 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Algorithms for Solving Nonlinear Binary Optimization Problems in Robust Causal Inference
Dec 22, 2020

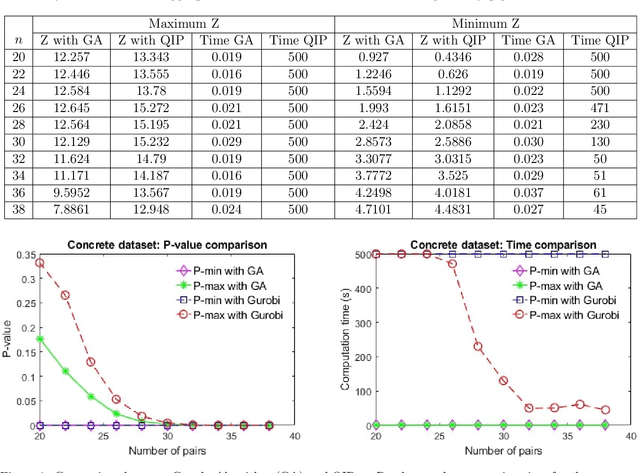

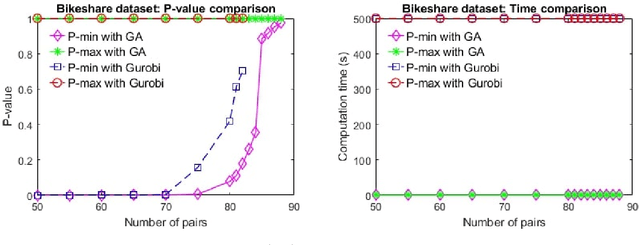
Identifying cause-effect relation among variables is a key step in the decision-making process. While causal inference requires randomized experiments, researchers and policymakers are increasingly using observational studies to test causal hypotheses due to the wide availability of observational data and the infeasibility of experiments. The matching method is the most used technique to make causal inference from observational data. However, the pair assignment process in one-to-one matching creates uncertainty in the inference because of different choices made by the experimenter. Recently, discrete optimization models are proposed to tackle such uncertainty. Although a robust inference is possible with discrete optimization models, they produce nonlinear problems and lack scalability. In this work, we propose greedy algorithms to solve the robust causal inference test instances from observational data with continuous outcomes. We propose a unique framework to reformulate the nonlinear binary optimization problems as feasibility problems. By leveraging the structure of the feasibility formulation, we develop greedy schemes that are efficient in solving robust test problems. In many cases, the proposed algorithms achieve global optimal solution. We perform experiments on three real-world datasets to demonstrate the effectiveness of the proposed algorithms and compare our result with the state-of-the-art solver. Our experiments show that the proposed algorithms significantly outperform the exact method in terms of computation time while achieving the same conclusion for causal tests. Both numerical experiments and complexity analysis demonstrate that the proposed algorithms ensure the scalability required for harnessing the power of big data in the decision-making process.
Maximum a posteriori signal recovery for optical coherence tomography angiography image generation and denoising
Oct 29, 2020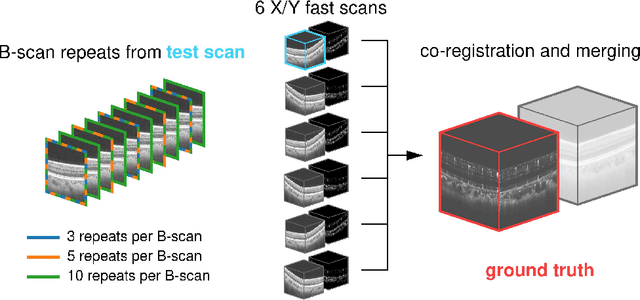
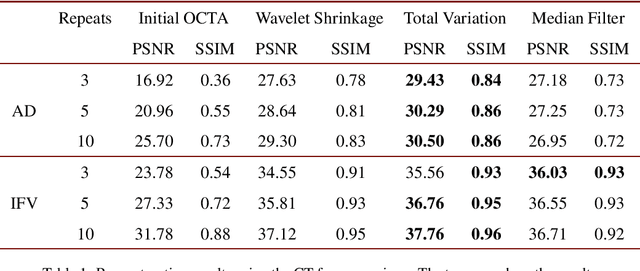
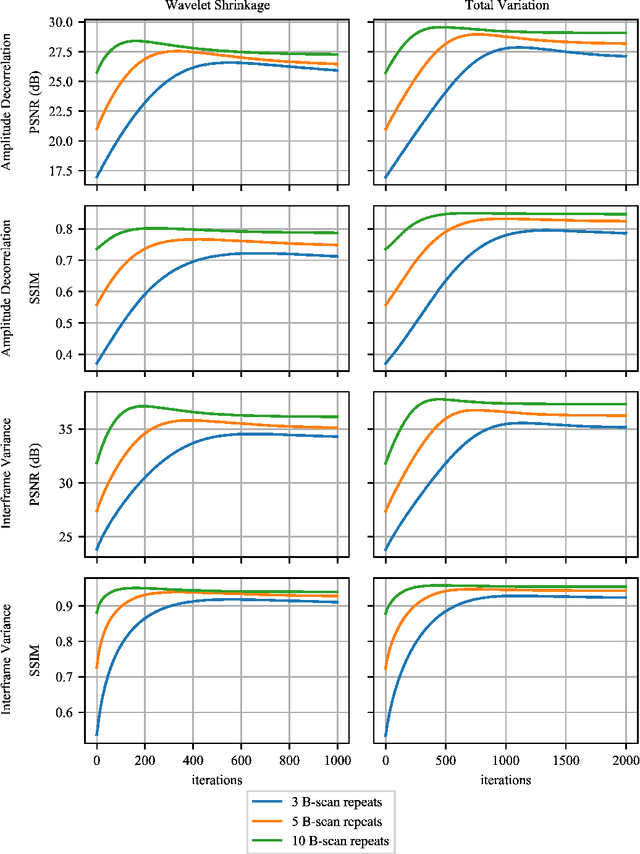

Optical coherence tomography angiography (OCTA) is a novel and clinically promising imaging modality to image retinal and sub-retinal vasculature. Based on repeated optical coherence tomography (OCT) scans, intensity changes are observed over time and used to compute OCTA image data. OCTA data are prone to noise and artifacts caused by variations in flow speed and patient movement. We propose a novel iterative maximum a posteriori signal recovery algorithm in order to generate OCTA volumes with reduced noise and increased image quality. This algorithm is based on previous work on probabilistic OCTA signal models and maximum likelihood estimates. Reconstruction results using total variation minimization and wavelet shrinkage for regularization were compared against an OCTA ground truth volume, merged from six co-registered single OCTA volumes. The results show a significant improvement in peak signal-to-noise ratio and structural similarity. The presented algorithm brings together OCTA image generation and Bayesian statistics and can be developed into new OCTA image generation and denoising algorithms.
Exploitation of Channel-Learning for Enhancing 5G Blind Beam Index Detection
Dec 07, 2020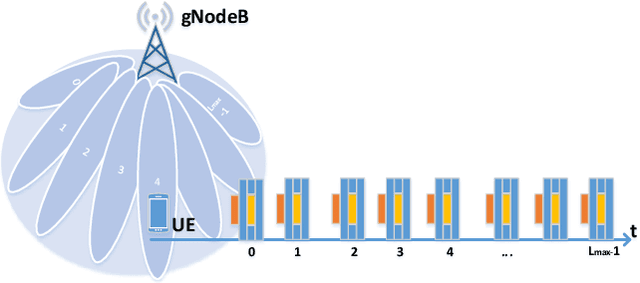
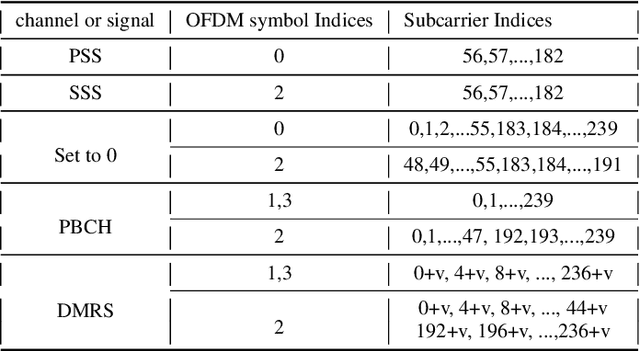
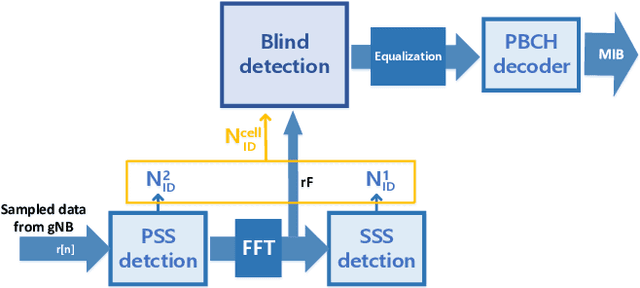

Proliferation of 5G devices and services has driven the demand for wide-scale enhancements ranging from data rate, reliability, and compatibility to sustain the ever increasing growth of the telecommunication industry. In this regard, this work investigates how machine learning technology can improve the performance of 5G cell and beam index search in practice. The cell search is an essential function for a User Equipment (UE) to be initially associated with a base station, and is also important to further maintain the wireless connection. Unlike the former generation cellular systems, the 5G UE faces with an additional challenge to detect suitable beams as well as the cell identities in the cell search procedures. Herein, we propose and implement new channel-learning schemes to enhance the performance of 5G beam index detection. The salient point lies in the use of machine learning models and softwarization for practical implementations in a system level. We develop the proposed channel-learning scheme including algorithmic procedures and corroborative system structure for efficient beam index detection. We also implement a real-time operating 5G testbed based on the off-the-shelf Software Defined Radio (SDR) platform and conduct intensive experiments with commercial 5G base stations. The experimental results indicate that the proposed channel-learning schemes outperform the conventional correlation-based scheme in real 5G channel environments.
Fast Hybrid Cascade for Voxel-based 3D Object Classification
Nov 09, 2020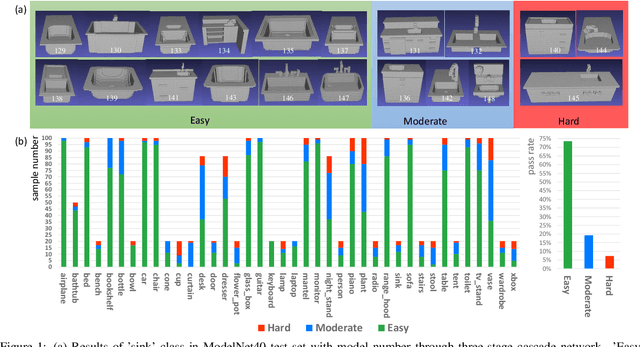
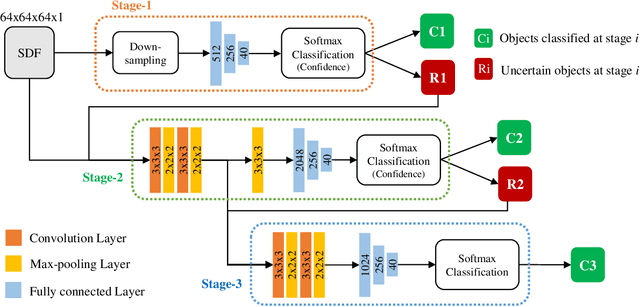

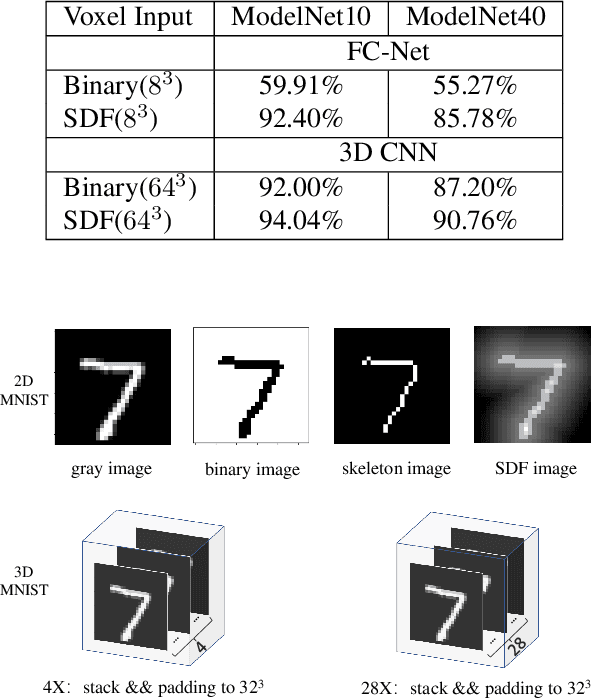
Voxel-based 3D object classification has been frequently studied in recent years. The previous methods often directly convert the classic 2D convolution into a 3D form applied to an object with binary voxel representation. In this paper, we investigate the reason why binary voxel representation is not very suitable for 3D convolution and how to simultaneously improve the performance both in accuracy and speed. We show that by giving each voxel a signed distance value, the accuracy will gain about 30% promotion compared with binary voxel representation using a two-layer fully connected network. We then propose a fast fully connected and convolution hybrid cascade network for voxel-based 3D object classification. This threestage cascade network can divide 3D models into three categories: easy, moderate and hard. Consequently, the mean inference time (0.3ms) can speedup about 5x and 2x compared with the state-of-the-art point cloud and voxel based methods respectively, while achieving the highest accuracy in the latter category of methods (92%). Experiments with ModelNet andMNIST verify the performance of the proposed hybrid cascade network.
Emulation as an Accurate Alternative to Interpolation in Sampling Radiative Transfer Codes
Dec 07, 2020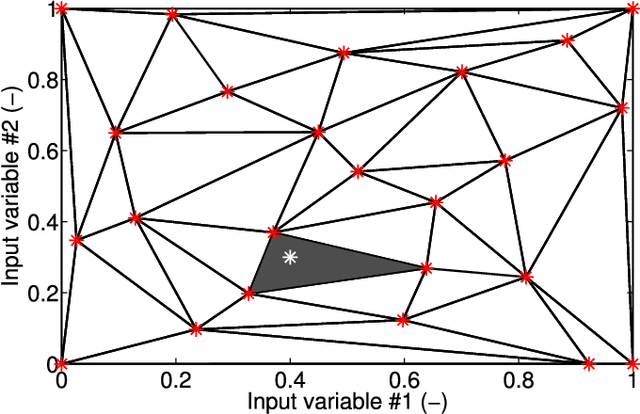
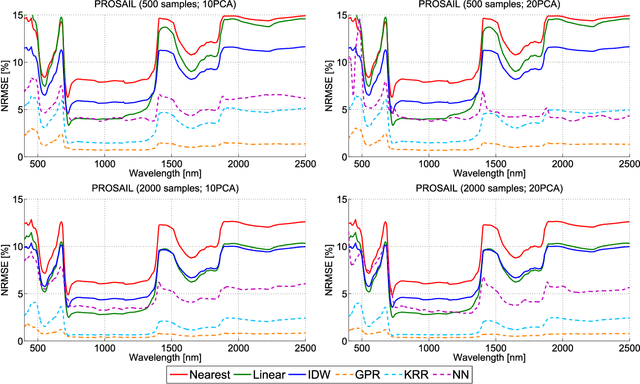
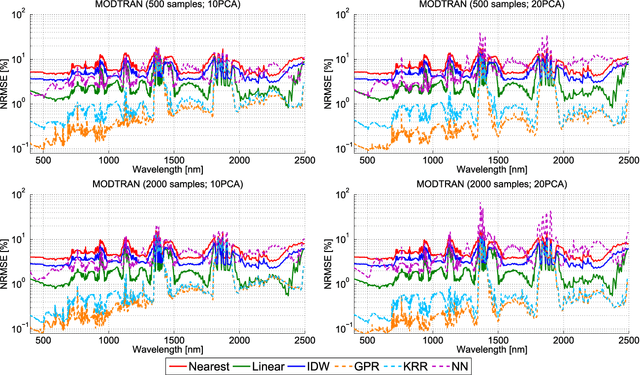
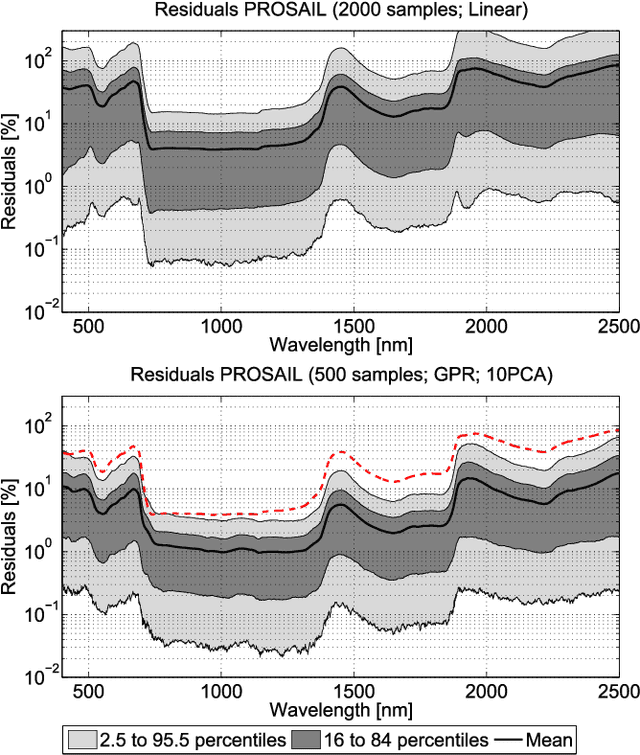
Computationally expensive Radiative Transfer Models (RTMs) are widely used} to realistically reproduce the light interaction with the Earth surface and atmosphere. Because these models take long processing time, the common practice is to first generate a sparse look-up table (LUT) and then make use of interpolation methods to sample the multi-dimensional LUT input variable space. However, the question arise whether common interpolation methods perform most accurate. As an alternative to interpolation, this work proposes to use emulation, i.e., approximating the RTM output by means of statistical learning. Two experiments were conducted to assess the accuracy in delivering spectral outputs using interpolation and emulation: (1) at canopy level, using PROSAIL; and (2) at top-of-atmosphere level, using MODTRAN. Various interpolation (nearest-neighbour, inverse distance weighting, piece-wice linear) and emulation (Gaussian process regression (GPR), kernel ridge regression, neural networks) methods were evaluated against a dense reference LUT. In all experiments, the emulation methods clearly produced more accurate output spectra than classical interpolation methods. GPR emulation performed up to ten times more accurately than the best performing interpolation method, and this with a speed that is competitive with the faster interpolation methods. It is concluded that emulation can function as a fast and more accurate alternative to commonly used interpolation methods for reconstructing RTM spectral data.
All-in-Focus Iris Camera With a Great Capture Volume
Nov 19, 2020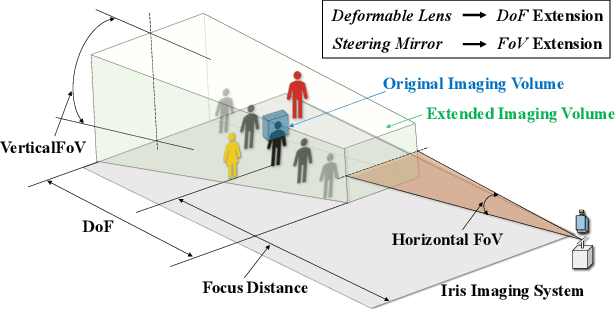
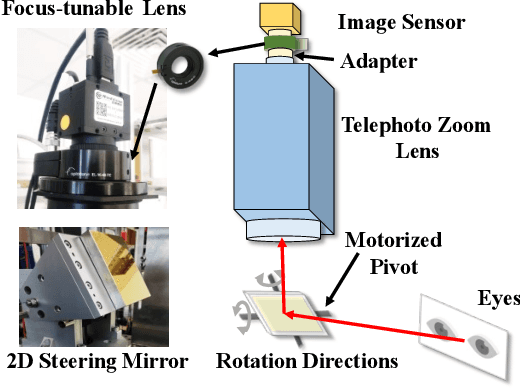
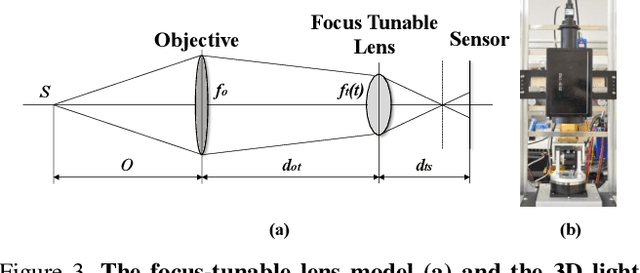
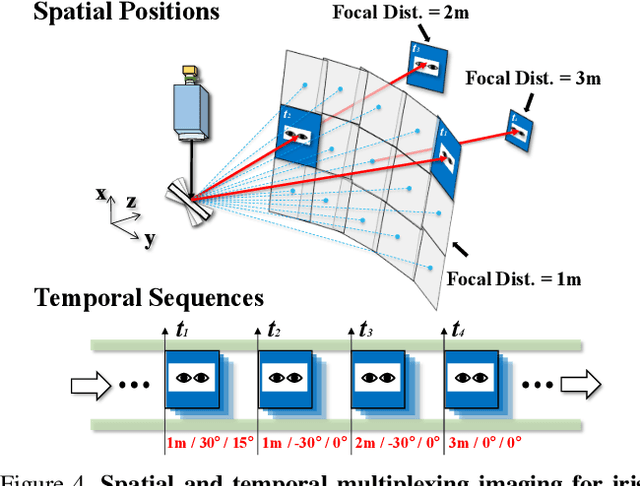
Imaging volume of an iris recognition system has been restricting the throughput and cooperation convenience in biometric applications. Numerous improvement trials are still impractical to supersede the dominant fixed-focus lens in stand-off iris recognition due to incremental performance increase and complicated optical design. In this study, we develop a novel all-in-focus iris imaging system using a focus-tunable lens and a 2D steering mirror to greatly extend capture volume by spatiotemporal multiplexing method. Our iris imaging depth of field extension system requires no mechanical motion and is capable to adjust the focal plane at extremely high speed. In addition, the motorized reflection mirror adaptively steers the light beam to extend the horizontal and vertical field of views in an active manner. The proposed all-in-focus iris camera increases the depth of field up to 3.9 m which is a factor of 37.5 compared with conventional long focal lens. We also experimentally demonstrate the capability of this 3D light beam steering imaging system in real-time multi-person iris refocusing using dynamic focal stacks and the potential of continuous iris recognition for moving participants.
Dynamic Formation Reshaping Based on Point Set Registration in a Swarm of Drones
Oct 29, 2020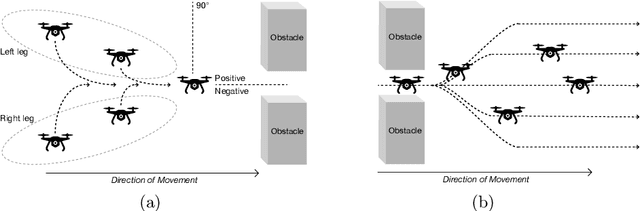
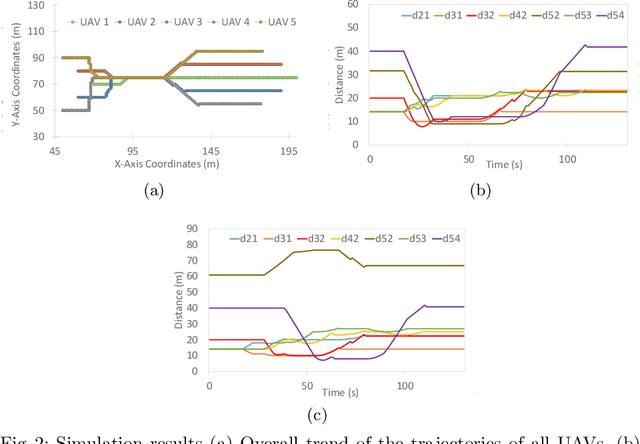
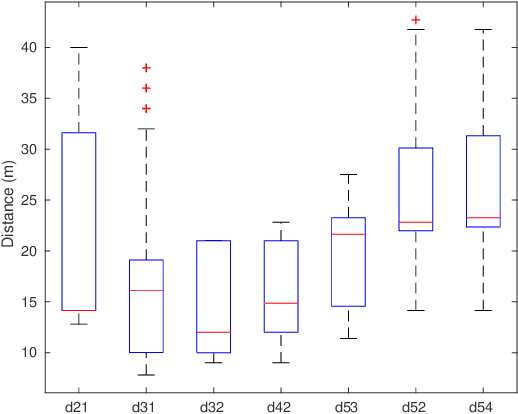
This work focuses on the formation reshaping in an optimized manner in autonomous swarm of drones. Here, the two main problems are: 1) how to break and reshape the initial formation in an optimal manner, and 2) how to do such reformation while minimizing the overall deviation of the drones and the overall time, i.e., without slowing down. To address the first problem, we introduce a set of routines for the drones/agents to follow while reshaping to a secondary formation shape. And the second problem is resolved by utilizing the temperature function reduction technique, originally used in the point set registration process. The goal is to be able to dynamically reform the shape of multi-agent based swarm in near-optimal manner while going through narrow openings between, for instance obstacles, and then bringing the agents back to their original shape after passing through the narrow passage using point set registration technique.
Segmentation of the cortical plate in fetal brain MRI with a topological loss
Oct 23, 2020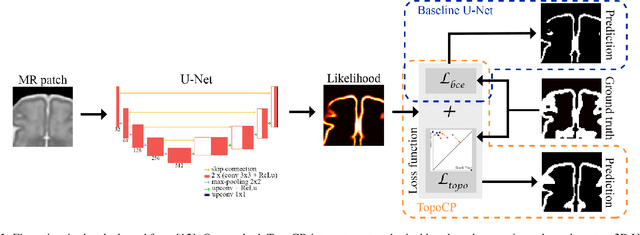

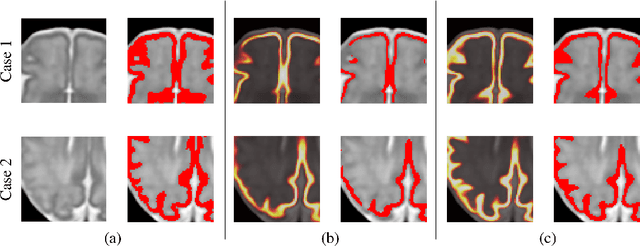

The fetal cortical plate undergoes drastic morphological changes throughout early in utero development that can be observed using magnetic resonance (MR) imaging. An accurate MR image segmentation, and more importantly a topologically correct delineation of the cortical gray matter, is a key baseline to perform further quantitative analysis of brain development. In this paper, we propose for the first time the integration of a topological constraint, as an additional loss function, to enhance the morphological consistency of a deep learning-based segmentation of the fetal cortical plate. We quantitatively evaluate our method on 18 fetal brain atlases ranging from 21 to 38 weeks of gestation, showing the significant benefits of our method through all gestational ages as compared to a baseline method. Furthermore, qualitative evaluation by three different experts on 130 randomly selected slices from 26 clinical MRIs evidences the out-performance of our method independently of the MR reconstruction quality.
Rescuing neural spike train models from bad MLE
Oct 23, 2020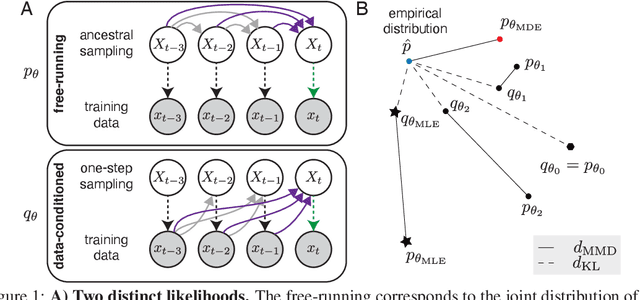
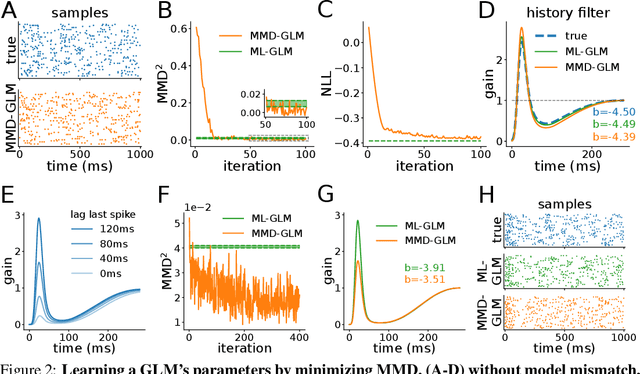
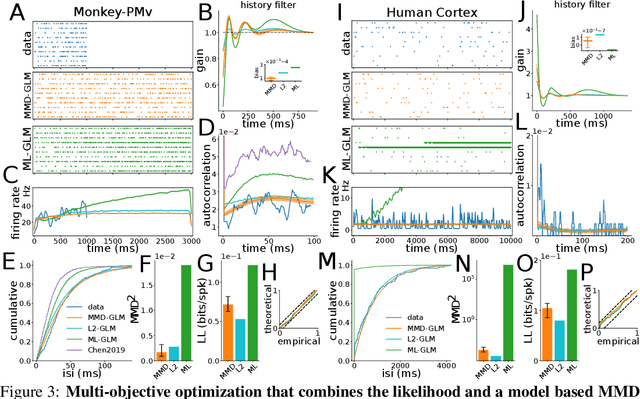
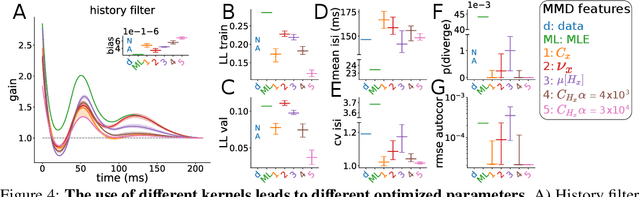
The standard approach to fitting an autoregressive spike train model is to maximize the likelihood for one-step prediction. This maximum likelihood estimation (MLE) often leads to models that perform poorly when generating samples recursively for more than one time step. Moreover, the generated spike trains can fail to capture important features of the data and even show diverging firing rates. To alleviate this, we propose to directly minimize the divergence between neural recorded and model generated spike trains using spike train kernels. We develop a method that stochastically optimizes the maximum mean discrepancy induced by the kernel. Experiments performed on both real and synthetic neural data validate the proposed approach, showing that it leads to well-behaving models. Using different combinations of spike train kernels, we show that we can control the trade-off between different features which is critical for dealing with model-mismatch.
GloVeInit at SemEval-2020 Task 1: Using GloVe Vector Initialization for Unsupervised Lexical Semantic Change Detection
Jul 10, 2020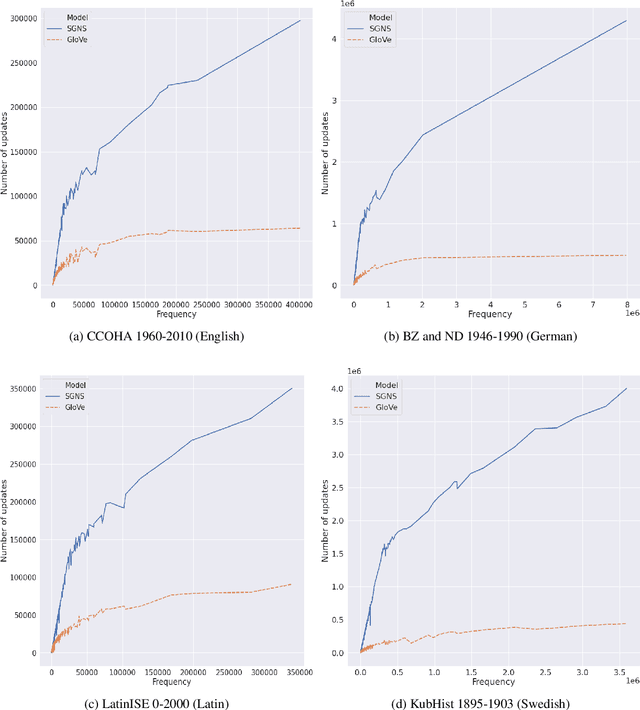
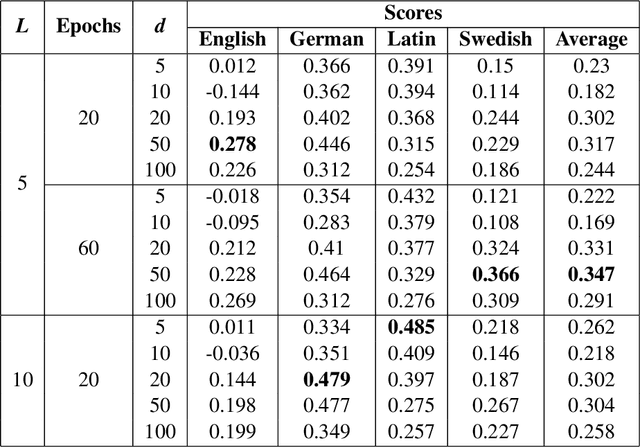
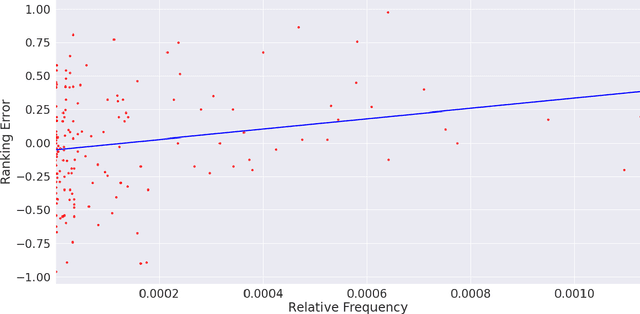
This paper presents a vector initialization approach for the SemEval2020 Task 1: Unsupervised Lexical Semantic Change Detection. Given two corpora belonging to different time periods and a set of target words, this task requires us to classify whether a word gained or lost a sense over time (subtask 1) and to rank them on the basis of the changes in their word senses (subtask 2). The proposed approach is based on using Vector Initialization method to align GloVe embeddings. The idea is to consecutively train GloVe embeddings for both corpora, while using the first model to initialize the second one. This paper is based on the hypothesis that GloVe embeddings are more suited for the Vector Initialization method than SGNS embeddings. It presents an intuitive reasoning behind this hypothesis, and also talks about the impact of various factors and hyperparameters on the performance of the proposed approach. Our model ranks 13th and 10th among 33 teams in the two subtasks. The implementation has been shared publicly.