 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Risk Management Framework for Machine Learning Security
Dec 09, 2020
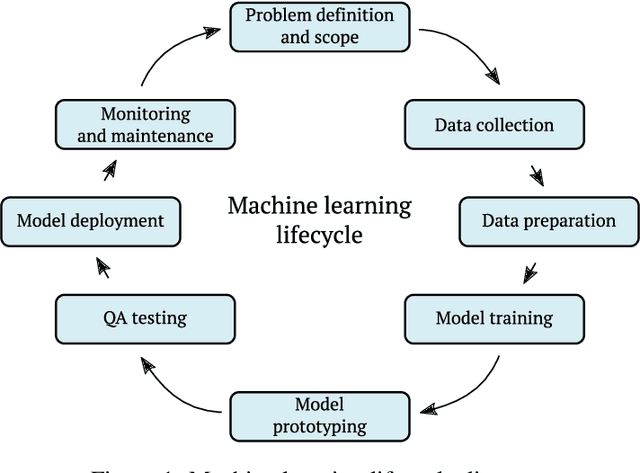
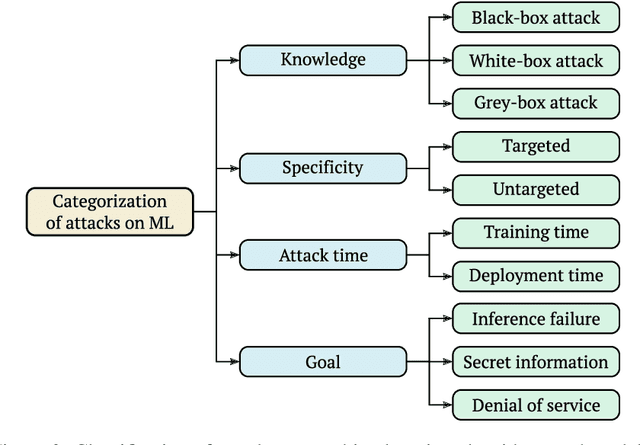
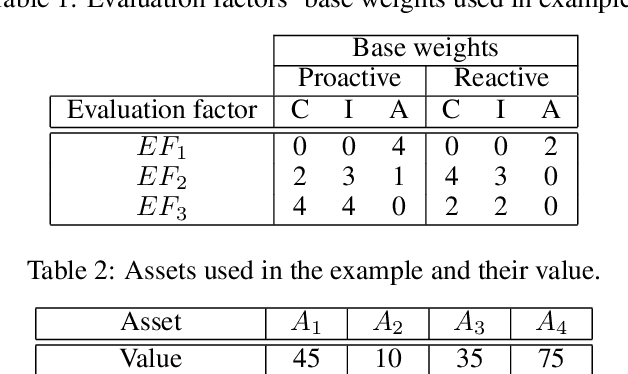
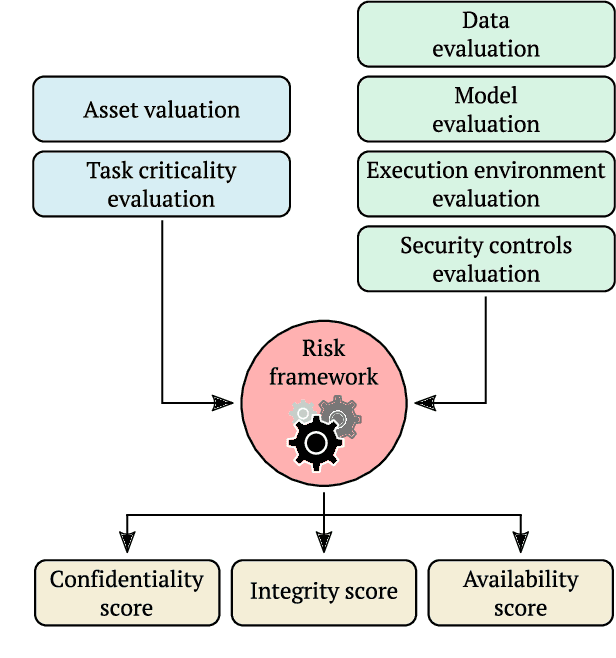
Adversarial attacks for machine learning models have become a highly studied topic both in academia and industry. These attacks, along with traditional security threats, can compromise confidentiality, integrity, and availability of organization's assets that are dependent on the usage of machine learning models. While it is not easy to predict the types of new attacks that might be developed over time, it is possible to evaluate the risks connected to using machine learning models and design measures that help in minimizing these risks. In this paper, we outline a novel framework to guide the risk management process for organizations reliant on machine learning models. First, we define sets of evaluation factors (EFs) in the data domain, model domain, and security controls domain. We develop a method that takes the asset and task importance, sets the weights of EFs' contribution to confidentiality, integrity, and availability, and based on implementation scores of EFs, it determines the overall security state in the organization. Based on this information, it is possible to identify weak links in the implemented security measures and find out which measures might be missing completely. We believe our framework can help in addressing the security issues related to usage of machine learning models in organizations and guide them in focusing on the adequate security measures to protect their assets.
A non-alternating graph hashing algorithm for large scale image search
Dec 24, 2020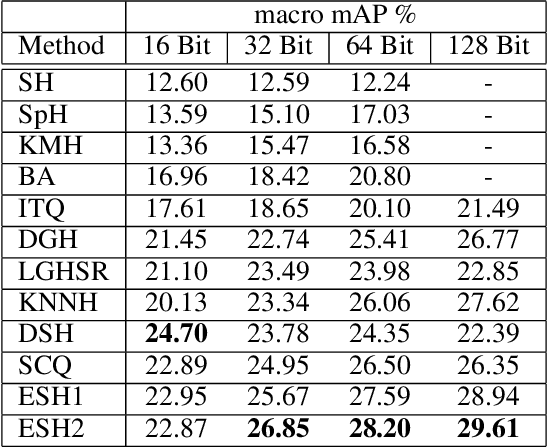
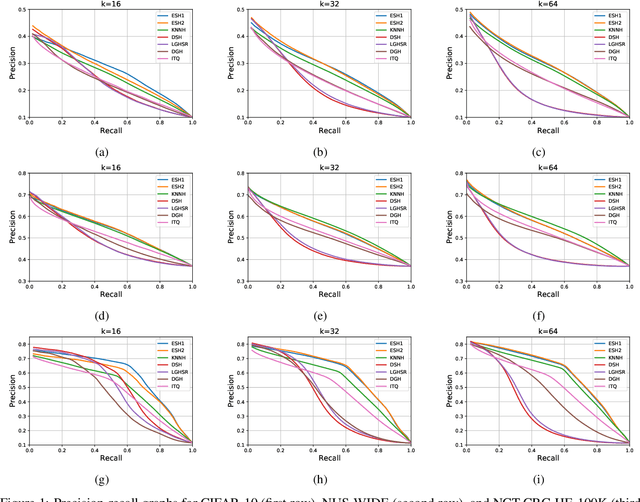
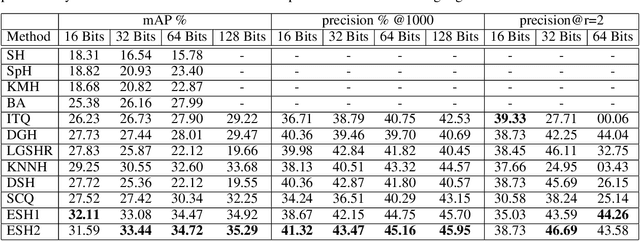
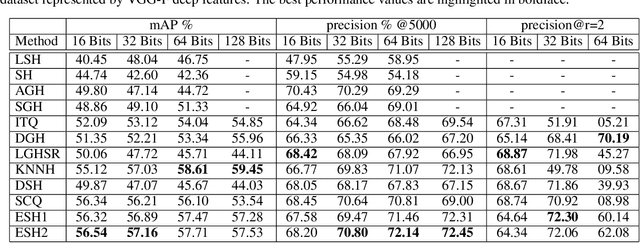
In the era of big data, methods for improving memory and computational efficiency have become crucial for successful deployment of technologies. Hashing is one of the most effective approaches to deal with computational limitations that come with big data. One natural way for formulating this problem is spectral hashing that directly incorporates affinity to learn binary codes. However, due to binary constraints, the optimization becomes intractable. To mitigate this challenge, different relaxation approaches have been proposed to reduce the computational load of obtaining binary codes and still attain a good solution. The problem with all existing relaxation methods is resorting to one or more additional auxiliary variables to attain high quality binary codes while relaxing the problem. The existence of auxiliary variables leads to coordinate descent approach which increases the computational complexity. We argue that introducing these variables is unnecessary. To this end, we propose a novel relaxed formulation for spectral hashing that adds no additional variables to the problem. Furthermore, instead of solving the problem in original space where number of variables is equal to the data points, we solve the problem in a much smaller space and retrieve the binary codes from this solution. This trick reduces both the memory and computational complexity at the same time. We apply two optimization techniques, namely projected gradient and optimization on manifold, to obtain the solution. Using comprehensive experiments on four public datasets, we show that the proposed efficient spectral hashing (ESH) algorithm achieves highly competitive retrieval performance compared with state of the art at low complexity.
Methods for Pruning Deep Neural Networks
Oct 31, 2020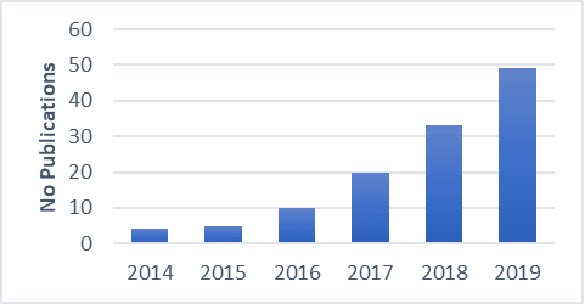
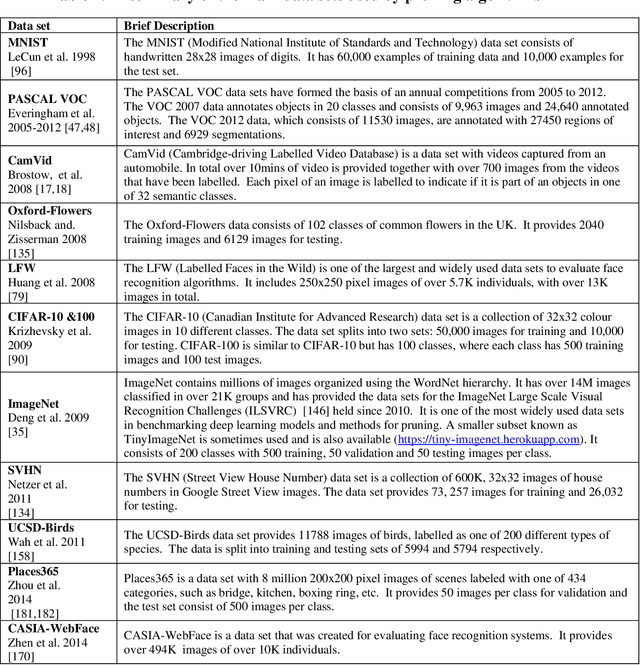
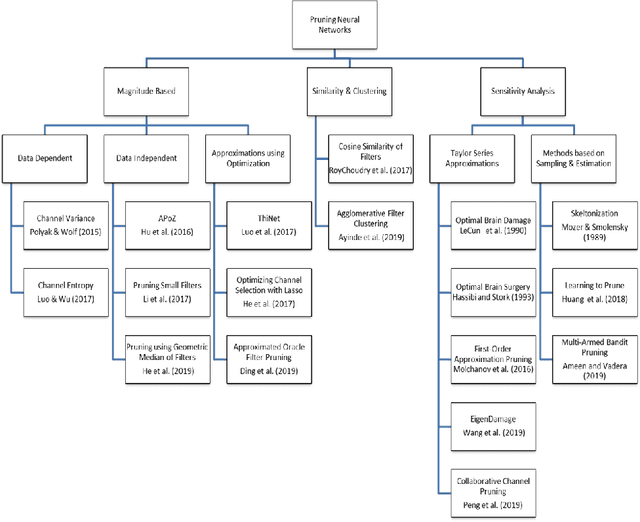
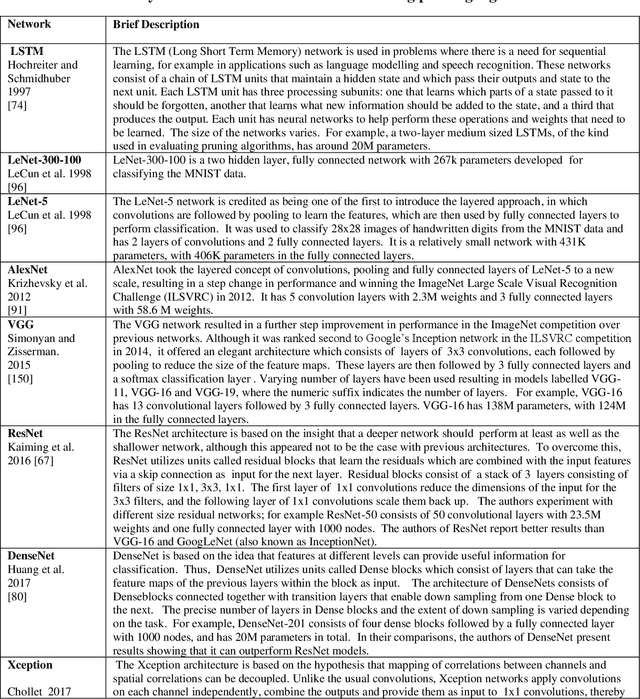
This paper presents a survey of methods for pruning deep neural networks, from algorithms first proposed for fully connected networks in the 1990s to the recent methods developed for reducing the size of convolutional neural networks. The paper begins by bringing together many different algorithms by categorising them based on the underlying approach used. It then focuses on three categories: methods that use magnitude-based pruning, methods that utilise clustering to identify redundancy, and methods that utilise sensitivity analysis. Some of the key influencing studies within these categories are presented to illuminate the underlying approaches and results achieved. Most studies on pruning present results from empirical evaluations, which are distributed in the literature as new architectures, algorithms and data sets have evolved with time. This paper brings together the reported results from some key papers in one place by providing a resource that can be used to quickly compare reported results, and trace studies where specific methods, data sets and architectures have been used.
Forecasting Multi-Dimensional Processes over Graphs
Apr 17, 2020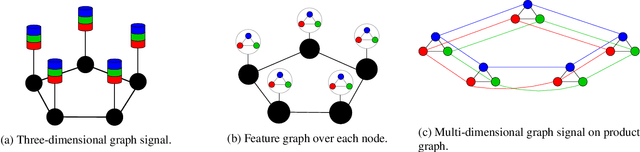
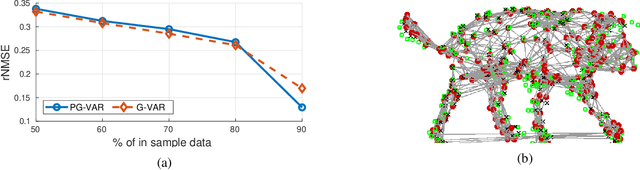
The forecasting of multi-variate time processes through graph-based techniques has recently been addressed under the graph signal processing framework. However, problems in the representation and the processing arise when each time series carries a vector of quantities rather than a scalar one. To tackle this issue, we devise a new framework and propose new methodologies based on the graph vector autoregressive model. More explicitly, we leverage product graphs to model the high-dimensional graph data and develop multi-dimensional graph-based vector autoregressive models to forecast future trends with a number of parameters that is independent of the number of time series and a linear computational complexity. Numerical results demonstrating the prediction of moving point clouds corroborate our findings.
Deep Interactive Denoiser (DID) for X-Ray Computed Tomography
Nov 30, 2020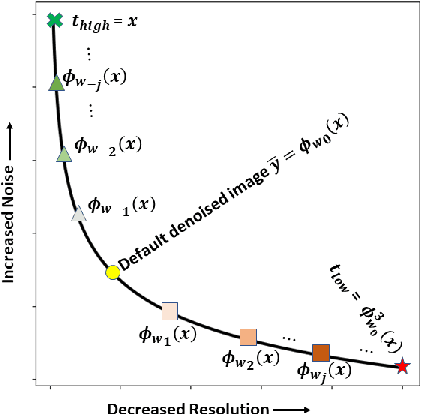
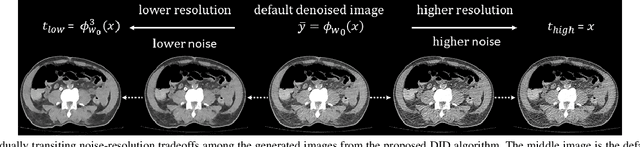
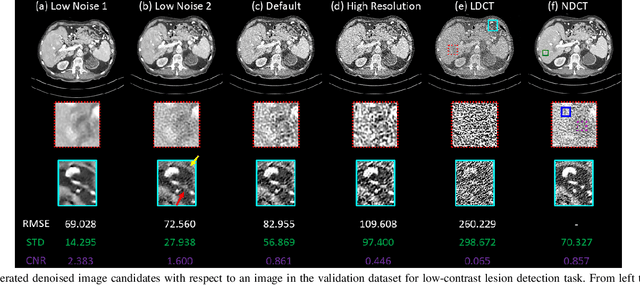
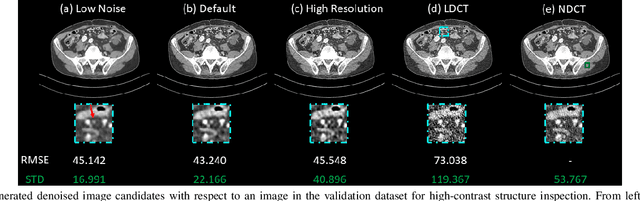
Low dose computed tomography (LDCT) is desirable for both diagnostic imaging and image guided interventions. Denoisers are openly used to improve the quality of LDCT. Deep learning (DL)-based denoisers have shown state-of-the-art performance and are becoming one of the mainstream methods. However, there exists two challenges regarding the DL-based denoisers: 1) a trained model typically does not generate different image candidates with different noise-resolution tradeoffs which sometimes are needed for different clinical tasks; 2) the model generalizability might be an issue when the noise level in the testing images is different from that in the training dataset. To address these two challenges, in this work, we introduce a lightweight optimization process at the testing phase on top of any existing DL-based denoisers to generate multiple image candidates with different noise-resolution tradeoffs suitable for different clinical tasks in real-time. Consequently, our method allows the users to interact with the denoiser to efficiently review various image candidates and quickly pick up the desired one, and thereby was termed as deep interactive denoiser (DID). Experimental results demonstrated that DID can deliver multiple image candidates with different noise-resolution tradeoffs, and shows great generalizability regarding various network architectures, as well as training and testing datasets with various noise levels.
Coarse scale representation of spiking neural networks: backpropagation through spikes and application to neuromorphic hardware
Jul 13, 2020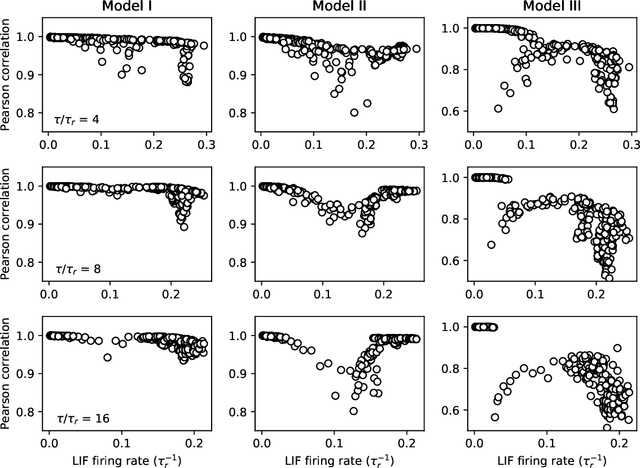
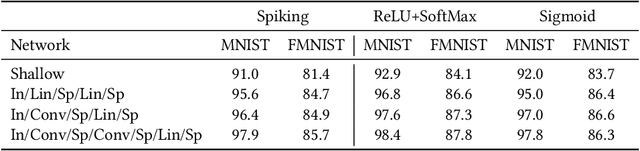
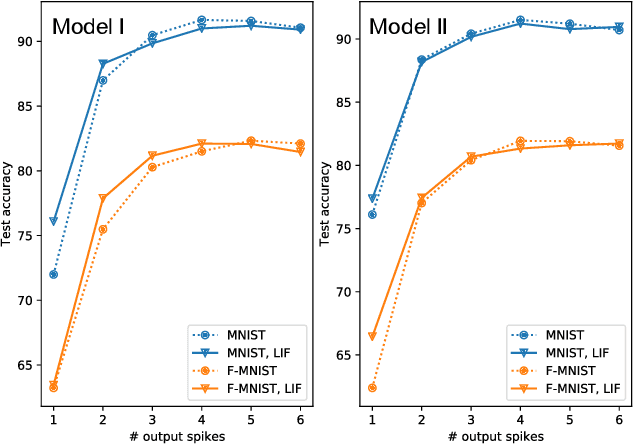
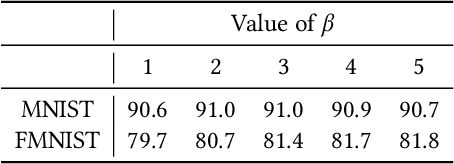
In this work we explore recurrent representations of leaky integrate and fire neurons operating at a timescale equal to their absolute refractory period. Our coarse time scale approximation is obtained using a probability distribution function for spike arrivals that is homogeneously distributed over this time interval. This leads to a discrete representation that exhibits the same dynamics as the continuous model, enabling efficient large scale simulations and backpropagation through the recurrent implementation. We use this approach to explore the training of deep spiking neural networks including convolutional, all-to-all connectivity, and maxpool layers directly in Pytorch. We found that the recurrent model leads to high classification accuracy using just 4-long spike trains during training. We also observed a good transfer back to continuous implementations of leaky integrate and fire neurons. Finally, we applied this approach to some of the standard control problems as a first step to explore reinforcement learning using neuromorphic chips.
E-commerce Query-based Generation based on User Review
Nov 11, 2020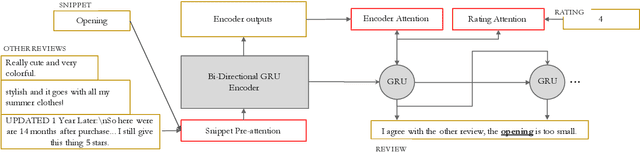
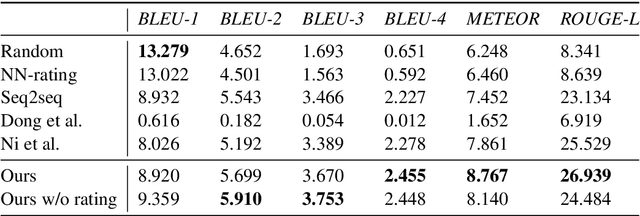
With the increasing number of merchandise on e-commerce platforms, users tend to refer to reviews of other shoppers to decide which product they should buy. However, with so many reviews of a product, users often have to spend lots of time browsing through reviews talking about product attributes they do not care about. We want to establish a system that can automatically summarize and answer user's product specific questions. In this study, we propose a novel seq2seq based text generation model to generate answers to user's question based on reviews posted by previous users. Given a user question and/or target sentiment polarity, we extract aspects of interest and generate an answer that summarizes previous relevant user reviews. Specifically, our model performs attention between input reviews and target aspects during encoding and is conditioned on both review rating and input context during decoding. We also incorporate a pre-trained auxiliary rating classifier to improve model performance and accelerate convergence during training. Experiments using real-world e-commerce dataset show that our model achieves improvement in performance compared to previously introduced models.
You Only Need Adversarial Supervision for Semantic Image Synthesis
Dec 08, 2020
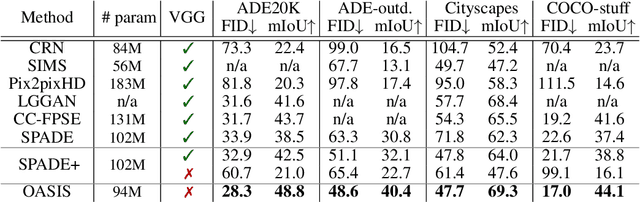

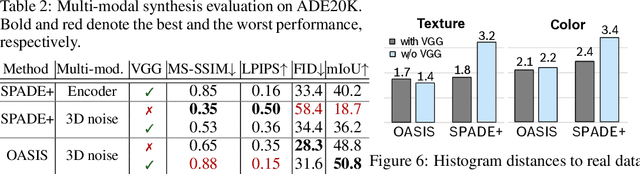
Despite their recent successes, GAN models for semantic image synthesis still suffer from poor image quality when trained with only adversarial supervision. Historically, additionally employing the VGG-based perceptual loss has helped to overcome this issue, significantly improving the synthesis quality, but at the same time limiting the progress of GAN models for semantic image synthesis. In this work, we propose a novel, simplified GAN model, which needs only adversarial supervision to achieve high quality results. We re-design the discriminator as a semantic segmentation network, directly using the given semantic label maps as the ground truth for training. By providing stronger supervision to the discriminator as well as to the generator through spatially- and semantically-aware discriminator feedback, we are able to synthesize images of higher fidelity with better alignment to their input label maps, making the use of the perceptual loss superfluous. Moreover, we enable high-quality multi-modal image synthesis through global and local sampling of a 3D noise tensor injected into the generator, which allows complete or partial image change. We show that images synthesized by our model are more diverse and follow the color and texture distributions of real images more closely. We achieve an average improvement of $6$ FID and $5$ mIoU points over the state of the art across different datasets using only adversarial supervision.
Learning to Solve AC Optimal Power Flow by Differentiating through Holomorphic Embeddings
Dec 16, 2020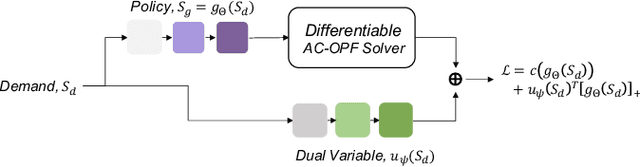
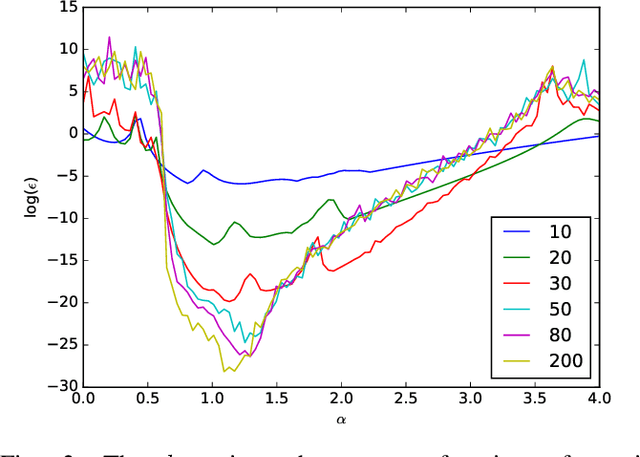
Alternating current optimal power flow (AC-OPF) is one of the fundamental problems in power systems operation. AC-OPF is traditionally cast as a constrained optimization problem that seeks optimal generation set points whilst fulfilling a set of non-linear equality constraints -- the power flow equations. With increasing penetration of renewable generation, grid operators need to solve larger problems at shorter intervals. This motivates the research interest in learning OPF solutions with neural networks, which have fast inference time and is potentially scalable to large networks. The main difficulty in solving the AC-OPF problem lies in dealing with this equality constraint that has spurious roots, i.e. there are assignments of voltages that fulfill the power flow equations that however are not physically realizable. This property renders any method relying on projected-gradients brittle because these non-physical roots can act as attractors. In this paper, we show efficient strategies that circumvent this problem by differentiating through the operations of a power flow solver that embeds the power flow equations into a holomorphic function. The resulting learning-based approach is validated experimentally on a 200-bus system and we show that, after training, the learned agent produces optimized power flow solutions reliably and fast. Specifically, we report a 12x increase in speed and a 40% increase in robustness compared to a traditional solver. To the best of our knowledge, this approach constitutes the first learning-based approach that successfully respects the full non-linear AC-OPF equations.
A Provably Convergent and Practical Algorithm for Min-max Optimization with Applications to GANs
Jun 23, 2020



We present a new algorithm for optimizing min-max loss functions that arise in training GANs. We prove that our algorithm converges to an equilibrium point in time polynomial in the dimension, and smoothness parameters of the loss function. The point our algorithm converges to is stable when the maximizing player can respond using any sequence of steps which increase the loss at each step, and the minimizing player is empowered to simulate the maximizing player's response for arbitrarily many steps but is restricted to move according to updates sampled from a stochastic gradient oracle. We apply our algorithm to train GANs on Gaussian mixtures, MNIST and CIFAR-10. We observe that our algorithm trains stably and avoids mode collapse, while achieving a training time per iteration and memory requirement similar to gradient descent-ascent.