 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
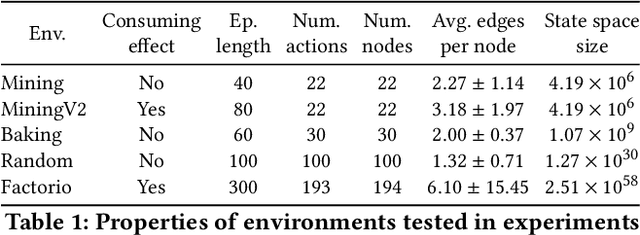
Impact of Power Supply Noise on Image Sensor Performance in Automotive Applications
Nov 24, 2020
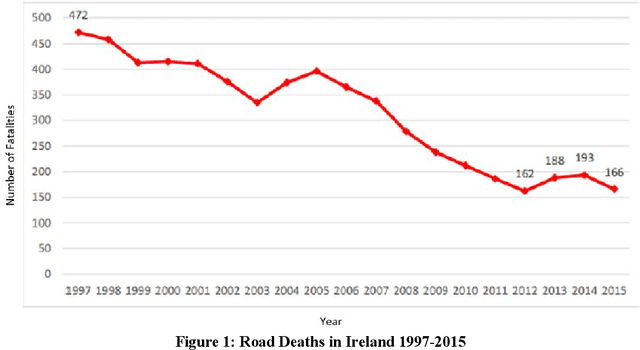
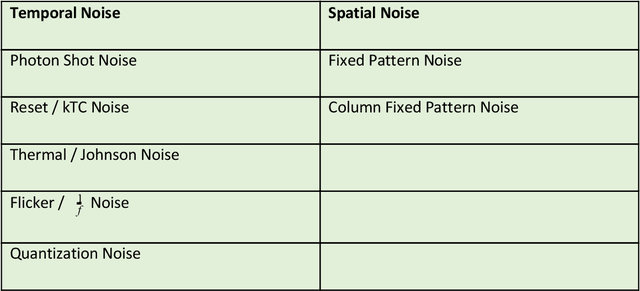
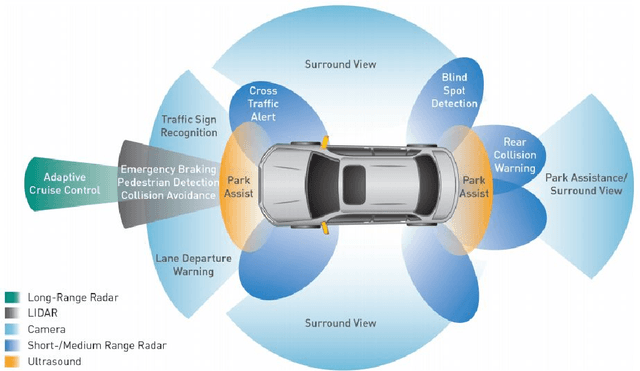

Vision Systems are quickly becoming a large component of Active Automotive Safety Systems. In order to be effective in critical safety applications these systems must produce high quality images in both daytime and night-time scenarios in order to provide the large informational content required for software analysis in applications such as lane departure, pedestrian detection and collision detection. The challenge in capturing high quality images in low light scenarios is that the signal to noise ratio is greatly reduced, which can result in noise becoming the dominant factor in a captured image, thereby making these safety systems less effective at night. Research has been undertaken to develop a systematic method of characterising image sensor performance in response to electrical noise in order to improve the design and performance of automotive cameras in low light scenarios. The root cause of image row noise has been established and a mathematical algorithm for determining the magnitude of row noise in an image has been devised. An automated characterisation method has been developed to allow performance characterisation in response to a large frequency spectrum of electrical noise on the image sensor power supply. Various strategies of improving image sensor performance for low light applications have also been proposed from the research outcomes.
Optimal Policies for Observing Time Series and Related Restless Bandit Problems
Mar 29, 2017



The trade-off between the cost of acquiring and processing data, and uncertainty due to a lack of data is fundamental in machine learning. A basic instance of this trade-off is the problem of deciding when to make noisy and costly observations of a discrete-time Gaussian random walk, so as to minimise the posterior variance plus observation costs. We present the first proof that a simple policy, which observes when the posterior variance exceeds a threshold, is optimal for this problem. The proof generalises to a wide range of cost functions other than the posterior variance. This result implies that optimal policies for linear-quadratic-Gaussian control with costly observations have a threshold structure. It also implies that the restless bandit problem of observing multiple such time series, has a well-defined Whittle index. We discuss computation of that index, give closed-form formulae for it, and compare the performance of the associated index policy with heuristic policies. The proof is based on a new verification theorem that demonstrates threshold structure for Markov decision processes, and on the relation between binary sequences known as mechanical words and the dynamics of discontinuous nonlinear maps, which frequently arise in physics, control and biology.
XSleepNet: Multi-View Sequential Model for Automatic Sleep Staging
Jul 17, 2020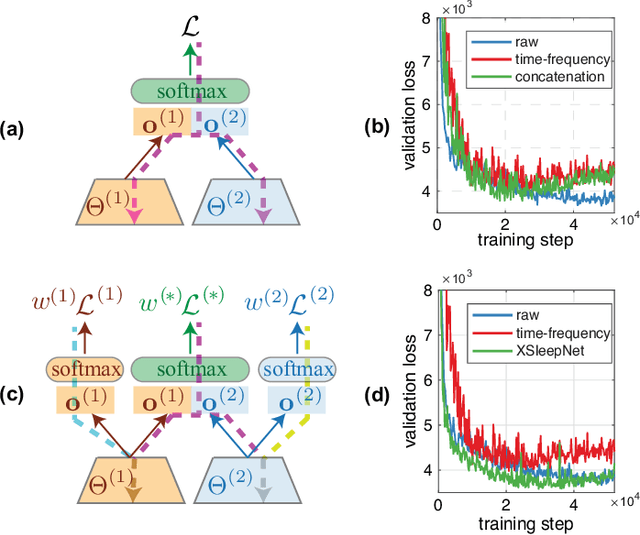

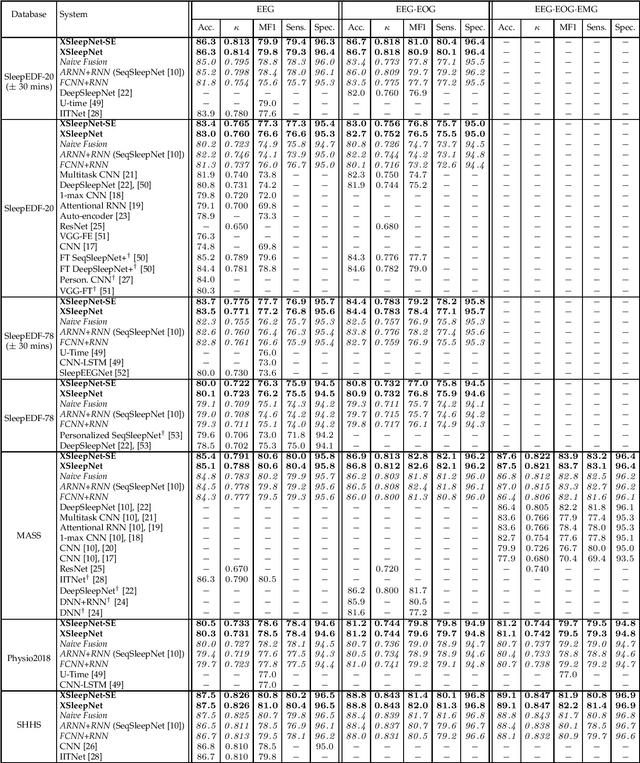
Automating sleep staging is vital to scale up sleep assessment and diagnosis to millions of people experiencing sleep deprivation and disorders and to enable longitudinal sleep monitoring in home environments. Learning from raw polysomnography signals and their derived time-frequency images has been prevalent. However, learning from multi-view inputs (e.g. both the raw signals and the time-frequency images) for sleep staging is difficult and not well understood. This work proposes a sequence-to-sequence sleep staging model, XSleepNet, that is capable of learning a joint representation from both raw signals and time-frequency images effectively. Since different views often generalize (and overfit) at different rates, the proposed network is trained in such a way that the learning pace on each view is adapted based on their generalization/overfitting behavior. In simple terms, the learning on a particular view is speeded up when it is generalizing well and slowed down when it is overfitting. View-specific generalization/overfitting measures are computed on-the-fly during the training course and used to derive weights to blend the gradients from different views. As a result, the network is able to retain representation power of different views in the joint features which represent the underlying distribution better than those learned by each individual view alone. Furthermore, the XSleepNet architecture is principally designed to gain robustness to the amount of training data and to increase the complementarity between the input views. Experimental results on five databases of different size show that XSleepNet consistently results in better performance than the single-view baselines as well as the multi-view baseline with a simple fusion strategy. Finally, XSleepNet outperforms all prior sleep staging methods and sets new state-of-the-art results on the experimental databases.
3D Probabilistic Segmentation and Volumetry from 2D projection images
Jun 23, 2020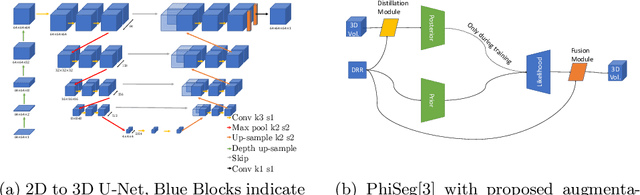
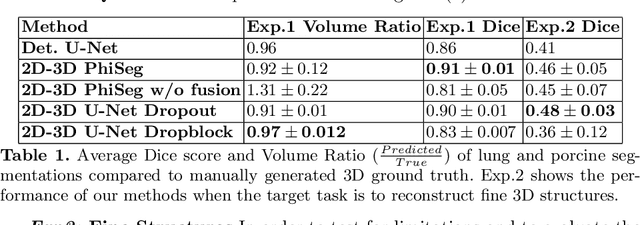

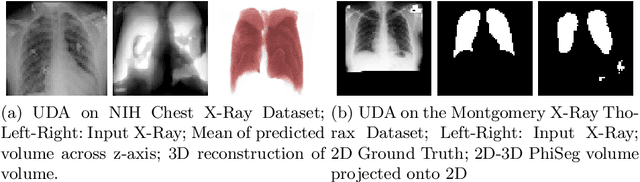
X-Ray imaging is quick, cheap and useful for front-line care assessment and intra-operative real-time imaging (e.g., C-Arm Fluoroscopy). However, it suffers from projective information loss and lacks vital volumetric information on which many essential diagnostic biomarkers are based on. In this paper we explore probabilistic methods to reconstruct 3D volumetric images from 2D imaging modalities and measure the models' performance and confidence. We show our models' performance on large connected structures and we test for limitations regarding fine structures and image domain sensitivity. We utilize fast end-to-end training of a 2D-3D convolutional networks, evaluate our method on 117 CT scans segmenting 3D structures from digitally reconstructed radiographs (DRRs) with a Dice score of $0.91 \pm 0.0013$. Source code will be made available by the time of the conference.
The Application of Data Mining in the Production Processes
Nov 24, 2020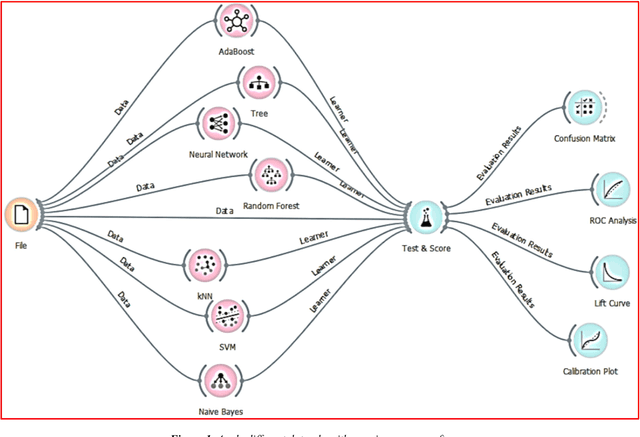
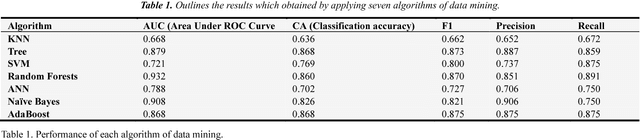
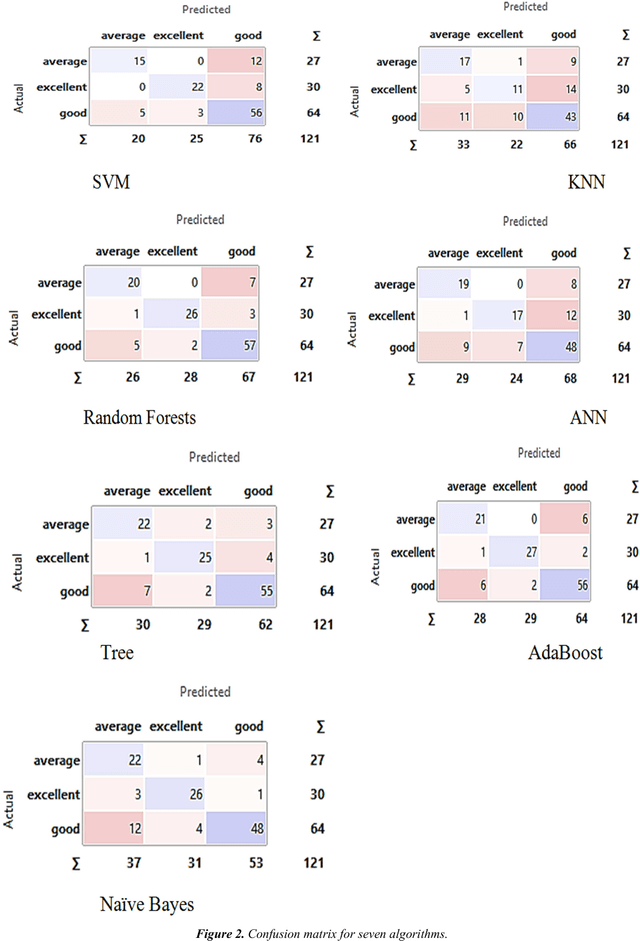
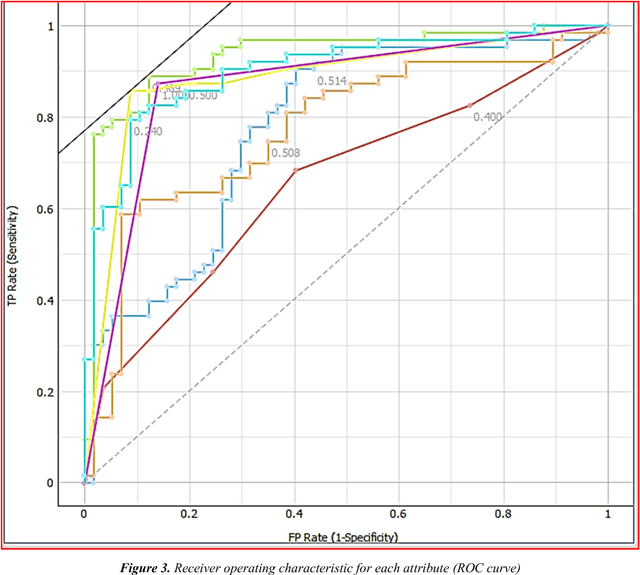
Traditional statistical and measurements are unable to solve all industrial data in the right way and appropriate time. Open markets mean the customers are increased, and production must increase to provide all customer requirements. Nowadays, large data generated daily from different production processes and traditional statistical or limited measurements are not enough to handle all daily data. Improve production and quality need to analyze data and extract the important information about the process how to improve. Data mining applied successfully in the industrial processes and some algorithms such as mining association rules, and decision tree recorded high professional results in different industrial and production fields. The study applied seven algorithms to analyze production data and extract the best result and algorithm in the industry field. KNN, Tree, SVM, Random Forests, ANN, Na\"ive Bayes, and AdaBoost applied to classify data based on three attributes without neglect any variables whether this variable is numerical or categorical. The best results of accuracy and area under the curve (ROC) obtained from Decision tree and its ensemble algorithms (Random Forest and AdaBoost). Thus, a decision tree is an appropriate algorithm to handle manufacturing and production data especially this algorithm can handle numerical and categorical data.
Scattering Transform Based Image Clustering using Projection onto Orthogonal Complement
Nov 24, 2020

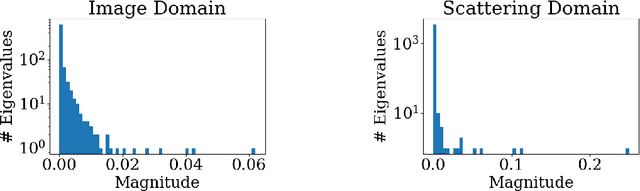
In the last few years, large improvements in image clustering have been driven by the recent advances in deep learning. However, due to the architectural complexity of deep neural networks, there is no mathematical theory that explains the success of deep clustering techniques. In this work we introduce Projected-Scattering Spectral Clustering (PSSC), a state-of-the-art, stable, and fast algorithm for image clustering, which is also mathematically interpretable. PSSC includes a novel method to exploit the geometric structure of the scattering transform of small images. This method is inspired by the observation that, in the scattering transform domain, the subspaces formed by the eigenvectors corresponding to the few largest eigenvalues of the data matrices of individual classes are nearly shared among different classes. Therefore, projecting out those shared subspaces reduces the intra-class variability, substantially increasing the clustering performance. We call this method Projection onto Orthogonal Complement (POC). Our experiments demonstrate that PSSC obtains the best results among all shallow clustering algorithms. Moreover, it achieves comparable clustering performance to that of recent state-of-the-art clustering techniques, while reducing the execution time by more than one order of magnitude. In the spirit of reproducible research, we publish a high quality code repository along with the paper.
Insights From A Large-Scale Database of Material Depictions In Paintings
Nov 24, 2020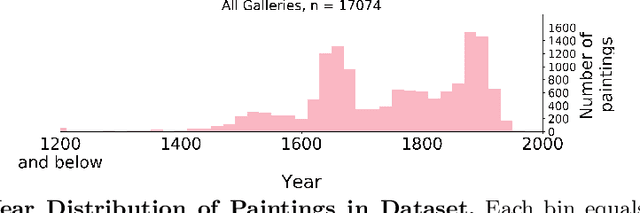
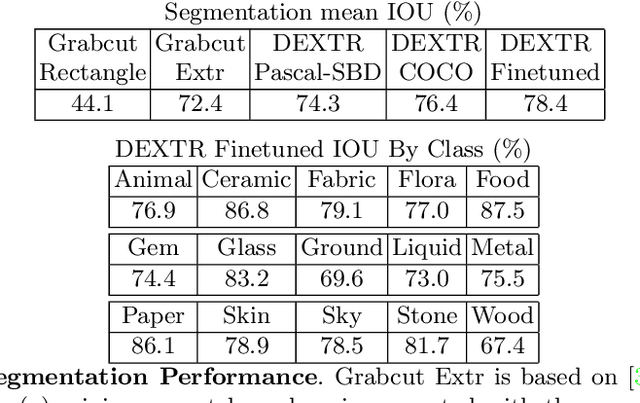


Deep learning has paved the way for strong recognition systems which are often both trained on and applied to natural images. In this paper, we examine the give-and-take relationship between such visual recognition systems and the rich information available in the fine arts. First, we find that visual recognition systems designed for natural images can work surprisingly well on paintings. In particular, we find that interactive segmentation tools can be used to cleanly annotate polygonal segments within paintings, a task which is time consuming to undertake by hand. We also find that FasterRCNN, a model which has been designed for object recognition in natural scenes, can be quickly repurposed for detection of materials in paintings. Second, we show that learning from paintings can be beneficial for neural networks that are intended to be used on natural images. We find that training on paintings instead of natural images can improve the quality of learned features and we further find that a large number of paintings can be a valuable source of test data for evaluating domain adaptation algorithms. Our experiments are based on a novel large-scale annotated database of material depictions in paintings which we detail in a separate manuscript.
I/O Lower Bounds for Auto-tuning of Convolutions in CNNs
Dec 31, 2020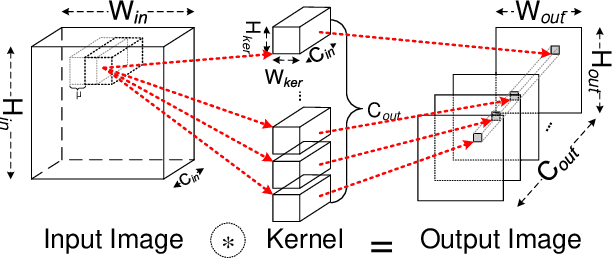
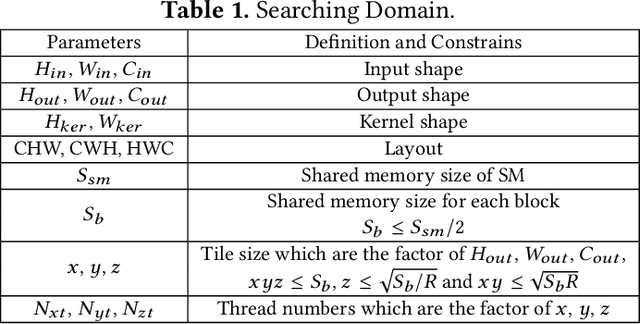
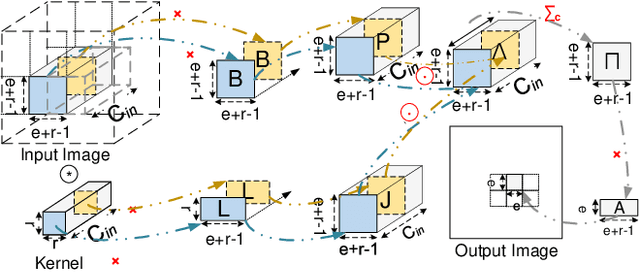

Convolution is the most time-consuming part in the computation of convolutional neural networks (CNNs), which have achieved great successes in numerous applications. Due to the complex data dependency and the increase in the amount of model samples, the convolution suffers from high overhead on data movement (i.e., memory access). This work provides comprehensive analysis and methodologies to minimize the communication for the convolution in CNNs. With an in-depth analysis of the recent I/O complexity theory under the red-blue game model, we develop a general I/O lower bound theory for a composite algorithm which consists of several different sub-computations. Based on the proposed theory, we establish the data movement lower bound results of two representative convolution algorithms in CNNs, namely the direct convolution and Winograd algorithm. Next, derived from I/O lower bound results, we design the near I/O-optimal dataflow strategies for the two main convolution algorithms by fully exploiting the data reuse. Furthermore, in order to push the envelope of performance of the near I/O-optimal dataflow strategies further, an aggressive design of auto-tuning based on I/O lower bounds, is proposed to search an optimal parameter configuration for the direct convolution and Winograd algorithm on GPU, such as the number of threads and the size of shared memory used in each thread block. Finally, experiment evaluation results on the direct convolution and Winograd algorithm show that our dataflow strategies with the auto-tuning approach can achieve about 3.32x performance speedup on average over cuDNN. In addition, compared with TVM, which represents the state-of-the-art technique for auto-tuning, not only our auto-tuning method based on I/O lower bounds can find the optimal parameter configuration faster, but also our solution has higher performance than the optimal solution provided by TVM.
Robust Hierarchical Planning with Policy Delegation
Oct 25, 2020
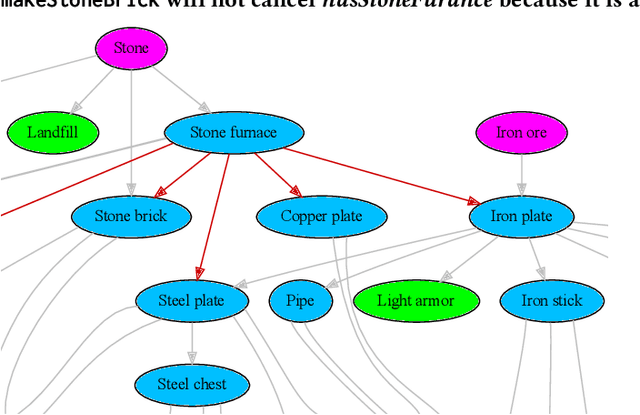
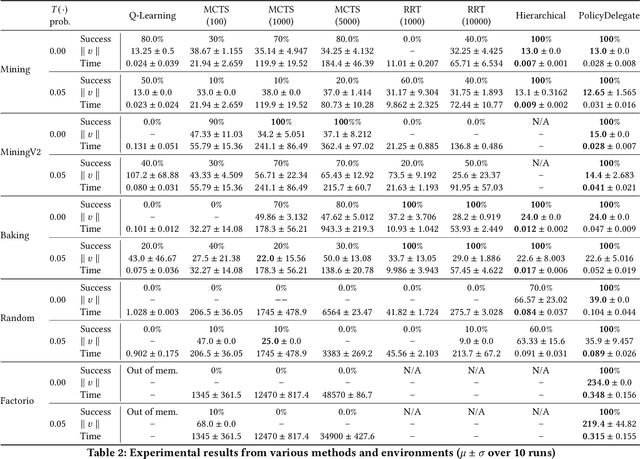
We propose a novel framework and algorithm for hierarchical planning based on the principle of delegation. This framework, the Markov Intent Process, features a collection of skills which are each specialised to perform a single task well. Skills are aware of their intended effects and are able to analyse planning goals to delegate planning to the best-suited skill. This principle dynamically creates a hierarchy of plans, in which each skill plans for sub-goals for which it is specialised. The proposed planning method features on-demand execution---skill policies are only evaluated when needed. Plans are only generated at the highest level, then expanded and optimised when the latest state information is available. The high-level plan retains the initial planning intent and previously computed skills, effectively reducing the computation needed to adapt to environmental changes. We show this planning approach is experimentally very competitive to classic planning and reinforcement learning techniques on a variety of domains, both in terms of solution length and planning time.
Deep intrinsic decomposition trained on surreal scenes yet with realistic light effects
Sep 14, 2020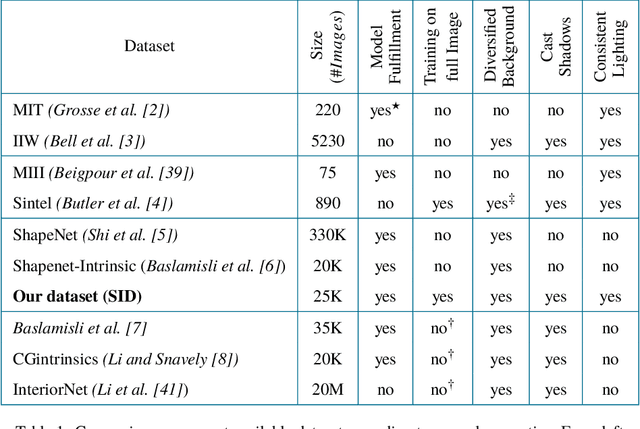

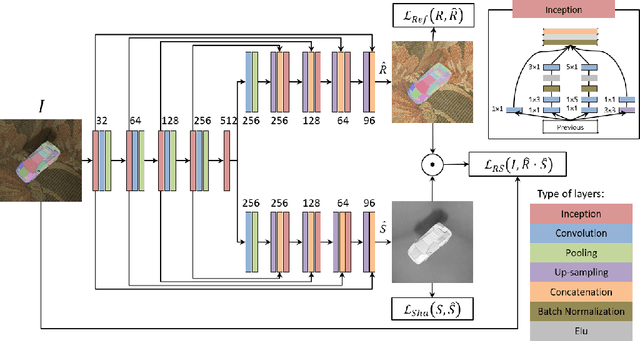
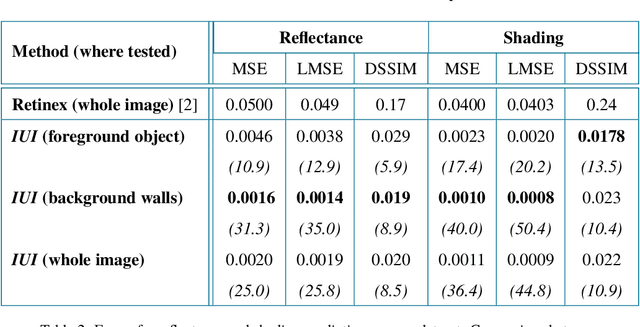
Estimation of intrinsic images still remains a challenging task due to weaknesses of ground-truth datasets, which either are too small or present non-realistic issues. On the other hand, end-to-end deep learning architectures start to achieve interesting results that we believe could be improved if important physical hints were not ignored. In this work, we present a twofold framework: (a) a flexible generation of images overcoming some classical dataset problems such as larger size jointly with coherent lighting appearance; and (b) a flexible architecture tying physical properties through intrinsic losses. Our proposal is versatile, presents low computation time, and achieves state-of-the-art results.