 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Detection and Tracking with Motion Modelling for Multiple Object Tracking
Aug 20, 2020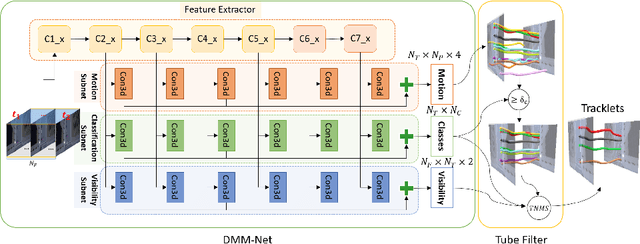

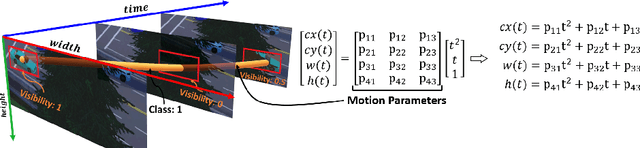

Deep learning-based Multiple Object Tracking (MOT) currently relies on off-the-shelf detectors for tracking-by-detection.This results in deep models that are detector biased and evaluations that are detector influenced. To resolve this issue, we introduce Deep Motion Modeling Network (DMM-Net) that can estimate multiple objects' motion parameters to perform joint detection and association in an end-to-end manner. DMM-Net models object features over multiple frames and simultaneously infers object classes, visibility, and their motion parameters. These outputs are readily used to update the tracklets for efficient MOT. DMM-Net achieves PR-MOTA score of 12.80 @ 120+ fps for the popular UA-DETRAC challenge, which is better performance and orders of magnitude faster. We also contribute a synthetic large-scale public dataset Omni-MOT for vehicle tracking that provides precise ground-truth annotations to eliminate the detector influence in MOT evaluation. This 14M+ frames dataset is extendable with our public script (Code at Dataset <https://github.com/shijieS/OmniMOTDataset>, Dataset Recorder <https://github.com/shijieS/OMOTDRecorder>, Omni-MOT Source <https://github.com/shijieS/DMMN>). We demonstrate the suitability of Omni-MOT for deep learning with DMMNet and also make the source code of our network public.
Deep Affinity Network for Multiple Object Tracking
Oct 28, 2018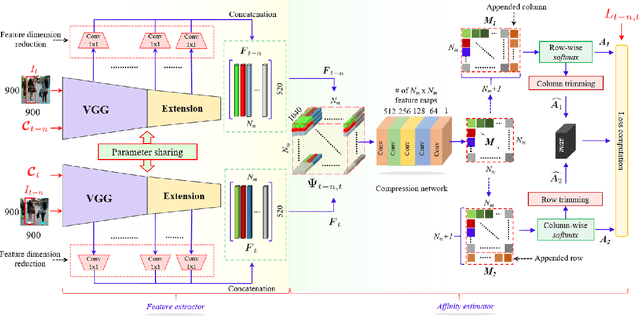
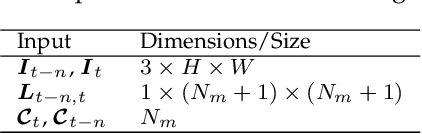
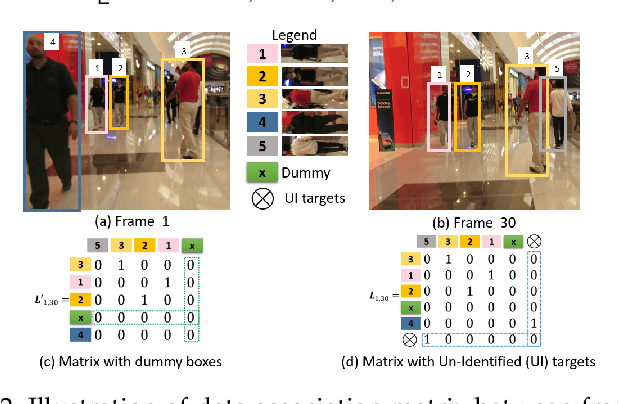
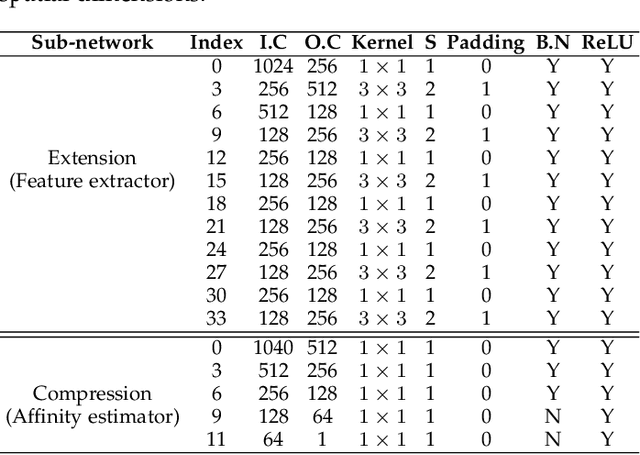
Multiple Object Tracking (MOT) plays an important role in solving many fundamental problems in video analysis in computer vision. Most MOT methods employ two steps: Object Detection and Data Association. The first step detects objects of interest in every frame of a video, and the second establishes correspondence between the detected objects in different frames to obtain their tracks. Object detection has made tremendous progress in the last few years due to deep learning. However, data association for tracking still relies on hand crafted constraints such as appearance, motion, spatial proximity, grouping etc. to compute affinities between the objects in different frames. In this paper, we harness the power of deep learning for data association in tracking by jointly modelling object appearances and their affinities between different frames in an end-to-end fashion. The proposed Deep Affinity Network (DAN) learns compact; yet comprehensive features of pre-detected objects at several levels of abstraction, and performs exhaustive pairing permutations of those features in any two frames to infer object affinities. DAN also accounts for multiple objects appearing and disappearing between video frames. We exploit the resulting efficient affinity computations to associate objects in the current frame deep into the previous frames for reliable on-line tracking. Our technique is evaluated on popular multiple object tracking challenges MOT15, MOT17 and UA-DETRAC. Comprehensive benchmarking under twelve evaluation metrics demonstrates that our approach is among the best performing techniques on the leader board for these challenges. The open source implementation of our work is available at https://github.com/shijieS/SST.git.
Benchmark data and method for real-time people counting in cluttered scenes using depth sensors
Oct 28, 2018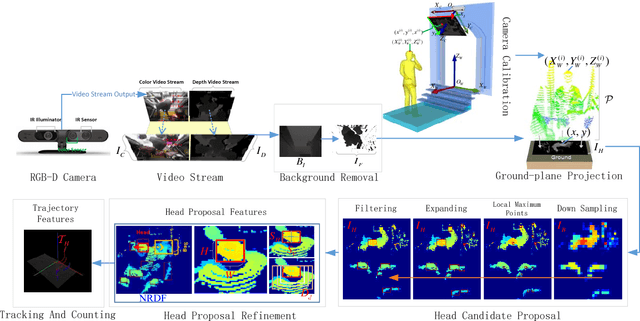

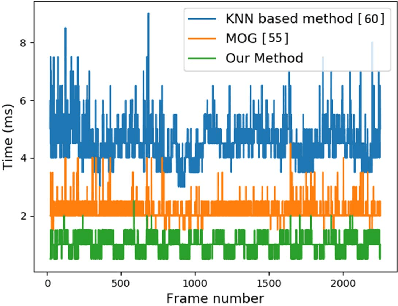
Vision-based automatic counting of people has widespread applications in intelligent transportation systems, security, and logistics. However, there is currently no large-scale public dataset for benchmarking approaches on this problem. This work fills this gap by introducing the first real-world RGB-D People Counting DataSet (PCDS) containing over 4,500 videos recorded at the entrance doors of buses in normal and cluttered conditions. It also proposes an efficient method for counting people in real-world cluttered scenes related to public transportations using depth videos. The proposed method computes a point cloud from the depth video frame and re-projects it onto the ground plane to normalize the depth information. The resulting depth image is analyzed for identifying potential human heads. The human head proposals are meticulously refined using a 3D human model. The proposals in each frame of the continuous video stream are tracked to trace their trajectories. The trajectories are again refined to ascertain reliable counting. People are eventually counted by accumulating the head trajectories leaving the scene. To enable effective head and trajectory identification, we also propose two different compound features. A thorough evaluation on PCDS demonstrates that our technique is able to count people in cluttered scenes with high accuracy at 45 fps on a 1.7 GHz processor, and hence it can be deployed for effective real-time people counting for intelligent transportation systems.