 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Streaming Algorithms for Stochastic Multi-armed Bandits
Dec 09, 2020
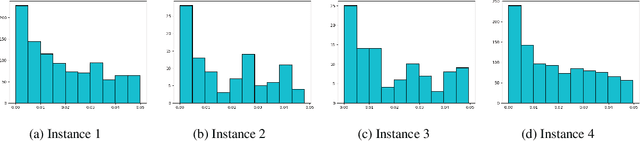
We study the Stochastic Multi-armed Bandit problem under bounded arm-memory. In this setting, the arms arrive in a stream, and the number of arms that can be stored in the memory at any time, is bounded. The decision-maker can only pull arms that are present in the memory. We address the problem from the perspective of two standard objectives: 1) regret minimization, and 2) best-arm identification. For regret minimization, we settle an important open question by showing an almost tight hardness. We show {\Omega}(T^{2/3}) cumulative regret in expectation for arm-memory size of (n-1), where n is the number of arms. For best-arm identification, we study two algorithms. First, we present an O(r) arm-memory r-round adaptive streaming algorithm to find an {\epsilon}-best arm. In r-round adaptive streaming algorithm for best-arm identification, the arm pulls in each round are decided based on the observed outcomes in the earlier rounds. The best-arm is the output at the end of r rounds. The upper bound on the sample complexity of our algorithm matches with the lower bound for any r-round adaptive streaming algorithm. Secondly, we present a heuristic to find the {\epsilon}-best arm with optimal sample complexity, by storing only one extra arm in the memory.
HiFi-GAN: High-Fidelity Denoising and Dereverberation Based on Speech Deep Features in Adversarial Networks
Jun 10, 2020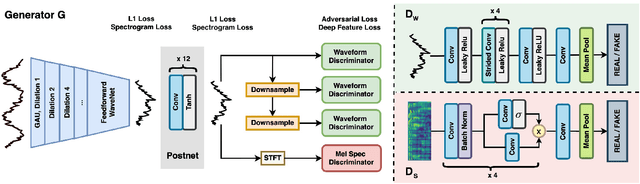
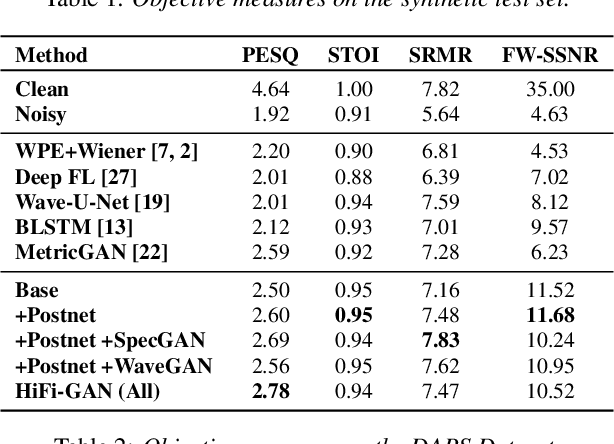
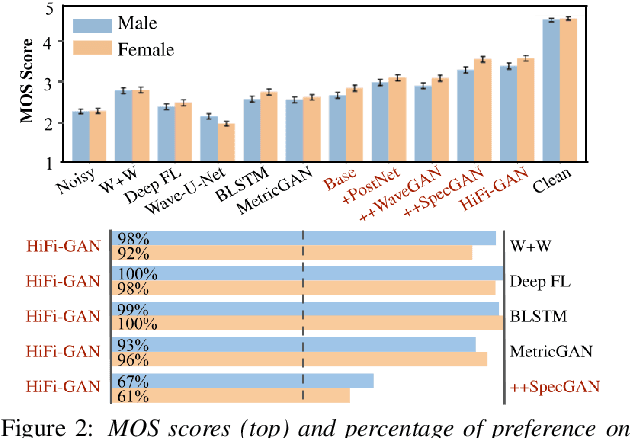
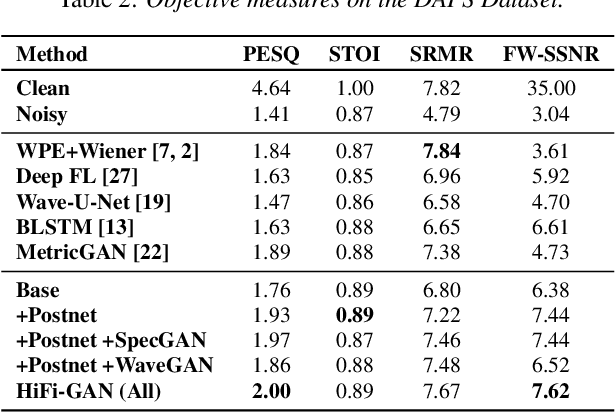
Real-world audio recordings are often degraded by factors such as noise, reverberation, and equalization distortion. This paper introduces HiFi-GAN, a deep learning method to transform recorded speech to sound as though it had been recorded in a studio. We use an end-to-end feed-forward WaveNet architecture, trained with multi-scale adversarial discriminators in both the time domain and the time-frequency domain. It relies on the deep feature matching losses of the discriminators to improve the perceptual quality of enhanced speech. The proposed model generalizes well to new speakers, new speech content, and new environments. It significantly outperforms state-of-the-art baseline methods in both objective and subjective experiments.
Scalable Linear Causal Inference for Irregularly Sampled Time Series with Long Range Dependencies
Mar 10, 2016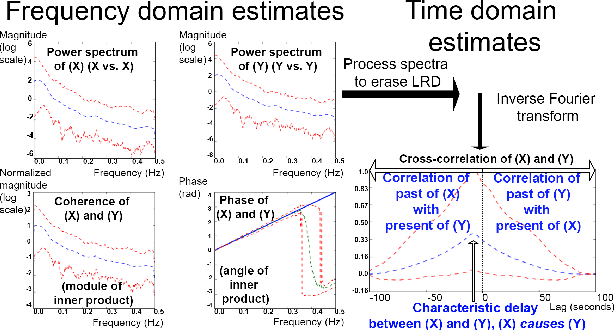
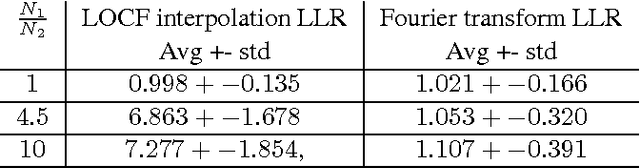
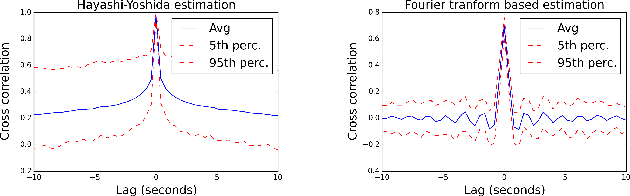
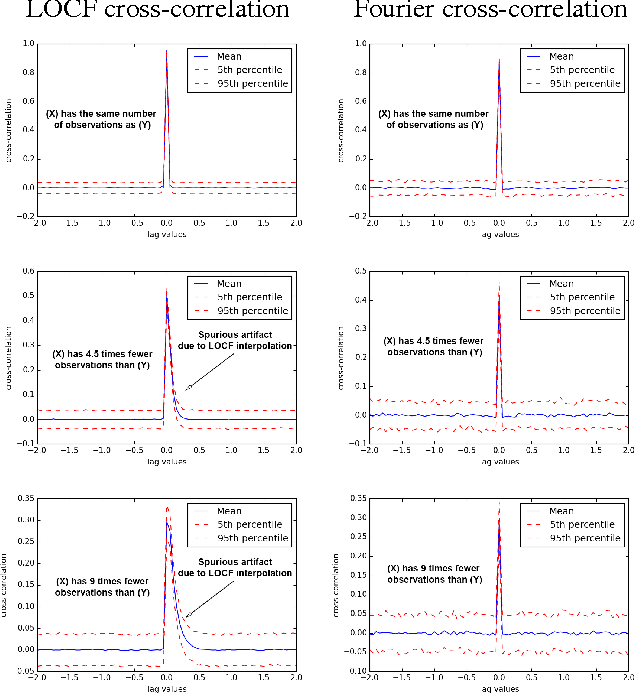
Linear causal analysis is central to a wide range of important application spanning finance, the physical sciences, and engineering. Much of the existing literature in linear causal analysis operates in the time domain. Unfortunately, the direct application of time domain linear causal analysis to many real-world time series presents three critical challenges: irregular temporal sampling, long range dependencies, and scale. Moreover, real-world data is often collected at irregular time intervals across vast arrays of decentralized sensors and with long range dependencies which make naive time domain correlation estimators spurious. In this paper we present a frequency domain based estimation framework which naturally handles irregularly sampled data and long range dependencies while enabled memory and communication efficient distributed processing of time series data. By operating in the frequency domain we eliminate the need to interpolate and help mitigate the effects of long range dependencies. We implement and evaluate our new work-flow in the distributed setting using Apache Spark and demonstrate on both Monte Carlo simulations and high-frequency financial trading that we can accurately recover causal structure at scale.
Content based singing voice source separation via strong conditioning using aligned phonemes
Aug 05, 2020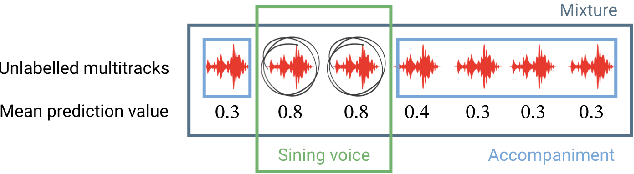
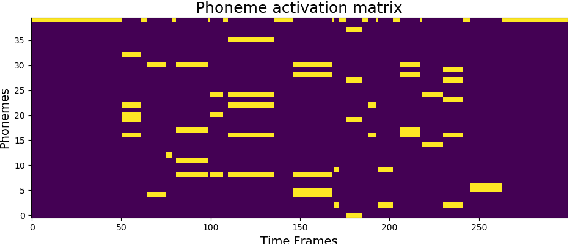
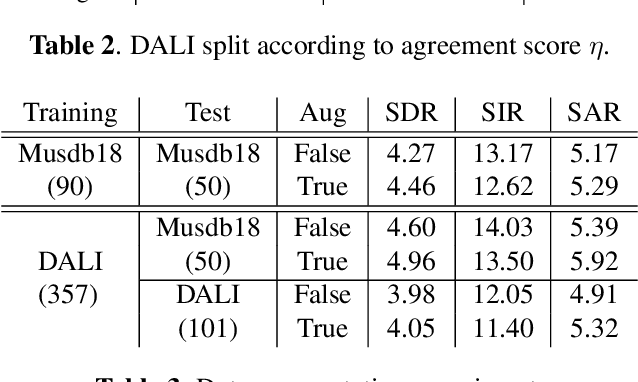
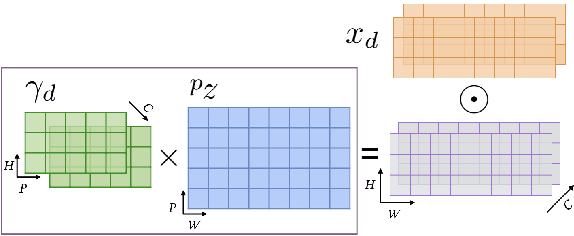
Informed source separation has recently gained renewed interest with the introduction of neural networks and the availability of large multitrack datasets containing both the mixture and the separated sources. These approaches use prior information about the target source to improve separation. Historically, Music Information Retrieval researchers have focused primarily on score-informed source separation, but more recent approaches explore lyrics-informed source separation. However, because of the lack of multitrack datasets with time-aligned lyrics, models use weak conditioning with non-aligned lyrics. In this paper, we present a multimodal multitrack dataset with lyrics aligned in time at the word level with phonetic information as well as explore strong conditioning using the aligned phonemes. Our model follows a U-Net architecture and takes as input both the magnitude spectrogram of a musical mixture and a matrix with aligned phonetic information. The phoneme matrix is embedded to obtain the parameters that control Feature-wise Linear Modulation (FiLM) layers. These layers condition the U-Net feature maps to adapt the separation process to the presence of different phonemes via affine transformations. We show that phoneme conditioning can be successfully applied to improve singing voice source separation.
Improving Text Generation Evaluation with Batch Centering and Tempered Word Mover Distance
Oct 13, 2020



Recent advances in automatic evaluation metrics for text have shown that deep contextualized word representations, such as those generated by BERT encoders, are helpful for designing metrics that correlate well with human judgements. At the same time, it has been argued that contextualized word representations exhibit sub-optimal statistical properties for encoding the true similarity between words or sentences. In this paper, we present two techniques for improving encoding representations for similarity metrics: a batch-mean centering strategy that improves statistical properties; and a computationally efficient tempered Word Mover Distance, for better fusion of the information in the contextualized word representations. We conduct numerical experiments that demonstrate the robustness of our techniques, reporting results over various BERT-backbone learned metrics and achieving state of the art correlation with human ratings on several benchmarks.
The voice of COVID-19: Acoustic correlates of infection
Dec 17, 2020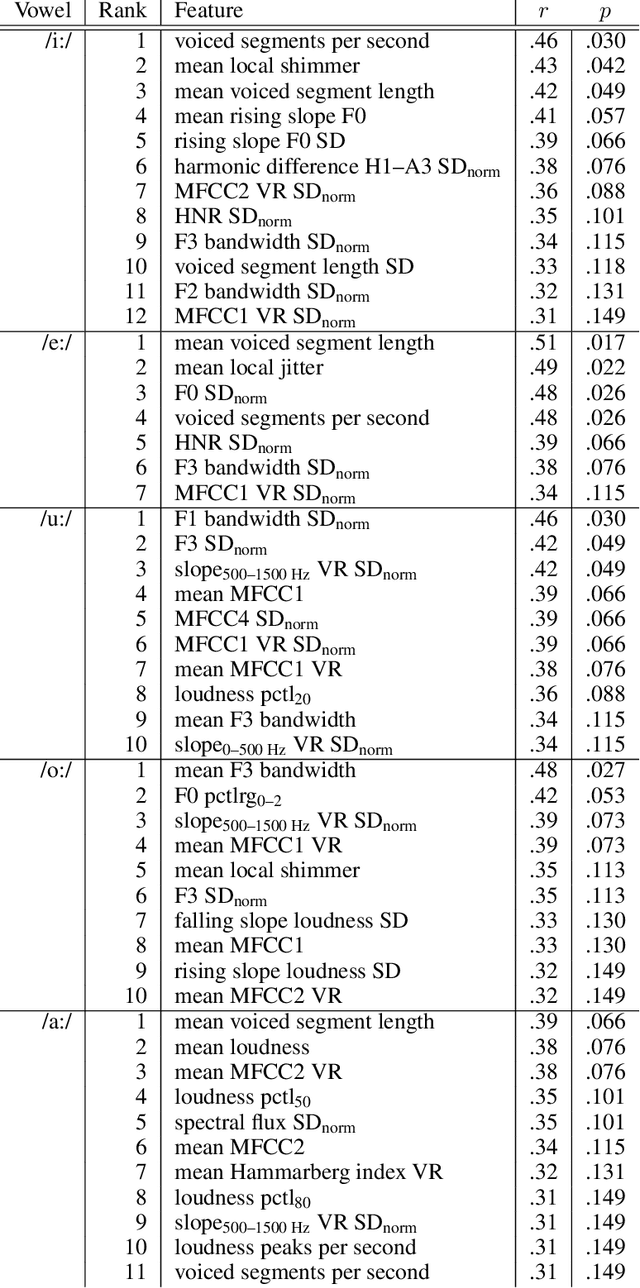
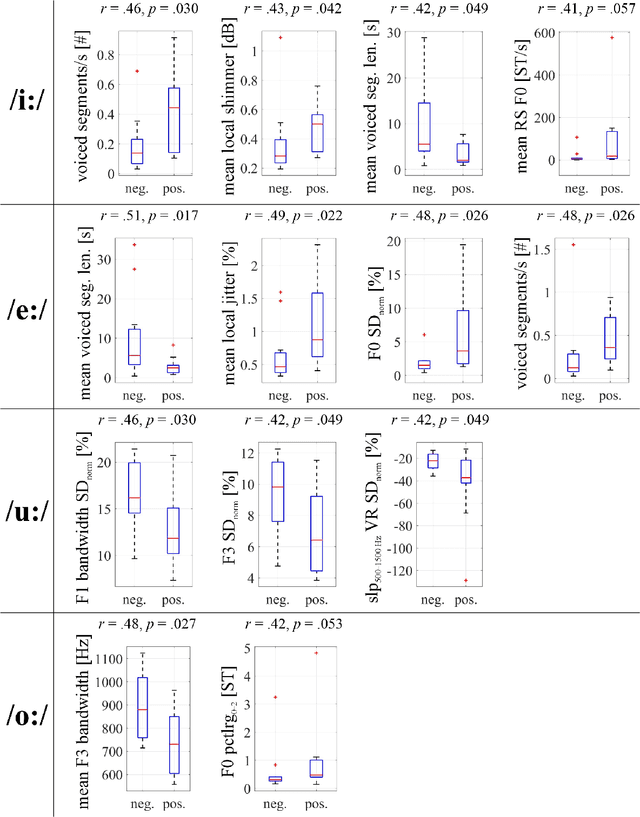
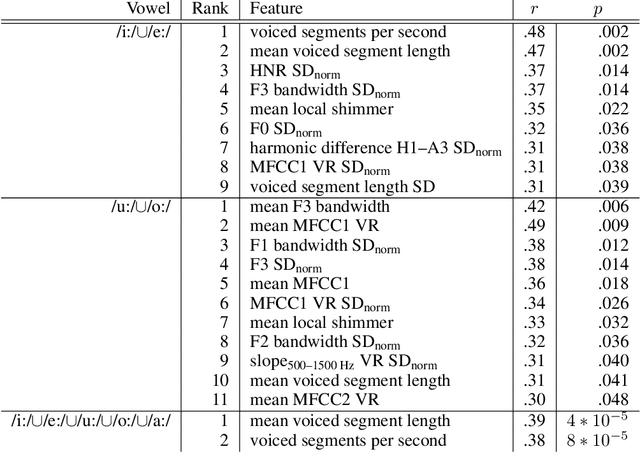
COVID-19 is a global health crisis that has been affecting many aspects of our daily lives throughout the past year. The symptomatology of COVID-19 is heterogeneous with a severity continuum. A considerable proportion of symptoms are related to pathological changes in the vocal system, leading to the assumption that COVID-19 may also affect voice production. For the very first time, the present study aims to investigate voice acoustic correlates of an infection with COVID-19 on the basis of a comprehensive acoustic parameter set. We compare 88 acoustic features extracted from recordings of the vowels /i:/, /e:/, /o:/, /u:/, and /a:/ produced by 11 symptomatic COVID-19 positive and 11 COVID-19 negative German-speaking participants. We employ the Mann-Whitney U test and calculate effect sizes to identify features with the most prominent group differences. The mean voiced segment length and the number of voiced segments per second yield the most important differences across all vowels indicating discontinuities in the pulmonic airstream during phonation in COVID-19 positive participants. Group differences in the front vowels /i:/ and /e:/ are additionally reflected in the variation of the fundamental frequency and the harmonics-to-noise ratio, group differences in back vowels /o:/ and /u:/ in statistics of the Mel-frequency cepstral coefficients and the spectral slope. Findings of this study can be considered an important proof-of-concept contribution for a potential future voice-based identification of individuals infected with COVID-19.
Spiking Associative Memory for Spatio-Temporal Patterns
Jun 30, 2020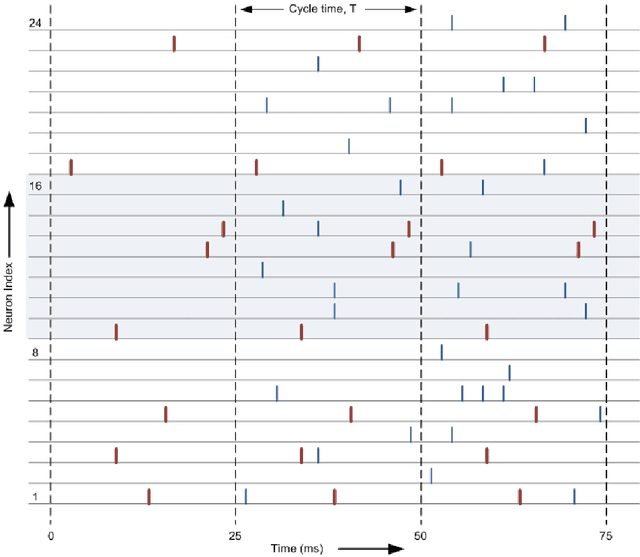
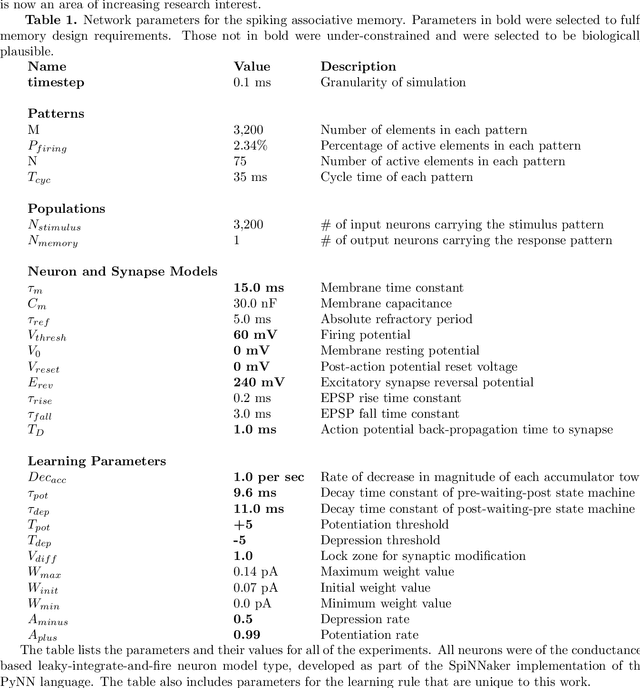
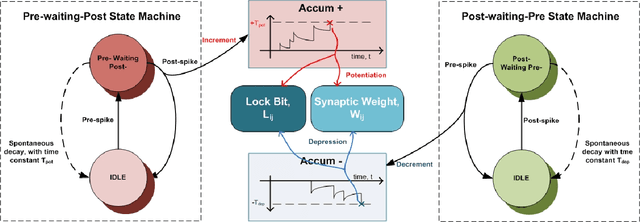
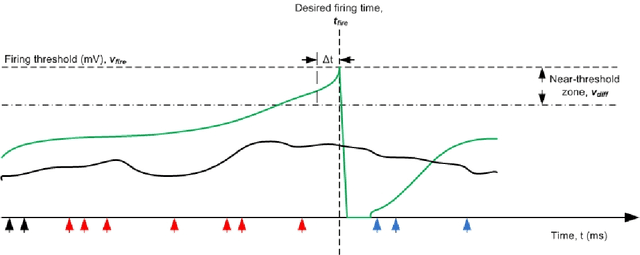
Spike Timing Dependent Plasticity is form of learning that has been demonstrated in real cortical tissue, but attempts to use it for artificial systems have not produced good results. This paper seeks to remedy this with two significant advances. The first is the development a simple stochastic learning rule called cyclic STDP that can extract patterns encoded in the precise spiking times of a group of neurons. We show that a population of neurons endowed with this learning rule can act as an effective short-term associative memory, storing and reliably recalling a large set of pattern associations over an extended period of time. The second major theme examines the challenges associated with training a neuron to produce a spike at a precise time and for the fidelity of spike recall time to be maintained as further learning occurs. The strong constraint of working with precisely-timed spikes (so-called temporal coding) is mandated by the learning rule but is also consistent with the believe in the necessity of such an encoding scheme to render a spiking neural network a competitive solution for flexible intelligent systems in continuous learning environments. The encoding and learning rules are demonstrated in the design of a single-layer associative memory (an input layer consisting of 3,200 spiking neurons fully-connected to a similar sized population of memory neurons), which we simulate and characterise. Design considerations and clarification of the role of parameters under the control of the designer are explored.
EPTAS for $k$-means Clustering of Affine Subspaces
Oct 19, 2020We consider a generalization of the fundamental $k$-means clustering for data with incomplete or corrupted entries. When data objects are represented by points in $\mathbb{R}^d$, a data point is said to be incomplete when some of its entries are missing or unspecified. An incomplete data point with at most $\Delta$ unspecified entries corresponds to an axis-parallel affine subspace of dimension at most $\Delta$, called a $\Delta$-point. Thus we seek a partition of $n$ input $\Delta$-points into $k$ clusters minimizing the $k$-means objective. For $\Delta=0$, when all coordinates of each point are specified, this is the usual $k$-means clustering. We give an algorithm that finds an $(1+ \epsilon)$-approximate solution in time $f(k,\epsilon, \Delta) \cdot n^2 \cdot d$ for some function $f$ of $k,\epsilon$, and $\Delta$ only.
Benchmark data and method for real-time people counting in cluttered scenes using depth sensors
Oct 28, 2018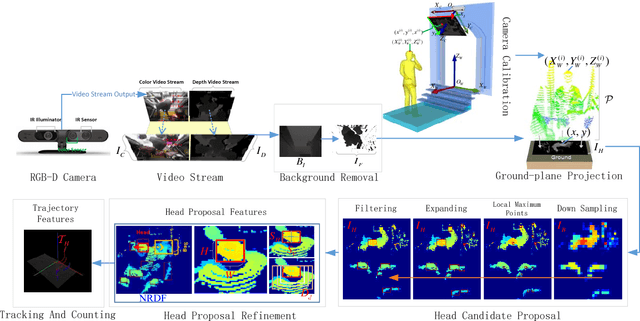

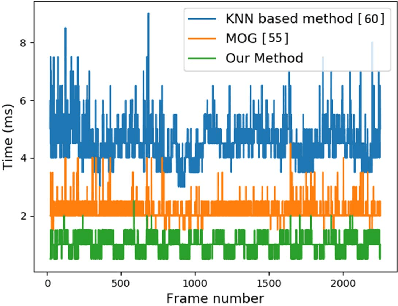
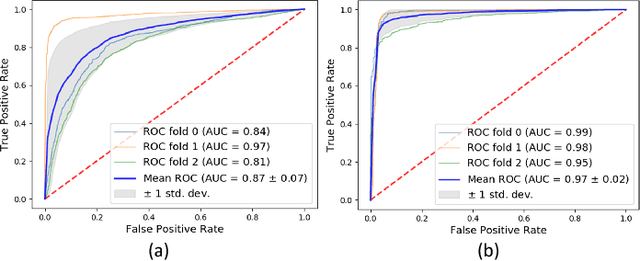
Vision-based automatic counting of people has widespread applications in intelligent transportation systems, security, and logistics. However, there is currently no large-scale public dataset for benchmarking approaches on this problem. This work fills this gap by introducing the first real-world RGB-D People Counting DataSet (PCDS) containing over 4,500 videos recorded at the entrance doors of buses in normal and cluttered conditions. It also proposes an efficient method for counting people in real-world cluttered scenes related to public transportations using depth videos. The proposed method computes a point cloud from the depth video frame and re-projects it onto the ground plane to normalize the depth information. The resulting depth image is analyzed for identifying potential human heads. The human head proposals are meticulously refined using a 3D human model. The proposals in each frame of the continuous video stream are tracked to trace their trajectories. The trajectories are again refined to ascertain reliable counting. People are eventually counted by accumulating the head trajectories leaving the scene. To enable effective head and trajectory identification, we also propose two different compound features. A thorough evaluation on PCDS demonstrates that our technique is able to count people in cluttered scenes with high accuracy at 45 fps on a 1.7 GHz processor, and hence it can be deployed for effective real-time people counting for intelligent transportation systems.
Forecasting Multi-Dimensional Processes over Graphs
Apr 17, 2020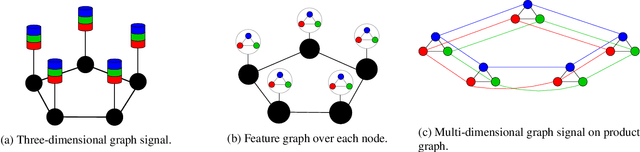
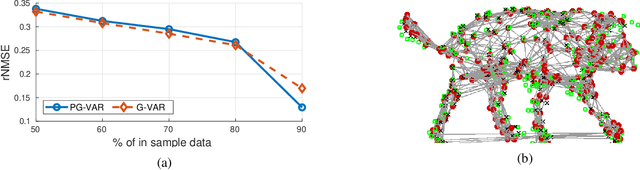
The forecasting of multi-variate time processes through graph-based techniques has recently been addressed under the graph signal processing framework. However, problems in the representation and the processing arise when each time series carries a vector of quantities rather than a scalar one. To tackle this issue, we devise a new framework and propose new methodologies based on the graph vector autoregressive model. More explicitly, we leverage product graphs to model the high-dimensional graph data and develop multi-dimensional graph-based vector autoregressive models to forecast future trends with a number of parameters that is independent of the number of time series and a linear computational complexity. Numerical results demonstrating the prediction of moving point clouds corroborate our findings.