 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Forecasting Daily Primary Three-Hour Net Load Ramps in the CAISO System
Dec 13, 2020
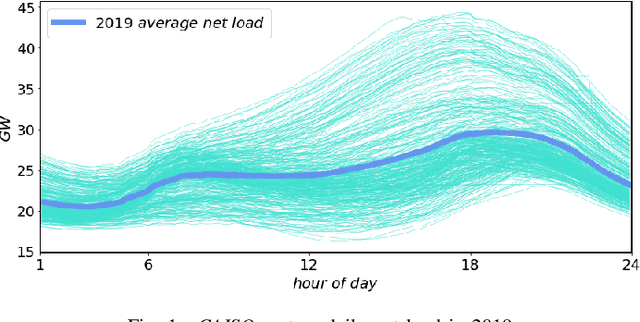
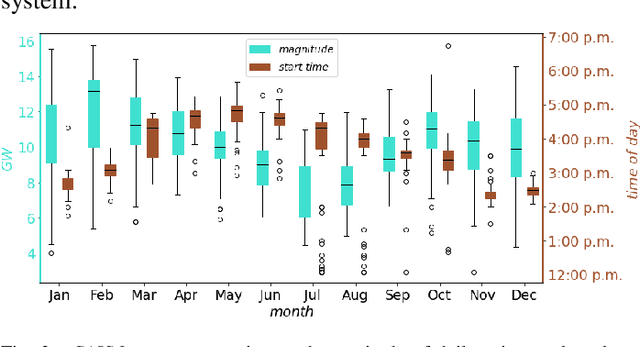
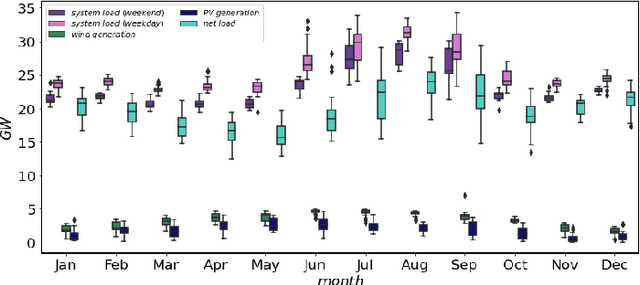
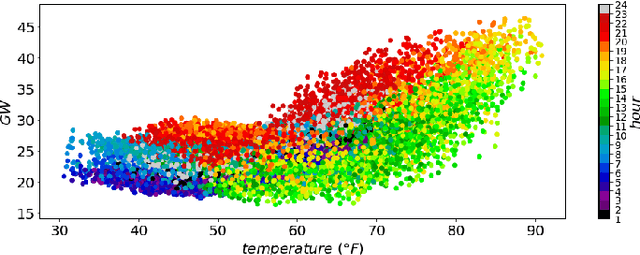
The deepening penetration of variable energy resources creates unprecedented challenges for system operators (SOs). An issue that merits special attention is the precipitous net load ramps, which require SOs to have flexible capacity at their disposal so as to maintain the supply-demand balance at all times. In the judicious procurement and deployment of flexible capacity, a tool that forecasts net load ramps may be of great assistance to SOs. To this end, we propose a methodology to forecast the magnitude and start time of daily primary three-hour net load ramps. We perform an extensive analysis so as to identify the factors that influence net load and draw on the identified factors to develop a forecasting methodology that harnesses the long short-term memory model. We demonstrate the effectiveness of the proposed methodology on the CAISO system using comparative assessments with selected benchmarks based on various evaluation metrics.
Pixel precise unsupervised detection of viral particle proliferation in cellular imaging data
Nov 10, 2020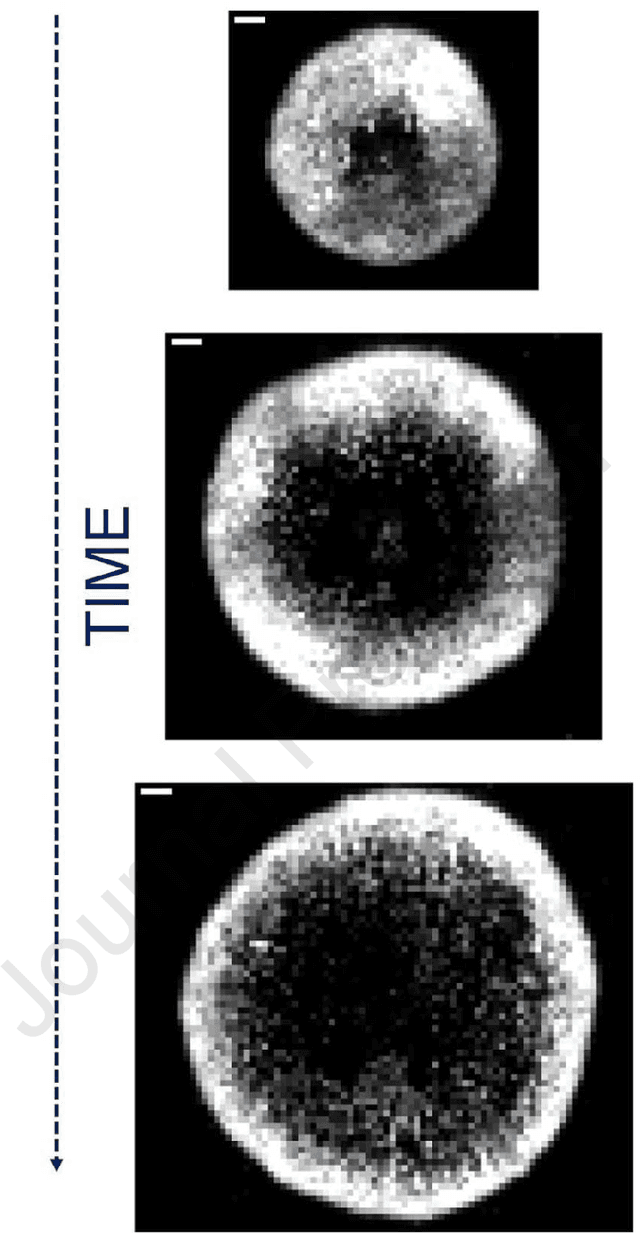
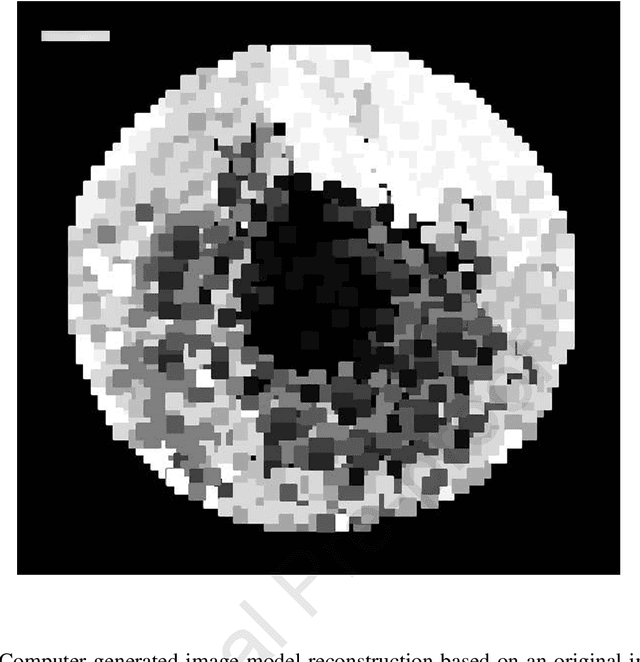
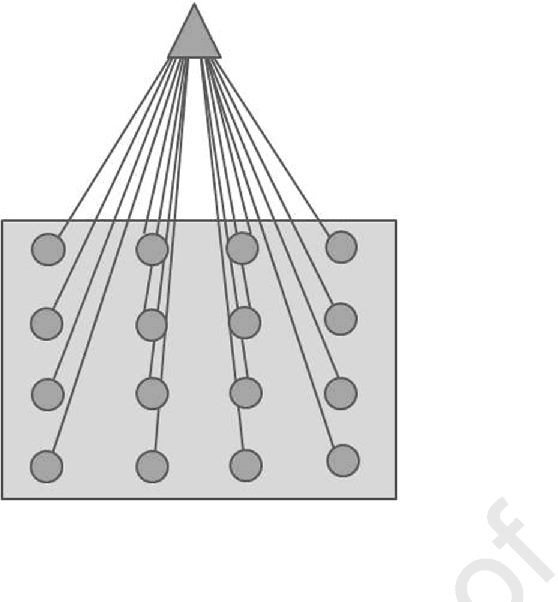
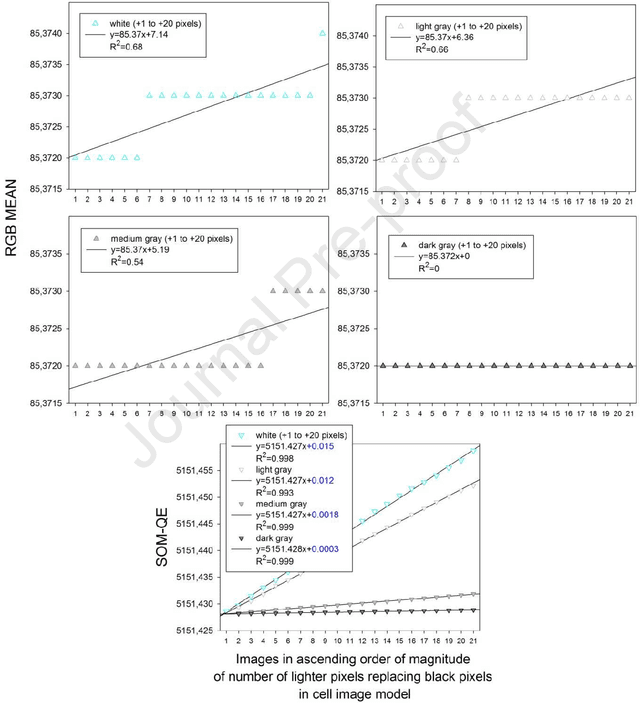
Cellular and molecular imaging techniques and models have been developed to characterize single stages of viral proliferation after focal infection of cells in vitro. The fast and automatic classification of cell imaging data may prove helpful prior to any further comparison of representative experimental data to mathematical models of viral propagation in host cells. Here, we use computer generated images drawn from a reproduction of an imaging model from a previously published study of experimentally obtained cell imaging data representing progressive viral particle proliferation in host cell monolayers. Inspired by experimental time-based imaging data, here in this study viral particle increase in time is simulated by a one-by-one increase, across images, in black or gray single pixels representing dead or partially infected cells, and hypothetical remission by a one-by-one increase in white pixels coding for living cells in the original image model. The image simulations are submitted to unsupervised learning by a Self-Organizing Map (SOM) and the Quantization Error in the SOM output (SOM-QE) is used for automatic classification of the image simulations as a function of the represented extent of viral particle proliferation or cell recovery. Unsupervised classification by SOM-QE of 160 model images, each with more than three million pixels, is shown to provide a statistically reliable, pixel precise, and fast classification model that outperforms human computer-assisted image classification by RGB image mean computation. The automatic classification procedure proposed here provides a powerful approach to understand finely tuned mechanisms in the infection and proliferation of virus in cell lines in vitro or other cells.
Towards Overfitting Avoidance: Tuning-free Tensor-aided Multi-user Channel Estimation for 3D Massive MIMO Communications
Jan 24, 2021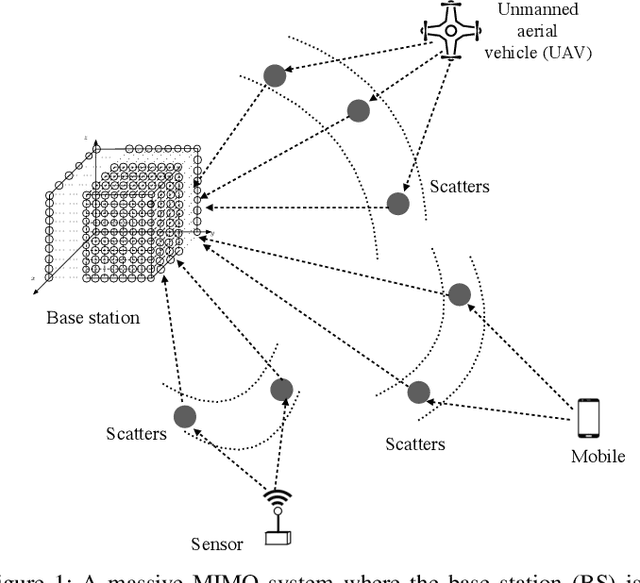
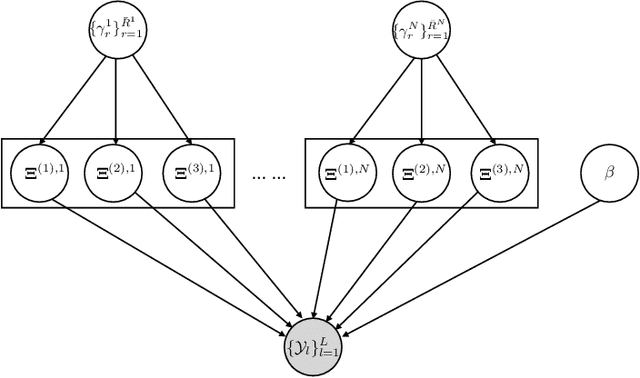
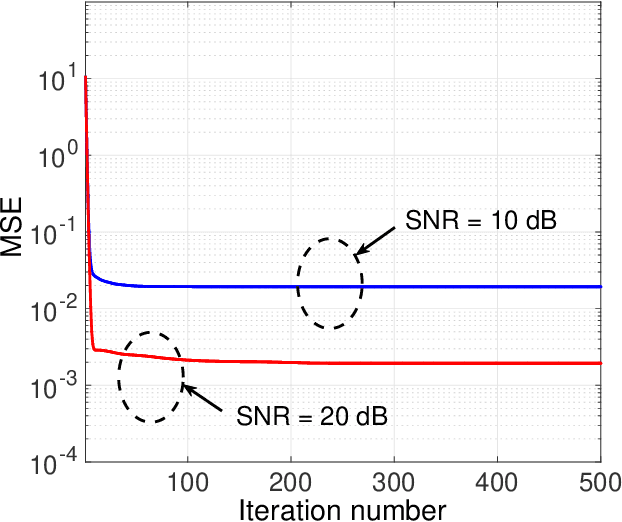
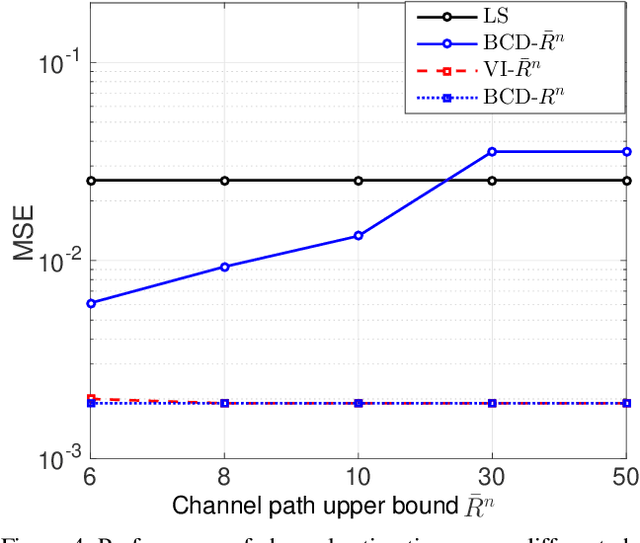
Channel estimation has long been deemed as one of the most critical problems in three-dimensional (3D) massive multiple-input multiple-output (MIMO), which is recognized as the leading technology that enables 3D spatial signal processing in the fifth-generation (5G) wireless communications and beyond. Recently, by exploring the angular channel model and tensor decompositions, the accuracy of single-user channel estimation for 3D massive MIMO communications has been significantly improved given a limited number of pilot signals. However, these existing approaches cannot be straightforwardly extended to the multi-user channel estimation task, where the base station (BS) aims at acquiring the channels of multiple users at the same time. The difficulty is that the coupling among multiple users' channels makes the channel estimation deviate from widely-used tensor decompositions. It gives a non-standard tensor decomposition format that has not been well tackled. To overcome this challenge, besides directly fitting the new tensor model for channel estimation to the wireless data via block coordinate descent (BCD) method, which is prone to the overfitting of noises or requires regularization parameter tuning, we further propose a novel tuning-free channel estimation algorithm that can automatically control the channel model complexity and thus effectively avoid the overfitting. Numerical results are presented to demonstrate the excellent performance of the proposed algorithm in terms of both estimation accuracy and overfitting avoidance.
A new distance measure of Pythagorean fuzzy sets based on matrix and and its application in medical diagnosis
Jan 31, 2021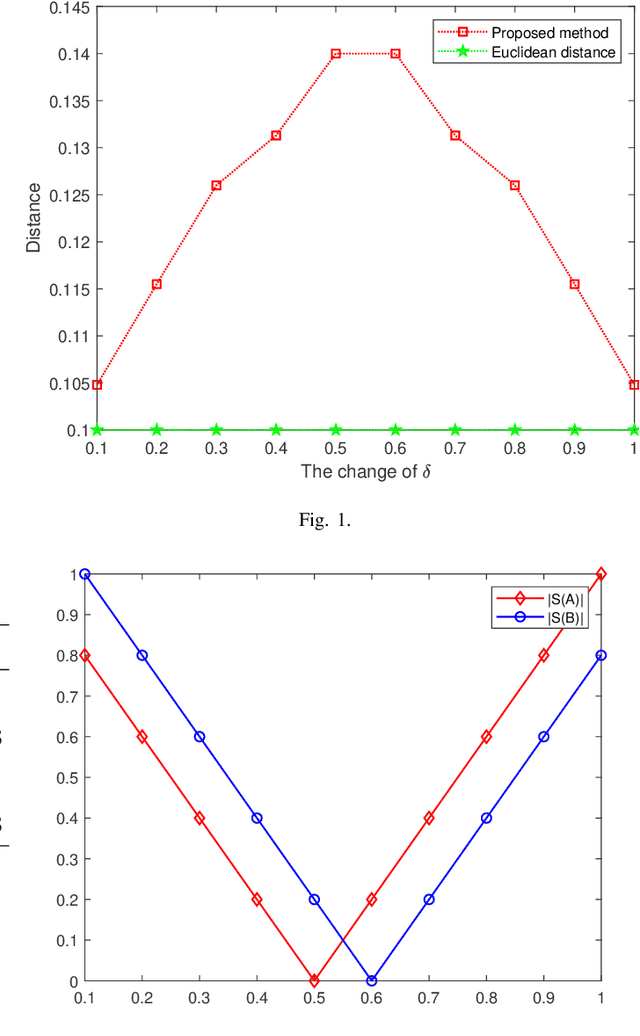
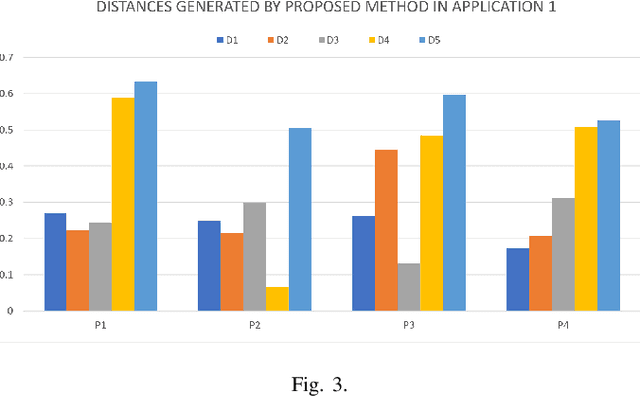
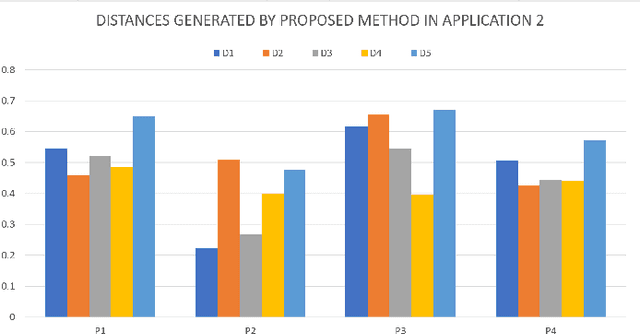
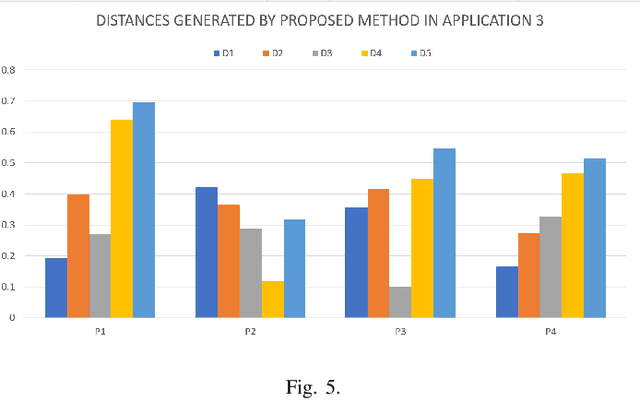
The pythagorean fuzzy set (PFS) which is developed based on intuitionistic fuzzy set, is more efficient in elaborating and disposing uncertainties in indeterminate situations, which is a very reason of that PFS is applied in various kinds of fields. How to measure the distance between two pythagorean fuzzy sets is still an open issue. Mnay kinds of methods have been proposed to present the of the question in former reaserches. However, not all of existing methods can accurately manifest differences among pythagorean fuzzy sets and satisfy the property of similarity. And some other kinds of methods neglect the relationship among three variables of pythagorean fuzzy set. To addrees the proplem, a new method of measuring distance is proposed which meets the requirements of axiom of distance measurement and is able to indicate the degree of distinction of PFSs well. Then some numerical examples are offered to to verify that the method of measuring distances can avoid the situation that some counter? intuitive and irrational results are produced and is more effective, reasonable and advanced than other similar methods. Besides, the proposed method of measuring distances between PFSs is applied in a real environment of application which is the medical diagnosis and is compared with other previous methods to demonstrate its superiority and efficiency. And the feasibility of the proposed method in handling uncertainties in practice is also proved at the same time.
A Hybrid 2-stage Neural Optimization for Pareto Front Extraction
Feb 13, 2021
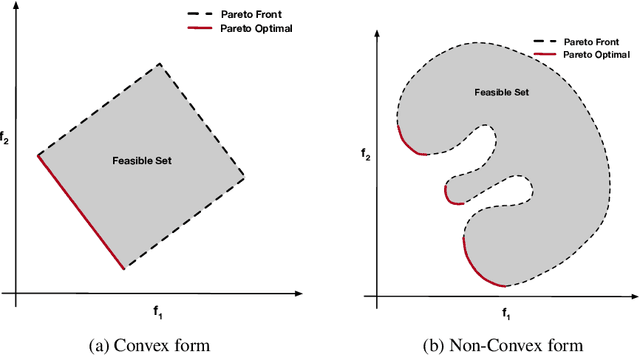
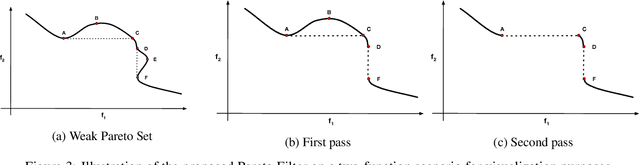
Classification, recommendation, and ranking problems often involve competing goals with additional constraints (e.g., to satisfy fairness or diversity criteria). Such optimization problems are quite challenging, often involving non-convex functions along with considerations of user preferences in balancing trade-offs. Pareto solutions represent optimal frontiers for jointly optimizing multiple competing objectives. A major obstacle for frequently used linear-scalarization strategies is that the resulting optimization problem might not always converge to a global optimum. Furthermore, such methods only return one solution point per run. A Pareto solution set is a subset of all such global optima over multiple runs for different trade-off choices. Therefore, a Pareto front can only be guaranteed with multiple runs of the linear-scalarization problem, where all runs converge to their respective global optima. Consequently, extracting a Pareto front for practical problems is computationally intractable with substantial computational overheads, limited scalability, and reduced accuracy. We propose a robust, low cost, two-stage, hybrid neural Pareto optimization approach that is accurate and scales (compute space and time) with data dimensions, as well as number of functions and constraints. The first stage (neural network) efficiently extracts a weak Pareto front, using Fritz-John conditions as the discriminator, with no assumptions of convexity on the objectives or constraints. The second stage (efficient Pareto filter) extracts the strong Pareto optimal subset given the weak front from stage 1. Fritz-John conditions provide us with theoretical bounds on approximation error between the true and network extracted weak Pareto front. Numerical experiments demonstrates the accuracy and efficiency on a canonical set of benchmark problems and a fairness optimization task from prior works.
TIME: A Transparent, Interpretable, Model-Adaptive and Explainable Neural Network for Dynamic Physical Processes
Mar 06, 2020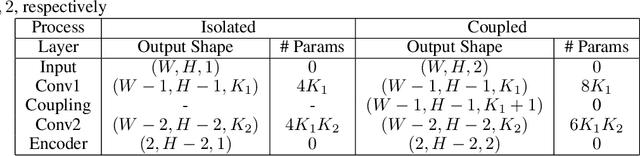

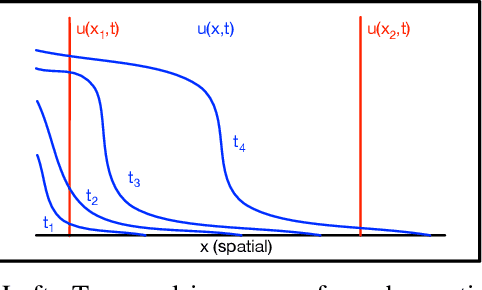
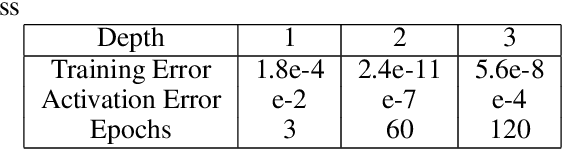
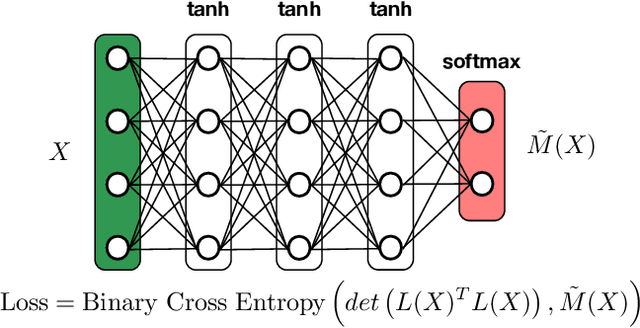
Partial Differential Equations are infinite dimensional encoded representations of physical processes. However, imbibing multiple observation data towards a coupled representation presents significant challenges. We present a fully convolutional architecture that captures the invariant structure of the domain to reconstruct the observable system. The proposed architecture is significantly low-weight compared to other networks for such problems. Our intent is to learn coupled dynamic processes interpreted as deviations from true kernels representing isolated processes for model-adaptivity. Experimental analysis shows that our architecture is robust and transparent in capturing process kernels and system anomalies. We also show that high weights representation is not only redundant but also impacts network interpretability. Our design is guided by domain knowledge, with isolated process representations serving as ground truths for verification. These allow us to identify redundant kernels and their manifestations in activation maps to guide better designs that are both interpretable and explainable unlike traditional deep-nets.
FC-GAGA: Fully Connected Gated Graph Architecture for Spatio-Temporal Traffic Forecasting
Jul 30, 2020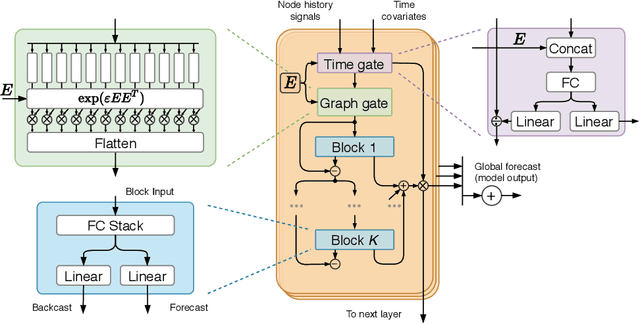
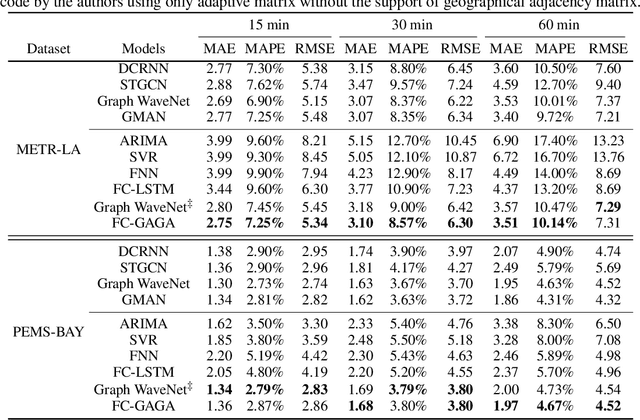
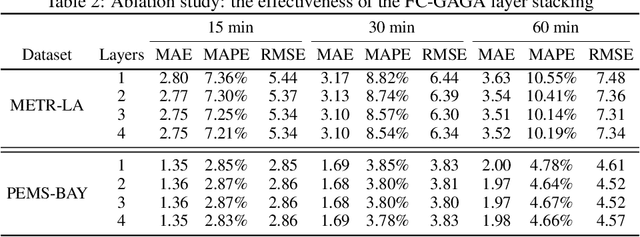
Forecasting of multivariate time-series is an important problem that has applications in many domains, including traffic management, cellular network configuration, and quantitative finance. In recent years, researchers have demonstrated the value of applying deep learning architectures for these problems. A special case of the problem arises when there is a graph available that captures the relationships between the time-series. In this paper we propose a novel learning architecture that achieves performance competitive with or better than the best existing algorithms, without requiring knowledge of the graph. The key elements of our proposed architecture are (i) jointly performing backcasting and forecasting with a deep fully-connected architecture; (ii) stacking multiple prediction modules that target successive residuals; and (iii) learning a separate causal relationship graph for each layer of the stack. We can view each layer as predicting a component of the time-series; the differing nature of the causal graphs at different layers can be interpreted as indicating that the multivariate predictive relationships differ for different components. Experimental results for two public traffic network datasets illustrate the value of our approach, and ablation studies confirm the importance of each element of the architecture.
Search-based Motion Planning for Quadrotors using Linear Quadratic Minimum Time Control
Sep 15, 2017
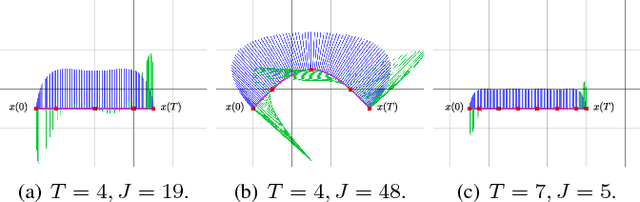
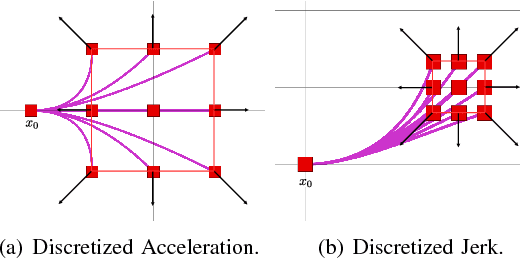
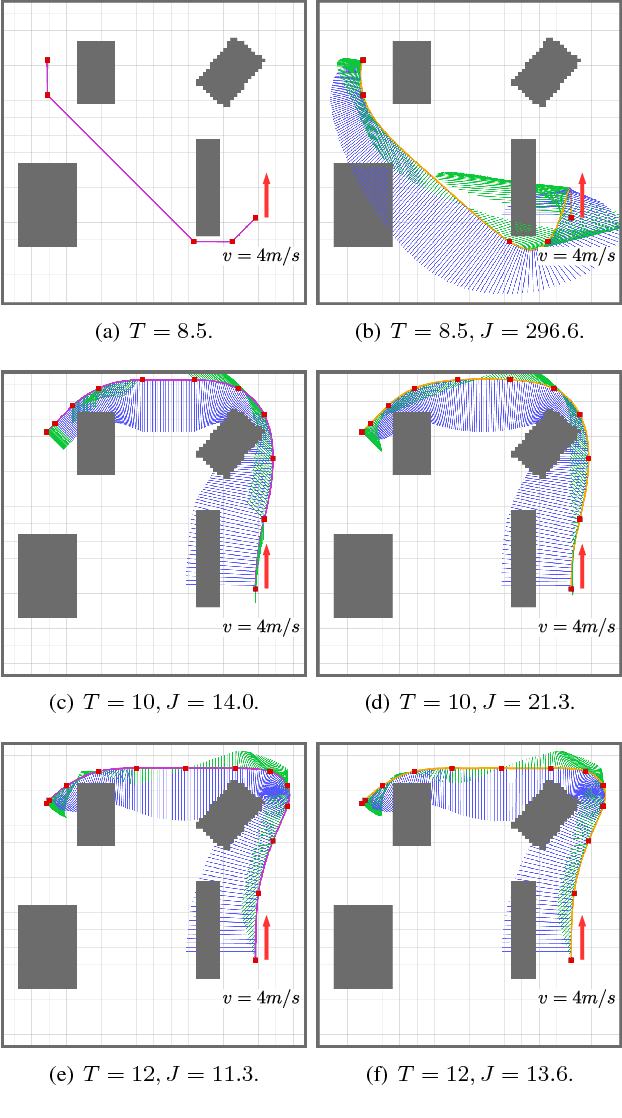
In this work, we propose a search-based planning method to compute dynamically feasible trajectories for a quadrotor flying in an obstacle-cluttered environment. Our approach searches for smooth, minimum-time trajectories by exploring the map using a set of short-duration motion primitives. The primitives are generated by solving an optimal control problem and induce a finite lattice discretization on the state space which can be explored using a graph-search algorithm. The proposed approach is able to generate resolution-complete (i.e., optimal in the discretized space), safe, dynamically feasibility trajectories efficiently by exploiting the explicit solution of a Linear Quadratic Minimum Time problem. It does not assume a hovering initial condition and, hence, is suitable for fast online re-planning while the robot is moving. Quadrotor navigation with online re-planning is demonstrated using the proposed approach in simulation and physical experiments and comparisons with trajectory generation based on state-of-art quadratic programming are presented.
A Review of Speaker Diarization: Recent Advances with Deep Learning
Jan 24, 2021
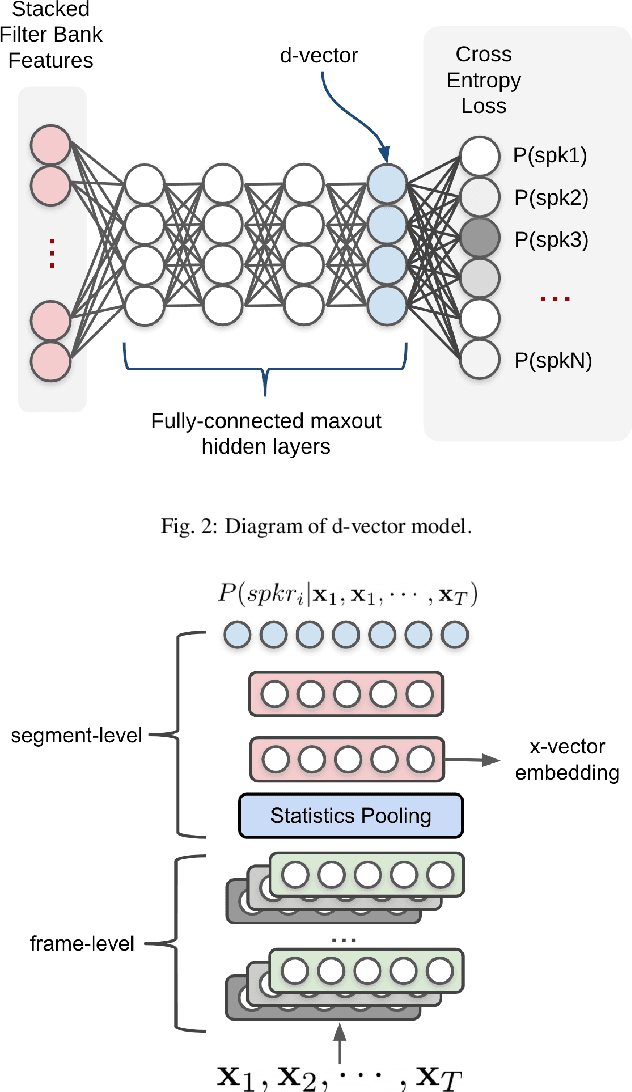
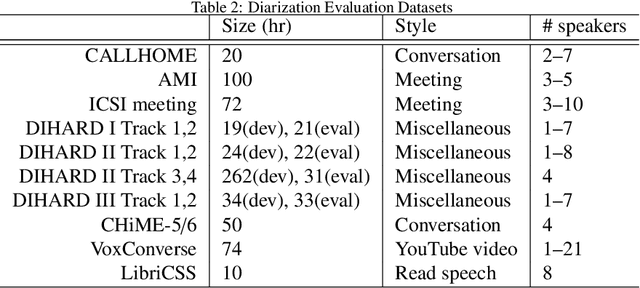
Speaker diarization is a task to label audio or video recordings with classes corresponding to speaker identity, or in short, a task to identify "who spoke when". In the early years, speaker diarization algorithms were developed for speech recognition on multi-speaker audio recordings to enable speaker adaptive processing, but also gained its own value as a stand-alone application over time to provide speaker-specific meta information for downstream tasks such as audio retrieval. More recently, with the rise of deep learning technology that has been a driving force to revolutionary changes in research and practices across speech application domains in the past decade, more rapid advancements have been made for speaker diarization. In this paper, we review not only the historical development of speaker diarization technology but also the recent advancements in neural speaker diarization approaches. We also discuss how speaker diarization systems have been integrated with speech recognition applications and how the recent surge of deep learning is leading the way of jointly modeling these two components to be complementary to each other. By considering such exciting technical trends, we believe that it is a valuable contribution to the community to provide a survey work by consolidating the recent developments with neural methods and thus facilitating further progress towards a more efficient speaker diarization.
Classification and clustering for observations of event time data using non-homogeneous Poisson process models
Jun 20, 2018



Data of the form of event times arise in various applications. A simple model for such data is a non-homogeneous Poisson process (NHPP) which is specified by a rate function that depends on time. We consider the problem of having access to multiple independent observations of event time data, observed on a common interval, from which we wish to classify or cluster the observations according to their rate functions. Each rate function is unknown but assumed to belong to a finite number of rate functions each defining a distinct class. We model the rate functions using a spline basis expansion, the coefficients of which need to be estimated from data. The classification approach consists of using training data for which the class membership is known, to calculate maximum likelihood estimates of the coefficients for each group, then assigning test observations to a group by a maximum likelihood criterion. For clustering, by analogy to the Gaussian mixture model approach for Euclidean data, we consider mixtures of NHPP and use the expectation-maximisation algorithm to estimate the coefficients of the rate functions for the component models and group membership probabilities for each observation. The classification and clustering approaches perform well on both synthetic and real-world data sets. Code associated with this paper is available at https://github.com/duncan-barrack/NHPP .