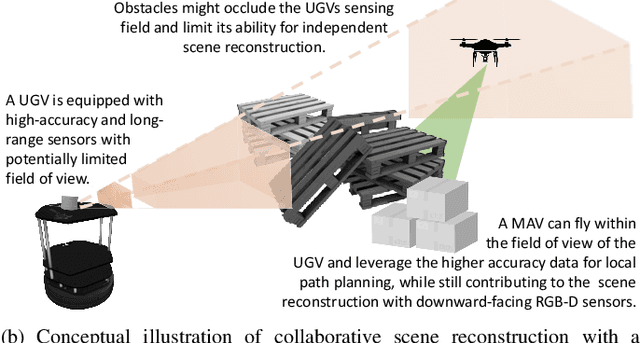

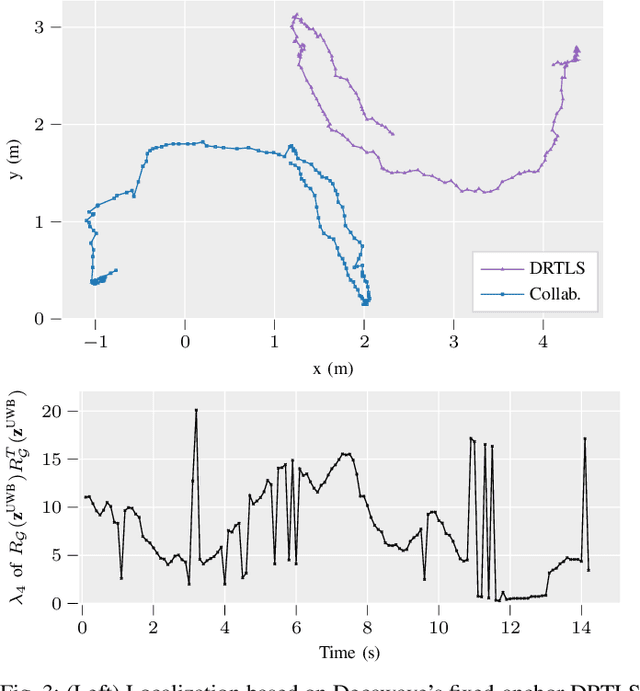
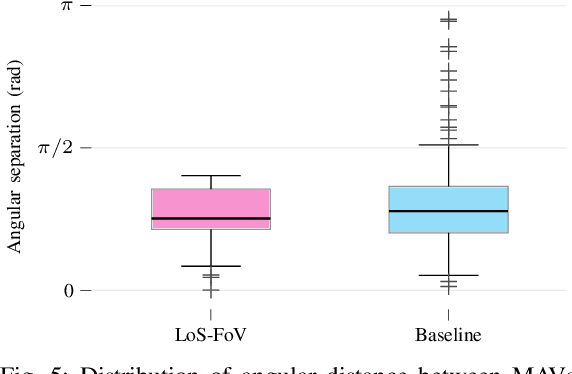
Effective collaboration in multi-robot systems requires accurate and robust estimation of relative localization: from cooperative manipulation to collaborative sensing, and including cooperative exploration or cooperative transportation. This paper introduces a novel approach to collaborative localization for dense scene reconstruction in heterogeneous multi-robot systems comprising ground robots and micro-aerial vehicles (MAVs). We solve the problem of full relative pose estimation without sliding time windows by relying on UWB-based ranging and Visual Inertial Odometry (VIO)-based egomotion estimation for localization, while exploiting lidars onboard the ground robots for full relative pose estimation in a single reference frame. During operation, the rigidity eigenvalue provides feedback to the system. To tackle the challenge of path planning and obstacle avoidance of MAVs in GNSS-denied environments, we maintain line-of-sight between ground robots and MAVs. Because lidars capable of dense reconstruction have limited FoV, this introduces new constraints to the system. Therefore, we propose a novel formulation with a variant of the Dubins multiple traveling salesman problem with neighborhoods (DMTSPN) where we include constraints related to the limited FoV of the ground robots. Our approach is validated with simulations and experiments with real robots for the different parts of the system.
Mathematical Word Problem Generation from Commonsense Knowledge Graph and Equations
Oct 13, 2020
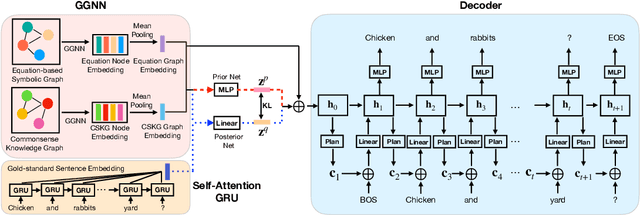
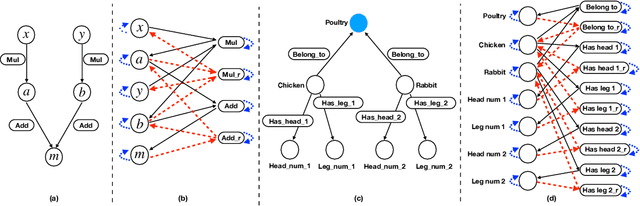
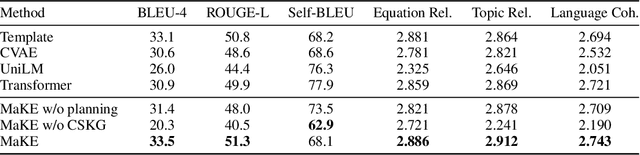
There is an increasing interest in the use of automatic mathematical word problem (MWP) generation in educational assessment. Different from standard natural question generation, MWP generation needs to maintain the underlying mathematical operations between quantities and variables, while at the same time ensuring the relevance between the output and the given topic. To address above problem we develop an end-to-end neural model to generate personalized and diverse MWPs in real-world scenarios from commonsense knowledge graph and equations. The proposed model (1) learns both representations from edge-enhanced Levi graphs of symbolic equations and commonsense knowledge; (2) automatically fuses equation and commonsense knowledge information via a self-planning module when generating the MWPs. Experiments on an educational gold-standard set and a large-scale generated MWP set show that our approach is superior on the MWP generation task, and it outperforms the state-of-the-art models in terms of both automatic evaluation metrics, i.e., BLEU-4, ROUGE-L, Self-BLEU, and human evaluation metrics, i.e, equation relevance, topic relevance, and language coherence.
Extremely Low Bit Transformer Quantization for On-Device Neural Machine Translation
Oct 13, 2020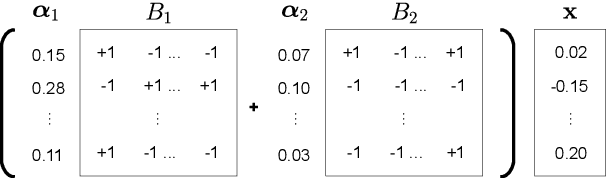
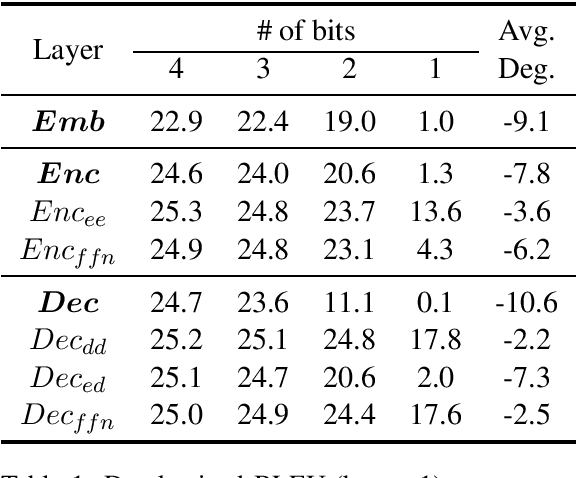
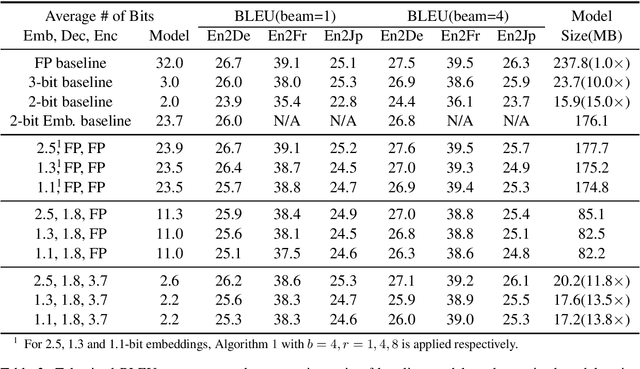
The deployment of widely used Transformer architecture is challenging because of heavy computation load and memory overhead during inference, especially when the target device is limited in computational resources such as mobile or edge devices. Quantization is an effective technique to address such challenges. Our analysis shows that for a given number of quantization bits, each block of Transformer contributes to translation quality and inference computations in different manners. Moreover, even inside an embedding block, each word presents vastly different contributions. Correspondingly, we propose a mixed precision quantization strategy to represent Transformer weights by an extremely low number of bits (e.g., under 3 bits). For example, for each word in an embedding block, we assign different quantization bits based on statistical property. Our quantized Transformer model achieves 11.8$\times$ smaller model size than the baseline model, with less than -0.5 BLEU. We achieve 8.3$\times$ reduction in run-time memory footprints and 3.5$\times$ speed up (Galaxy N10+) such that our proposed compression strategy enables efficient implementation for on-device NMT.
ISAAQ -- Mastering Textbook Questions with Pre-trained Transformers and Bottom-Up and Top-Down Attention
Oct 01, 2020



Textbook Question Answering is a complex task in the intersection of Machine Comprehension and Visual Question Answering that requires reasoning with multimodal information from text and diagrams. For the first time, this paper taps on the potential of transformer language models and bottom-up and top-down attention to tackle the language and visual understanding challenges this task entails. Rather than training a language-visual transformer from scratch we rely on pre-trained transformers, fine-tuning and ensembling. We add bottom-up and top-down attention to identify regions of interest corresponding to diagram constituents and their relationships, improving the selection of relevant visual information for each question and answer options. Our system ISAAQ reports unprecedented success in all TQA question types, with accuracies of 81.36%, 71.11% and 55.12% on true/false, text-only and diagram multiple choice questions. ISAAQ also demonstrates its broad applicability, obtaining state-of-the-art results in other demanding datasets.
Speech enhancement aided end-to-end multi-task learning for voice activity detection
Oct 23, 2020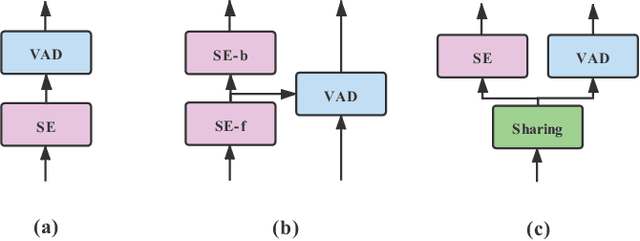
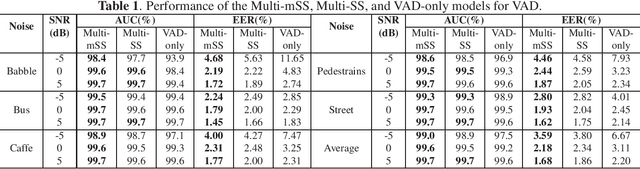


Robust voice activity detection (VAD) is a challenging task in low signal-to-noise (SNR) environments. Recent studies show that speech enhancement is helpful to VAD, but the performance improvement is limited. To address this issue, here we propose a speech enhancement aided end-to-end multi-task model for VAD. The model has two decoders, one for speech enhancement and the other for VAD. The two decoders share the same encoder and speech separation network. Unlike the direct thought that takes two separated objectives for VAD and speech enhancement respectively, here we propose a new joint optimization objective---VAD-masked scale-invariant source-to-noise ratio (mSI-SDR). mSI-SDR uses VAD information to mask the output of the speech enhancement decoder in the training process. It makes the VAD and speech enhancement tasks jointly optimized not only at the shared encoder and separation network, but also at the objective level. Experimental results show that the multi-task method significantly outperforms its single-task VAD counterpart. Moreover, mSI-SDR outperforms SI-SDR in the same multi-task setting. Finally, the model performs well in real-time conditions.
Exposing the Robustness and Vulnerability of Hybrid 8T-6T SRAM Memory Architectures to Adversarial Attacks in Deep Neural Networks
Nov 26, 2020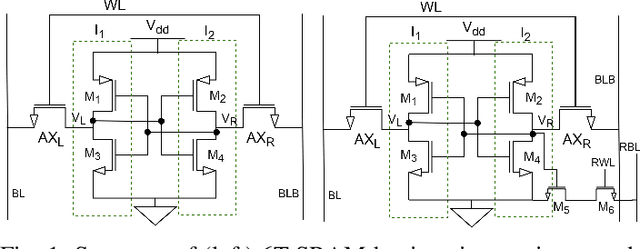
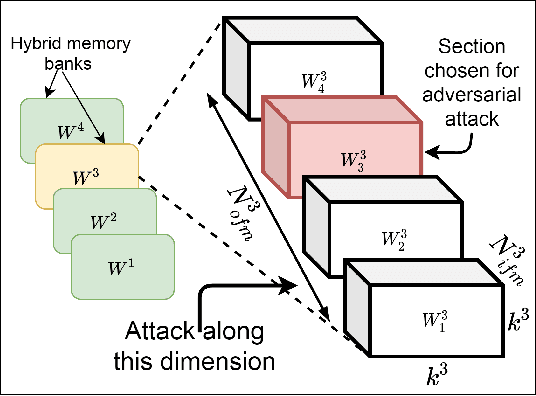
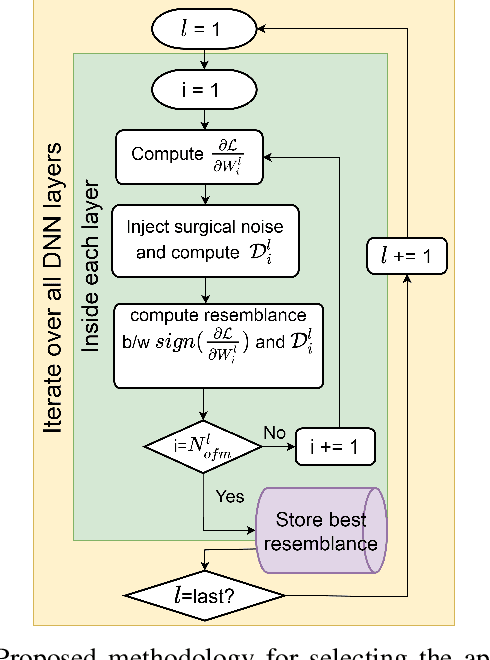
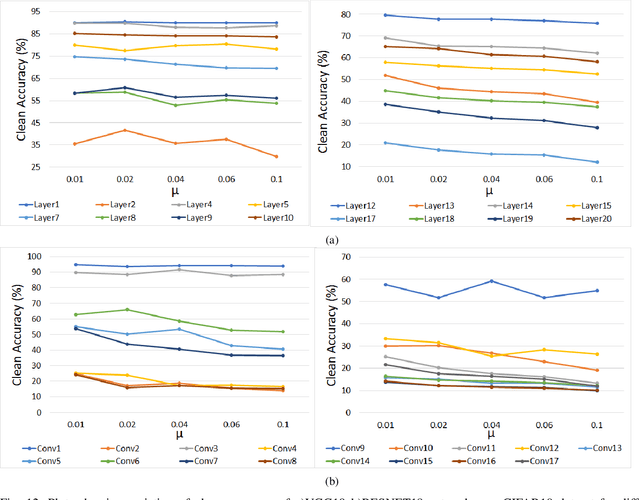
Deep Learning is able to solve a plethora of once impossible problems. However, they are vulnerable to input adversarial attacks preventing them from being autonomously deployed in critical applications. Several algorithm-centered works have discussed methods to cause adversarial attacks and improve adversarial robustness of a Deep Neural Network (DNN). In this work, we elicit the advantages and vulnerabilities of hybrid 6T-8T memories to improve the adversarial robustness and cause adversarial attacks on DNNs. We show that bit-error noise in hybrid memories due to erroneous 6T-SRAM cells have deterministic behaviour based on the hybrid memory configurations (V_DD, 8T-6T ratio). This controlled noise (surgical noise) can be strategically introduced into specific DNN layers to improve the adversarial accuracy of DNNs. At the same time, surgical noise can be carefully injected into the DNN parameters stored in hybrid memory to cause adversarial attacks. To improve the adversarial robustness of DNNs using surgical noise, we propose a methodology to select appropriate DNN layers and their corresponding hybrid memory configurations to introduce the required surgical noise. Using this, we achieve 2-8% higher adversarial accuracy without re-training against white-box attacks like FGSM, than the baseline models (with no surgical noise introduced). To demonstrate adversarial attacks using surgical noise, we design a novel, white-box attack on DNN parameters stored in hybrid memory banks that causes the DNN inference accuracy to drop by more than 60% with over 90% confidence value. We support our claims with experiments, performed using benchmark datasets-CIFAR10 and CIFAR100 on VGG19 and ResNet18 networks.