 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemDreamer: Decoupling Perception and Reasoning for Long Video Understanding via Hierarchical Graph Memory and Agentic Retrieval Mechanism
Jun 05, 2026Current Vision-Language Models struggle with hours-long videos because processing full-length visual sequences induces prohibitive token explosion and attention dilution. To overcome this, we introduce MemDreamer to decouple perception and reasoning, shifting long-video understanding into an agentic exploration process. As a plug-and-play framework, it incrementally streams videos to construct a Hierarchical Graph Memory, a top-down three-tier architecture for semantic abstraction, anchored by a foundational graph capturing spatiotemporal and causal relations. During inference, the reasoning model employs agentic tool-augmented retrieval, navigating hierarchies, searching nodes, and traversing logical edges via an Observation-Reason-Action loop. Experiments show MemDreamer achieves SOTA results across four mainstream benchmarks, narrowing the gap with human experts to only 3.7 points. It constrains the reasoning context window to merely 2% of full-context ingestion while delivering a 12.5 point absolute accuracy gain. Furthermore, statistical analysis uncovers a strong positive linear correlation between an VLM's performance on logic reasoning and long-video understanding benchmarks, establishing agentic capability scaling as a new paradigm for multimodal comprehension.
Benchmark data and method for real-time people counting in cluttered scenes using depth sensors
Oct 28, 2018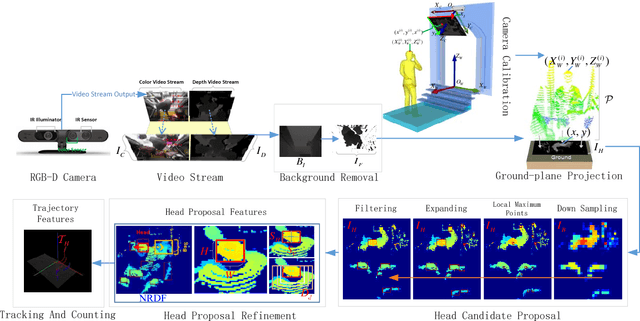

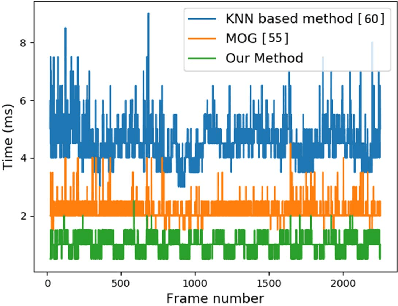
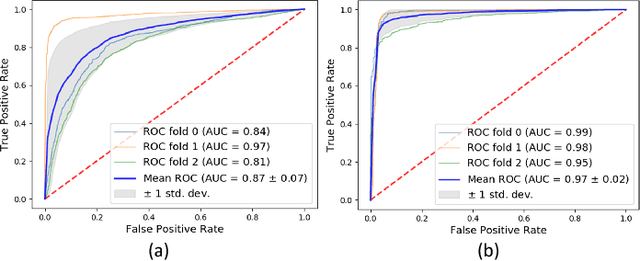
Vision-based automatic counting of people has widespread applications in intelligent transportation systems, security, and logistics. However, there is currently no large-scale public dataset for benchmarking approaches on this problem. This work fills this gap by introducing the first real-world RGB-D People Counting DataSet (PCDS) containing over 4,500 videos recorded at the entrance doors of buses in normal and cluttered conditions. It also proposes an efficient method for counting people in real-world cluttered scenes related to public transportations using depth videos. The proposed method computes a point cloud from the depth video frame and re-projects it onto the ground plane to normalize the depth information. The resulting depth image is analyzed for identifying potential human heads. The human head proposals are meticulously refined using a 3D human model. The proposals in each frame of the continuous video stream are tracked to trace their trajectories. The trajectories are again refined to ascertain reliable counting. People are eventually counted by accumulating the head trajectories leaving the scene. To enable effective head and trajectory identification, we also propose two different compound features. A thorough evaluation on PCDS demonstrates that our technique is able to count people in cluttered scenes with high accuracy at 45 fps on a 1.7 GHz processor, and hence it can be deployed for effective real-time people counting for intelligent transportation systems.