 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Prediction of the onset of cardiovascular diseases from electronic health records using multi-task gated recurrent units
Jul 16, 2020
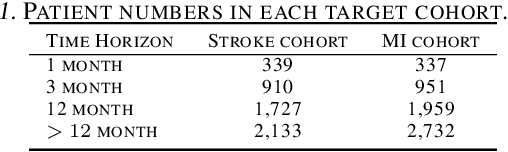
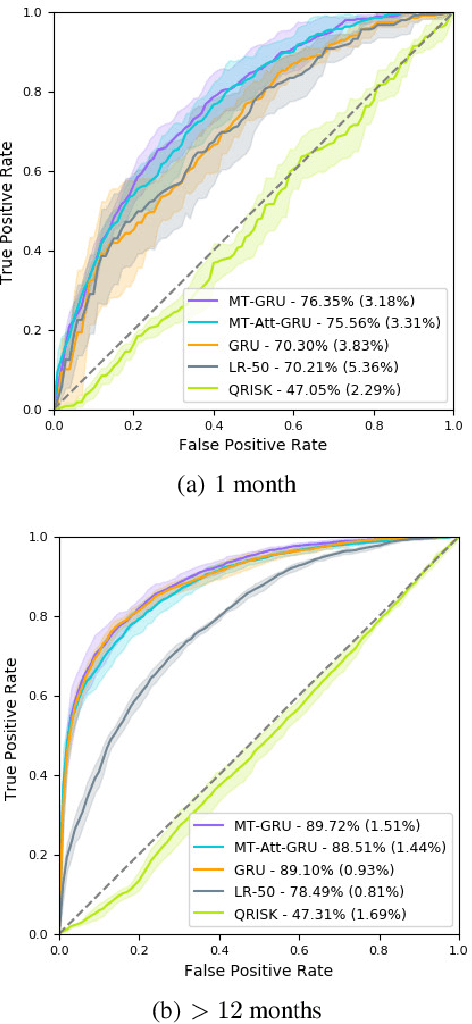
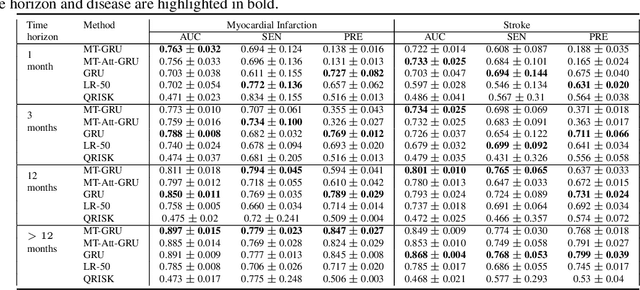
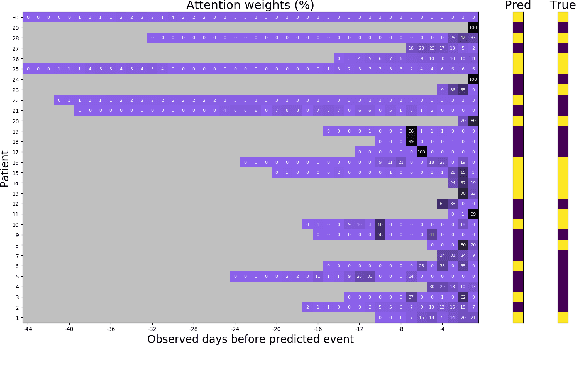
In this work, we propose a multi-task recurrent neural network with attention mechanism for predicting cardiovascular events from electronic health records (EHRs) at different time horizons. The proposed approach is compared to a standard clinical risk predictor (QRISK) and machine learning alternatives using 5-year data from a NHS Foundation Trust. The proposed model outperforms standard clinical risk scores in predicting stroke (AUC=0.85) and myocardial infarction (AUC=0.89), considering the largest time horizon. Benefit of using an \gls{mt} setting becomes visible for very short time horizons, which results in an AUC increase between 2-6%. Further, we explored the importance of individual features and attention weights in predicting cardiovascular events. Our results indicate that the recurrent neural network approach benefits from the hospital longitudinal information and demonstrates how machine learning techniques can be applied to secondary care.
VolumeDeform: Real-time Volumetric Non-rigid Reconstruction
Jul 30, 2016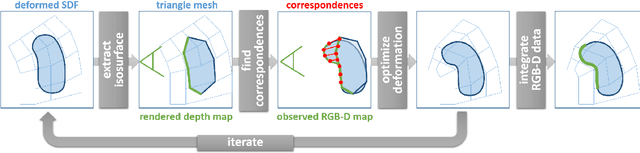



We present a novel approach for the reconstruction of dynamic geometric shapes using a single hand-held consumer-grade RGB-D sensor at real-time rates. Our method does not require a pre-defined shape template to start with and builds up the scene model from scratch during the scanning process. Geometry and motion are parameterized in a unified manner by a volumetric representation that encodes a distance field of the surface geometry as well as the non-rigid space deformation. Motion tracking is based on a set of extracted sparse color features in combination with a dense depth-based constraint formulation. This enables accurate tracking and drastically reduces drift inherent to standard model-to-depth alignment. We cast finding the optimal deformation of space as a non-linear regularized variational optimization problem by enforcing local smoothness and proximity to the input constraints. The problem is tackled in real-time at the camera's capture rate using a data-parallel flip-flop optimization strategy. Our results demonstrate robust tracking even for fast motion and scenes that lack geometric features.
Beyond 4D Tracking: Using Cluster Shapes for Track Seeding
Dec 08, 2020



Tracking is one of the most time consuming aspects of event reconstruction at the Large Hadron Collider (LHC) and its high-luminosity upgrade (HL-LHC). Innovative detector technologies extend tracking to four-dimensions by including timing in the pattern recognition and parameter estimation. However, present and future hardware already have additional information that is largely unused by existing track seeding algorithms. The shape of clusters provides an additional dimension for track seeding that can significantly reduce the combinatorial challenge of track finding. We use neural networks to show that cluster shapes can reduce significantly the rate of fake combinatorical backgrounds while preserving a high efficiency. We demonstrate this using the information in cluster singlets, doublets and triplets. Numerical results are presented with simulations from the TrackML challenge.
Robust Real-Time Multi-View Eye Tracking
Jan 03, 2018

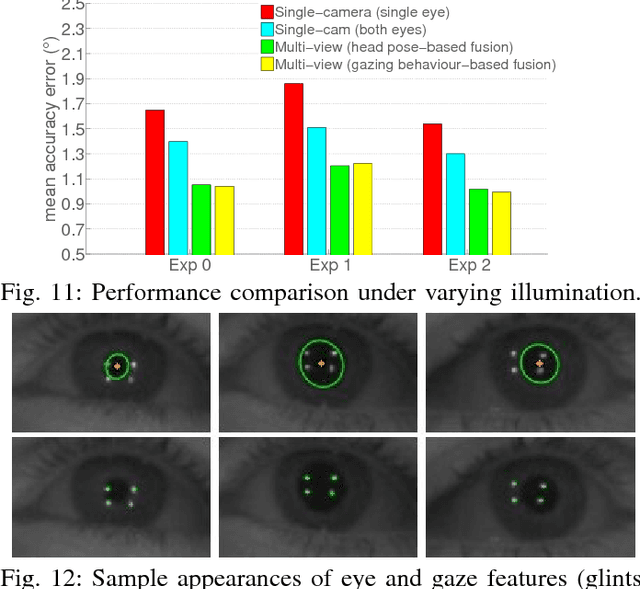
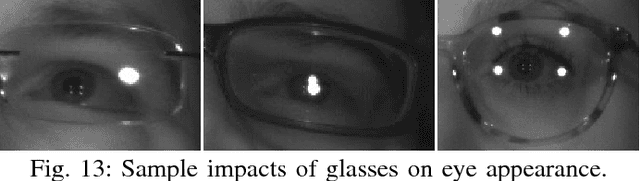
Despite significant advances in improving the gaze tracking accuracy under controlled conditions, the tracking robustness under real-world conditions, such as large head pose and movements, use of eyeglasses, illumination and eye type variations, remains a major challenge in eye tracking. In this paper, we revisit this challenge and introduce a real-time multi-camera eye tracking framework to improve the tracking robustness. First, differently from previous work, we design a multi-view tracking setup that allows for acquiring multiple eye appearances simultaneously. Leveraging multi-view appearances enables to more reliably detect gaze features under challenging conditions, particularly when they are obstructed in conventional single-view appearance due to large head movements or eyewear effects. The features extracted on various appearances are then used for estimating multiple gaze outputs. Second, we propose to combine estimated gaze outputs through an adaptive fusion mechanism to compute user's overall point of regard. The proposed mechanism firstly determines the estimation reliability of each gaze output according to user's momentary head pose and predicted gazing behavior, and then performs a reliability-based weighted fusion. We demonstrate the efficacy of our framework with extensive simulations and user experiments on a collected dataset featuring 20 subjects. Our results show that in comparison with state-of-the-art eye trackers, the proposed framework provides not only a significant enhancement in accuracy but also a notable robustness. Our prototype system runs at 30 frames-per-second (fps) and achieves 1 degree accuracy under challenging experimental scenarios, which makes it suitable for applications demanding high accuracy and robustness.
Asking Crowdworkers to Write Entailment Examples: The Best of Bad Options
Oct 13, 2020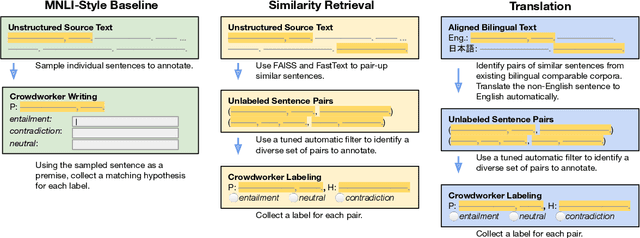

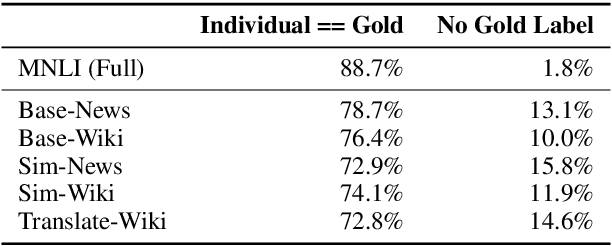

Large-scale natural language inference (NLI) datasets such as SNLI or MNLI have been created by asking crowdworkers to read a premise and write three new hypotheses, one for each possible semantic relationships (entailment, contradiction, and neutral). While this protocol has been used to create useful benchmark data, it remains unclear whether the writing-based annotation protocol is optimal for any purpose, since it has not been evaluated directly. Furthermore, there is ample evidence that crowdworker writing can introduce artifacts in the data. We investigate two alternative protocols which automatically create candidate (premise, hypothesis) pairs for annotators to label. Using these protocols and a writing-based baseline, we collect several new English NLI datasets of over 3k examples each, each using a fixed amount of annotator time, but a varying number of examples to fit that time budget. Our experiments on NLI and transfer learning show negative results: None of the alternative protocols outperforms the baseline in evaluations of generalization within NLI or on transfer to outside target tasks. We conclude that crowdworker writing still the best known option for entailment data, highlighting the need for further data collection work to focus on improving writing-based annotation processes.
Corrupted Contextual Bandits with Action Order Constraints
Nov 16, 2020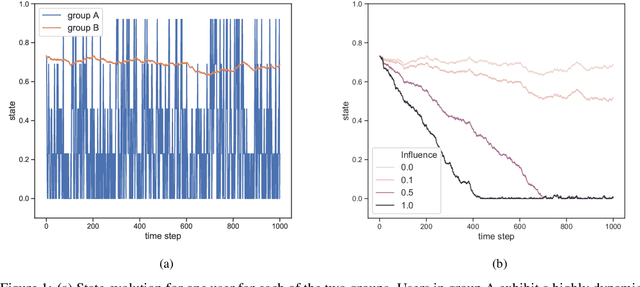
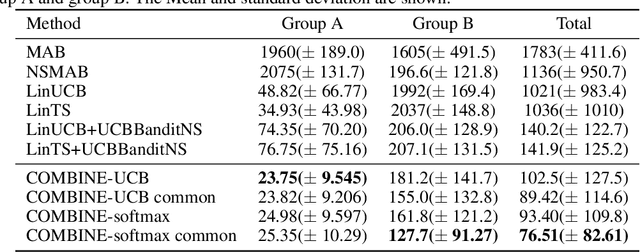
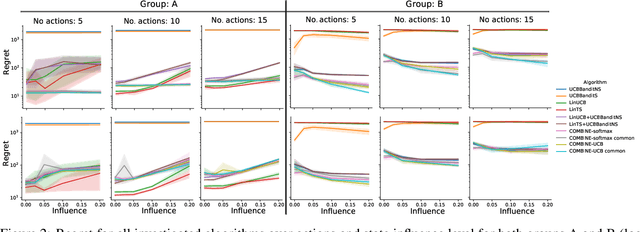
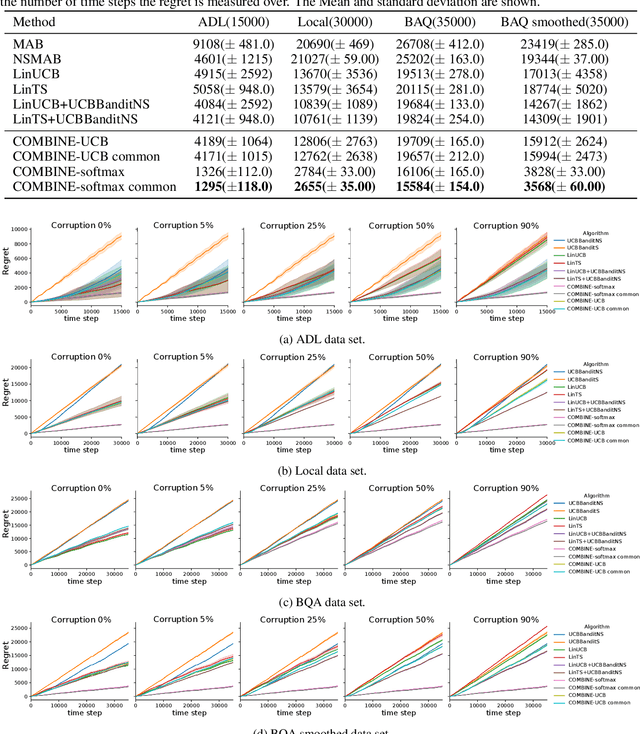
We consider a variant of the novel contextual bandit problem with corrupted context, which we call the contextual bandit problem with corrupted context and action correlation, where actions exhibit a relationship structure that can be exploited to guide the exploration of viable next decisions. Our setting is primarily motivated by adaptive mobile health interventions and related applications, where users might transitions through different stages requiring more targeted action selection approaches. In such settings, keeping user engagement is paramount for the success of interventions and therefore it is vital to provide relevant recommendations in a timely manner. The context provided by users might not always be informative at every decision point and standard contextual approaches to action selection will incur high regret. We propose a meta-algorithm using a referee that dynamically combines the policies of a contextual bandit and multi-armed bandit, similar to previous work, as wells as a simple correlation mechanism that captures action to action transition probabilities allowing for more efficient exploration of time-correlated actions. We evaluate empirically the performance of said algorithm on a simulation where the sequence of best actions is determined by a hidden state that evolves in a Markovian manner. We show that the proposed meta-algorithm improves upon regret in situations where the performance of both policies varies such that one is strictly superior to the other for a given time period. To demonstrate that our setting has relevant practical applicability, we evaluate our method on several real world data sets, clearly showing better empirical performance compared to a set of simple algorithms.
Pretraining and Fine-Tuning Strategies for Sentiment Analysis of Latvian Tweets
Oct 23, 2020
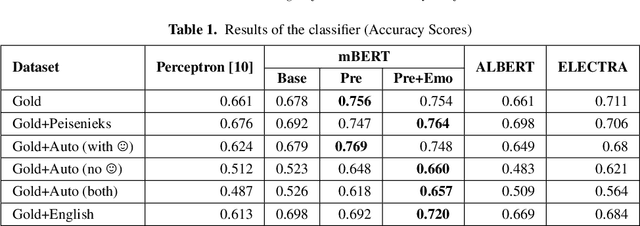

In this paper, we present various pre-training strategies that aid in im-proving the accuracy of the sentiment classification task. We, at first, pre-trainlanguage representation models using these strategies and then fine-tune them onthe downstream task. Experimental results on a time-balanced tweet evaluation setshow the improvement over the previous technique. We achieve 76% accuracy forsentiment analysis on Latvian tweets, which is a substantial improvement over pre-vious work
Hybrid and Non-Uniform quantization methods using retro synthesis data for efficient inference
Dec 26, 2020
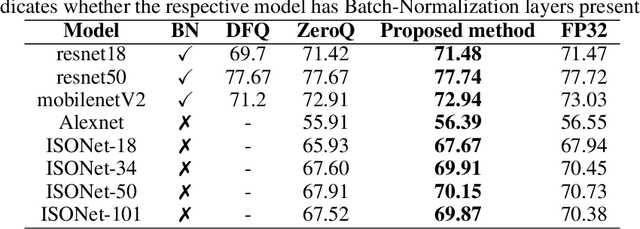

Existing quantization aware training methods attempt to compensate for the quantization loss by leveraging on training data, like most of the post-training quantization methods, and are also time consuming. Both these methods are not effective for privacy constraint applications as they are tightly coupled with training data. In contrast, this paper proposes a data-independent post-training quantization scheme that eliminates the need for training data. This is achieved by generating a faux dataset, hereafter referred to as Retro-Synthesis Data, from the FP32 model layer statistics and further using it for quantization. This approach outperformed state-of-the-art methods including, but not limited to, ZeroQ and DFQ on models with and without Batch-Normalization layers for 8, 6, and 4 bit precisions on ImageNet and CIFAR-10 datasets. We also introduced two futuristic variants of post-training quantization methods namely Hybrid Quantization and Non-Uniform Quantization
Interspeech 2021 Deep Noise Suppression Challenge
Jan 10, 2021
The Deep Noise Suppression (DNS) challenge is designed to foster innovation in the area of noise suppression to achieve superior perceptual speech quality. We recently organized a DNS challenge special session at INTERSPEECH and ICASSP 2020. We open-sourced training and test datasets for the wideband scenario. We also open-sourced a subjective evaluation framework based on ITU-T standard P.808, which was also used to evaluate participants of the challenge. Many researchers from academia and industry made significant contributions to push the field forward, yet even the best noise suppressor was far from achieving superior speech quality in challenging scenarios. In this version of the challenge organized at INTERSPEECH 2021, we are expanding both our training and test datasets to accommodate full band scenarios. The two tracks in this challenge will focus on real-time denoising for (i) wide band, and(ii) full band scenarios. We are also making available a reliable non-intrusive objective speech quality metric called DNSMOS for the participants to use during their development phase.
Psychoacoustic Calibration of Loss Functions for Efficient End-to-End Neural Audio Coding
Dec 31, 2020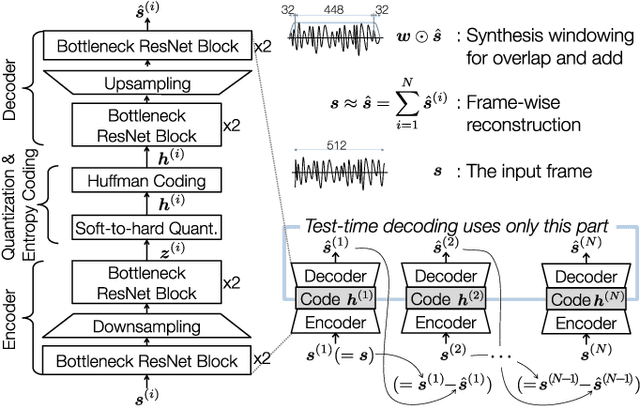
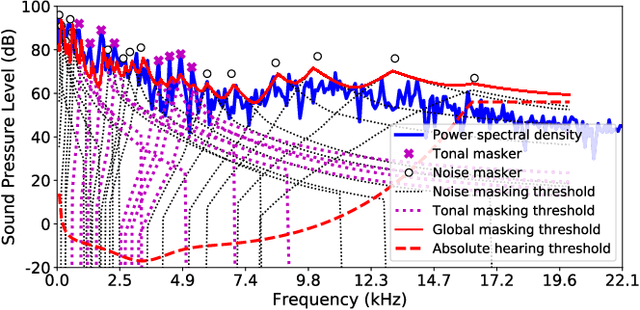
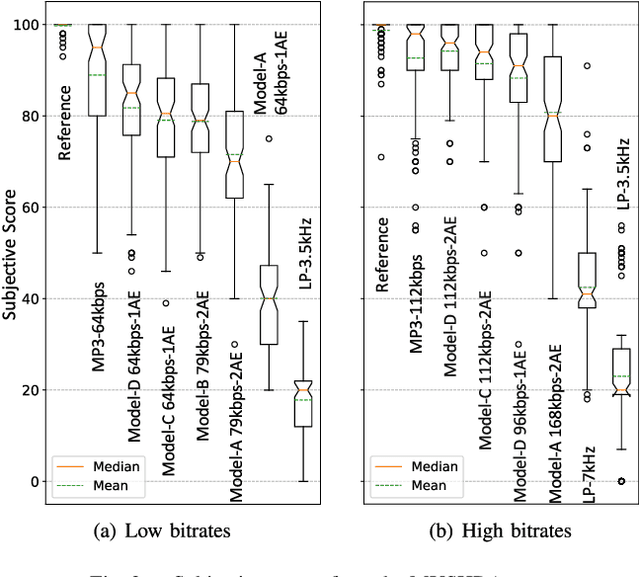
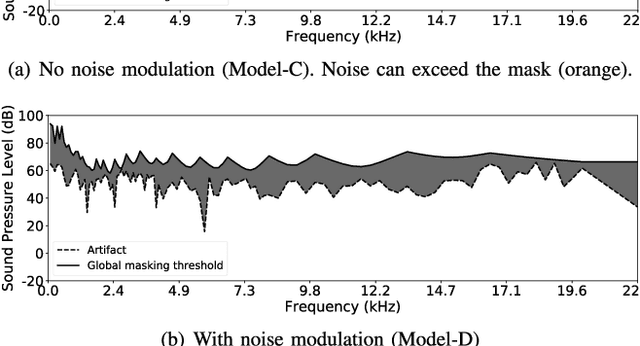
Conventional audio coding technologies commonly leverage human perception of sound, or psychoacoustics, to reduce the bitrate while preserving the perceptual quality of the decoded audio signals. For neural audio codecs, however, the objective nature of the loss function usually leads to suboptimal sound quality as well as high run-time complexity due to the large model size. In this work, we present a psychoacoustic calibration scheme to re-define the loss functions of neural audio coding systems so that it can decode signals more perceptually similar to the reference, yet with a much lower model complexity. The proposed loss function incorporates the global masking threshold, allowing the reconstruction error that corresponds to inaudible artifacts. Experimental results show that the proposed model outperforms the baseline neural codec twice as large and consuming 23.4% more bits per second. With the proposed method, a lightweight neural codec, with only 0.9 million parameters, performs near-transparent audio coding comparable with the commercial MPEG-1 Audio Layer III codec at 112 kbps.