 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hidden Latent State Inference in a Spatio-Temporal Generative Model
Sep 21, 2020


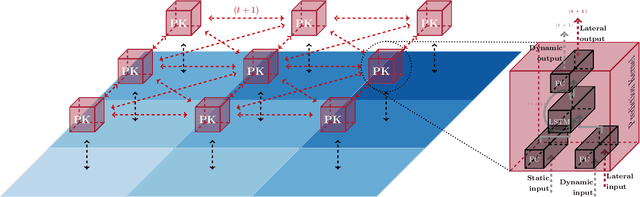
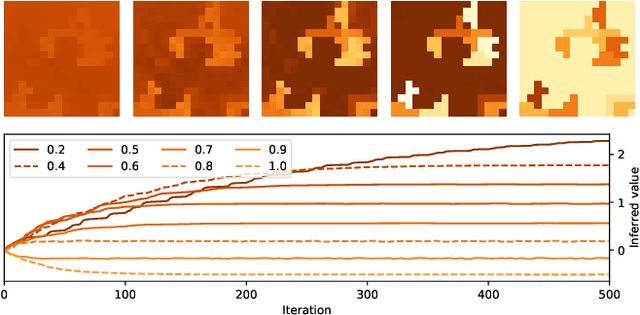
Knowledge of the hidden factors that determine particular system dynamics is crucial for both explaining them and pursuing goal-directed, interventional actions. The inference of these factors without supervision given time series data remains an open challenge. Here, we focus on spatio-temporal processes, including wave propagations and weather dynamics, and assume that universal causes (e.g. physics) apply throughout space and time. We apply a novel DIstributed, Spatio-Temporal graph Artificial Neural network Architecture, DISTANA, which learns a generative model in such domains. DISTANA requires fewer parameters, and yields more accurate predictions than temporal convolutional neural networks and other related approaches on a 2D circular wave prediction task. We show that DISTANA, when combined with a retrospective latent state inference principle called active tuning, can reliably derive hidden local causal factors. In a current weather prediction benchmark, DISTANA infers our planet's land-sea mask solely by observing temperature dynamics and uses the self inferred information to improve its own prediction of temperature. We are convinced that the retrospective inference of latent states in generative RNN architectures will play an essential role in future research on causal inference and explainable systems.
A Comprehensive LiDAR-based SLAM Comparison for Control of Unmanned Aerial Vehicles
Nov 04, 2020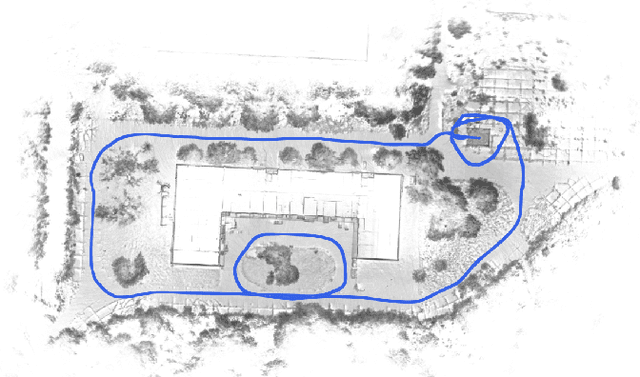

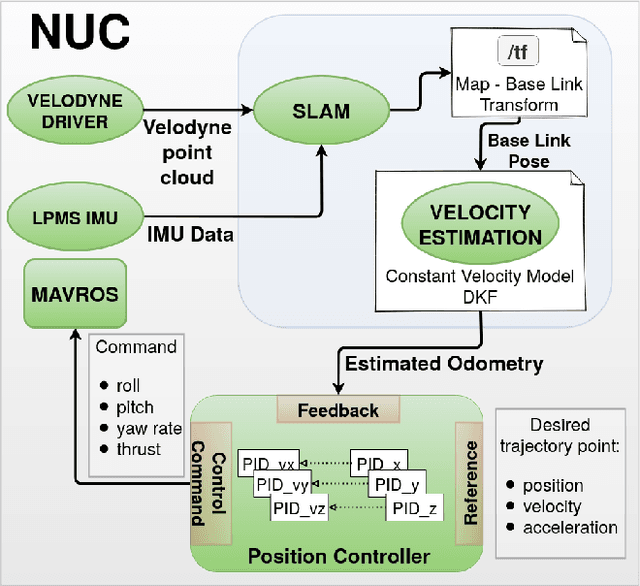
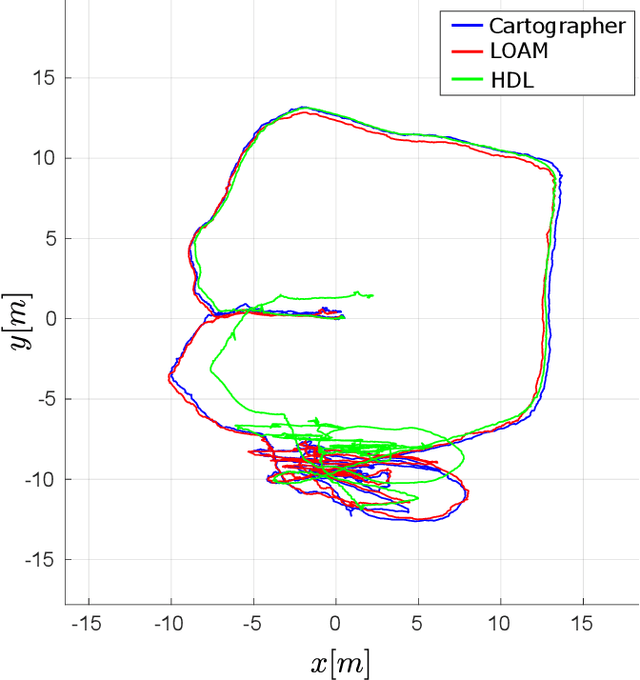
This paper investigates the use of LiDAR SLAM as a pose feedback for autonomous flight. Cartographer, LOAM and hdl graph SLAM are tested for this role. They are first compared offline on a series of datasets to see if they are capable of producing high-quality pose estimations in agile and long-range flight scenarios. The second stage of testing consists of integrating the SLAM algorithms into a cascade PID UAV control system and comparing the control system performance on step excitation signals and helical trajectories. The comparison is based on step response characteristics and several time integral performance criteria as well as the RMS error between planned and executed trajectory.
Nonsmooth Analysis and Subgradient Methods for Averaging in Dynamic Time Warping Spaces
Jan 23, 2017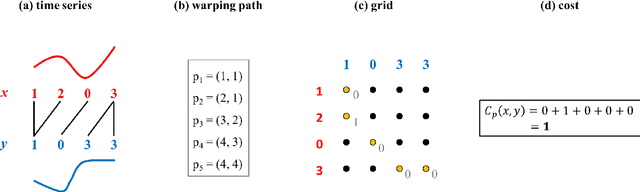
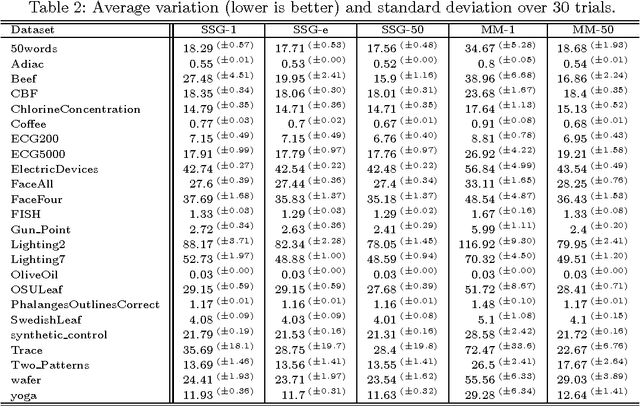
Time series averaging in dynamic time warping (DTW) spaces has been successfully applied to improve pattern recognition systems. This article proposes and analyzes subgradient methods for the problem of finding a sample mean in DTW spaces. The class of subgradient methods generalizes existing sample mean algorithms such as DTW Barycenter Averaging (DBA). We show that DBA is a majorize-minimize algorithm that converges to necessary conditions of optimality after finitely many iterations. Empirical results show that for increasing sample sizes the proposed stochastic subgradient (SSG) algorithm is more stable and finds better solutions in shorter time than the DBA algorithm on average. Therefore, SSG is useful in online settings and for non-small sample sizes. The theoretical and empirical results open new paths for devising sample mean algorithms: nonsmooth optimization methods and modified variants of pairwise averaging methods.
Pointwise HSIC: A Linear-Time Kernelized Co-occurrence Norm for Sparse Linguistic Expressions
Sep 04, 2018


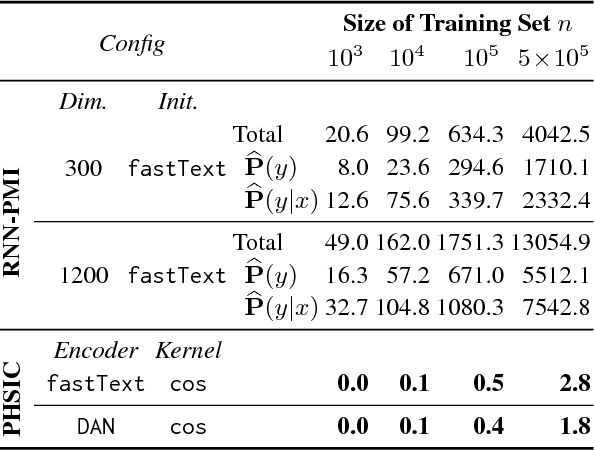
In this paper, we propose a new kernel-based co-occurrence measure that can be applied to sparse linguistic expressions (e.g., sentences) with a very short learning time, as an alternative to pointwise mutual information (PMI). As well as deriving PMI from mutual information, we derive this new measure from the Hilbert--Schmidt independence criterion (HSIC); thus, we call the new measure the pointwise HSIC (PHSIC). PHSIC can be interpreted as a smoothed variant of PMI that allows various similarity metrics (e.g., sentence embeddings) to be plugged in as kernels. Moreover, PHSIC can be estimated by simple and fast (linear in the size of the data) matrix calculations regardless of whether we use linear or nonlinear kernels. Empirically, in a dialogue response selection task, PHSIC is learned thousands of times faster than an RNN-based PMI while outperforming PMI in accuracy. In addition, we also demonstrate that PHSIC is beneficial as a criterion of a data selection task for machine translation owing to its ability to give high (low) scores to a consistent (inconsistent) pair with other pairs.
Benchmarking of Deep Learning Irradiance Forecasting Models from Sky Images -- an in-depth Analysis
Feb 01, 2021

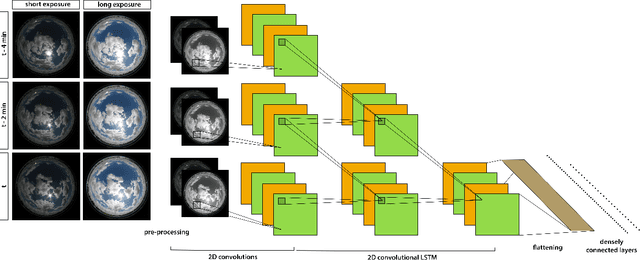
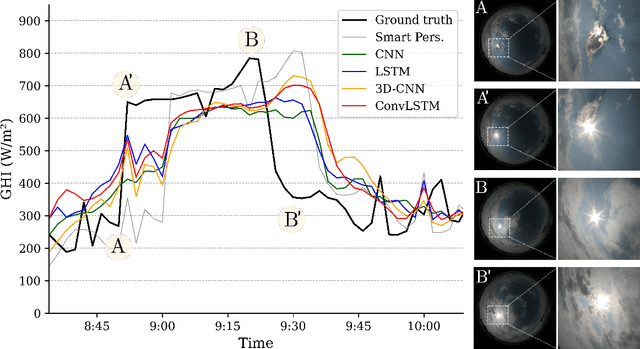
A number of industrial applications, such as smart grids, power plant operation, hybrid system management or energy trading, could benefit from improved short-term solar forecasting, addressing the intermittent energy production from solar panels. However, current approaches to modelling the cloud cover dynamics from sky images still lack precision regarding the spatial configuration of clouds, their temporal dynamics and physical interactions with solar radiation. Benefiting from a growing number of large datasets, data driven methods are being developed to address these limitations with promising results. In this study, we compare four commonly used Deep Learning architectures trained to forecast solar irradiance from sequences of hemispherical sky images and exogenous variables. To assess the relative performance of each model, we used the Forecast Skill metric based on the smart persistence model, as well as ramp and time distortion metrics. The results show that encoding spatiotemporal aspects of the sequence of sky images greatly improved the predictions with 10 min ahead Forecast Skill reaching 20.4% on the test year. However, based on the experimental data, we conclude that, with a common setup, Deep Learning models tend to behave just as a `very smart persistence model', temporally aligned with the persistence model while mitigating its most penalising errors. Thus, despite being captured by the sky cameras, models often miss fundamental events causing large irradiance changes such as clouds obscuring the sun. We hope that our work will contribute to a shift of this approach to irradiance forecasting, from reactive to anticipatory.
Robust & Asymptotically Locally Optimal UAV-Trajectory Generation Based on Spline Subdivision
Nov 11, 2020


Generating locally optimal UAV-trajectories is challenging due to the non-convex constraints of collision avoidance and actuation limits. We present the first local, optimization-based UAV-trajectory generator that simultaneously guarantees validity and asymptotic optimality. Validity: Given a feasible initial guess, our algorithm guarantees the satisfaction of all constraints throughout the process of optimization. Asymptotic Optimality: We use a conservative piecewise approximation of the trajectory with automatically adjustable resolution of its discretization. The trajectory converges under refinement to the first-order stationary point of the exact non-convex programming problem. Our method has additional practical advantages including joint optimality in terms of trajectory and time-allocation, and robustness to challenging environments as demonstrated in our experiments.
QuickTumorNet: Fast Automatic Multi-Class Segmentation of Brain Tumors
Dec 22, 2020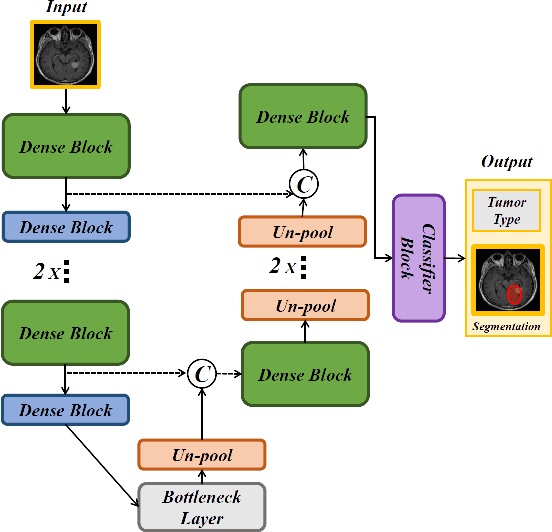
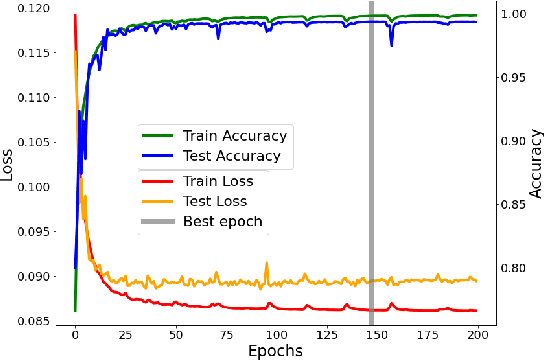
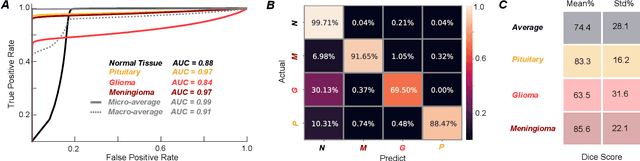
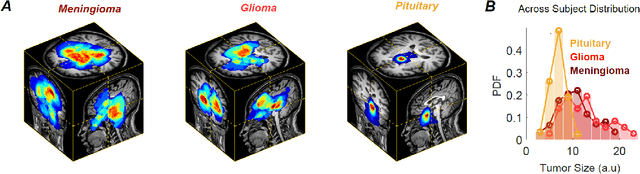
Non-invasive techniques such as magnetic resonance imaging (MRI) are widely employed in brain tumor diagnostics. However, manual segmentation of brain tumors from 3D MRI volumes is a time-consuming task that requires trained expert radiologists. Due to the subjectivity of manual segmentation, there is low inter-rater reliability which can result in diagnostic discrepancies. As the success of many brain tumor treatments depends on early intervention, early detection is paramount. In this context, a fully automated segmentation method for brain tumor segmentation is necessary as an efficient and reliable method for brain tumor detection and quantification. In this study, we propose an end-to-end approach for brain tumor segmentation, capitalizing on a modified version of QuickNAT, a brain tissue type segmentation deep convolutional neural network (CNN). Our method was evaluated on a data set of 233 patient's T1 weighted images containing three tumor type classes annotated (meningioma, glioma, and pituitary). Our model, QuickTumorNet, demonstrated fast, reliable, and accurate brain tumor segmentation that can be utilized to assist clinicians in diagnosis and treatment.
CFC-Net: A Critical Feature Capturing Network for Arbitrary-Oriented Object Detection in Remote Sensing Images
Jan 18, 2021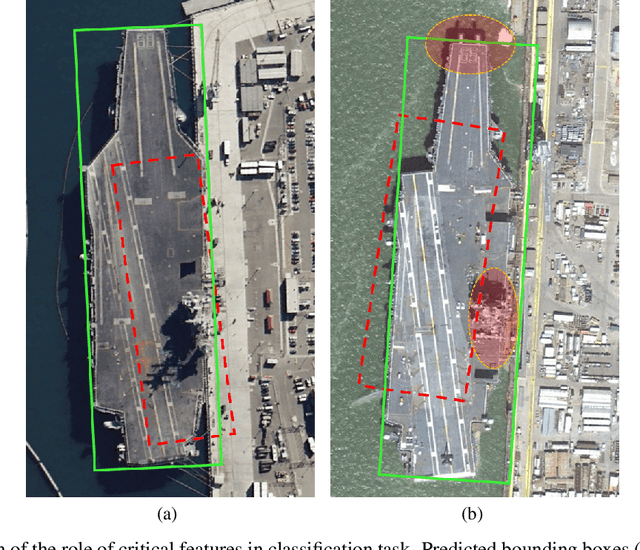
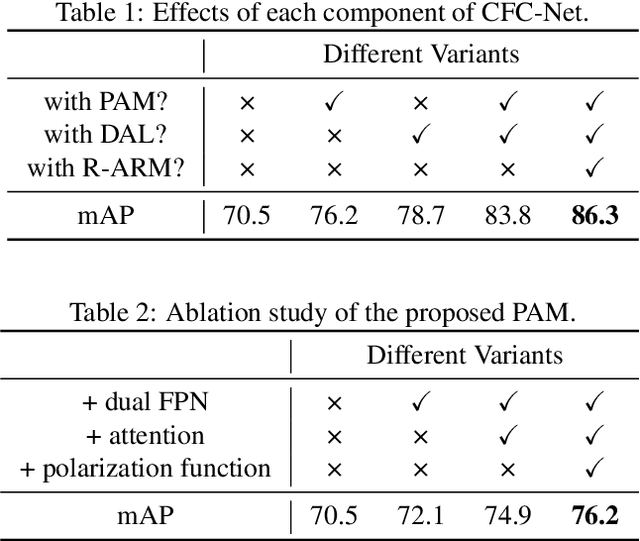
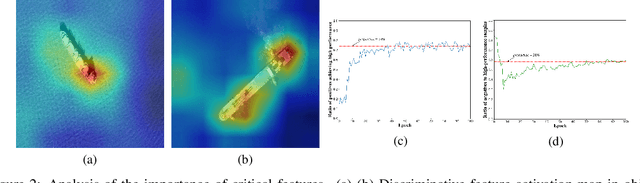
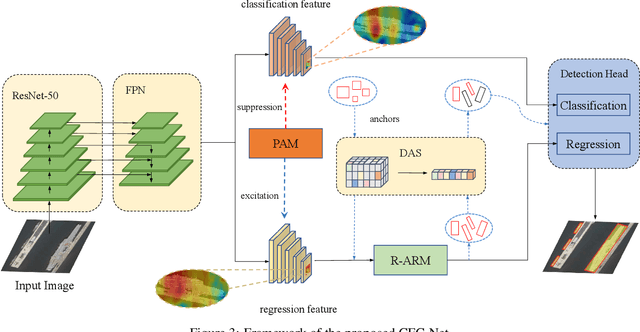
Object detection in optical remote sensing images is an important and challenging task. In recent years, the methods based on convolutional neural networks have made good progress. However, due to the large variation in object scale, aspect ratio, and arbitrary orientation, the detection performance is difficult to be further improved. In this paper, we discuss the role of discriminative features in object detection, and then propose a Critical Feature Capturing Network (CFC-Net) to improve detection accuracy from three aspects: building powerful feature representation, refining preset anchors, and optimizing label assignment. Specifically, we first decouple the classification and regression features, and then construct robust critical features adapted to the respective tasks through the Polarization Attention Module (PAM). With the extracted discriminative regression features, the Rotation Anchor Refinement Module (R-ARM) performs localization refinement on preset horizontal anchors to obtain superior rotation anchors. Next, the Dynamic Anchor Learning (DAL) strategy is given to adaptively select high-quality anchors based on their ability to capture critical features. The proposed framework creates more powerful semantic representations for objects in remote sensing images and achieves high-performance real-time object detection. Experimental results on three remote sensing datasets including HRSC2016, DOTA, and UCAS-AOD show that our method achieves superior detection performance compared with many state-of-the-art approaches. Code and models are available at https://github.com/ming71/CFC-Net.
A Real-Time Deep Learning Pedestrian Detector for Robot Navigation
Sep 19, 2017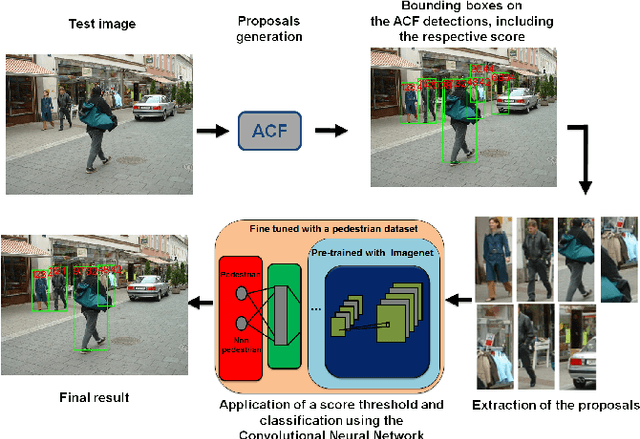



A real-time Deep Learning based method for Pedestrian Detection (PD) is applied to the Human-Aware robot navigation problem. The pedestrian detector combines the Aggregate Channel Features (ACF) detector with a deep Convolutional Neural Network (CNN) in order to obtain fast and accurate performance. Our solution is firstly evaluated using a set of real images taken from onboard and offboard cameras and, then, it is validated in a typical robot navigation environment with pedestrians (two distinct experiments are conducted). The results on both tests show that our pedestrian detector is robust and fast enough to be used on robot navigation applications.
Detect, Reject, Correct: Crossmodal Compensation of Corrupted Sensors
Dec 01, 2020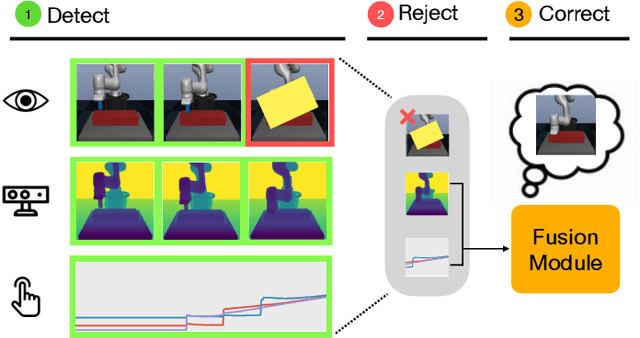
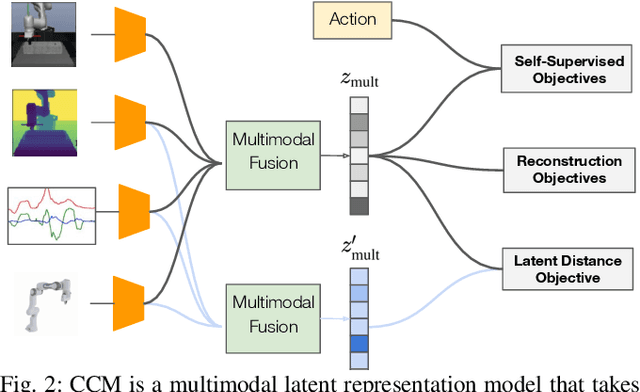
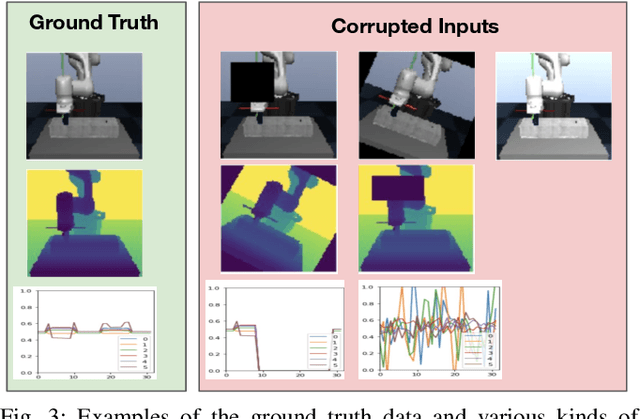
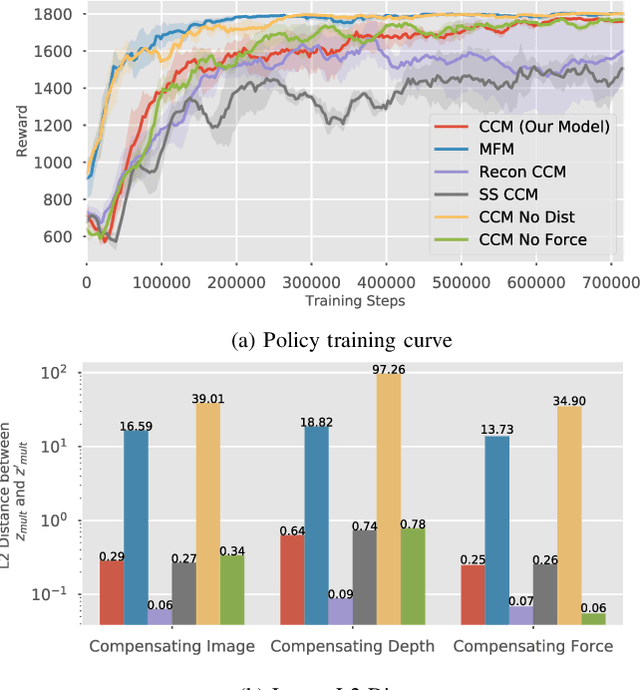
Using sensor data from multiple modalities presents an opportunity to encode redundant and complementary features that can be useful when one modality is corrupted or noisy. Humans do this everyday, relying on touch and proprioceptive feedback in visually-challenging environments. However, robots might not always know when their sensors are corrupted, as even broken sensors can return valid values. In this work, we introduce the Crossmodal Compensation Model (CCM), which can detect corrupted sensor modalities and compensate for them. CMM is a representation model learned with self-supervision that leverages unimodal reconstruction loss for corruption detection. CCM then discards the corrupted modality and compensates for it with information from the remaining sensors. We show that CCM learns rich state representations that can be used for contact-rich manipulation policies, even when input modalities are corrupted in ways not seen during training time.