 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
"Drunk Man" Saves Our Lives: Route Planning by a Biased Random Walk Mode
Oct 04, 2020

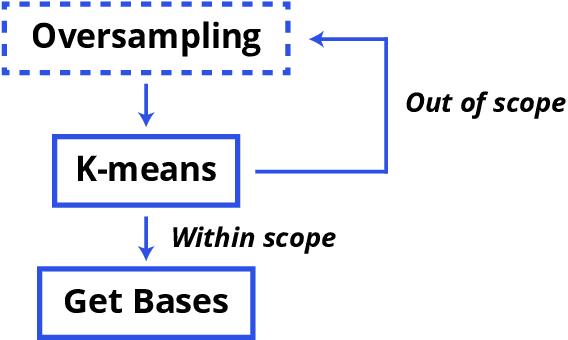
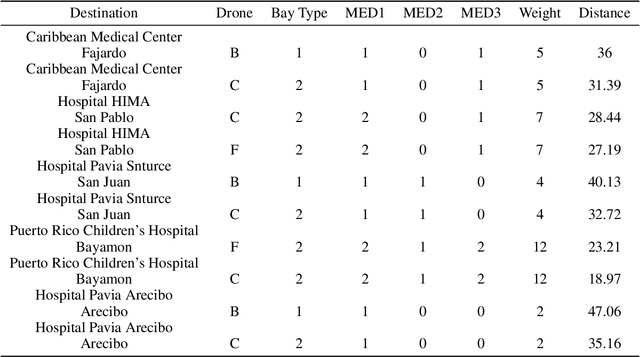
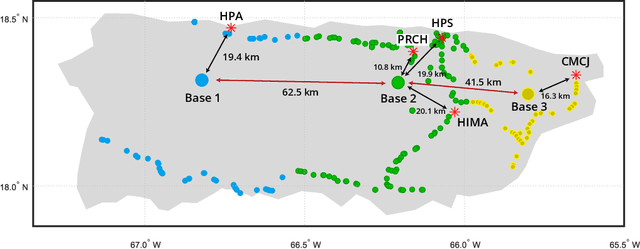
Based on the hurricane striking Puerto Rico in 2017, we developed a transportable disaster response system "DroneGo" featuring a drone fleet capable of delivering the medical package and videoing roads. Covering with a genetic algorithm and a biased random walk model mimicking a drunk man to explore feasible routes on a field with altitude and road information. A proposal mechanism guaranteeing stochasticity and an objective function biasing randomness are combined. The results showed high performance though time-consuming.
Robust Multi-class Feature Selection via $l_{2,0}$-Norm Regularization Minimization
Oct 08, 2020
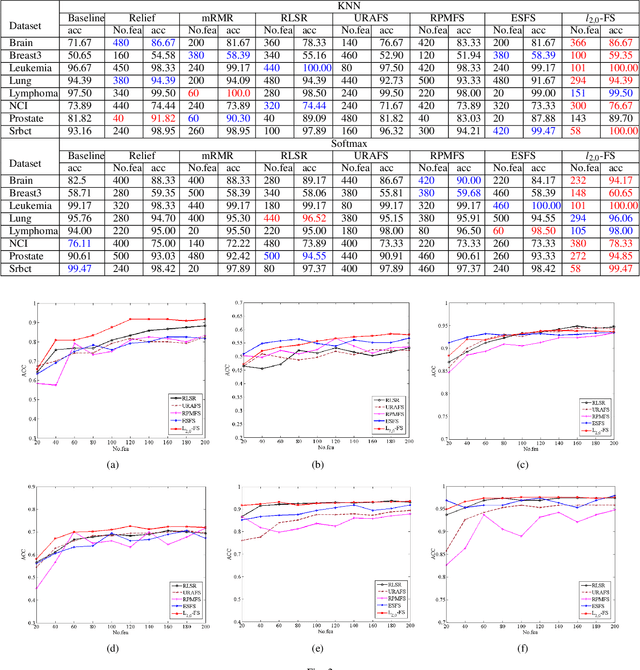
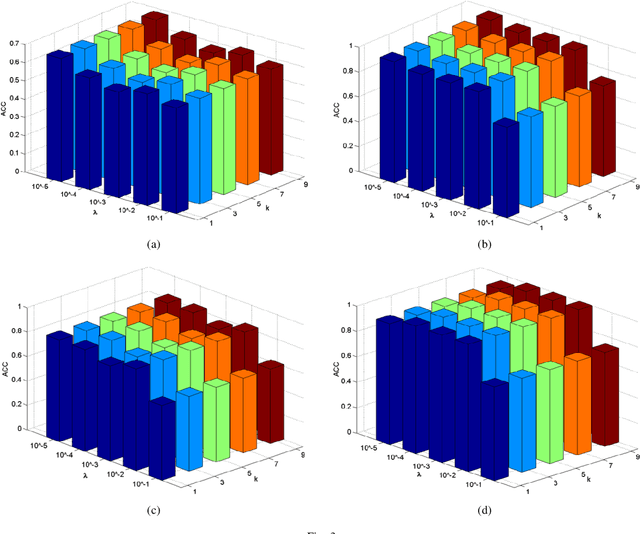
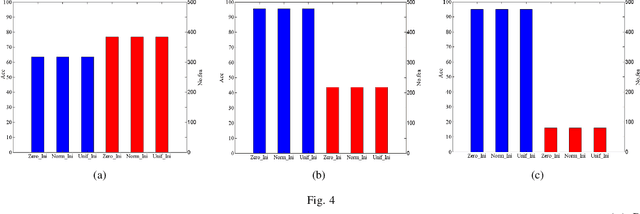
Feature selection is an important data preprocessing in data mining and machine learning, which can reduce feature size without deteriorating model's performance. Recently, sparse regression based feature selection methods have received considerable attention due to their good performance. However, these methods generally cannot determine the number of selected features automatically without using a predefined threshold. In order to get a satisfactory result, it often costs significant time and effort to tune the number of selected features carefully. To this end, this paper proposed a novel framework to solve the $l_{2,0}$-norm regularization least square problem directly for multi-class feature selection, which can produce exact rowsparsity solution for the weights matrix, features corresponding to non-zero rows will be selected thus the number of selected features can be determined automatically. An efficient homotopy iterative hard threshold (HIHT) algorithm is derived to solve the above optimization problem and find out the stable local solution. Besides, in order to reduce the computational time of HIHT, an acceleration version of HIHT (AHIHT) is derived. Extensive experiments on eight biological datasets show that the proposed method can achieve higher classification accuracy with fewest number of selected features comparing with the approximate convex counterparts and state-of-the-art feature selection methods. The robustness of classification accuracy to the regularization parameter is also exhibited.
Canonical 3D Deformer Maps: Unifying parametric and non-parametric methods for dense weakly-supervised category reconstruction
Aug 28, 2020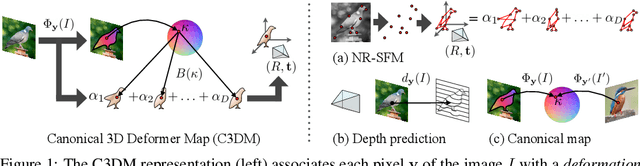
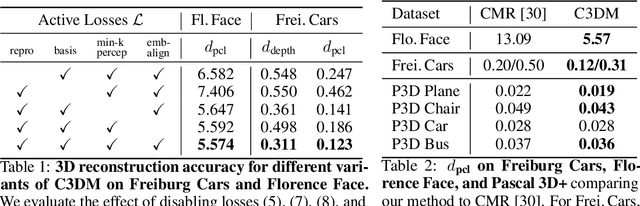
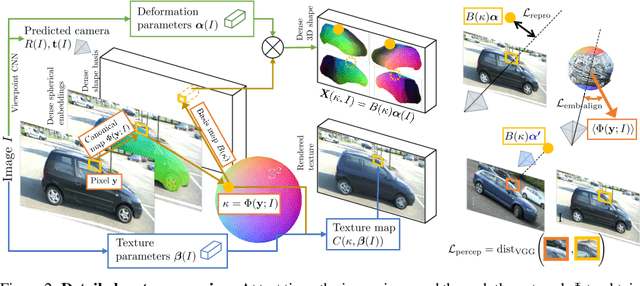

We propose the Canonical 3D Deformer Map, a new representation of the 3D shape of common object categories that can be learned from a collection of 2D images of independent objects. Our method builds in a novel way on concepts from parametric deformation models, non-parametric 3D reconstruction, and canonical embeddings, combining their individual advantages. In particular, it learns to associate each image pixel with a deformation model of the corresponding 3D object point which is canonical, i.e. intrinsic to the identity of the point and shared across objects of the category. The result is a method that, given only sparse 2D supervision at training time, can, at test time, reconstruct the 3D shape and texture of objects from single views, while establishing meaningful dense correspondences between object instances. It also achieves state-of-the-art results in dense 3D reconstruction on public in-the-wild datasets of faces, cars, and birds.
Cell assemblies at multiple time scales with arbitrary lag constellations
Feb 14, 2017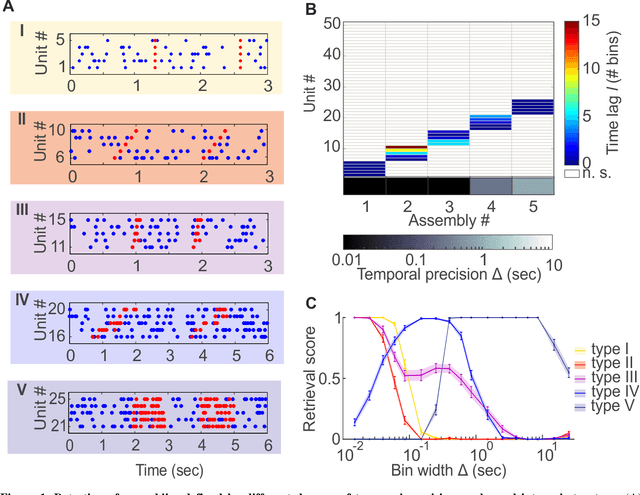
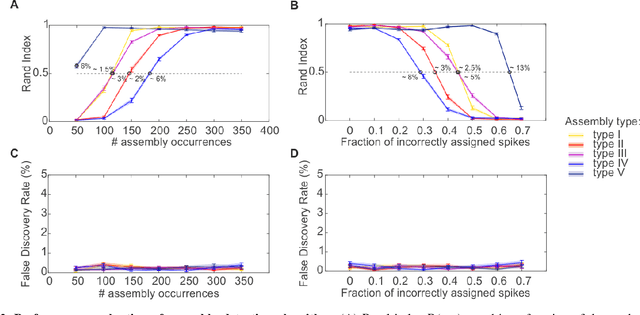
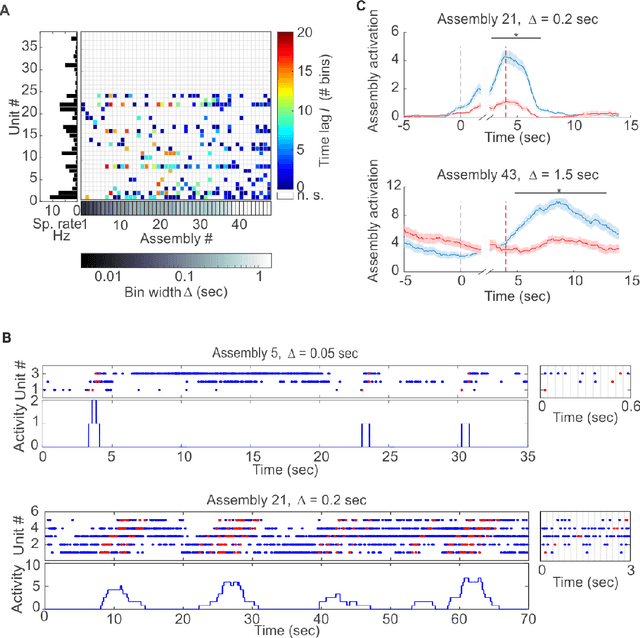
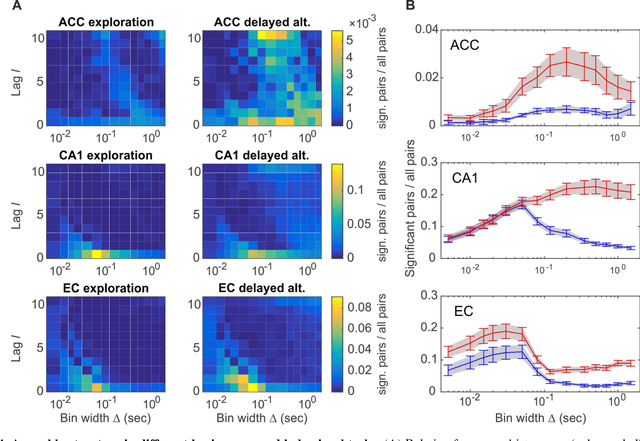
Hebb's idea of a cell assembly as the fundamental unit of neural information processing has dominated neuroscience like no other theoretical concept within the past 60 years. A range of different physiological phenomena, from precisely synchronized spiking to broadly simultaneous rate increases, has been subsumed under this term. Yet progress in this area is hampered by the lack of statistical tools that would enable to extract assemblies with arbitrary constellations of time lags, and at multiple temporal scales, partly due to the severe computational burden. Here we present such a unifying methodological and conceptual framework which detects assembly structure at many different time scales, levels of precision, and with arbitrary internal organization. Applying this methodology to multiple single unit recordings from various cortical areas, we find that there is no universal cortical coding scheme, but that assembly structure and precision significantly depends on brain area recorded and ongoing task demands.
Categorical data as a stone guest in a data science project for predicting defective water meters
Feb 05, 2021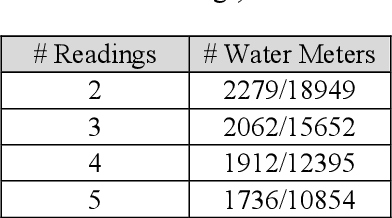
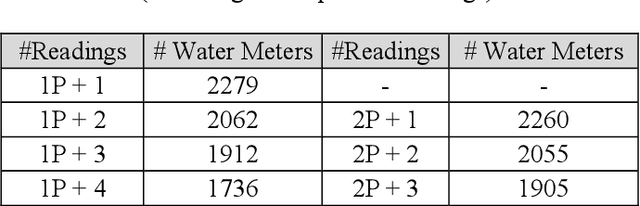
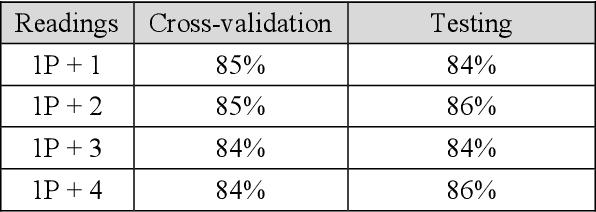
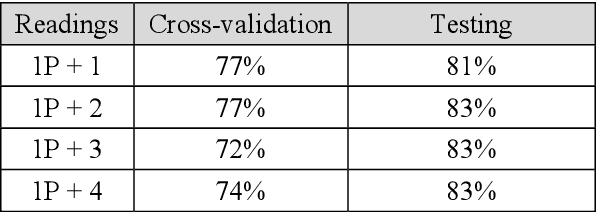
After a one-year long effort of research on the field, we developed a machine learning-based classifier, tailored to predict whether a mechanical water meter would fail with passage of time and intensive use as well. A recurrent deep neural network (RNN) was trained with data extrapolated from 15 million readings of water consumption, gathered from 1 million meters. The data we used for training were essentially of two types: continuous vs categorical. Categorical being a type of data that can take on one of a limited and fixed number of possible values, on the basis of some qualitative property; while continuous, in this case, are the values of the measurements. taken at the meters, of the quantity of consumed water (cubic meters). In this paper, we want to discuss the fact that while the prediction accuracy of our RNN has exceeded the 80% on average, based on the use of continuous data, those performances did not improve, significantly, with the introduction of categorical information during the training phase. From a specific viewpoint, this remains an unsolved and critical problem of our research. Yet, if we reason about this controversial case from a data science perspective, we realize that we have had a confirmation that accurate machine learning solutions cannot be built without the participation of domain experts, who can differentiate on the importance of (the relation between) different types of data, each with its own sense, validity, and implications. Past all the original hype, the science of data is thus evolving towards a multifaceted discipline, where the designitations of data scientist/machine learning expert and domain expert are symbiotic
Voxel R-CNN: Towards High Performance Voxel-based 3D Object Detection
Feb 05, 2021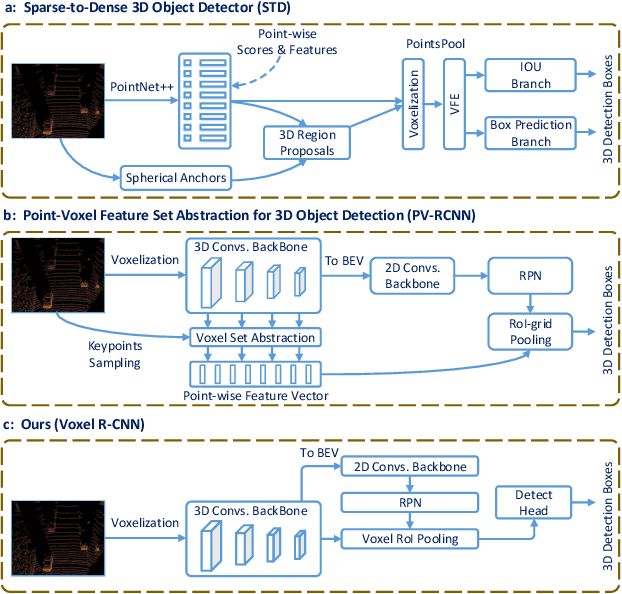


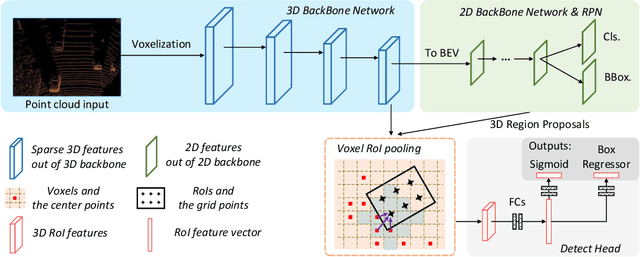
Recent advances on 3D object detection heavily rely on how the 3D data are represented, \emph{i.e.}, voxel-based or point-based representation. Many existing high performance 3D detectors are point-based because this structure can better retain precise point positions. Nevertheless, point-level features lead to high computation overheads due to unordered storage. In contrast, the voxel-based structure is better suited for feature extraction but often yields lower accuracy because the input data are divided into grids. In this paper, we take a slightly different viewpoint -- we find that precise positioning of raw points is not essential for high performance 3D object detection and that the coarse voxel granularity can also offer sufficient detection accuracy. Bearing this view in mind, we devise a simple but effective voxel-based framework, named Voxel R-CNN. By taking full advantage of voxel features in a two stage approach, our method achieves comparable detection accuracy with state-of-the-art point-based models, but at a fraction of the computation cost. Voxel R-CNN consists of a 3D backbone network, a 2D bird-eye-view (BEV) Region Proposal Network and a detect head. A voxel RoI pooling is devised to extract RoI features directly from voxel features for further refinement. Extensive experiments are conducted on the widely used KITTI Dataset and the more recent Waymo Open Dataset. Our results show that compared to existing voxel-based methods, Voxel R-CNN delivers a higher detection accuracy while maintaining a real-time frame processing rate, \emph{i.e}., at a speed of 25 FPS on an NVIDIA RTX 2080 Ti GPU. The code is available at \url{https://github.com/djiajunustc/Voxel-R-CNN}.
Can We Automate Scientific Reviewing?
Jan 30, 2021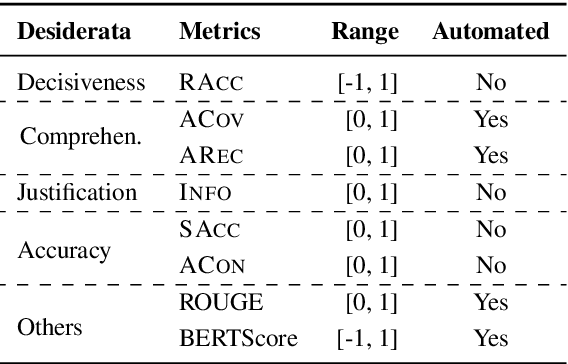
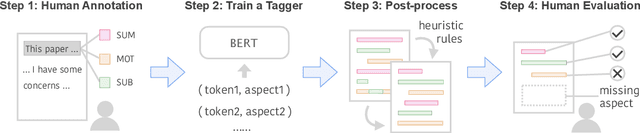
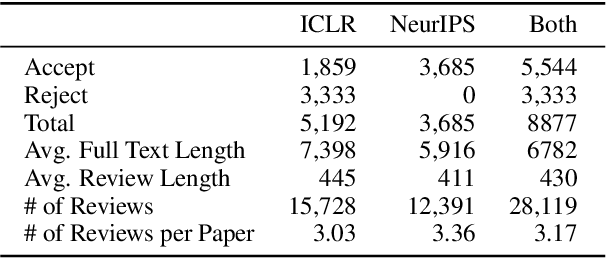
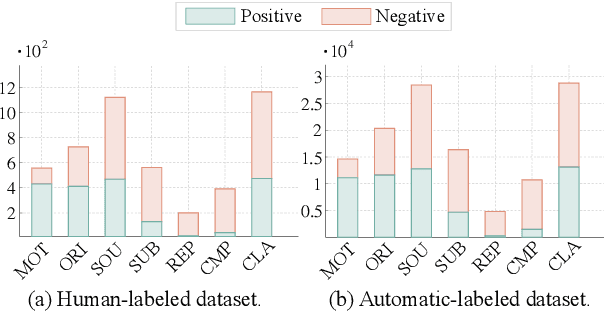
The rapid development of science and technology has been accompanied by an exponential growth in peer-reviewed scientific publications. At the same time, the review of each paper is a laborious process that must be carried out by subject matter experts. Thus, providing high-quality reviews of this growing number of papers is a significant challenge. In this work, we ask the question "can we automate scientific reviewing?", discussing the possibility of using state-of-the-art natural language processing (NLP) models to generate first-pass peer reviews for scientific papers. Arguably the most difficult part of this is defining what a "good" review is in the first place, so we first discuss possible evaluation measures for such reviews. We then collect a dataset of papers in the machine learning domain, annotate them with different aspects of content covered in each review, and train targeted summarization models that take in papers to generate reviews. Comprehensive experimental results show that system-generated reviews tend to touch upon more aspects of the paper than human-written reviews, but the generated text can suffer from lower constructiveness for all aspects except the explanation of the core ideas of the papers, which are largely factually correct. We finally summarize eight challenges in the pursuit of a good review generation system together with potential solutions, which, hopefully, will inspire more future research on this subject. We make all code, and the dataset publicly available: https://github.com/neulab/ReviewAdvisor, as well as a ReviewAdvisor system: http://review.nlpedia.ai/.
Auto-MVCNN: Neural Architecture Search for Multi-view 3D Shape Recognition
Dec 10, 2020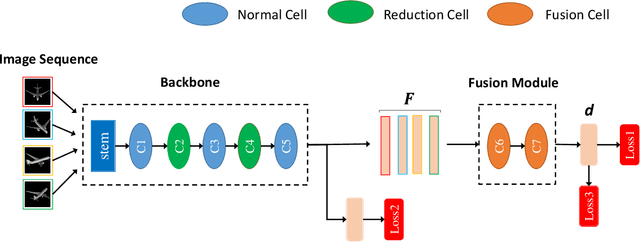
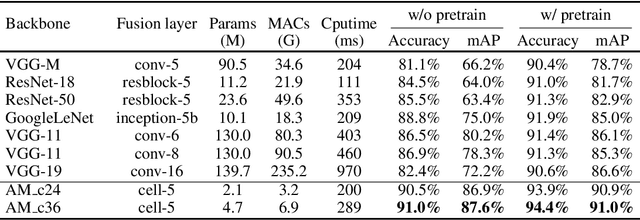
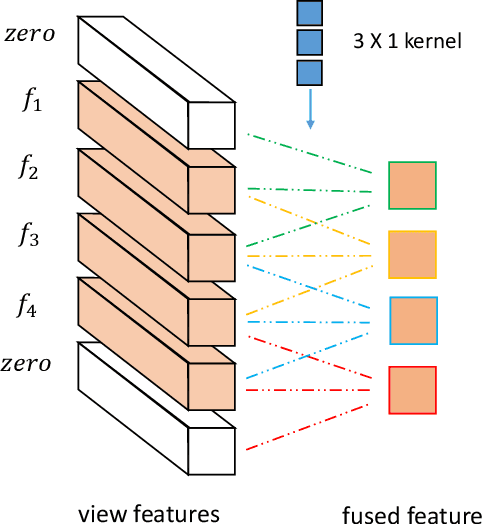
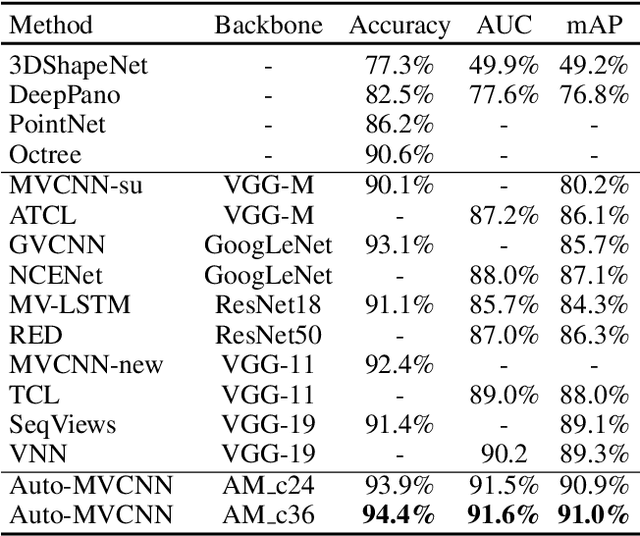
In 3D shape recognition, multi-view based methods leverage human's perspective to analyze 3D shapes and have achieved significant outcomes. Most existing research works in deep learning adopt handcrafted networks as backbones due to their high capacity of feature extraction, and also benefit from ImageNet pretraining. However, whether these network architectures are suitable for 3D analysis or not remains unclear. In this paper, we propose a neural architecture search method named Auto-MVCNN which is particularly designed for optimizing architecture in multi-view 3D shape recognition. Auto-MVCNN extends gradient-based frameworks to process multi-view images, by automatically searching the fusion cell to explore intrinsic correlation among view features. Moreover, we develop an end-to-end scheme to enhance retrieval performance through the trade-off parameter search. Extensive experimental results show that the searched architectures significantly outperform manually designed counterparts in various aspects, and our method achieves state-of-the-art performance at the same time.
Graph-based denoising for time-varying point clouds
Nov 16, 2015
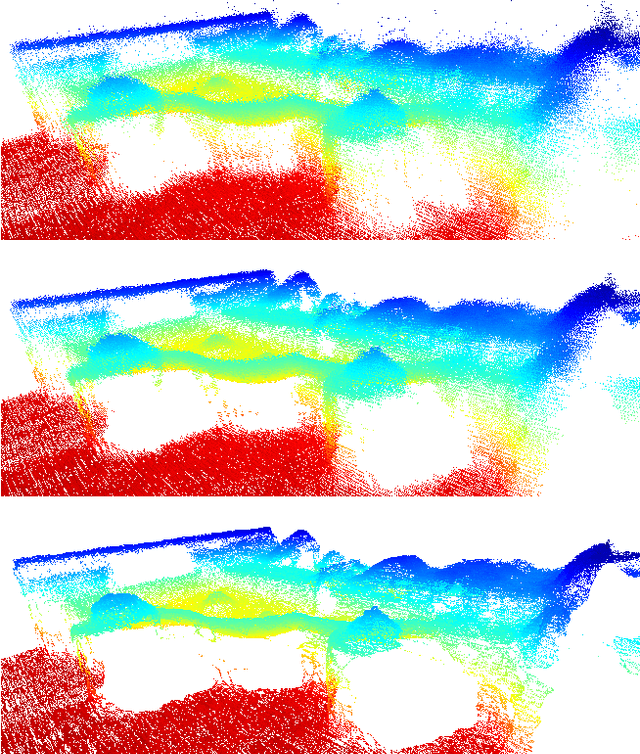
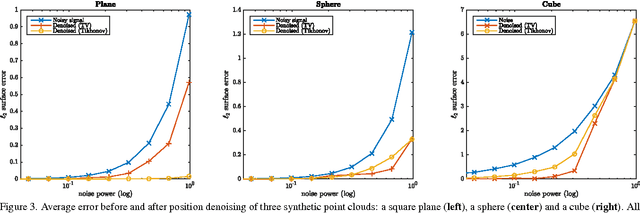
Noisy 3D point clouds arise in many applications. They may be due to errors when constructing a 3D model from images or simply to imprecise depth sensors. Point clouds can be given geometrical structure using graphs created from the similarity information between points. This paper introduces a technique that uses this graph structure and convex optimization methods to denoise 3D point clouds. A short discussion presents how those methods naturally generalize to time-varying inputs such as 3D point cloud time series.
* 4 pages, 3 figures, 3DTV-Con 2015
Temporal Clustering of Time Series via Threshold Autoregressive Models: Application to Commodity Prices
May 03, 2016
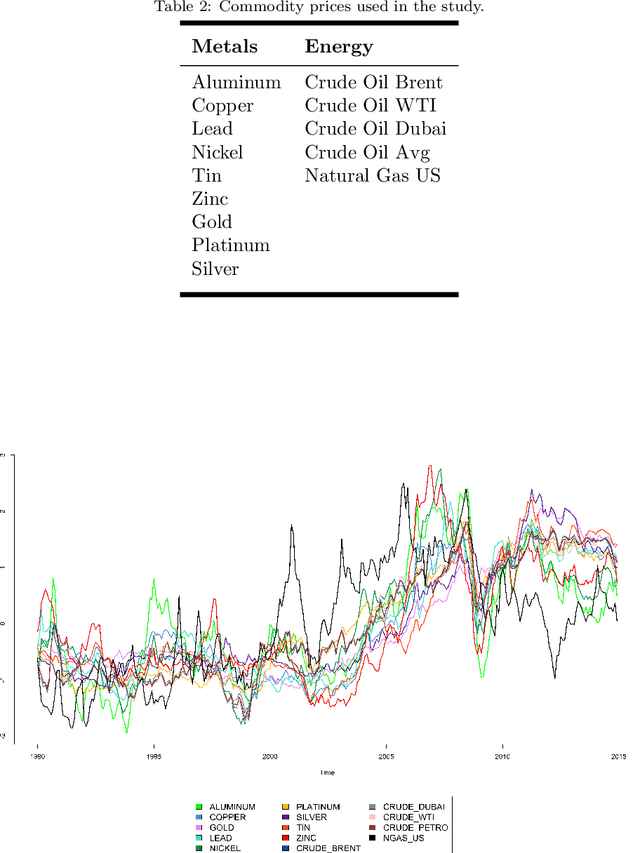
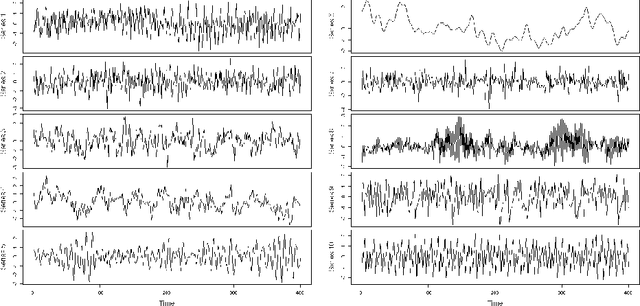
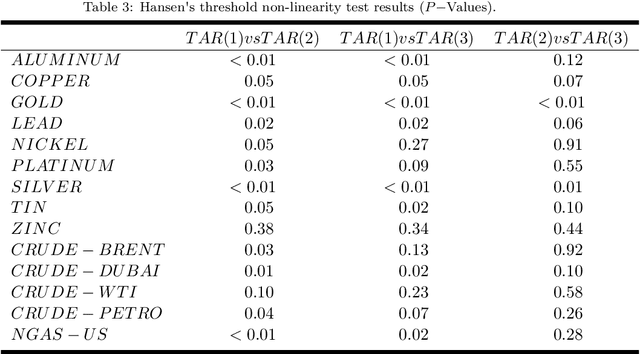
This study aimed to find temporal clusters for several commodity prices using the threshold non-linear autoregressive model. It is expected that the process of determining the commodity groups that are time-dependent will advance the current knowledge about the dynamics of co-moving and coherent prices, and can serve as a basis for multivariate time series analyses. The clustering of commodity prices was examined using the proposed clustering approach based on time series models to incorporate the time varying properties of price series into the clustering scheme. Accordingly, the primary aim in this study was grouping time series according to the similarity between their Data Generating Mechanisms (DGMs) rather than comparing pattern similarities in the time series traces. The approximation to the DGM of each series was accomplished using threshold autoregressive models, which are recognized for their ability to represent nonlinear features in time series, such as abrupt changes, time-irreversibility and regime-shifting behavior. Through the use of the proposed approach, one can determine and monitor the set of co-moving time series variables across the time dimension. Furthermore, generating a time varying commodity price index and sub-indexes can become possible. Consequently, we conducted a simulation study to assess the effectiveness of the proposed clustering approach and the results are presented for both the simulated and real data sets.