 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Efficient Neural Speech Coding
Mar 27, 2021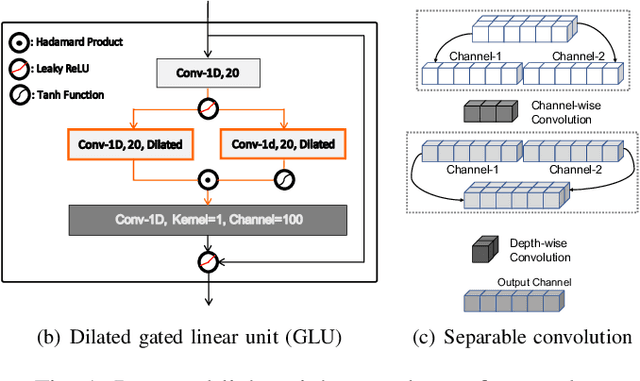
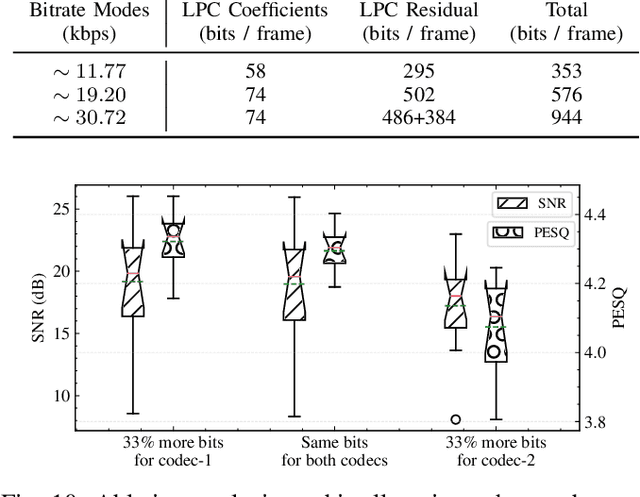
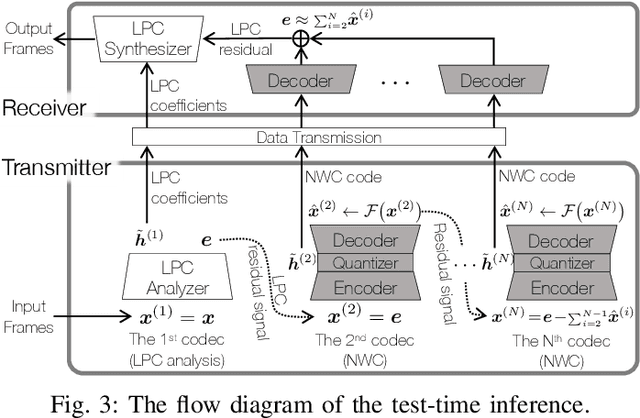
This work presents a scalable and efficient neural waveform codec (NWC) for speech compression. We formulate the speech coding problem as an autoencoding task, where a convolutional neural network (CNN) performs encoding and decoding as its feedforward routine. The proposed CNN autoencoder also defines quantization and entropy coding as a trainable module, so the coding artifacts and bitrate control are handled during the optimization process. We achieve efficiency by introducing compact model architectures to our fully convolutional network model, such as gated residual networks and depthwise separable convolution. Furthermore, the proposed models are with a scalable architecture, cross-module residual learning (CMRL), to cover a wide range of bitrates. To this end, we employ the residual coding concept to concatenate multiple NWC autoencoding modules, where an NWC module performs residual coding to restore any reconstruction loss that its preceding modules have created. CMRL can scale down to cover lower bitrates as well, for which it employs linear predictive coding (LPC) module as its first autoencoder. We redefine LPC's quantization as a trainable module to enhance the bit allocation tradeoff between LPC and its following NWC modules. Compared to the other autoregressive decoder-based neural speech coders, our decoder has significantly smaller architecture, e.g., with only 0.12 million parameters, more than 100 times smaller than a WaveNet decoder. Compared to the LPCNet-based speech codec, which leverages the speech production model to reduce the network complexity in low bitrates, ours can scale up to higher bitrates to achieve transparent performance. Our lightweight neural speech coding model achieves comparable subjective scores against AMR-WB at the low bitrate range and provides transparent coding quality at 32 kbps.
Psychoacoustic Calibration of Loss Functions for Efficient End-to-End Neural Audio Coding
Dec 31, 2020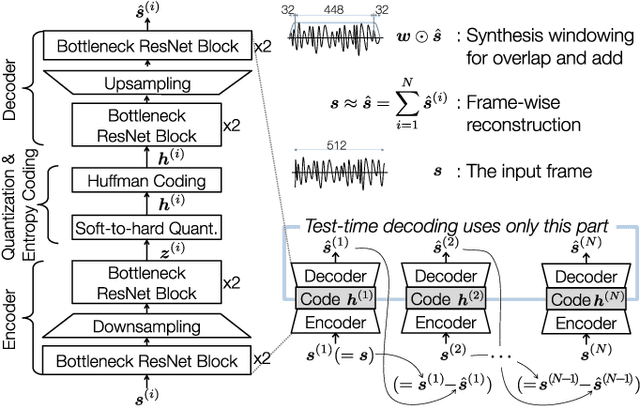
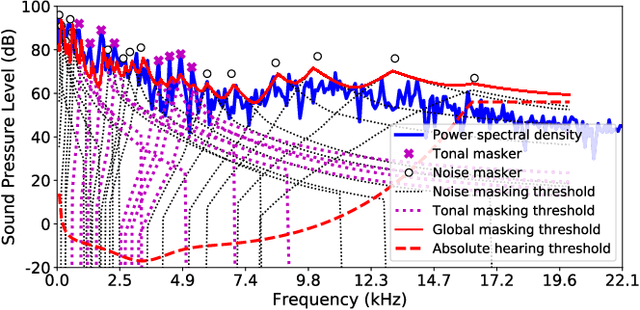
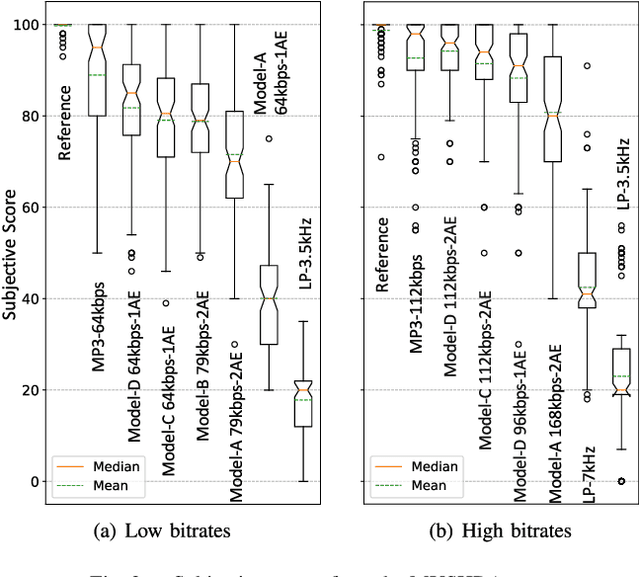
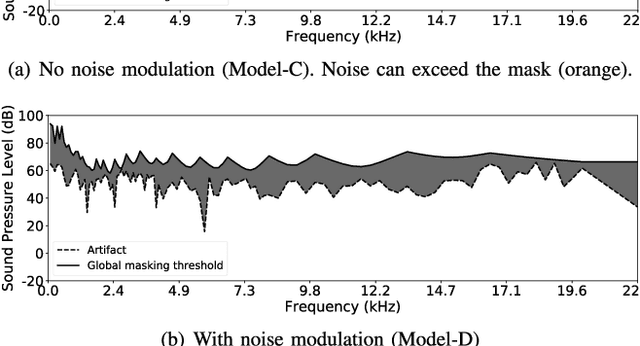
Conventional audio coding technologies commonly leverage human perception of sound, or psychoacoustics, to reduce the bitrate while preserving the perceptual quality of the decoded audio signals. For neural audio codecs, however, the objective nature of the loss function usually leads to suboptimal sound quality as well as high run-time complexity due to the large model size. In this work, we present a psychoacoustic calibration scheme to re-define the loss functions of neural audio coding systems so that it can decode signals more perceptually similar to the reference, yet with a much lower model complexity. The proposed loss function incorporates the global masking threshold, allowing the reconstruction error that corresponds to inaudible artifacts. Experimental results show that the proposed model outperforms the baseline neural codec twice as large and consuming 23.4% more bits per second. With the proposed method, a lightweight neural codec, with only 0.9 million parameters, performs near-transparent audio coding comparable with the commercial MPEG-1 Audio Layer III codec at 112 kbps.
Efficient Context Aggregation for End-to-End Speech Enhancement Using a Densely Connected Convolutional and Recurrent Network
Aug 18, 2019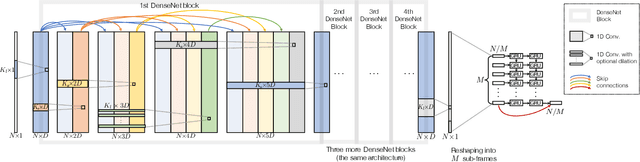
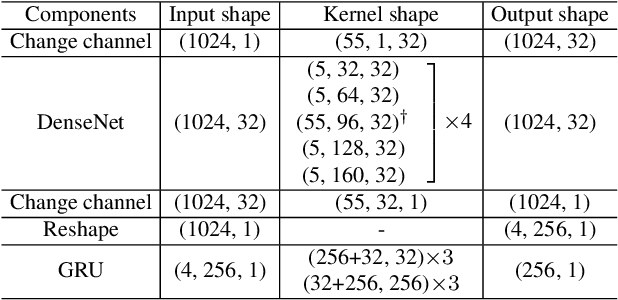
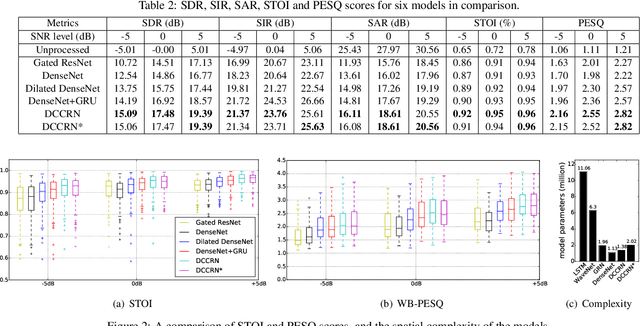
In speech enhancement, an end-to-end deep neural network converts a noisy speech signal to a clean speech directly in time domain without time-frequency transformation or mask estimation. However, aggregating contextual information from a high-resolution time domain signal with an affordable model complexity still remains challenging. In this paper, we propose a hybrid architecture, incorporating densely connected convolutional networks (DenseNet) and gated recurrent units (GRU), to enable dual-level temporal context aggregation. Due to the dense connectivity pattern and a cross-component identical shortcut, the proposed model consistently outperforms competing convolutional baselines with an average STOI improvement of 0.23 and PESQ of 1.38 at three SNR levels. In addition, the proposed hybrid architecture is computationally efficient with 1.38 million parameters.
Cascaded Cross-Module Residual Learning towards Lightweight End-to-End Speech Coding
Jun 18, 2019
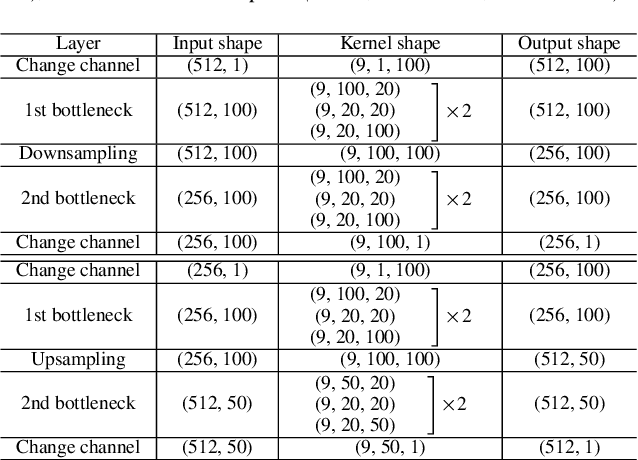
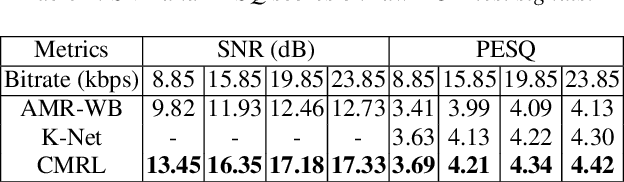
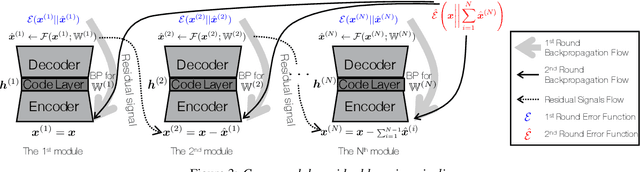
Speech codecs learn compact representations of speech signals to facilitate data transmission. Many recent deep neural network (DNN) based end-to-end speech codecs achieve low bitrates and high perceptual quality at the cost of model complexity. We propose a cross-module residual learning (CMRL) pipeline as a module carrier with each module reconstructing the residual from its preceding modules. CMRL differs from other DNN-based speech codecs, in that rather than modeling speech compression problem in a single large neural network, it optimizes a series of less-complicated modules in a two-phase training scheme. The proposed method shows better objective performance than AMR-WB and the state-of-the-art DNN-based speech codec with a similar network architecture. As an end-to-end model, it takes raw PCM signals as an input, but is also compatible with linear predictive coding (LPC), showing better subjective quality at high bitrates than AMR-WB and OPUS. The gain is achieved by using only 0.9 million trainable parameters, a significantly less complex architecture than the other DNN-based codecs in the literature.