 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating 5G Synchronization Signal Timing Offset Estimation Using Dual-Rate Sampling
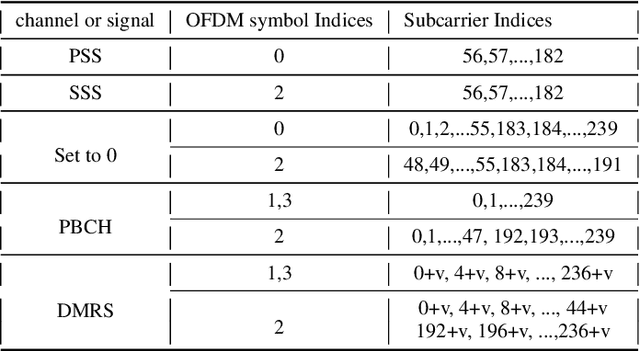
Mar 31, 2026Cell search engineers face significant challenge in reducing computation time to meet the requirements for fast initial access and radio link recovery. Since the majority of cell search time is consumed by Primary Synchronization Signal (PSS) detection, reducing the computational burden of this step is critical for shortening the overall procedure. This paper proposes a novel timing offset estimation scheme designed to accelerate 5G cell search. Leveraging the 5G Synchronization Signal Block (SSB) structure, the proposed scheme employs a two-step estimation process using dual-rate sampling. This approach effectively reduces the PSS detection search space without compromising the performance of subsequent processes. Performance evaluations in practical system and channel environments demonstrate that the proposed scheme reduces the cell search procedure time by 68\% compared to the baseline, while maintaining Physical Broadcast CHannel (PBCH) decoding performance.
Design of Orthogonal Phase of Arrival Positioning Scheme Based on 5G PRS and Optimization of TOA Performance
Oct 30, 2025This study analyzes the performance of positioning techniques based on configuration changes of 5G New Radio signals. In 5G networks, a terminal position is determined from the Time of Arrival of Positioning Reference Signals transmitted by base stations. We propose an algorithm that improves TOA accuracy under low sampling rate constraints and implement 5G PRS for positioning in a software defined modem. We also examine how flexible time frequency resource allocation of PRS affects TOA estimation accuracy and discuss optimal PRS configurations for a given signal environment.
Impact of Regularization on Calibration and Robustness: from the Representation Space Perspective
Oct 05, 2024Recent studies have shown that regularization techniques using soft labels, e.g., label smoothing, Mixup, and CutMix, not only enhance image classification accuracy but also improve model calibration and robustness against adversarial attacks. However, the underlying mechanisms of such improvements remain underexplored. In this paper, we offer a novel explanation from the perspective of the representation space (i.e., the space of the features obtained at the penultimate layer). Our investigation first reveals that the decision regions in the representation space form cone-like shapes around the origin after training regardless of the presence of regularization. However, applying regularization causes changes in the distribution of features (or representation vectors). The magnitudes of the representation vectors are reduced and subsequently the cosine similarities between the representation vectors and the class centers (minimal loss points for each class) become higher, which acts as a central mechanism inducing improved calibration and robustness. Our findings provide new insights into the characteristics of the high-dimensional representation space in relation to training and regularization using soft labels.
Curved Representation Space of Vision Transformers
Oct 11, 2022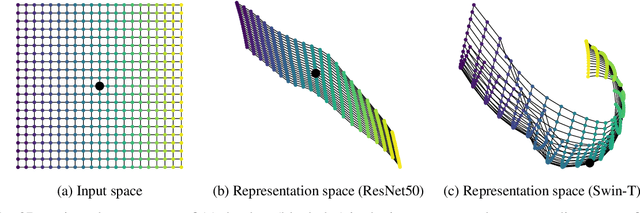
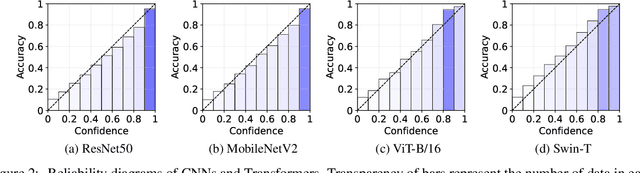
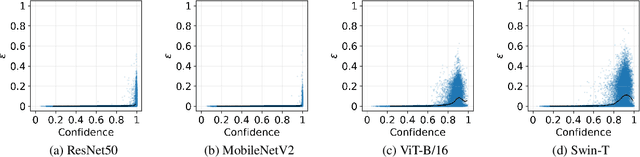
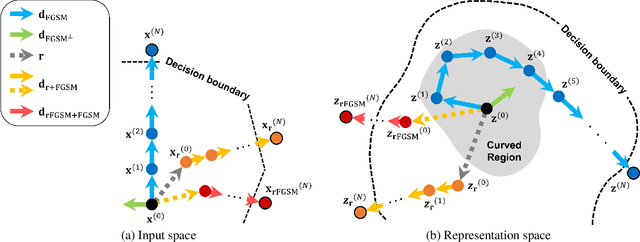
Neural networks with self-attention (a.k.a. Transformers) like ViT and Swin have emerged as a better alternative to traditional convolutional neural networks (CNNs) for computer vision tasks. However, our understanding of how the new architecture works is still limited. In this paper, we focus on the phenomenon that Transformers show higher robustness against corruptions than CNNs, while not being overconfident (in fact, we find Transformers are actually underconfident). This is contrary to the intuition that robustness increases with confidence. We resolve this contradiction by investigating how the output of the penultimate layer moves in the representation space as the input data moves within a small area. In particular, we show the following. (1) While CNNs exhibit fairly linear relationship between the input and output movements, Transformers show nonlinear relationship for some data. For those data, the output of Transformers moves in a curved trajectory as the input moves linearly. (2) When a data is located in a curved region, it is hard to move it out of the decision region since the output moves along a curved trajectory instead of a straight line to the decision boundary, resulting in high robustness of Transformers. (3) If a data is slightly modified to jump out of the curved region, the movements afterwards become linear and the output goes to the decision boundary directly. Thus, Transformers can be attacked easily after a small random jump and the perturbation in the final attacked data remains imperceptible, i.e., there does exist a decision boundary near the data. This also explains the underconfident prediction of Transformers. (4) The curved regions in the representation space start to form at an early training stage and grow throughout the training course. Some data are trapped in the regions, obstructing Transformers from reducing the training loss.
Amicable Aid: Turning Adversarial Attack to Benefit Classification
Dec 09, 2021
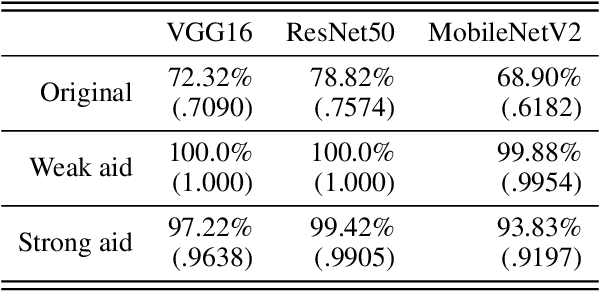
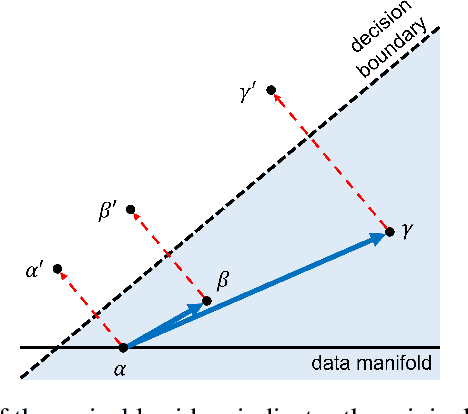
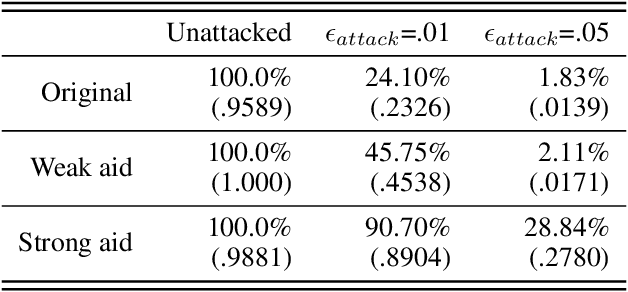
While adversarial attacks on deep image classification models pose serious security concerns in practice, this paper suggests a novel paradigm where the concept of adversarial attacks can benefit classification performance, which we call amicable aid. We show that by taking the opposite search direction of perturbation, an image can be converted to another yielding higher confidence by the classification model and even a wrongly classified image can be made to be correctly classified. Furthermore, with a large amount of perturbation, an image can be made unrecognizable by human eyes, while it is correctly recognized by the model. The mechanism of the amicable aid is explained in the viewpoint of the underlying natural image manifold. We also consider universal amicable perturbations, i.e., a fixed perturbation can be applied to multiple images to improve their classification results. While it is challenging to find such perturbations, we show that making the decision boundary as perpendicular to the image manifold as possible via training with modified data is effective to obtain a model for which universal amicable perturbations are more easily found. Finally, we discuss several application scenarios where the amicable aid can be useful, including secure image communication, privacy-preserving image communication, and protection against adversarial attacks.
Designing a Robust Carrier Frequency Offset Estimation Scheme for Meeting Target Decoding Performance in an OFDM System
Jul 19, 2021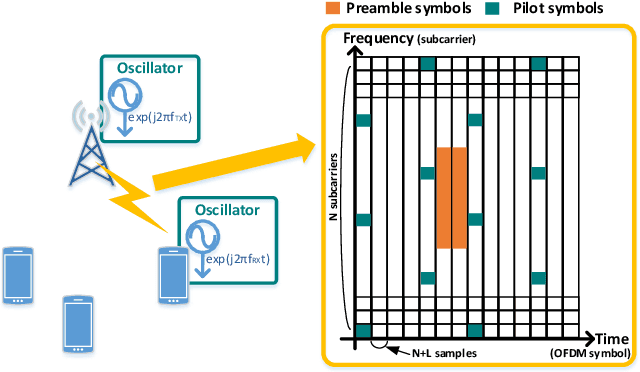
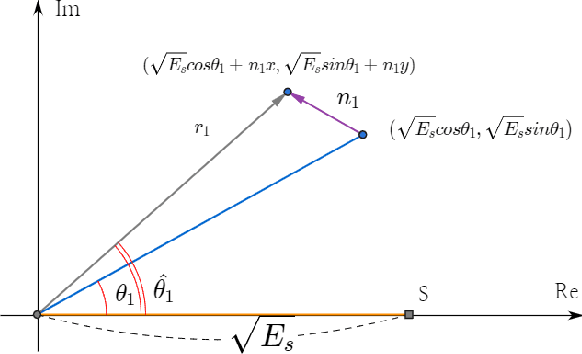
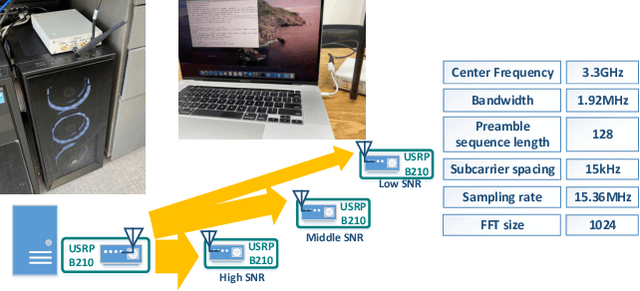
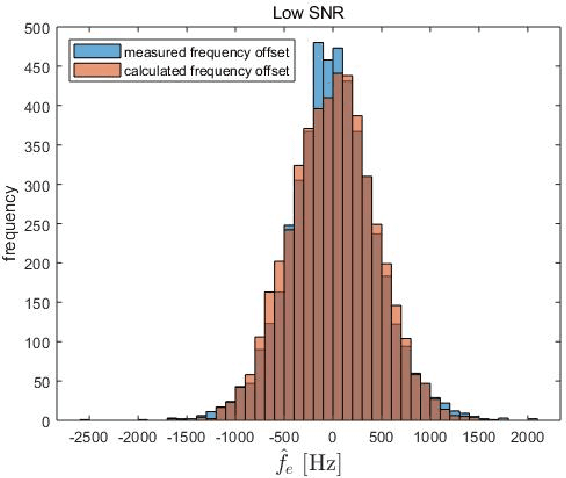
In a target communication system, a delicately designed frequency offset estimation scheme is required to meet certain decoding performance. In this paper, we proposed at wo-step estimation scheme, coarse and residual, with different value of an time interval parameter. A result of RF conduction test shows that the proposed method has an 1dB gain of SNR compared to coarse-only estimator. A result of the commercial test also indicates the proposed method outperforms coarse-only estimator especially in low SNR condition.
Exploitation of Channel-Learning for Enhancing 5G Blind Beam Index Detection
Dec 07, 2020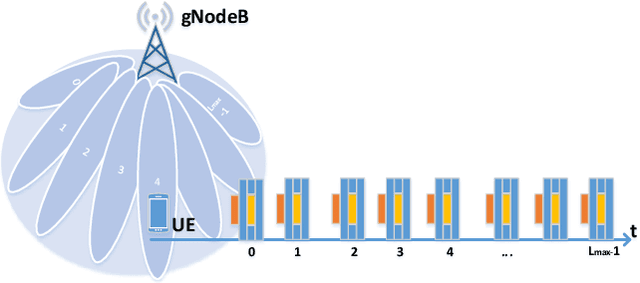
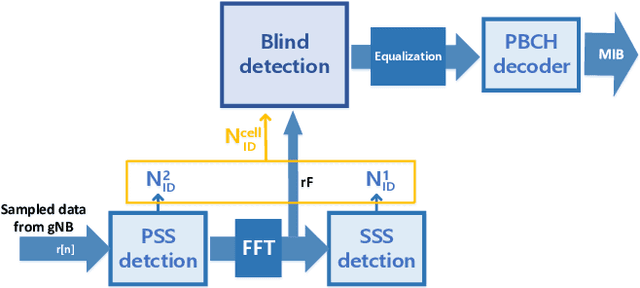

Proliferation of 5G devices and services has driven the demand for wide-scale enhancements ranging from data rate, reliability, and compatibility to sustain the ever increasing growth of the telecommunication industry. In this regard, this work investigates how machine learning technology can improve the performance of 5G cell and beam index search in practice. The cell search is an essential function for a User Equipment (UE) to be initially associated with a base station, and is also important to further maintain the wireless connection. Unlike the former generation cellular systems, the 5G UE faces with an additional challenge to detect suitable beams as well as the cell identities in the cell search procedures. Herein, we propose and implement new channel-learning schemes to enhance the performance of 5G beam index detection. The salient point lies in the use of machine learning models and softwarization for practical implementations in a system level. We develop the proposed channel-learning scheme including algorithmic procedures and corroborative system structure for efficient beam index detection. We also implement a real-time operating 5G testbed based on the off-the-shelf Software Defined Radio (SDR) platform and conduct intensive experiments with commercial 5G base stations. The experimental results indicate that the proposed channel-learning schemes outperform the conventional correlation-based scheme in real 5G channel environments.