 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaffe Barista: Brewing Caffe with FPGAs in the Training Loop
Jun 18, 2020
As the complexity of deep learning (DL) models increases, their compute requirements increase accordingly. Deploying a Convolutional Neural Network (CNN) involves two phases: training and inference. With the inference task typically taking place on resource-constrained devices, a lot of research has explored the field of low-power inference on custom hardware accelerators. On the other hand, training is both more compute- and memory-intensive and is primarily performed on power-hungry GPUs in large-scale data centres. CNN training on FPGAs is a nascent field of research. This is primarily due to the lack of tools to easily prototype and deploy various hardware and/or algorithmic techniques for power-efficient CNN training. This work presents Barista, an automated toolflow that provides seamless integration of FPGAs into the training of CNNs within the popular deep learning framework Caffe. To the best of our knowledge, this is the only tool that allows for such versatile and rapid deployment of hardware and algorithms for the FPGA-based training of CNNs, providing the necessary infrastructure for further research and development.
Multi-Precision Policy Enforced Training (MuPPET): A precision-switching strategy for quantised fixed-point training of CNNs
Jun 16, 2020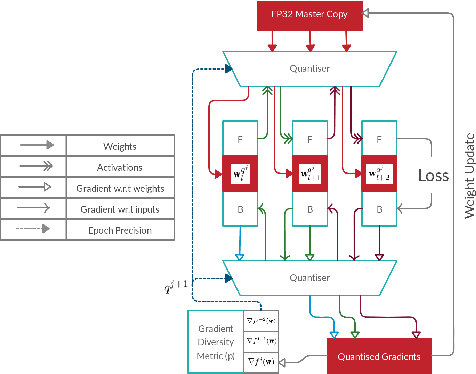
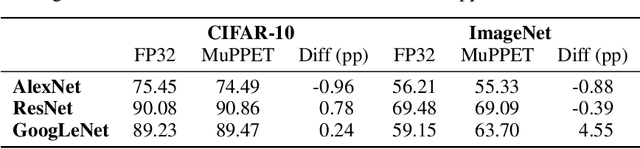
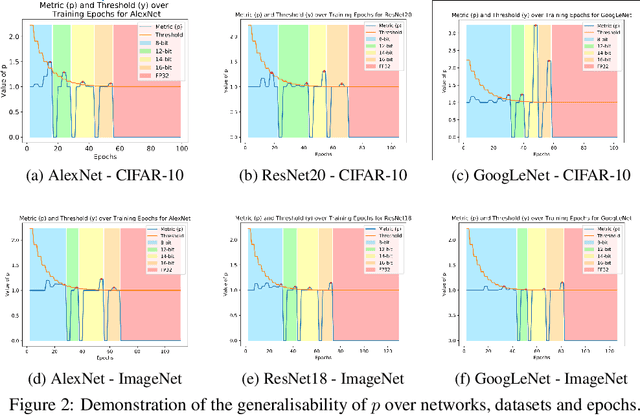

Large-scale convolutional neural networks (CNNs) suffer from very long training times, spanning from hours to weeks, limiting the productivity and experimentation of deep learning practitioners. As networks grow in size and complexity, training time can be reduced through low-precision data representations and computations. However, in doing so the final accuracy suffers due to the problem of vanishing gradients. Existing state-of-the-art methods combat this issue by means of a mixed-precision approach utilising two different precision levels, FP32 (32-bit floating-point) and FP16/FP8 (16-/8-bit floating-point), leveraging the hardware support of recent GPU architectures for FP16 operations to obtain performance gains. This work pushes the boundary of quantised training by employing a multilevel optimisation approach that utilises multiple precisions including low-precision fixed-point representations. The novel training strategy, MuPPET, combines the use of multiple number representation regimes together with a precision-switching mechanism that decides at run time the transition point between precision regimes. Overall, the proposed strategy tailors the training process to the hardware-level capabilities of the target hardware architecture and yields improvements in training time and energy efficiency compared to state-of-the-art approaches. Applying MuPPET on the training of AlexNet, ResNet18 and GoogLeNet on ImageNet (ILSVRC12) and targeting an NVIDIA Turing GPU, MuPPET achieves the same accuracy as standard full-precision training with training-time speedup of up to 1.84$\times$ and an average speedup of 1.58$\times$ across the networks.