 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVServe: Service-Aware KV Cache Compression for Communication-Efficient Disaggregated LLM Serving
May 13, 2026LLMs are widely adopted in production, pushing inference systems to their limits. Disaggregated LLM serving (e.g., PD separation and KV state disaggregation) improves scalability and cost efficiency, but it also turns KV into an explicit payload crossing network and storage boundaries, making KV a dominant end-to-end bottleneck. Existing KV compression are typically static runtime configurations, despite production service context varies over time in workload mix, bandwidth, and SLO/quality budgets. As a result, a fixed choice can be suboptimal or even increase latency. We present \emph{KVServe}, the first service-aware and adaptive KV communication compression framework for disaggregated LLM serving: KVServe (1) unifies KV compression into a modular strategy space with new components and cross-method recomposition; (2) introduces Bayesian Profiling Engine that efficiently searches this space and distills a 3D Pareto candidate set, reducing $50\times$ offline search overhead; and (3) deploys a Service-Aware Online Controller that combines an analytical latency model with a lightweight bandit to select profiles under constraints and correct offline-to-online mismatch. Integrated into vLLM and evaluated across datasets, models, GPUs and networks, KVServe achieves up to $9.13\times$ JCT speedup in PD-separated serving and up to $32.8\times$ TTFT reduction in KV-disaggregated serving.
CCL-D: A High-Precision Diagnostic System for Slow and Hang Anomalies in Large-Scale Model Training
May 06, 2026As training scales grow, collective communication libraries (CCL) increasingly face anomalies arising from complex interactions among hardware, software, and environmental factors. These anomalies typically manifest as slow/hang communication, the most frequent and time-consuming category to diagnose. However, traditional diagnostic methods remain inaccurate and inefficient, frequently requiring hours or even days for root cause analysis. To address this, we propose CCL-D, a high-precision diagnostic system designed to detect and locate slow/hang anomalies in large-scale distributed training. CCL-D integrates a rank-level real-time probe with an intelligent decision analyzer. The probe measures cross-layer anomaly metrics using a lightweight distributed tracing framework to monitor communication traffic. The analyzer performs automated anomaly detection and root-cause location, precisely identifying the faulty GPU rank. Deployed on a 4,000-GPU cluster over one year, CCL-D achieved near-complete coverage of known slow/hang anomalies and pinpointed affected ranks within 6 minutes-substantially outperforming existing solutions.
TACO: Efficient Communication Compression of Intermediate Tensors for Scalable Tensor-Parallel LLM Training
Apr 27, 2026Handling communication overhead in large-scale tensor-parallel training remains a critical challenge due to the dense, near-zero distributions of intermediate tensors, which exacerbate errors under frequent communication and introduce significant computational overhead during compression. To this end, we propose TACO (Tensor-parallel Adaptive COmmunication compression), a robust FP8-based framework for compressing TP intermediate tensors. First, we employ a data-driven reshaping strategy combined with an Adaptive Scale-Hadamard Transform to enable high-fidelity FP8 quantization, while its Dual-Scale Quantization mechanism ensures numerical stability throughout training. Second, we design a highly fused compression operator to reduce memory traffic and kernel launch overhead, allowing efficient overlap with communication. Finally, we integrate TACO with existing state-of-the-art methods for Data and Pipeline Parallelism to develop a compression-enabled 3D-parallel training framework. Detailed experiments on GPT models and Qwen model demonstrate up to 1.87X end-to-end throughput improvement while maintaining near-lossless accuracy, validating the effectiveness and efficiency of TACO in large-scale training.
Research Paradigm of Materials Science Tetrahedra with Artificial Intelligence
Mar 14, 2026The classical material tetrahedron that represents the Structure-Property-Processing-Performance-Characterization relationship is the most important research paradigm in materials science so far. It has served as a protocol to guide experiments, modeling, and theory to uncover hidden relationships between various aspects of a certain material. This substantially facilitates knowledge accumulation and material discovery with desired functionalities to realize versatile applications. In recent years, with the advent of artificial intelligence (AI) techniques, the attention of AI towards scientific research is soaring. The trials of implementing AI in various disciplines are endless, with great potential to revolutionize the research diagram. Despite the success in natural language processing and computer vision, how to effectively integrate AI with natural science is still a grand challenge, bearing in mind their fundamental differences. Inspired by these observations and limitations, we delve into the current research paradigm dictated by the classical material tetrahedron and propose two new paradigms to stimulate data-driven and AI-augmented research. One tetrahedron focuses on AI for materials science by considering the Matter-Data-Model-Potential-Agent diagram. The other demonstrates AI research by discussing Data-Architecture-Encoding-Optimization-Inference relationships. The crucial ingredients of these frameworks and their connections are discussed, which will likely motivate both scientific thinking refinement and technology advancement. Despite the widespread enthusiasm for chasing AI for science, we must analyze issues rationally to come up with well-defined, resolvable scientific problems in order to better master the power of AI.
MatRIS: Toward Reliable and Efficient Pretrained Machine Learning Interatomic Potentials
Mar 05, 2026Foundation MLIPs demonstrate broad applicability across diverse material systems and have emerged as a powerful and transformative paradigm in chemical and computational materials science. Equivariant MLIPs achieve state-of-the-art accuracy in a wide range of benchmarks by incorporating equivariant inductive bias. However, the reliance on tensor products and high-degree representations makes them computationally costly. This raises a fundamental question: as quantum mechanical-based datasets continue to expand, can we develop a more compact model to thoroughly exploit high-dimensional atomic interactions? In this work, we present MatRIS (\textbf{Mat}erials \textbf{R}epresentation and \textbf{I}nteraction \textbf{S}imulation), an invariant MLIP that introduces attention-based modeling of three-body interactions. MatRIS leverages a novel separable attention mechanism with linear complexity $O(N)$, enabling both scalability and expressiveness. MatRIS delivers accuracy comparable to that of leading equivariant models on a wide range of popular benchmarks (Matbench-Discovery, MatPES, MDR phonon, Molecular dataset, etc). Taking Matbench-Discovery as an example, MatRIS achieves an F1 score of up to 0.847 and attains comparable accuracy at a lower training cost. The work indicates that our carefully designed invariant models can match or exceed the accuracy of equivariant models at a fraction of the cost, shedding light on the development of accurate and efficient MLIPs.
Exploring Landscapes for Better Minima along Valleys
Oct 31, 2025Finding lower and better-generalizing minima is crucial for deep learning. However, most existing optimizers stop searching the parameter space once they reach a local minimum. Given the complex geometric properties of the loss landscape, it is difficult to guarantee that such a point is the lowest or provides the best generalization. To address this, we propose an adaptor "E" for gradient-based optimizers. The adapted optimizer tends to continue exploring along landscape valleys (areas with low and nearly identical losses) in order to search for potentially better local minima even after reaching a local minimum. This approach increases the likelihood of finding a lower and flatter local minimum, which is often associated with better generalization. We also provide a proof of convergence for the adapted optimizers in both convex and non-convex scenarios for completeness. Finally, we demonstrate their effectiveness in an important but notoriously difficult training scenario, large-batch training, where Lamb is the benchmark optimizer. Our testing results show that the adapted Lamb, ALTO, increases the test accuracy (generalization) of the current state-of-the-art optimizer by an average of 2.5% across a variety of large-batch training tasks. This work potentially opens a new research direction in the design of optimization algorithms.
FastCHGNet: Training one Universal Interatomic Potential to 1.5 Hours with 32 GPUs
Dec 30, 2024Graph neural network universal interatomic potentials (GNN-UIPs) have demonstrated remarkable generalization and transfer capabilities in material discovery and property prediction. These models can accelerate molecular dynamics (MD) simulation by several orders of magnitude while maintaining \textit{ab initio} accuracy, making them a promising new paradigm in material simulations. One notable example is Crystal Hamiltonian Graph Neural Network (CHGNet), pretrained on the energies, forces, stresses, and magnetic moments from the MPtrj dataset, representing a state-of-the-art GNN-UIP model for charge-informed MD simulations. However, training the CHGNet model is time-consuming(8.3 days on one A100 GPU) for three reasons: (i) requiring multi-layer propagation to reach more distant atom information, (ii) requiring second-order derivatives calculation to finish weights updating and (iii) the implementation of reference CHGNet does not fully leverage the computational capabilities. This paper introduces FastCHGNet, an optimized CHGNet, with three contributions: Firstly, we design innovative Force/Stress Readout modules to decompose Force/Stress prediction. Secondly, we adopt massive optimizations such as kernel fusion, redundancy bypass, etc, to exploit GPU computation power sufficiently. Finally, we extend CHGNet to support multiple GPUs and propose a load-balancing technique to enhance GPU utilization. Numerical results show that FastCHGNet reduces memory footprint by a factor of 3.59. The final training time of FastCHGNet can be decreased to \textbf{1.53 hours} on 32 GPUs without sacrificing model accuracy.
I/O Lower Bounds for Auto-tuning of Convolutions in CNNs
Dec 31, 2020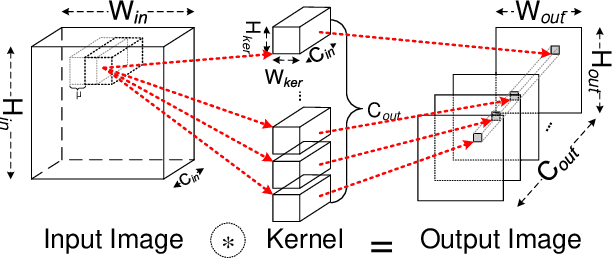
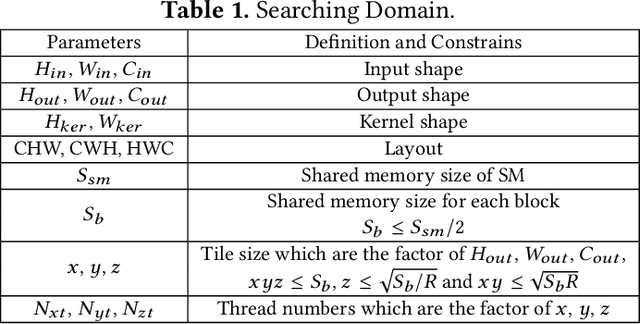
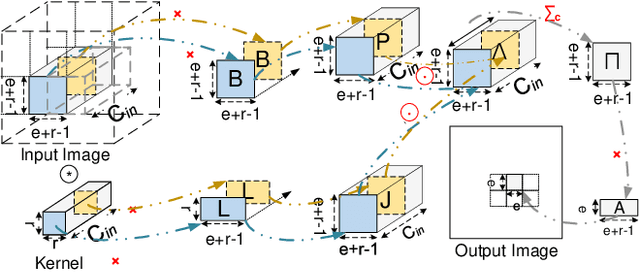

Convolution is the most time-consuming part in the computation of convolutional neural networks (CNNs), which have achieved great successes in numerous applications. Due to the complex data dependency and the increase in the amount of model samples, the convolution suffers from high overhead on data movement (i.e., memory access). This work provides comprehensive analysis and methodologies to minimize the communication for the convolution in CNNs. With an in-depth analysis of the recent I/O complexity theory under the red-blue game model, we develop a general I/O lower bound theory for a composite algorithm which consists of several different sub-computations. Based on the proposed theory, we establish the data movement lower bound results of two representative convolution algorithms in CNNs, namely the direct convolution and Winograd algorithm. Next, derived from I/O lower bound results, we design the near I/O-optimal dataflow strategies for the two main convolution algorithms by fully exploiting the data reuse. Furthermore, in order to push the envelope of performance of the near I/O-optimal dataflow strategies further, an aggressive design of auto-tuning based on I/O lower bounds, is proposed to search an optimal parameter configuration for the direct convolution and Winograd algorithm on GPU, such as the number of threads and the size of shared memory used in each thread block. Finally, experiment evaluation results on the direct convolution and Winograd algorithm show that our dataflow strategies with the auto-tuning approach can achieve about 3.32x performance speedup on average over cuDNN. In addition, compared with TVM, which represents the state-of-the-art technique for auto-tuning, not only our auto-tuning method based on I/O lower bounds can find the optimal parameter configuration faster, but also our solution has higher performance than the optimal solution provided by TVM.