 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning the Pareto Front with Hypernetworks
Oct 08, 2020
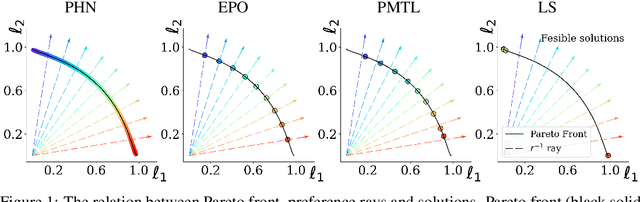
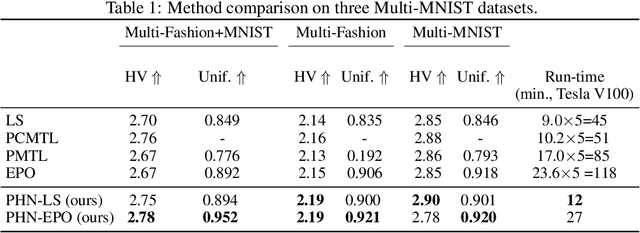
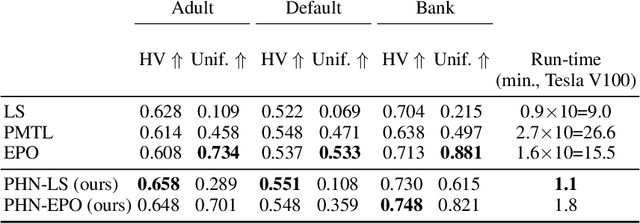
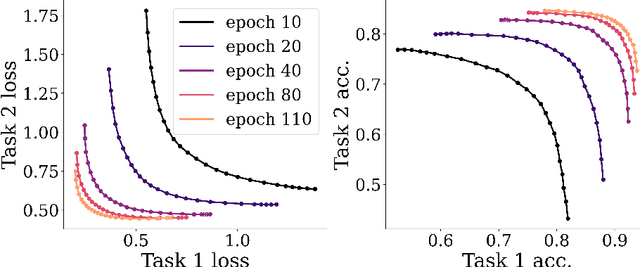
Multi-objective optimization problems are prevalent in machine learning. These problems have a set of optimal solutions, called the Pareto front, where each point on the front represents a different trade-off between possibly conflicting objectives. Recent optimization algorithms can target a specific desired ray in loss space, but still face two grave limitations: (i) A separate model has to be trained for each point on the front; and (ii) The exact trade-off must be known prior to the optimization process. Here, we tackle the problem of learning the entire Pareto front, with the capability of selecting a desired operating point on the front after training. We call this new setup Pareto-Front Learning (PFL). We describe an approach to PFL implemented using HyperNetworks, which we term Pareto HyperNetworks (PHNs). PHN learns the entire Pareto front simultaneously using a single hypernetwork, which receives as input a desired preference vector and returns a Pareto-optimal model whose loss vector is in the desired ray. The unified model is runtime efficient compared to training multiple models, and generalizes to new operating points not used during training. We evaluate our method on a wide set of problems, from multi-task regression and classification to fairness. PHNs learns the entire Pareto front in roughly the same time as learning a single point on the front, and also reaches a better solution set. PFL opens the door to new applications where models are selected based on preferences that are only available at run time.
Learning from History: Modeling Temporal Knowledge Graphs with Sequential Copy-Generation Networks
Dec 15, 2020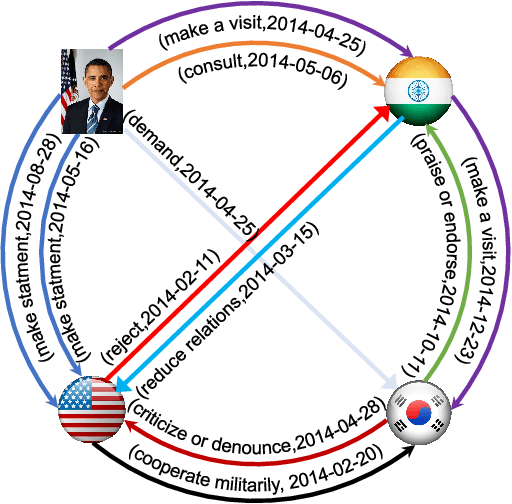
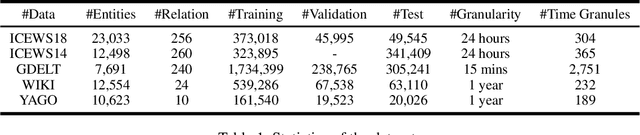
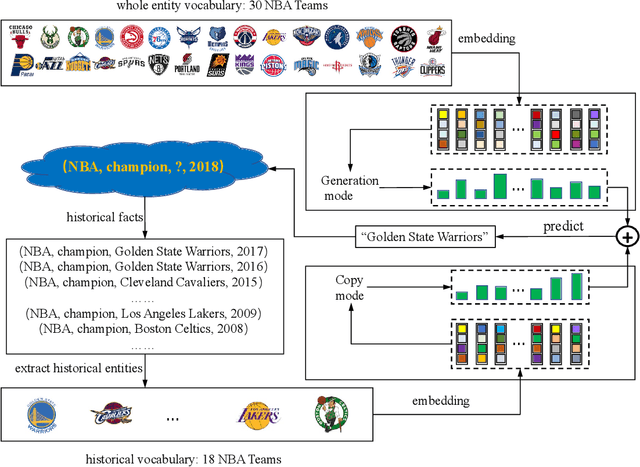
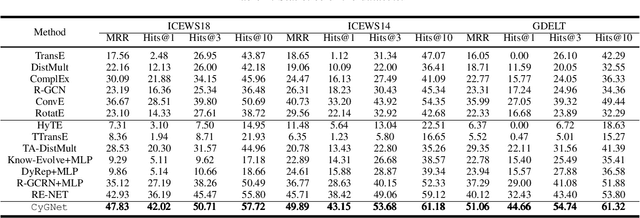
Large knowledge graphs often grow to store temporal facts that model the dynamic relations or interactions of entities along the timeline. Since such temporal knowledge graphs often suffer from incompleteness, it is important to develop time-aware representation learning models that help to infer the missing temporal facts. While the temporal facts are typically evolving, it is observed that many facts often show a repeated pattern along the timeline, such as economic crises and diplomatic activities. This observation indicates that a model could potentially learn much from the known facts appeared in history. To this end, we propose a new representation learning model for temporal knowledge graphs, namely CyGNet, based on a novel timeaware copy-generation mechanism. CyGNet is not only able to predict future facts from the whole entity vocabulary, but also capable of identifying facts with repetition and accordingly predicting such future facts with reference to the known facts in the past. We evaluate the proposed method on the knowledge graph completion task using five benchmark datasets. Extensive experiments demonstrate the effectiveness of CyGNet for predicting future facts with repetition as well as de novo fact prediction.
On the Learnability of Possibilistic Theories
May 06, 2020
We investigate learnability of possibilistic theories from entailments in light of Angluin's exact learning model. We consider cases in which only membership, only equivalence, and both kinds of queries can be posed by the learner. We then show that, for a large class of problems, polynomial time learnability results for classical logic can be transferred to the respective possibilistic extension. In particular, it follows from our results that the possibilistic extension of propositional Horn theories is exactly learnable in polynomial time. As polynomial time learnability in the exact model is transferable to the classical probably approximately correct model extended with membership queries, our work also establishes such results in this model.
A Generalizable Model for Fault Detection in Offshore Wind Turbines Based on Deep Learning
Nov 25, 2020
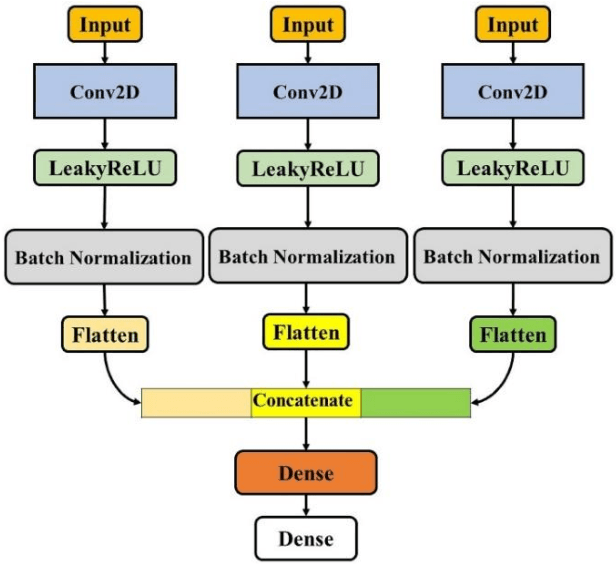
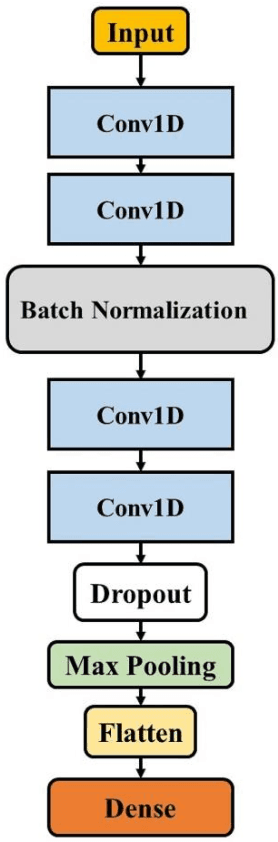
This paper presents a new deep learning-based model for fault detection in offshore wind turbines. To design a generalizable model for fault detection, we use 5 sensors and a sliding window to exploit the inherent temporal information contained in the raw time-series data obtained from sensors. The proposed model uses the nonlinear relationships among multiple sensor variables and the temporal dependency of each sensor on others that considerably increases the performance of fault detection model. A 10-fold cross-validation is used to verify the generalization of the model and evaluate the classification metrics. To evaluate the performance of the model, simulated data from a benchmark floating offshore wind turbine (FOWT) with supervisory control and data acquisition (SCADA) are used. The results illustrate that the proposed model would accurately disclose and classify more than 99% of the faults. Moreover, it is generalizable and can be used to detect faults for different types of systems.
Leave Zero Out: Towards a No-Cross-Validation Approach for Model Selection
Dec 24, 2020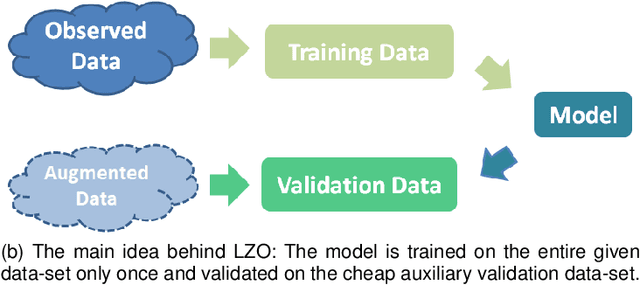
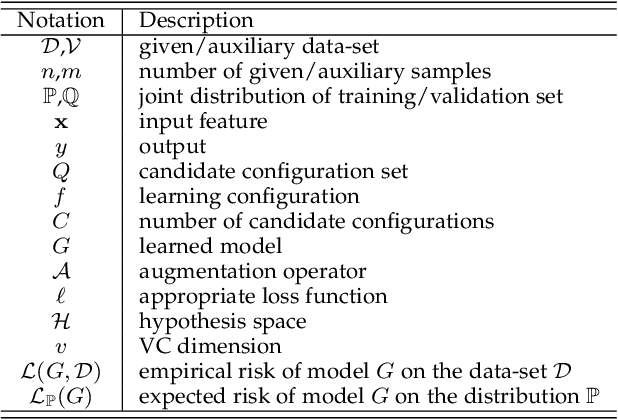
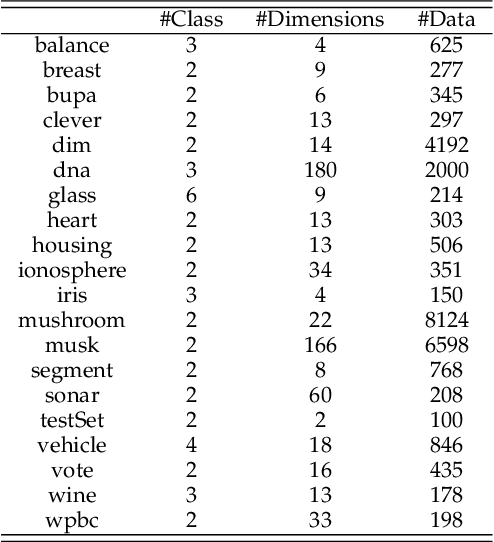
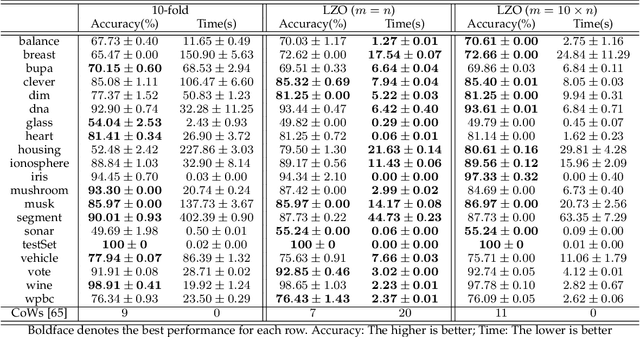
As the main workhorse for model selection, Cross Validation (CV) has achieved an empirical success due to its simplicity and intuitiveness. However, despite its ubiquitous role, CV often falls into the following notorious dilemmas. On the one hand, for small data cases, CV suffers a conservatively biased estimation, since some part of the limited data has to hold out for validation. On the other hand, for large data cases, CV tends to be extremely cumbersome, e.g., intolerant time-consuming, due to the repeated training procedures. Naturally, a straightforward ambition for CV is to validate the models with far less computational cost, while making full use of the entire given data-set for training. Thus, instead of holding out the given data, a cheap and theoretically guaranteed auxiliary/augmented validation is derived strategically in this paper. Such an embarrassingly simple strategy only needs to train models on the entire given data-set once, making the model-selection considerably efficient. In addition, the proposed validation approach is suitable for a wide range of learning settings due to the independence of both augmentation and out-of-sample estimation on learning process. In the end, we demonstrate the accuracy and computational benefits of our proposed method by extensive evaluation on multiple data-sets, models and tasks.
Automating Cluster Analysis to Generate Customer Archetypes for Residential Energy Consumers in South Africa
Jun 11, 2020
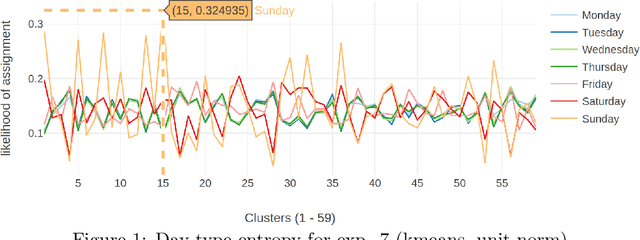
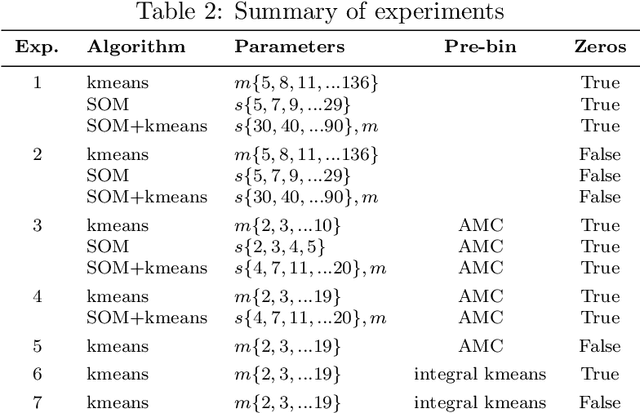
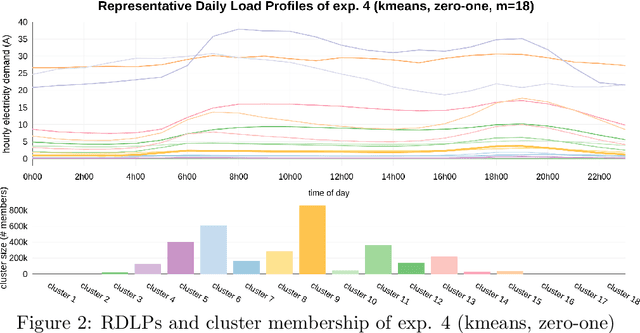
Time series clustering is frequently used in the energy domain to generate representative energy consumption patterns of households, which can be used to construct customer archetypes for long term energy planning. Selecting the optimal set of clusters however requires extensive experimentation and domain knowledge, and typically relies on a combination of metrics together with additional expert guidance through visual inspection of the clustering results. This can be time consuming, subjective and difficult to reproduce. In this work we present an approach that uses competency questions to elicit expert knowledge and to specify the requirements for creating residential energy customer archetypes from energy meter data. The approach enabled a structured and formal cluster analysis process, while easing cluster evaluation and reducing the time to select an optimal cluster set that satisfies the application requirements. The usefulness of the selected cluster set is demonstrated in a use case application that reconstructs a customer archetype developed manually by experts.
Multi-Precision Policy Enforced Training (MuPPET): A precision-switching strategy for quantised fixed-point training of CNNs
Jun 16, 2020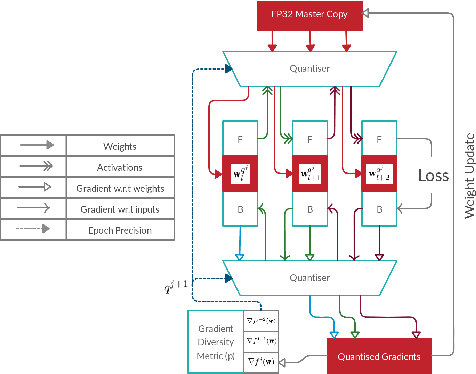
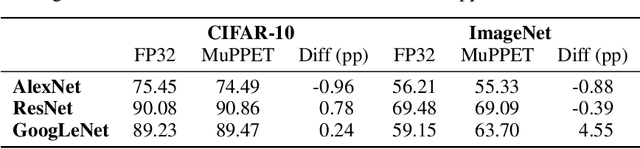
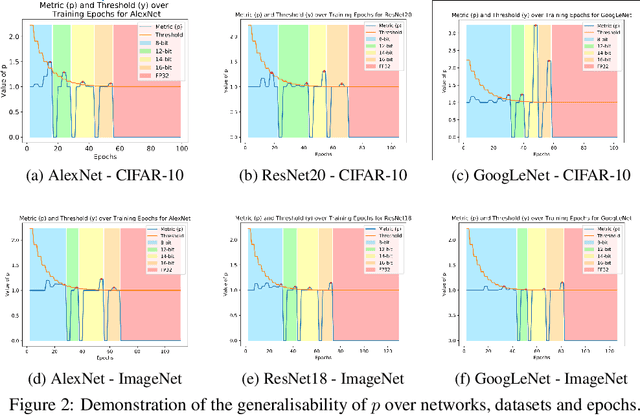

Large-scale convolutional neural networks (CNNs) suffer from very long training times, spanning from hours to weeks, limiting the productivity and experimentation of deep learning practitioners. As networks grow in size and complexity, training time can be reduced through low-precision data representations and computations. However, in doing so the final accuracy suffers due to the problem of vanishing gradients. Existing state-of-the-art methods combat this issue by means of a mixed-precision approach utilising two different precision levels, FP32 (32-bit floating-point) and FP16/FP8 (16-/8-bit floating-point), leveraging the hardware support of recent GPU architectures for FP16 operations to obtain performance gains. This work pushes the boundary of quantised training by employing a multilevel optimisation approach that utilises multiple precisions including low-precision fixed-point representations. The novel training strategy, MuPPET, combines the use of multiple number representation regimes together with a precision-switching mechanism that decides at run time the transition point between precision regimes. Overall, the proposed strategy tailors the training process to the hardware-level capabilities of the target hardware architecture and yields improvements in training time and energy efficiency compared to state-of-the-art approaches. Applying MuPPET on the training of AlexNet, ResNet18 and GoogLeNet on ImageNet (ILSVRC12) and targeting an NVIDIA Turing GPU, MuPPET achieves the same accuracy as standard full-precision training with training-time speedup of up to 1.84$\times$ and an average speedup of 1.58$\times$ across the networks.
ACP: Automatic Channel Pruning via Clustering and Swarm Intelligence Optimization for CNN
Jan 16, 2021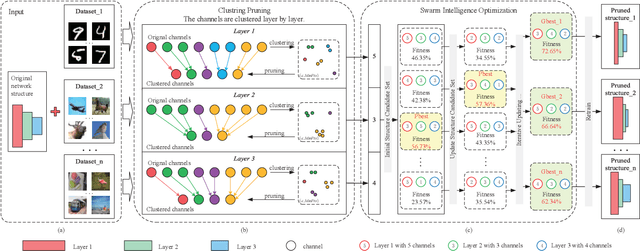
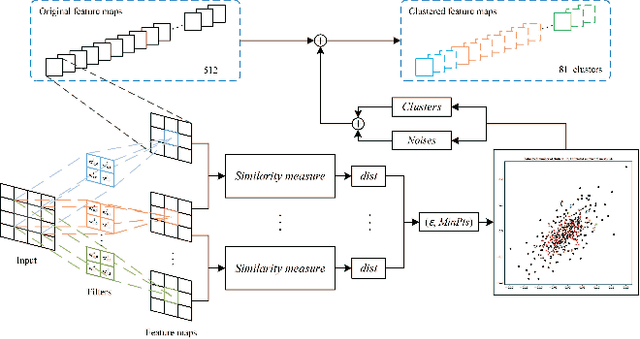
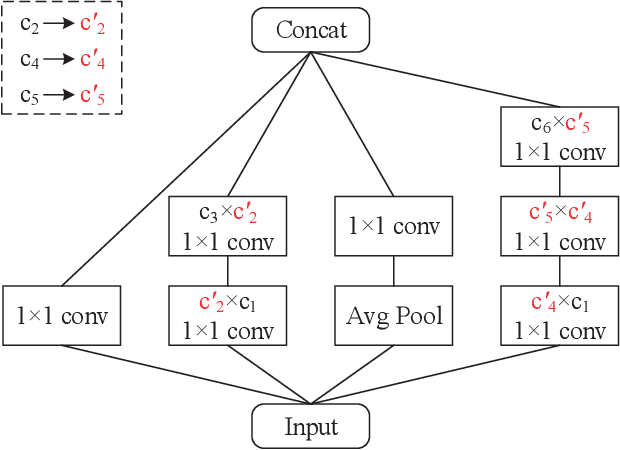
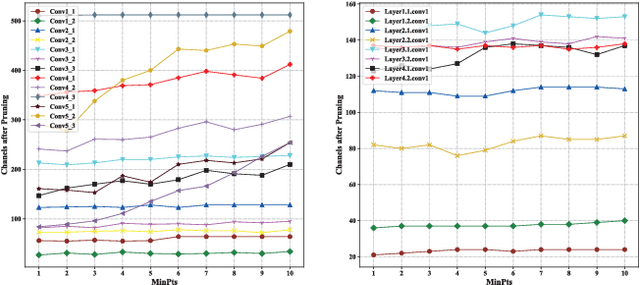
As the convolutional neural network (CNN) gets deeper and wider in recent years, the requirements for the amount of data and hardware resources have gradually increased. Meanwhile, CNN also reveals salient redundancy in several tasks. The existing magnitude-based pruning methods are efficient, but the performance of the compressed network is unpredictable. While the accuracy loss after pruning based on the structure sensitivity is relatively slight, the process is time-consuming and the algorithm complexity is notable. In this article, we propose a novel automatic channel pruning method (ACP). Specifically, we firstly perform layer-wise channel clustering via the similarity of the feature maps to perform preliminary pruning on the network. Then a population initialization method is introduced to transform the pruned structure into a candidate population. Finally, we conduct searching and optimizing iteratively based on the particle swarm optimization (PSO) to find the optimal compressed structure. The compact network is then retrained to mitigate the accuracy loss from pruning. Our method is evaluated against several state-of-the-art CNNs on three different classification datasets CIFAR-10/100 and ILSVRC-2012. On the ILSVRC-2012, when removing 64.36% parameters and 63.34% floating-point operations (FLOPs) of ResNet-50, the Top-1 and Top-5 accuracy drop are less than 0.9%. Moreover, we demonstrate that without harming overall performance it is possible to compress SSD by more than 50% on the target detection dataset PASCAL VOC. It further verifies that the proposed method can also be applied to other CNNs and application scenarios.
Practical Auto-Calibration for Spatial Scene-Understanding from Crowdsourced Dashcamera Videos
Dec 15, 2020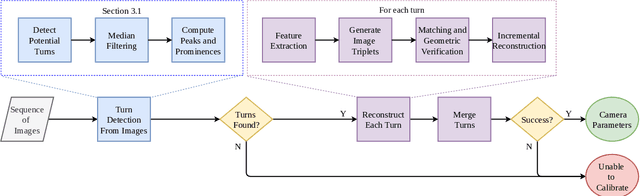
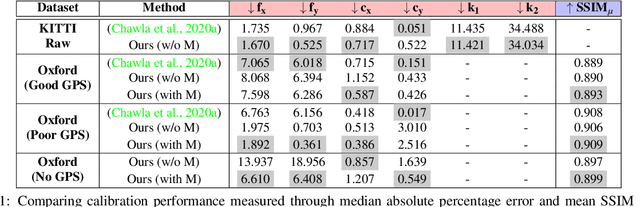


Spatial scene-understanding, including dense depth and ego-motion estimation, is an important problem in computer vision for autonomous vehicles and advanced driver assistance systems. Thus, it is beneficial to design perception modules that can utilize crowdsourced videos collected from arbitrary vehicular onboard or dashboard cameras. However, the intrinsic parameters corresponding to such cameras are often unknown or change over time. Typical manual calibration approaches require objects such as a chessboard or additional scene-specific information. On the other hand, automatic camera calibration does not have such requirements. Yet, the automatic calibration of dashboard cameras is challenging as forward and planar navigation results in critical motion sequences with reconstruction ambiguities. Structure reconstruction of complete visual-sequences that may contain tens of thousands of images is also computationally untenable. Here, we propose a system for practical monocular onboard camera auto-calibration from crowdsourced videos. We show the effectiveness of our proposed system on the KITTI raw, Oxford RobotCar, and the crowdsourced D$^2$-City datasets in varying conditions. Finally, we demonstrate its application for accurate monocular dense depth and ego-motion estimation on uncalibrated videos.
YieldNet: A Convolutional Neural Network for Simultaneous Corn and Soybean Yield Prediction Based on Remote Sensing Data
Dec 05, 2020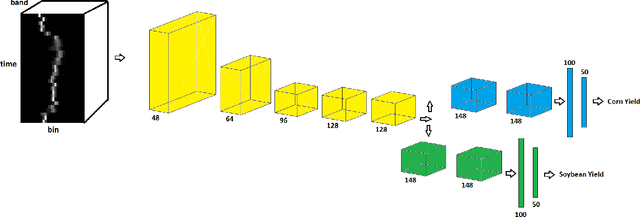
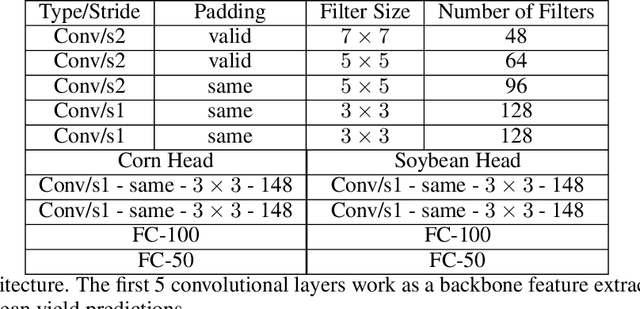
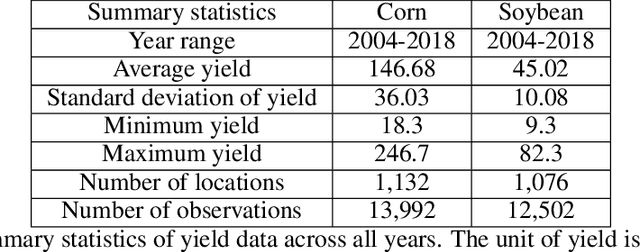
Large scale crop yield estimation is, in part, made possible due to the availability of remote sensing data allowing for the continuous monitoring of crops throughout its growth state. Having this information allows stakeholders the ability to make real-time decisions to maximize yield potential. Although various models exist that predict yield from remote sensing data, there currently does not exist an approach that can estimate yield for multiple crops simultaneously, and thus leads to more accurate predictions. A model that predicts yield of multiple crops and concurrently considers the interaction between multiple crop's yield. We propose a new model called YieldNet which utilizes a novel deep learning framework that uses transfer learning between corn and soybean yield predictions by sharing the weights of the backbone feature extractor. Additionally, to consider the multi-target response variable, we propose a new loss function. Numerical results demonstrate that our proposed method accurately predicts yield from one to four months before the harvest, and is competitive to other state-of-the-art approaches.