 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor encoding in Latent Space of Stable Diffusion Models
Dec 10, 2025



Recent advances in diffusion-based generative models have achieved remarkable visual fidelity, yet a detailed understanding of how specific perceptual attributes - such as color and shape - are internally represented remains limited. This work explores how color is encoded in a generative model through a systematic analysis of the latent representations in Stable Diffusion. Through controlled synthetic datasets, principal component analysis (PCA) and similarity metrics, we reveal that color information is encoded along circular, opponent axes predominantly captured in latent channels c_3 and c_4, whereas intensity and shape are primarily represented in channels c_1 and c_2. Our findings indicate that the latent space of Stable Diffusion exhibits an interpretable structure aligned with a efficient coding representation. These insights provide a foundation for future work in model understanding, editing applications, and the design of more disentangled generative frameworks.
Color in Visual-Language Models: CLIP deficiencies
Feb 06, 2025This work explores how color is encoded in CLIP (Contrastive Language-Image Pre-training) which is currently the most influential VML (Visual Language model) in Artificial Intelligence. After performing different experiments on synthetic datasets created for this task, we conclude that CLIP is able to attribute correct color labels to colored visual stimulus, but, we come across two main deficiencies: (a) a clear bias on achromatic stimuli that are poorly related to the color concept, thus white, gray and black are rarely assigned as color labels; and (b) the tendency to prioritize text over other visual information. Here we prove it is highly significant in color labelling through an exhaustive Stroop-effect test. With the aim to find the causes of these color deficiencies, we analyse the internal representation at the neuron level. We conclude that CLIP presents an important amount of neurons selective to text, specially in deepest layers of the network, and a smaller amount of multi-modal color neurons which could be the key of understanding the concept of color properly. Our investigation underscores the necessity of refining color representation mechanisms in neural networks to foster a more comprehensive comprehension of colors as humans understand them, thereby advancing the efficacy and versatility of multimodal models like CLIP in real-world scenarios.
* 6 pages, 10 figures, conference, Artificial Intelligence
MLI-NeRF: Multi-Light Intrinsic-Aware Neural Radiance Fields
Nov 26, 2024



Current methods for extracting intrinsic image components, such as reflectance and shading, primarily rely on statistical priors. These methods focus mainly on simple synthetic scenes and isolated objects and struggle to perform well on challenging real-world data. To address this issue, we propose MLI-NeRF, which integrates \textbf{M}ultiple \textbf{L}ight information in \textbf{I}ntrinsic-aware \textbf{Ne}ural \textbf{R}adiance \textbf{F}ields. By leveraging scene information provided by different light source positions complementing the multi-view information, we generate pseudo-label images for reflectance and shading to guide intrinsic image decomposition without the need for ground truth data. Our method introduces straightforward supervision for intrinsic component separation and ensures robustness across diverse scene types. We validate our approach on both synthetic and real-world datasets, outperforming existing state-of-the-art methods. Additionally, we demonstrate its applicability to various image editing tasks. The code and data are publicly available.
Relighting from a Single Image: Datasets and Deep Intrinsic-based Architecture
Sep 27, 2024Single image scene relighting aims to generate a realistic new version of an input image so that it appears to be illuminated by a new target light condition. Although existing works have explored this problem from various perspectives, generating relit images under arbitrary light conditions remains highly challenging, and related datasets are scarce. Our work addresses this problem from both the dataset and methodological perspectives. We propose two new datasets: a synthetic dataset with the ground truth of intrinsic components and a real dataset collected under laboratory conditions. These datasets alleviate the scarcity of existing datasets. To incorporate physical consistency in the relighting pipeline, we establish a two-stage network based on intrinsic decomposition, giving outputs at intermediate steps, thereby introducing physical constraints. When the training set lacks ground truth for intrinsic decomposition, we introduce an unsupervised module to ensure that the intrinsic outputs are satisfactory. Our method outperforms the state-of-the-art methods in performance, as tested on both existing datasets and our newly developed datasets. Furthermore, pretraining our method or other prior methods using our synthetic dataset can enhance their performance on other datasets. Since our method can accommodate any light conditions, it is capable of producing animated results. The dataset, method, and videos are publicly available.
Learning Relighting and Intrinsic Decomposition in Neural Radiance Fields
Jun 16, 2024The task of extracting intrinsic components, such as reflectance and shading, from neural radiance fields is of growing interest. However, current methods largely focus on synthetic scenes and isolated objects, overlooking the complexities of real scenes with backgrounds. To address this gap, our research introduces a method that combines relighting with intrinsic decomposition. By leveraging light variations in scenes to generate pseudo labels, our method provides guidance for intrinsic decomposition without requiring ground truth data. Our method, grounded in physical constraints, ensures robustness across diverse scene types and reduces the reliance on pre-trained models or hand-crafted priors. We validate our method on both synthetic and real-world datasets, achieving convincing results. Furthermore, the applicability of our method to image editing tasks demonstrates promising outcomes.
Intrinsic Decomposition of Document Images In-the-Wild
Nov 29, 2020
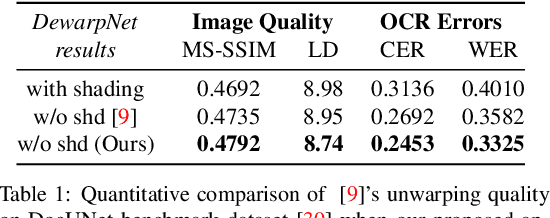

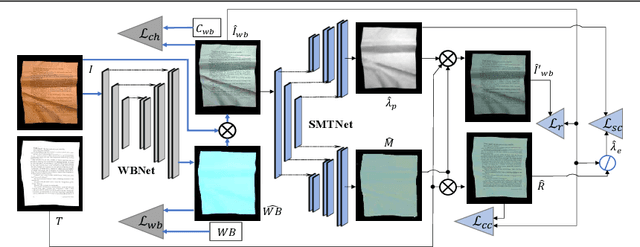
Automatic document content processing is affected by artifacts caused by the shape of the paper, non-uniform and diverse color of lighting conditions. Fully-supervised methods on real data are impossible due to the large amount of data needed. Hence, the current state of the art deep learning models are trained on fully or partially synthetic images. However, document shadow or shading removal results still suffer because: (a) prior methods rely on uniformity of local color statistics, which limit their application on real-scenarios with complex document shapes and textures and; (b) synthetic or hybrid datasets with non-realistic, simulated lighting conditions are used to train the models. In this paper we tackle these problems with our two main contributions. First, a physically constrained learning-based method that directly estimates document reflectance based on intrinsic image formation which generalizes to challenging illumination conditions. Second, a new dataset that clearly improves previous synthetic ones, by adding a large range of realistic shading and diverse multi-illuminant conditions, uniquely customized to deal with documents in-the-wild. The proposed architecture works in a self-supervised manner where only the synthetic texture is used as a weak training signal (obviating the need for very costly ground truth with disentangled versions of shading and reflectance). The proposed approach leads to a significant generalization of document reflectance estimation in real scenes with challenging illumination. We extensively evaluate on the real benchmark datasets available for intrinsic image decomposition and document shadow removal tasks. Our reflectance estimation scheme, when used as a pre-processing step of an OCR pipeline, shows a 26% improvement of character error rate (CER), thus, proving the practical applicability.
Light Direction and Color Estimation from Single Image with Deep Regression
Sep 18, 2020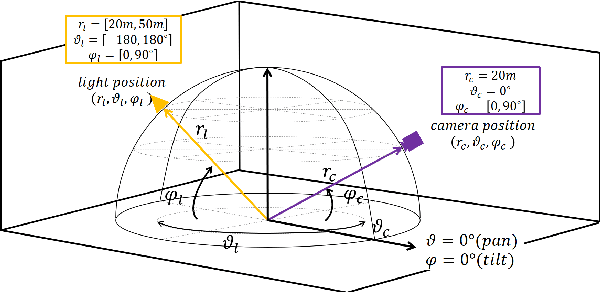
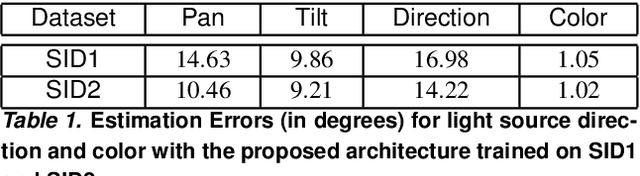
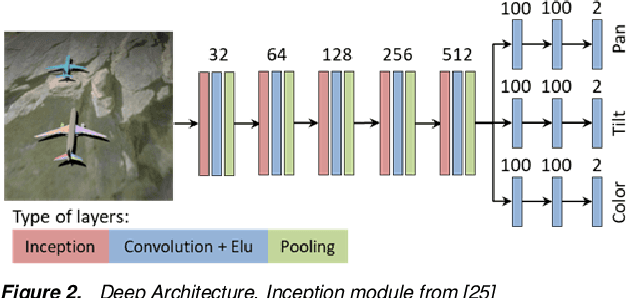
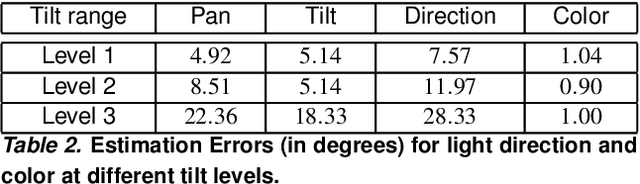
We present a method to estimate the direction and color of the scene light source from a single image. Our method is based on two main ideas: (a) we use a new synthetic dataset with strong shadow effects with similar constraints to the SID dataset; (b) we define a deep architecture trained on the mentioned dataset to estimate the direction and color of the scene light source. Apart from showing good performance on synthetic images, we additionally propose a preliminary procedure to obtain light positions of the Multi-Illumination dataset, and, in this way, we also prove that our trained model achieves good performance when it is applied to real scenes.
Deep intrinsic decomposition trained on surreal scenes yet with realistic light effects
Sep 14, 2020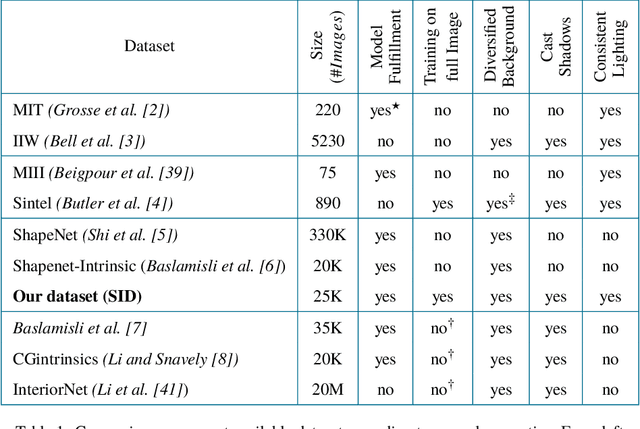

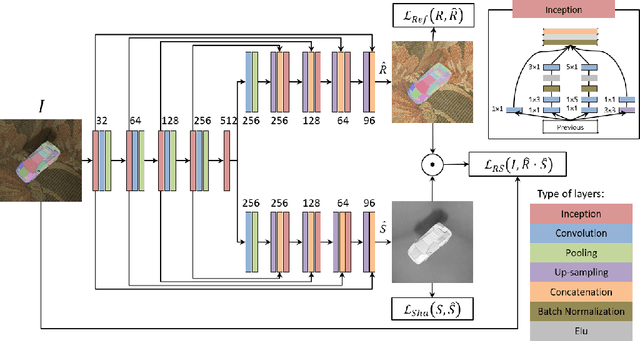
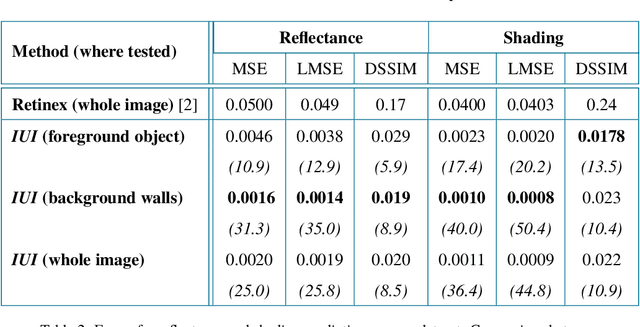
Estimation of intrinsic images still remains a challenging task due to weaknesses of ground-truth datasets, which either are too small or present non-realistic issues. On the other hand, end-to-end deep learning architectures start to achieve interesting results that we believe could be improved if important physical hints were not ignored. In this work, we present a twofold framework: (a) a flexible generation of images overcoming some classical dataset problems such as larger size jointly with coherent lighting appearance; and (b) a flexible architecture tying physical properties through intrinsic losses. Our proposal is versatile, presents low computation time, and achieves state-of-the-art results.
Understanding trained CNNs by indexing neuron selectivity
Feb 01, 2017



The impressive performance and plasticity of convolutional neural networks to solve different vision problems are shadowed by their black-box nature and its consequent lack of full understanding. To reduce this gap we propose to describe the activity of individual neurons by quantifying their inherent selectivity to specific properties. Our approach is based on the definition of feature selectivity indexes that allow the ranking of neurons according to specific properties. Here we report the results of exploring selectivity indexes for: (a) an image feature (color); and (b) an image label (class membership). Our contribution is a framework to seek or classify neurons by indexing on these selectivity properties. It helps to find color selective neurons, such as a red-mushroom neuron in layer conv4 or class selective neurons such as dog-face neurons in layer conv5, and establishes a methodology to derive other selectivity properties. Indexing on neuron selectivity can statistically draw how features and classes are represented through layers at a moment when the size of trained nets is growing and automatic tools to index can be helpful.
Understanding learned CNN features through Filter Decoding with Substitution
Nov 17, 2015
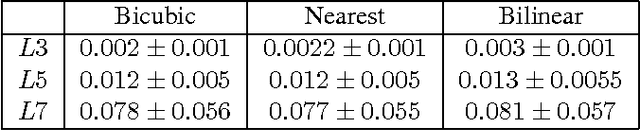
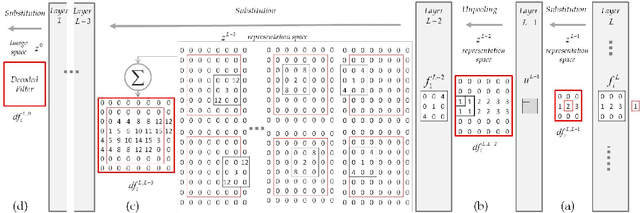
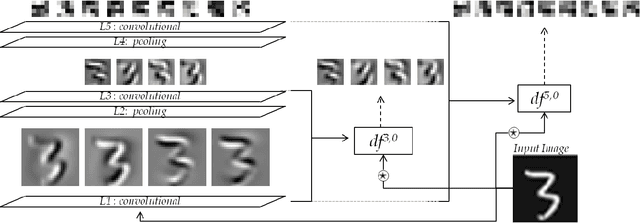
In parallel with the success of CNNs to solve vision problems, there is a growing interest in developing methodologies to understand and visualize the internal representations of these networks. How the responses of a trained CNN encode the visual information is a fundamental question both for computer and human vision research. Image representations provided by the first convolutional layer as well as the resolution change provided by the max-polling operation are easy to understand, however, as soon as a second and further convolutional layers are added in the representation, any intuition is lost. A usual way to deal with this problem has been to define deconvolutional networks that somehow allow to explore the internal representations of the most important activations towards the image space, where deconvolution is assumed as a convolution with the transposed filter. However, this assumption is not the best approximation of an inverse convolution. In this paper we propose a new assumption based on filter substitution to reverse the encoding of a convolutional layer. This provides us with a new tool to directly visualize any CNN single neuron as a filter in the first layer, this is in terms of the image space.