 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Application of Data Mining in the Production Processes
Nov 24, 2020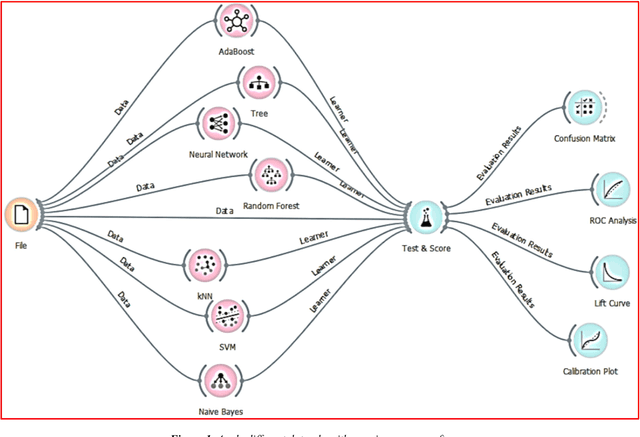
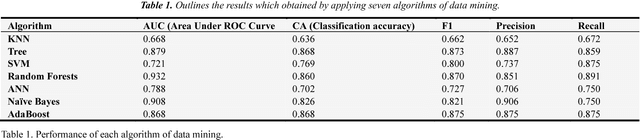
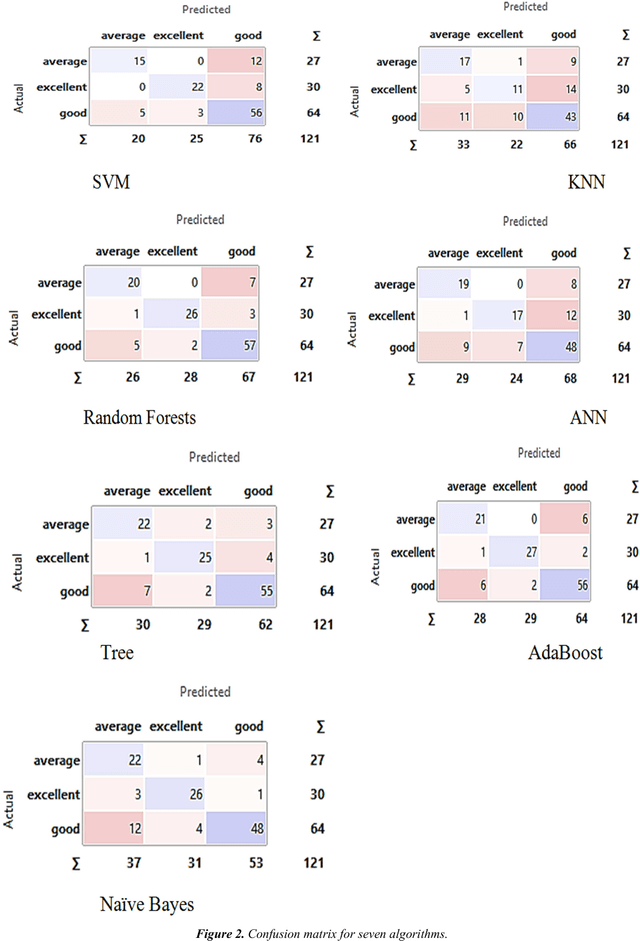
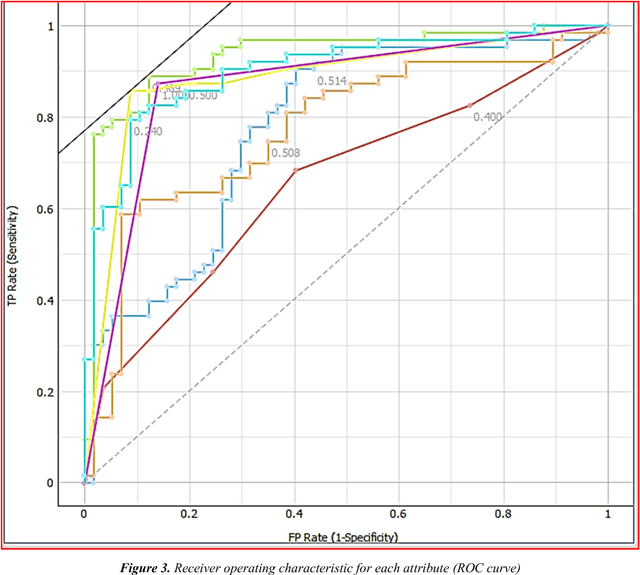
Traditional statistical and measurements are unable to solve all industrial data in the right way and appropriate time. Open markets mean the customers are increased, and production must increase to provide all customer requirements. Nowadays, large data generated daily from different production processes and traditional statistical or limited measurements are not enough to handle all daily data. Improve production and quality need to analyze data and extract the important information about the process how to improve. Data mining applied successfully in the industrial processes and some algorithms such as mining association rules, and decision tree recorded high professional results in different industrial and production fields. The study applied seven algorithms to analyze production data and extract the best result and algorithm in the industry field. KNN, Tree, SVM, Random Forests, ANN, Na\"ive Bayes, and AdaBoost applied to classify data based on three attributes without neglect any variables whether this variable is numerical or categorical. The best results of accuracy and area under the curve (ROC) obtained from Decision tree and its ensemble algorithms (Random Forest and AdaBoost). Thus, a decision tree is an appropriate algorithm to handle manufacturing and production data especially this algorithm can handle numerical and categorical data.
Data Mining Techniques in Predicting Breast Cancer
Nov 22, 2020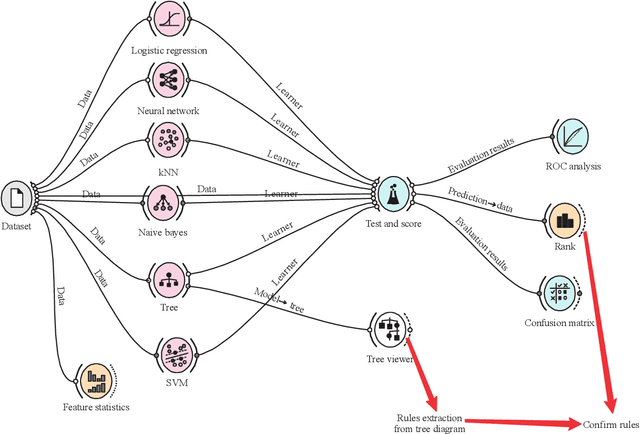
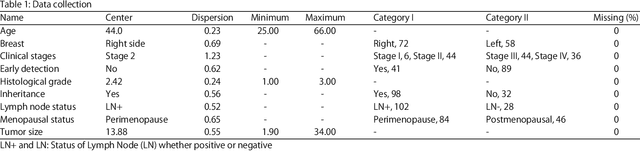
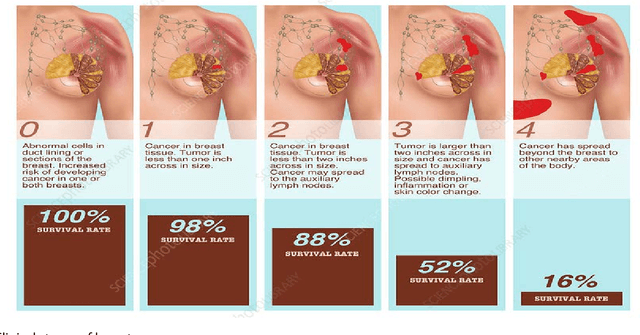

Background and Objective: Breast cancer, which accounts for 23% of all cancers, is threatening the communities of developing countries because of poor awareness and treatment. Early diagnosis helps a lot in the treatment of the disease. The present study conducted in order to improve the prediction process and extract the main causes impacted the breast cancer. Materials and Methods: Data were collected based on eight attributes for 130 Libyan women in the clinical stages infected with this disease. Data mining was used by applying six algorithms to predict disease based on clinical stages. All the algorithms gain high accuracy, but the decision tree provides the highest accuracy-diagram of decision tree utilized to build rules from each leafnode. Ranking variables applied to extract significant variables and support final rules to predict disease. Results: All applied algorithms were gained a high prediction with different accuracies. Rules 1, 3, 4, 5 and 9 provided a pure subset to be confirmed as significant rules. Only five input variables contributed to building rules, but not all variables have a significant impact. Conclusion: Tumor size plays a vital role in constructing all rules with a significant impact. Variables of inheritance, breast side and menopausal status have an insignificant impact in analysis, but they may consider remarkable findings using a different strategy of data analysis.
* 9 pages, 4 figures, paper published in journal