 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ActionXPose: A Novel 2D Multi-view Pose-based Algorithm for Real-time Human Action Recognition
Oct 29, 2018
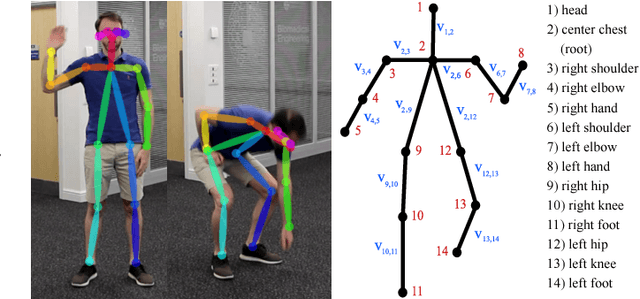
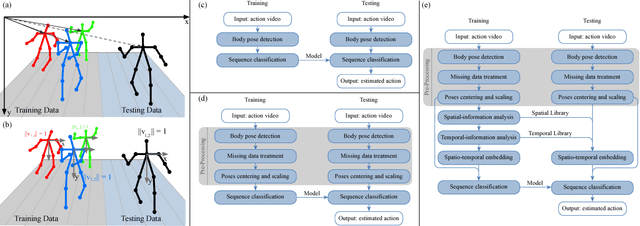
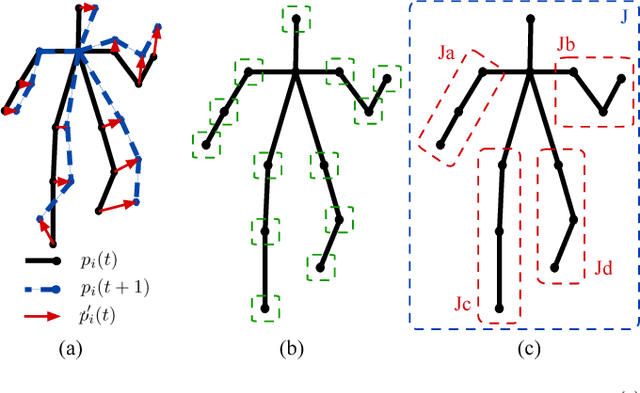

We present ActionXPose, a novel 2D pose-based algorithm for posture-level Human Action Recognition (HAR). The proposed approach exploits 2D human poses provided by OpenPose detector from RGB videos. ActionXPose aims to process poses data to be provided to a Long Short-Term Memory Neural Network and to a 1D Convolutional Neural Network, which solve the classification problem. ActionXPose is one of the first algorithms that exploits 2D human poses for HAR. The algorithm has real-time performance and it is robust to camera movings, subject proximity changes, viewpoint changes, subject appearance changes and provide high generalization degree. In fact, extensive simulations show that ActionXPose can be successfully trained using different datasets at once. State-of-the-art performance on popular datasets for posture-related HAR problems (i3DPost, KTH) are provided and results are compared with those obtained by other methods, including the selected ActionXPose baseline. Moreover, we also proposed two novel datasets called MPOSE and ISLD recorded in our Intelligent Sensing Lab, to show ActionXPose generalization performance.
Machine Learning in Magnetic Resonance Imaging: Image Reconstruction
Dec 09, 2020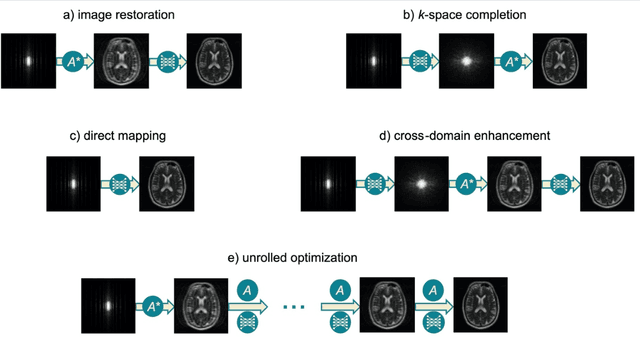
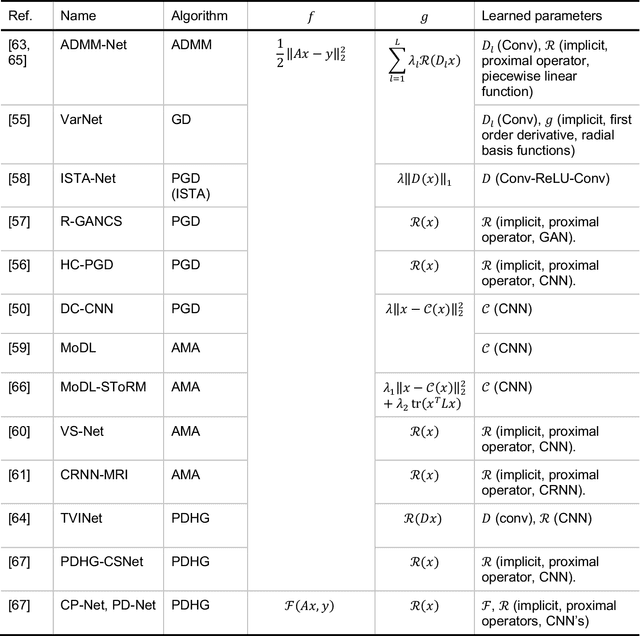
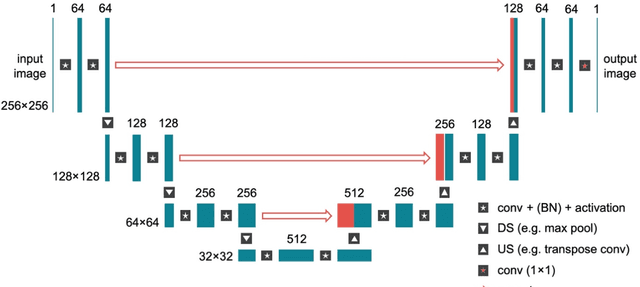
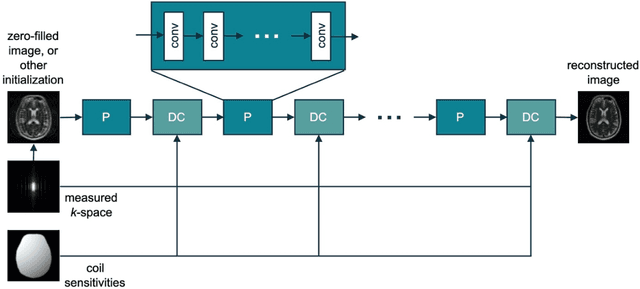
Magnetic Resonance Imaging (MRI) plays a vital role in diagnosis, management and monitoring of many diseases. However, it is an inherently slow imaging technique. Over the last 20 years, parallel imaging, temporal encoding and compressed sensing have enabled substantial speed-ups in the acquisition of MRI data, by accurately recovering missing lines of k-space data. However, clinical uptake of vastly accelerated acquisitions has been limited, in particular in compressed sensing, due to the time-consuming nature of the reconstructions and unnatural looking images. Following the success of machine learning in a wide range of imaging tasks, there has been a recent explosion in the use of machine learning in the field of MRI image reconstruction. A wide range of approaches have been proposed, which can be applied in k-space and/or image-space. Promising results have been demonstrated from a range of methods, enabling natural looking images and rapid computation. In this review article we summarize the current machine learning approaches used in MRI reconstruction, discuss their drawbacks, clinical applications, and current trends.
Brain tumour segmentation using cascaded 3D densely-connected U-net
Sep 16, 2020

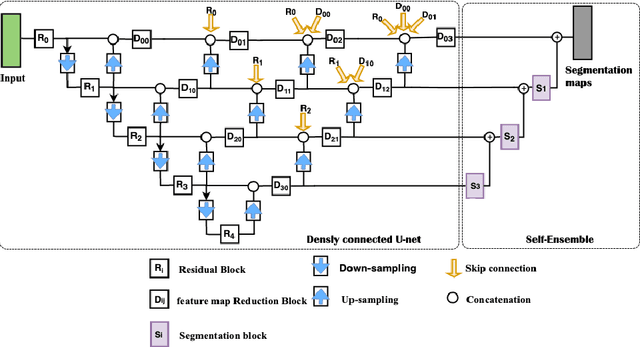
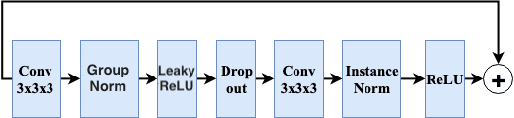
Accurate brain tumour segmentation is a crucial step towards improving disease diagnosis and proper treatment planning. In this paper, we propose a deep-learning based method to segment a brain tumour into its subregions: whole tumour, tumour core and enhancing tumour. The proposed architecture is a 3D convolutional neural network based on a variant of the U-Net architecture of Ronneberger et al. [17] with three main modifications: (i) a heavy encoder, light decoder structure using residual blocks (ii) employment of dense blocks instead of skip connections, and (iii) utilization of self-ensembling in the decoder part of the network. The network was trained and tested using two different approaches: a multitask framework to segment all tumour subregions at the same time and a three-stage cascaded framework to segment one sub-region at a time. An ensemble of the results from both frameworks was also computed. To address the class imbalance issue, appropriate patch extraction was employed in a pre-processing step. The connected component analysis was utilized in the post-processing step to reduce false positive predictions. Experimental results on the BraTS20 validation dataset demonstrates that the proposed model achieved average Dice Scores of 0.90, 0.82, and 0.78 for whole tumour, tumour core and enhancing tumour respectively.
A Three-Stage Algorithm for the Large Scale Dynamic Vehicle Routing Problem with an Industry 4.0 Approach
Aug 26, 2020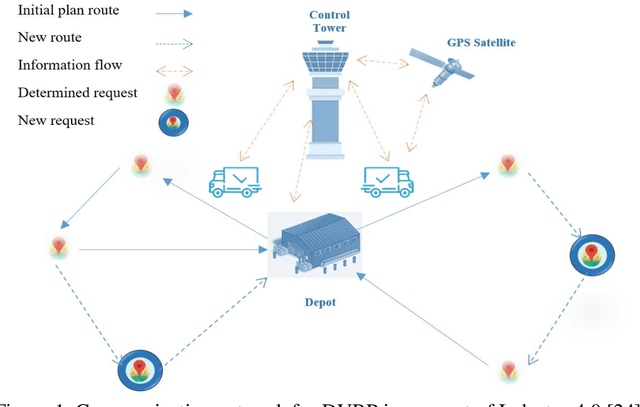

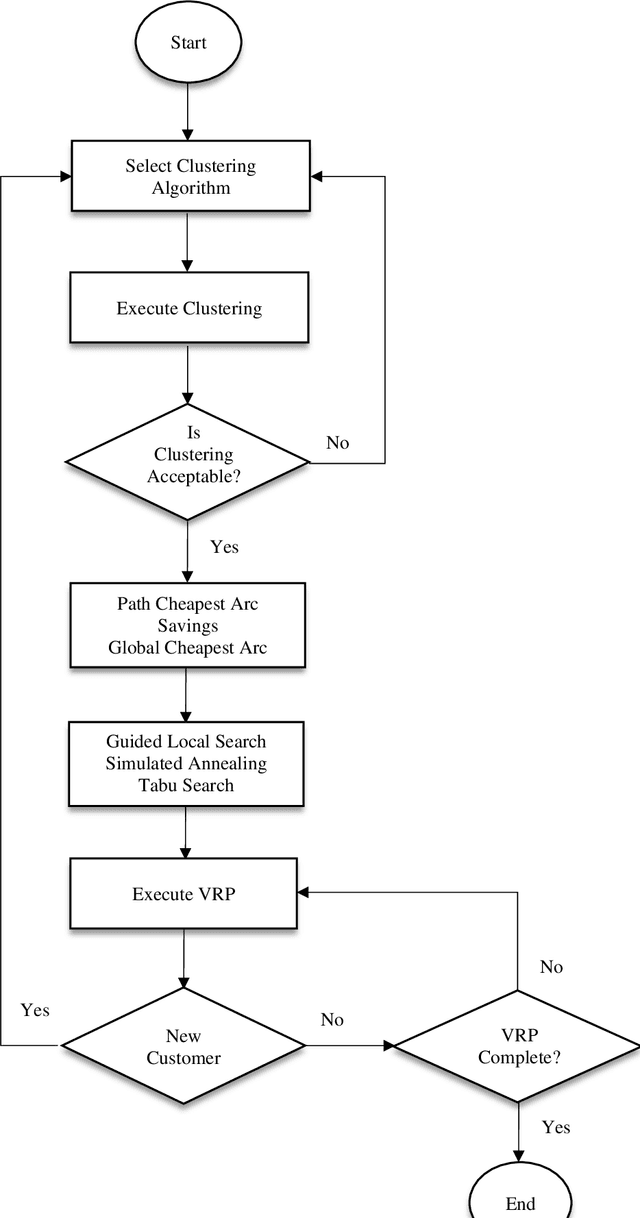
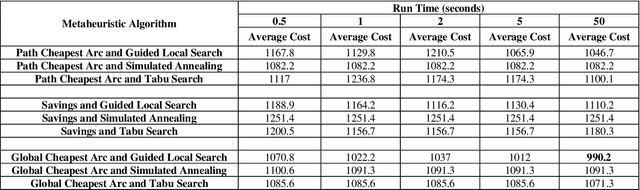
Industry 4.0 is a concept which helps companies to have a smart supply chain system when they are faced with a dynamic process. As Industry 4.0 focuses on mobility and real-time integration, it is a good framework for a Dynamic Vehicle Routing problem (DVRP). The main objective of this research is to solve the DVRP on a large-scale size. The aim of this study is to show that the delivery vehicles must serve customer demands from a common depot to have a minimum transit cost without exceeding the capacity constraint of each vehicle. In VRP, to reach an exact solution is quite difficult, and in large-size real world problems it is often impossible. Also, the computational time complexity of this type of problem grows exponentially. In order to find optimal answers for this problem in medium and large dimensions, using a heuristic approach is recommended as the best approach. A hierarchical approach consisting of three stages as cluster-first, route-construction second, route-improvement third is proposed. In the first stage, customers are clustered based on the number of vehicles with different clustering algorithms (i.e., K-mean, GMM, and BIRCH algorithms). In the second stage, the DVRP is solved using construction algorithms and in the third stage improvement algorithms are applied. The second stage is solved using construction algorithms (i.e. Savings algorithm, path cheapest arc algorithm, etc.). In the third stage, improvement algorithms such as Guided Local Search, Simulated Annealing and Tabu Search are applied. One of the main contributions of this paper is that the proposed approach can deal with large-size real world problems to decrease the computational time complexity. The results of this approach confirmed that the proposed methodology is applicable.
Panoster: End-to-end Panoptic Segmentation of LiDAR Point Clouds
Oct 28, 2020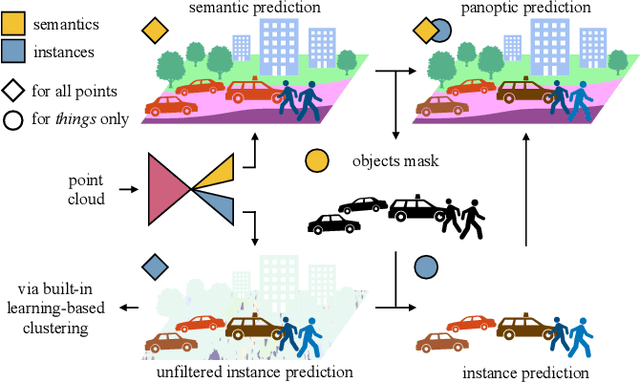
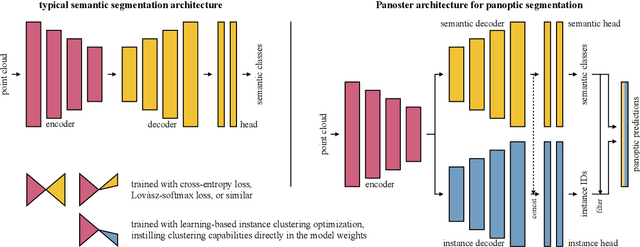
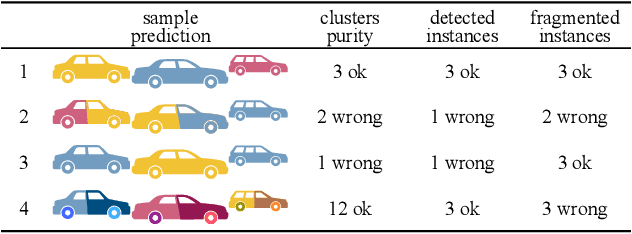
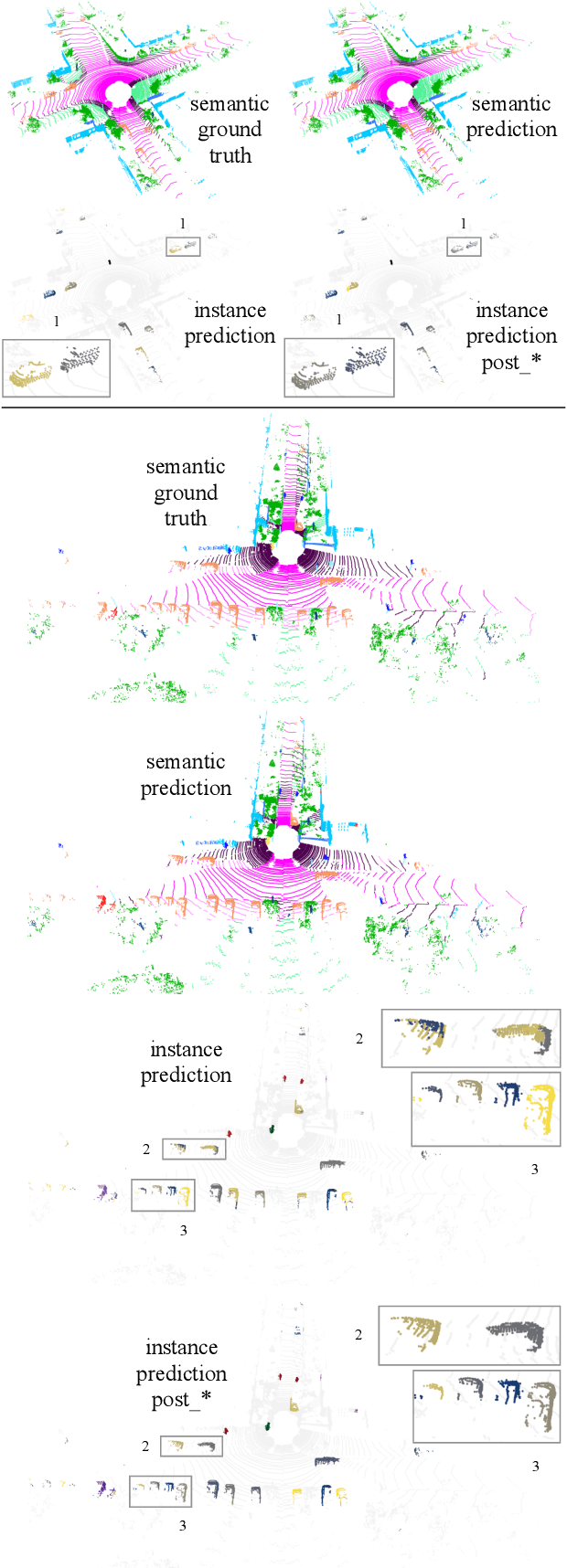
Panoptic segmentation has recently unified semantic and instance segmentation, previously addressed separately, thus taking a step further towards creating more comprehensive and efficient perception systems. In this paper, we present Panoster, a novel proposal-free panoptic segmentation method for point clouds. Unlike previous approaches relying on several steps to group pixels or points into objects, Panoster proposes a simplified framework incorporating a learning-based clustering solution to identify instances. At inference time, this acts as a class-agnostic semantic segmentation, allowing Panoster to be fast, while outperforming prior methods in terms of accuracy. Additionally, we showcase how our approach can be flexibly and effectively applied on diverse existing semantic architectures to deliver panoptic predictions.
Intelligent Icing Detection Model of Wind Turbine Blades Based on SCADA data
Jan 20, 2021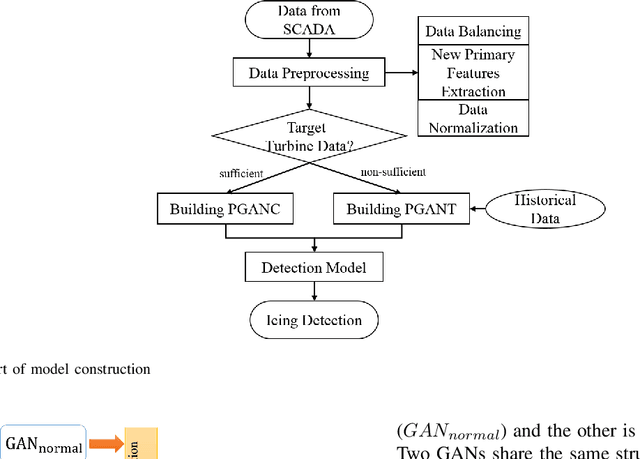
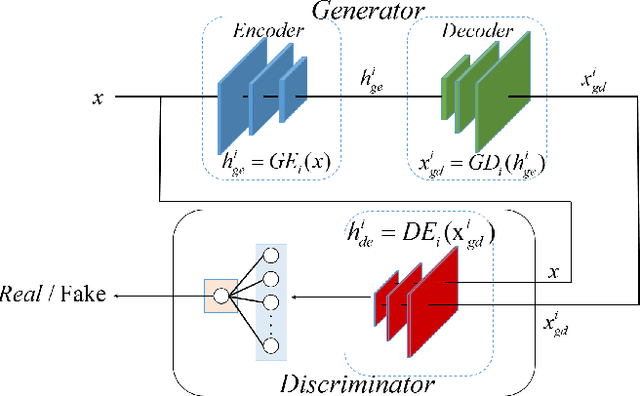
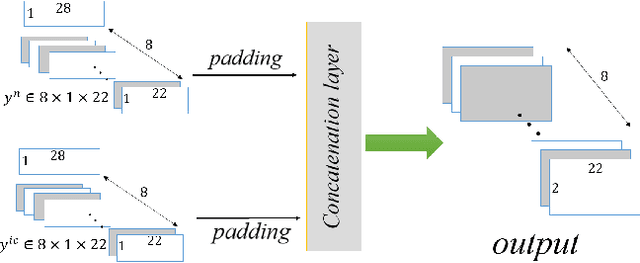
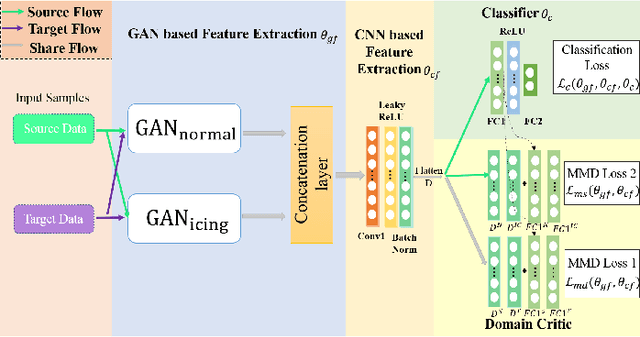
Diagnosis of ice accretion on wind turbine blades is all the time a hard nut to crack in condition monitoring of wind farms. Existing methods focus on mechanism analysis of icing process, deviation degree analysis of feature engineering. However, there have not been deep researches of neural networks applied in this field at present. Supervisory control and data acquisition (SCADA) makes it possible to train networks through continuously providing not only operation parameters and performance parameters of wind turbines but also environmental parameters and operation modes. This paper explores the possibility that using convolutional neural networks (CNNs), generative adversarial networks (GANs) and domain adaption learning to establish intelligent diagnosis frameworks under different training scenarios. Specifically, PGANC and PGANT are proposed for sufficient and non-sufficient target wind turbine labeled data, respectively. The basic idea is that we consider a two-stage training with parallel GANs, which are aimed at capturing intrinsic features for normal and icing samples, followed by classification CNN or domain adaption module in various training cases. Model validation on three wind turbine SCADA data shows that two-stage training can effectively improve the model performance. Besides, if there is no sufficient labeled data for a target turbine, which is an extremely common phenomenon in real industrial practices, the addition of domain adaption learning makes the trained model show better performance. Overall, our proposed intelligent diagnosis frameworks can achieve more accurate detection on the same wind turbine and more generalized capability on a new wind turbine, compared with other machine learning models and conventional CNNs.
A Nonconvex Framework for Structured Dynamic Covariance Recovery
Nov 11, 2020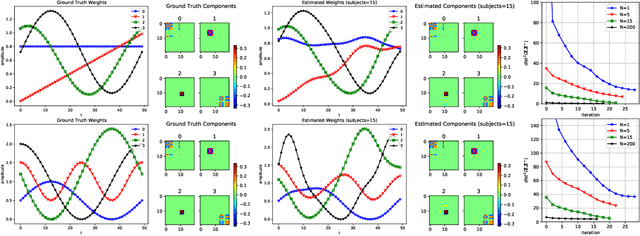
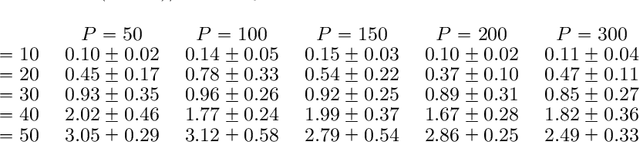
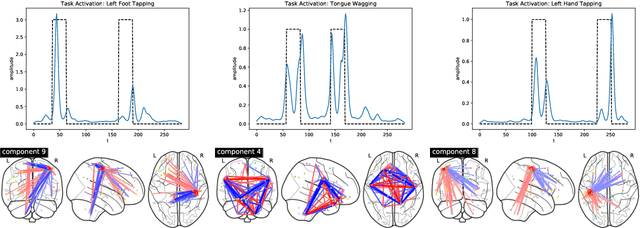
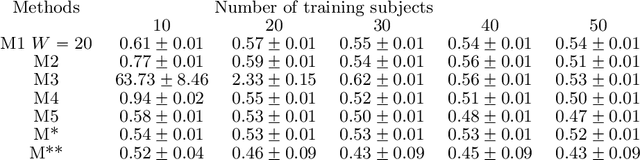
We propose a flexible yet interpretable model for high-dimensional data with time-varying second order statistics, motivated and applied to functional neuroimaging data. Motivated by the neuroscience literature, we factorize the covariances into sparse spatial and smooth temporal components. While this factorization results in both parsimony and domain interpretability, the resulting estimation problem is nonconvex. To this end, we design a two-stage optimization scheme with a carefully tailored spectral initialization, combined with iteratively refined alternating projected gradient descent. We prove a linear convergence rate up to a nontrivial statistical error for the proposed descent scheme and establish sample complexity guarantees for the estimator. We further quantify the statistical error for the multivariate Gaussian case. Empirical results using simulated and real brain imaging data illustrate that our approach outperforms existing baselines.
ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on
Jan 13, 2021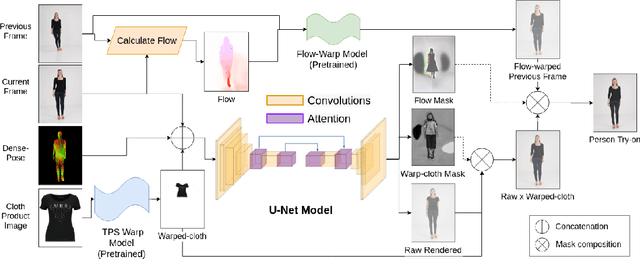

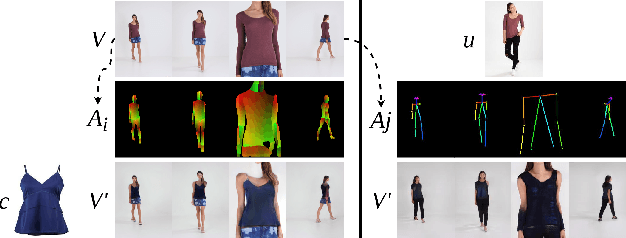
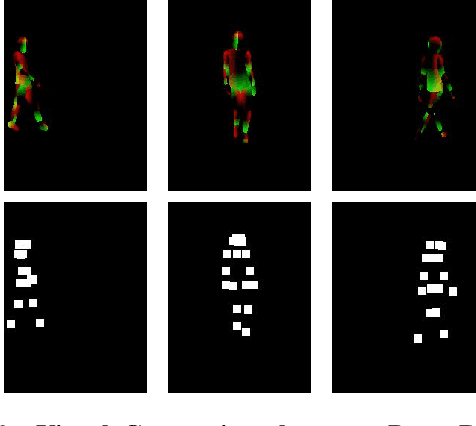
Virtual try-on has garnered interest as a neural rendering benchmark task to evaluate complex object transfer and scene composition. Recent works in virtual clothing try-on feature a plethora of possible architectural and data representation choices. However, they present little clarity on quantifying the isolated visual effect of each choice, nor do they specify the hyperparameter details that are key to experimental reproduction. Our work, ShineOn, approaches the try-on task from a bottom-up approach and aims to shine light on the visual and quantitative effects of each experiment. We build a series of scientific experiments to isolate effective design choices in video synthesis for virtual clothing try-on. Specifically, we investigate the effect of different pose annotations, self-attention layer placement, and activation functions on the quantitative and qualitative performance of video virtual try-on. We find that DensePose annotations not only enhance face details but also decrease memory usage and training time. Next, we find that attention layers improve face and neck quality. Finally, we show that GELU and ReLU activation functions are the most effective in our experiments despite the appeal of newer activations such as Swish and Sine. We will release a well-organized code base, hyperparameters, and model checkpoints to support the reproducibility of our results. We expect our extensive experiments and code to greatly inform future design choices in video virtual try-on. Our code may be accessed at https://github.com/andrewjong/ShineOn-Virtual-Tryon.
Many-shot from Low-shot: Learning to Annotate using Mixed Supervision for Object Detection
Aug 26, 2020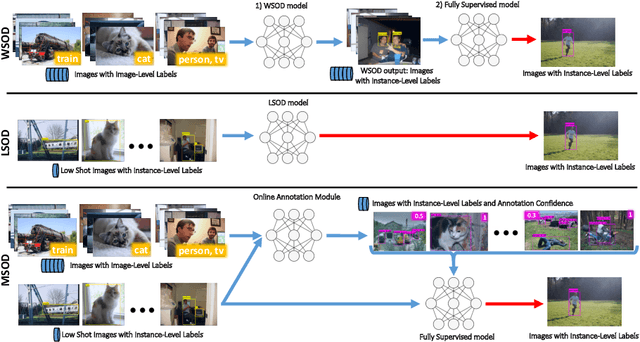
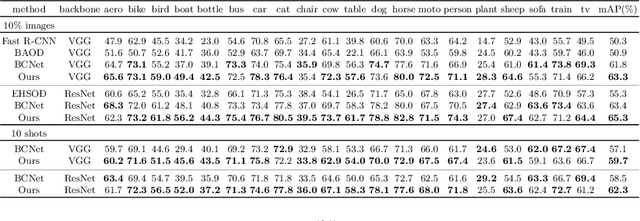
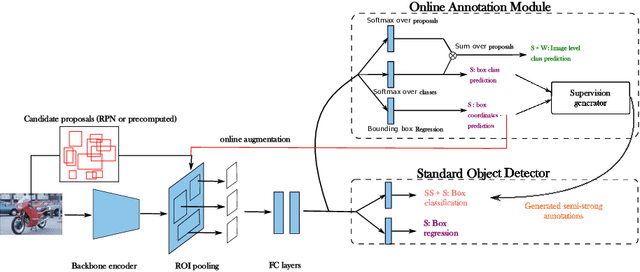
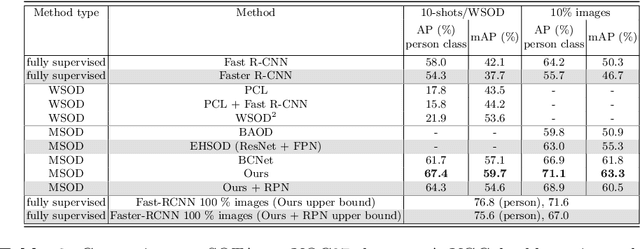
Object detection has witnessed significant progress by relying on large, manually annotated datasets. Annotating such datasets is highly time consuming and expensive, which motivates the development of weakly supervised and few-shot object detection methods. However, these methods largely underperform with respect to their strongly supervised counterpart, as weak training signals \emph{often} result in partial or oversized detections. Towards solving this problem we introduce, for the first time, an online annotation module (OAM) that learns to generate a many-shot set of \emph{reliable} annotations from a larger volume of weakly labelled images. Our OAM can be jointly trained with any fully supervised two-stage object detection method, providing additional training annotations on the fly. This results in a fully end-to-end strategy that only requires a low-shot set of fully annotated images. The integration of the OAM with Fast(er) R-CNN improves their performance by $17\%$ mAP, $9\%$ AP50 on PASCAL VOC 2007 and MS-COCO benchmarks, and significantly outperforms competing methods using mixed supervision.
Inverse Optimal Control from Demonstration Segments
Oct 28, 2020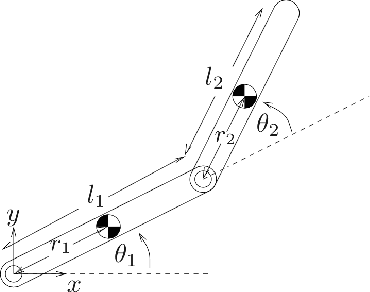
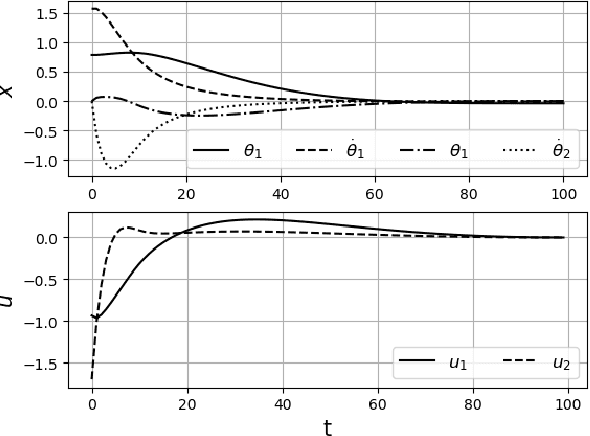
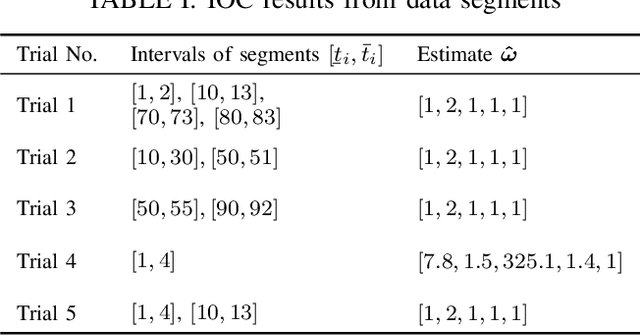
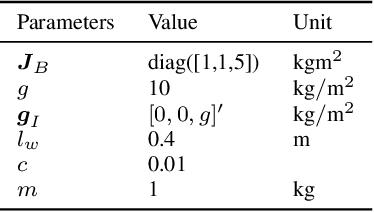
This paper develops an inverse optimal control method to learn an objective function from segments of demonstrations. Here, each segment is part of an optimal trajectory within any time interval of the horizon. The unknown objective function is parameterized as a weighted sum of given features with unknown weights. The proposed method shows that each trajectory segment can be transformed into a linear constraint to the unknown weights, and then all available segments are incrementally incorporated to solve for the unknown weights. Effectiveness of the proposed method is shown on a simulated 2-link robot arm and a 6-DoF maneuvering quadrotor system, in each of which only segment data of the systems' trajectories are available.