 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Cost On-device Partial Domain Adaptation : Enabling efficient CNN retraining on edge devices
Mar 01, 2022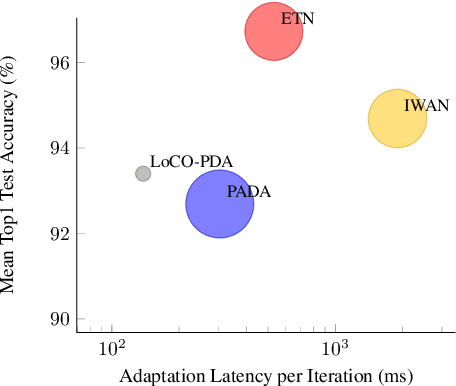
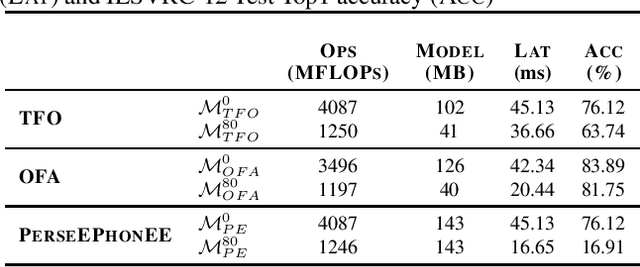
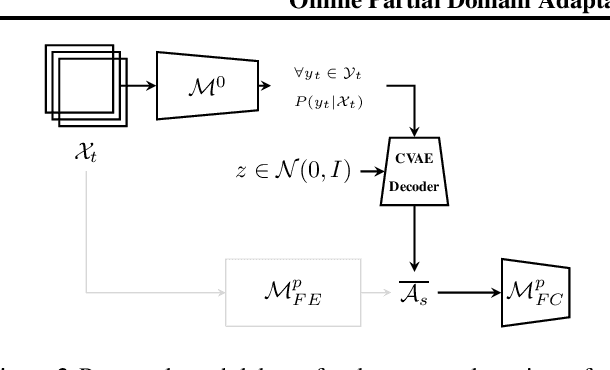
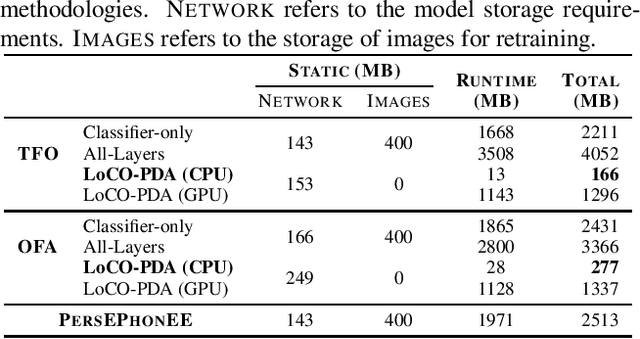
With the increased deployment of Convolutional Neural Networks (CNNs) on edge devices, the uncertainty of the observed data distribution upon deployment has led researchers to to utilise large and extensive datasets such as ILSVRC'12 to train CNNs. Consequently, it is likely that the observed data distribution upon deployment is a subset of the training data distribution. In such cases, not adapting a network to the observed data distribution can cause performance degradation due to negative transfer and alleviating this is the focus of Partial Domain Adaptation (PDA). Current works targeting PDA do not focus on performing the domain adaptation on an edge device, adapting to a changing target distribution or reducing the cost of deploying the adapted network. This work proposes a novel PDA methodology that targets all of these directions and opens avenues for on-device PDA. LoCO-PDA adapts a deployed network to the observed data distribution by enabling it to be retrained on an edge device. Across subsets of the ILSVRC12 dataset, LoCO-PDA improves classification accuracy by 3.04pp on average while achieving up to 15.1x reduction in retraining memory consumption and 2.07x improvement in inference latency on the NVIDIA Jetson TX2. The work is open-sourced at \emph{link removed for anonymity}.
perf4sight: A toolflow to model CNN training performance on Edge GPUs
Aug 12, 2021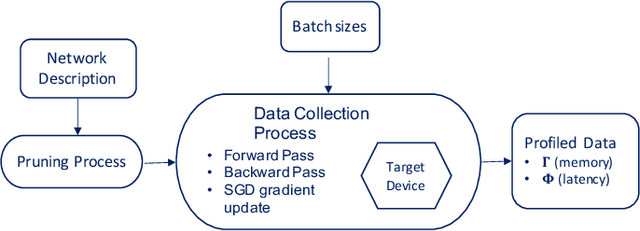
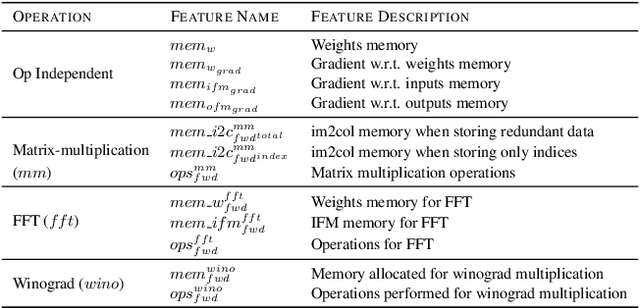
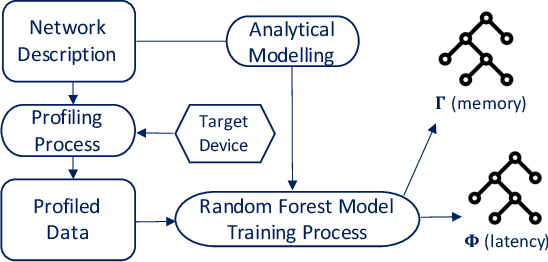

The increased memory and processing capabilities of today's edge devices create opportunities for greater edge intelligence. In the domain of vision, the ability to adapt a Convolutional Neural Network's (CNN) structure and parameters to the input data distribution leads to systems with lower memory footprint, latency and power consumption. However, due to the limited compute resources and memory budget on edge devices, it is necessary for the system to be able to predict the latency and memory footprint of the training process in order to identify favourable training configurations of the network topology and device combination for efficient network adaptation. This work proposes perf4sight, an automated methodology for developing accurate models that predict CNN training memory footprint and latency given a target device and network. This enables rapid identification of network topologies that can be retrained on the edge device with low resource consumption. With PyTorch as the framework and NVIDIA Jetson TX2 as the target device, the developed models predict training memory footprint and latency with 95% and 91% accuracy respectively for a wide range of networks, opening the path towards efficient network adaptation on edge GPUs.
Caffe Barista: Brewing Caffe with FPGAs in the Training Loop
Jun 18, 2020
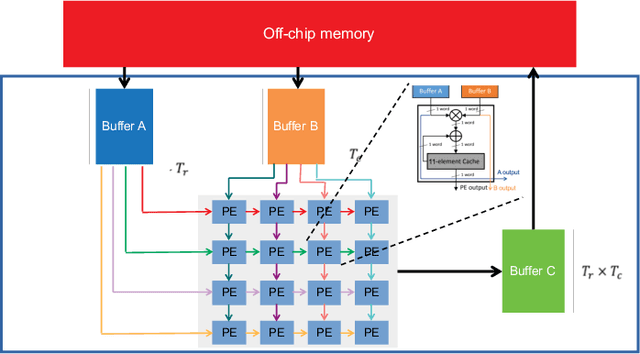
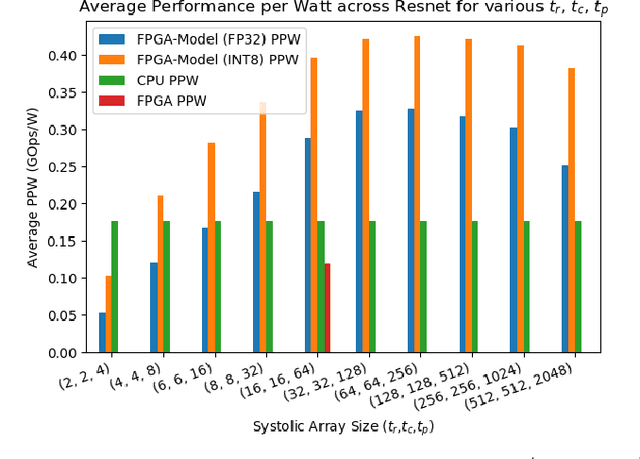
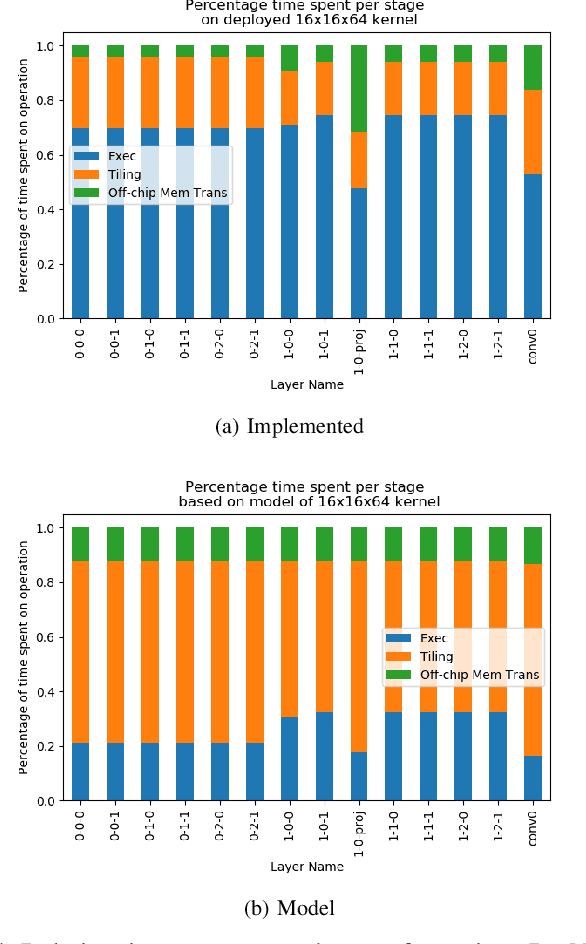
As the complexity of deep learning (DL) models increases, their compute requirements increase accordingly. Deploying a Convolutional Neural Network (CNN) involves two phases: training and inference. With the inference task typically taking place on resource-constrained devices, a lot of research has explored the field of low-power inference on custom hardware accelerators. On the other hand, training is both more compute- and memory-intensive and is primarily performed on power-hungry GPUs in large-scale data centres. CNN training on FPGAs is a nascent field of research. This is primarily due to the lack of tools to easily prototype and deploy various hardware and/or algorithmic techniques for power-efficient CNN training. This work presents Barista, an automated toolflow that provides seamless integration of FPGAs into the training of CNNs within the popular deep learning framework Caffe. To the best of our knowledge, this is the only tool that allows for such versatile and rapid deployment of hardware and algorithms for the FPGA-based training of CNNs, providing the necessary infrastructure for further research and development.
Multi-Precision Policy Enforced Training (MuPPET): A precision-switching strategy for quantised fixed-point training of CNNs
Jun 16, 2020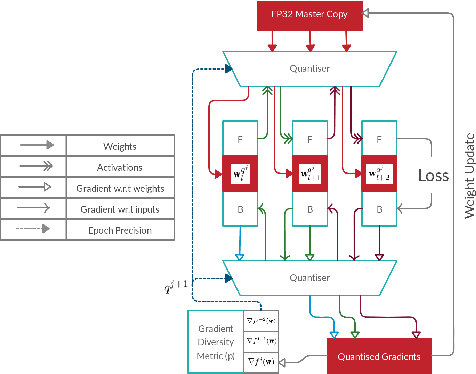
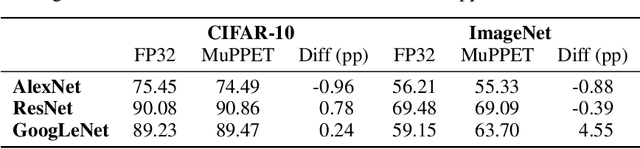
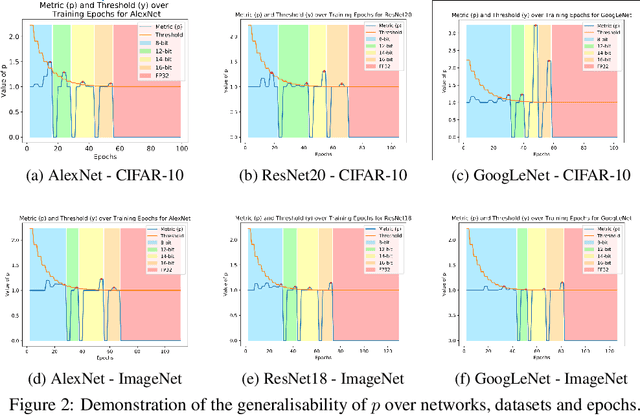

Large-scale convolutional neural networks (CNNs) suffer from very long training times, spanning from hours to weeks, limiting the productivity and experimentation of deep learning practitioners. As networks grow in size and complexity, training time can be reduced through low-precision data representations and computations. However, in doing so the final accuracy suffers due to the problem of vanishing gradients. Existing state-of-the-art methods combat this issue by means of a mixed-precision approach utilising two different precision levels, FP32 (32-bit floating-point) and FP16/FP8 (16-/8-bit floating-point), leveraging the hardware support of recent GPU architectures for FP16 operations to obtain performance gains. This work pushes the boundary of quantised training by employing a multilevel optimisation approach that utilises multiple precisions including low-precision fixed-point representations. The novel training strategy, MuPPET, combines the use of multiple number representation regimes together with a precision-switching mechanism that decides at run time the transition point between precision regimes. Overall, the proposed strategy tailors the training process to the hardware-level capabilities of the target hardware architecture and yields improvements in training time and energy efficiency compared to state-of-the-art approaches. Applying MuPPET on the training of AlexNet, ResNet18 and GoogLeNet on ImageNet (ILSVRC12) and targeting an NVIDIA Turing GPU, MuPPET achieves the same accuracy as standard full-precision training with training-time speedup of up to 1.84$\times$ and an average speedup of 1.58$\times$ across the networks.
Now that I can see, I can improve: Enabling data-driven finetuning of CNNs on the edge
Jun 15, 2020

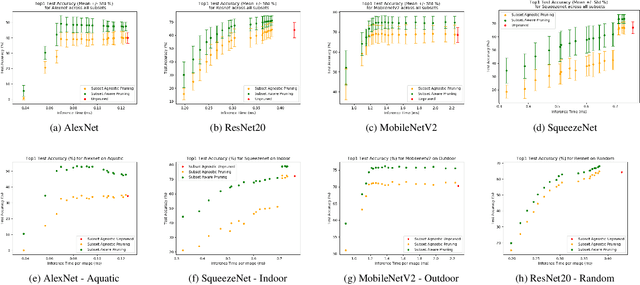
In today's world, a vast amount of data is being generated by edge devices that can be used as valuable training data to improve the performance of machine learning algorithms in terms of the achieved accuracy or to reduce the compute requirements of the model. However, due to user data privacy concerns as well as storage and communication bandwidth limitations, this data cannot be moved from the device to the data centre for further improvement of the model and subsequent deployment. As such there is a need for increased edge intelligence, where the deployed models can be fine-tuned on the edge, leading to improved accuracy and/or reducing the model's workload as well as its memory and power footprint. In the case of Convolutional Neural Networks (CNNs), both the weights of the network as well as its topology can be tuned to adapt to the data that it processes. This paper provides a first step towards enabling CNN finetuning on an edge device based on structured pruning. It explores the performance gains and costs of doing so and presents an extensible open-source framework that allows the deployment of such approaches on a wide range of network architectures and devices. The results show that on average, data-aware pruning with retraining can provide 10.2pp increased accuracy over a wide range of subsets, networks and pruning levels with a maximum improvement of 42.0pp over pruning and retraining in a manner agnostic to the data being processed by the network.