 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ultra-Fast, Low-Storage, Highly Effective Coarse-grained Selection in Retrieval-based Chatbot by Using Deep Semantic Hashing
Dec 18, 2020
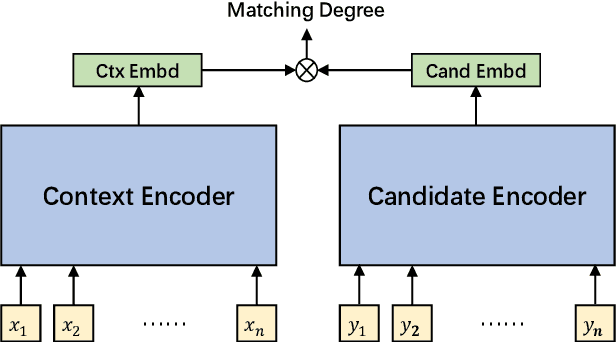
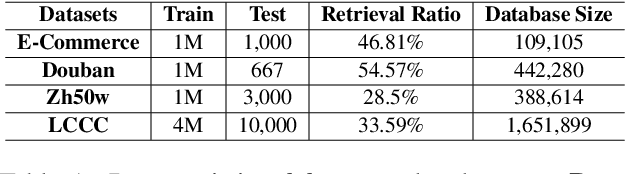
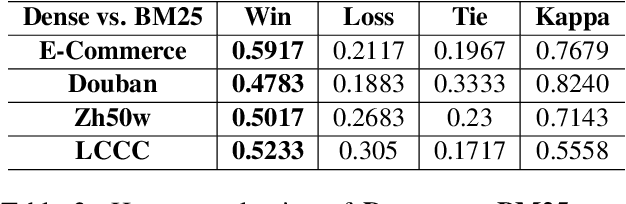
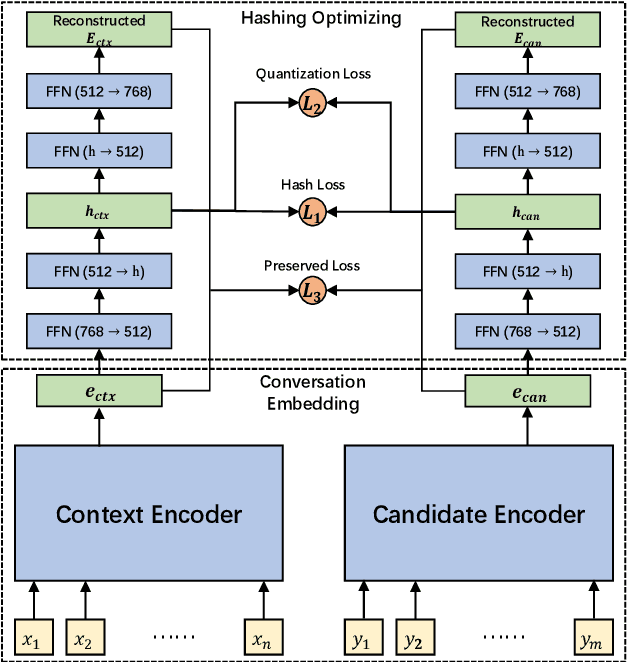
We study the coarse-grained selection module in retrieval-based chatbot. Coarse-grained selection is a basic module in a retrieval-based chatbot, which constructs a rough candidate set from the whole database to speed up the interaction with customers. So far, there are two kinds of approaches for coarse-grained selection module: (1) sparse representation; (2) dense representation. To the best of our knowledge, there is no systematic comparison between these two approaches in retrieval-based chatbots, and which kind of method is better in real scenarios is still an open question. In this paper, we first systematically compare these two methods from four aspects: (1) effectiveness; (2) index stoarge; (3) search time cost; (4) human evaluation. Extensive experiment results demonstrate that dense representation method significantly outperforms the sparse representation, but costs more time and storage occupation. In order to overcome these fatal weaknesses of dense representation method, we propose an ultra-fast, low-storage, and highly effective Deep Semantic Hashing Coarse-grained selection method, called DSHC model. Specifically, in our proposed DSHC model, a hashing optimizing module that consists of two autoencoder models is stacked on a trained dense representation model, and three loss functions are designed to optimize it. The hash codes provided by hashing optimizing module effectively preserve the rich semantic and similarity information in dense vectors. Extensive experiment results prove that, our proposed DSHC model can achieve much faster speed and lower storage than sparse representation, with limited performance loss compared with dense representation. Besides, our source codes have been publicly released for future research.
Online Neural Networks for Change-Point Detection
Oct 03, 2020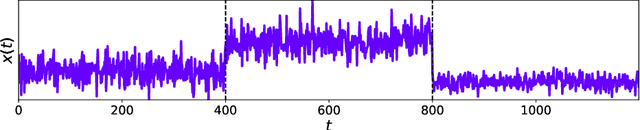
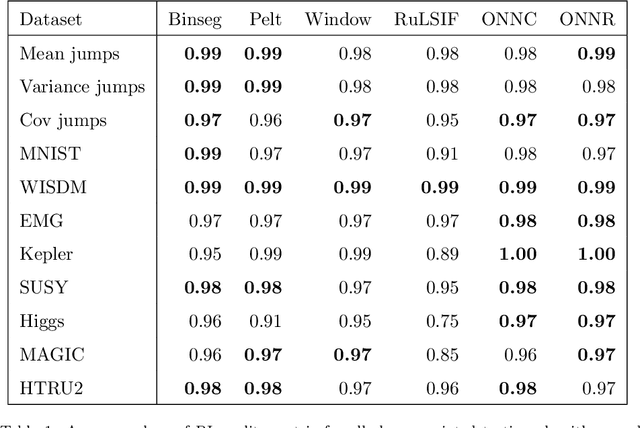
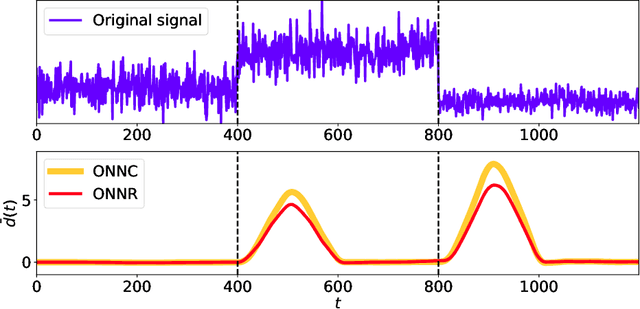
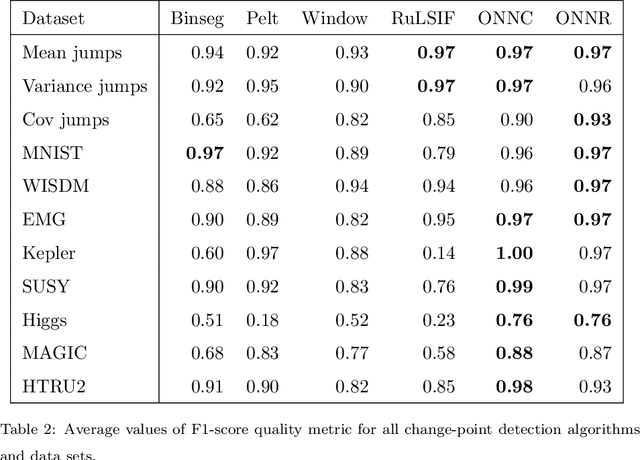
Moments when a time series changes its behaviour are called change points. Detection of such points is a well-known problem, which can be found in many applications: quality monitoring of industrial processes, failure detection in complex systems, health monitoring, speech recognition and video analysis. Occurrence of change point implies that the state of the system is altered and its timely detection might help to prevent unwanted consequences. In this paper, we present two online change-point detection approaches based on neural networks. These algorithms demonstrate linear computational complexity and are suitable for change-point detection in large time series. We compare them with the best known algorithms on various synthetic and real world data sets. Experiments show that the proposed methods outperform known approaches.
Dynamically Constrained Motion Planning Networks for Non-Holonomic Robots
Aug 12, 2020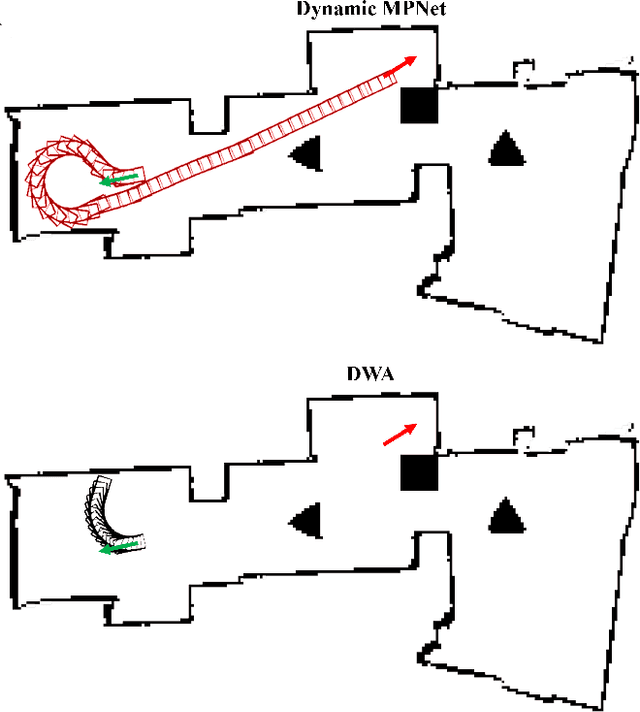
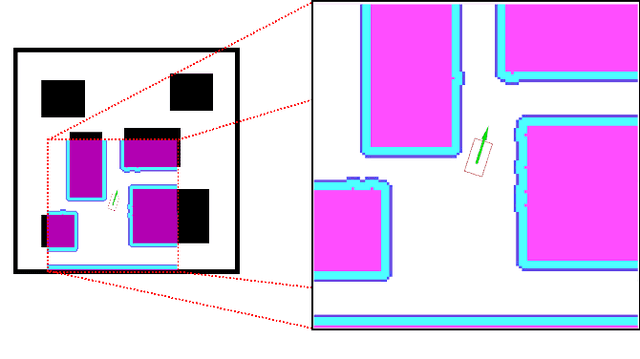
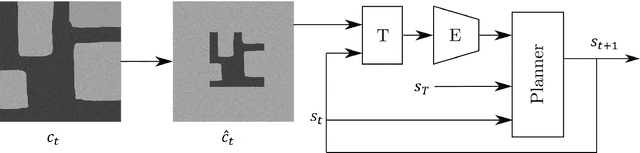
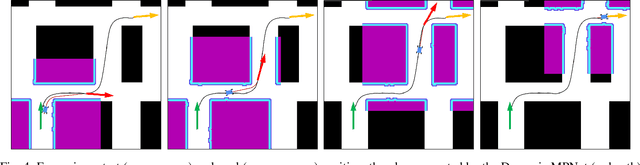
Reliable real-time planning for robots is essential in today's rapidly expanding automated ecosystem. In such environments, traditional methods that plan by relaxing constraints become unreliable or slow-down for kinematically constrained robots. This paper describes the algorithm Dynamic Motion Planning Networks (Dynamic MPNet), an extension to Motion Planning Networks, for non-holonomic robots that address the challenge of real-time motion planning using a neural planning approach. We propose modifications to the training and planning networks that make it possible for real-time planning while improving the data efficiency of training and trained models' generalizability. We evaluate our model in simulation for planning tasks for a non-holonomic robot. We also demonstrate experimental results for an indoor navigation task using a Dubins car.
Smooth Variational Graph Embeddings for Efficient Neural Architecture Search
Oct 09, 2020
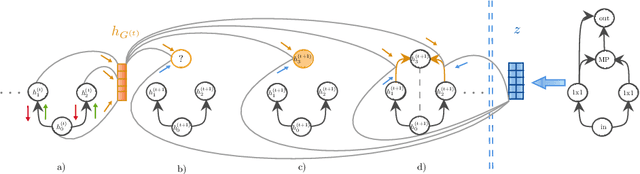
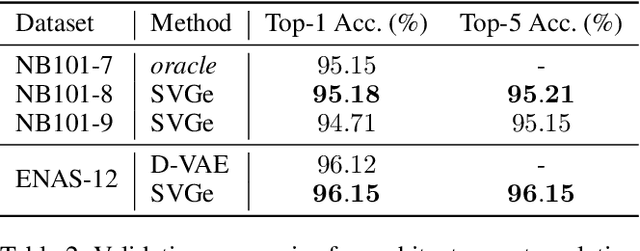
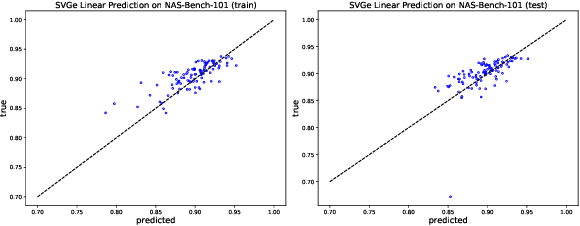
In this paper, we propose an approach to neural architecture search (NAS) based on graph embeddings. NAS has been addressed previously using discrete, sampling based methods, which are computationally expensive as well as differentiable approaches, which come at lower costs but enforce stronger constraints on the search space. The proposed approach leverages advantages from both sides by building a smooth variational neural architecture embedding space in which we evaluate a structural subset of architectures at training time using the predicted performance while it allows to extrapolate from this subspace at inference time. We evaluate the proposed approach in the context of two common search spaces, the graph structure defined by the ENAS approach and the NAS-Bench-101 search space, and improve over the state of the art in both.
Cluster-to-Conquer: A Framework for End-to-End Multi-Instance Learning for Whole Slide Image Classification
Mar 19, 2021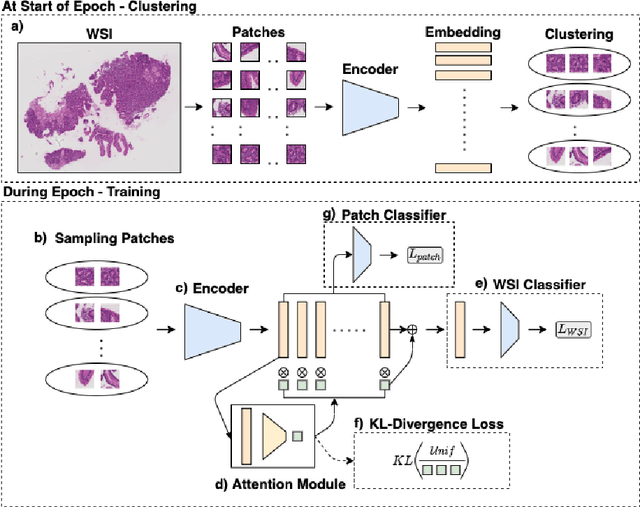
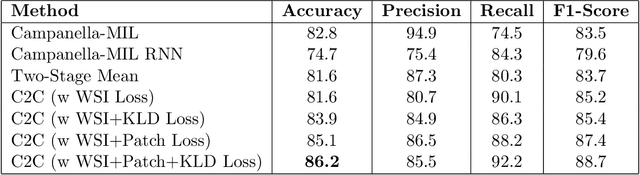
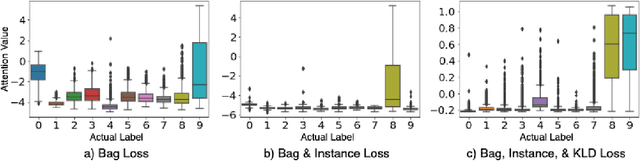

In recent years, the availability of digitized Whole Slide Images (WSIs) has enabled the use of deep learning-based computer vision techniques for automated disease diagnosis. However, WSIs present unique computational and algorithmic challenges. WSIs are gigapixel-sized ($\sim$100K pixels), making them infeasible to be used directly for training deep neural networks. Also, often only slide-level labels are available for training as detailed annotations are tedious and can be time-consuming for experts. Approaches using multiple-instance learning (MIL) frameworks have been shown to overcome these challenges. Current state-of-the-art approaches divide the learning framework into two decoupled parts: a convolutional neural network (CNN) for encoding the patches followed by an independent aggregation approach for slide-level prediction. In this approach, the aggregation step has no bearing on the representations learned by the CNN encoder. We have proposed an end-to-end framework that clusters the patches from a WSI into ${k}$-groups, samples ${k}'$ patches from each group for training, and uses an adaptive attention mechanism for slide level prediction; Cluster-to-Conquer (C2C). We have demonstrated that dividing a WSI into clusters can improve the model training by exposing it to diverse discriminative features extracted from the patches. We regularized the clustering mechanism by introducing a KL-divergence loss between the attention weights of patches in a cluster and the uniform distribution. The framework is optimized end-to-end on slide-level cross-entropy, patch-level cross-entropy, and KL-divergence loss (Implementation: https://github.com/YashSharma/C2C).
Classification of Imbalanced Credit scoring data sets Based on Ensemble Method with the Weighted-Hybrid-Sampling
Feb 09, 2021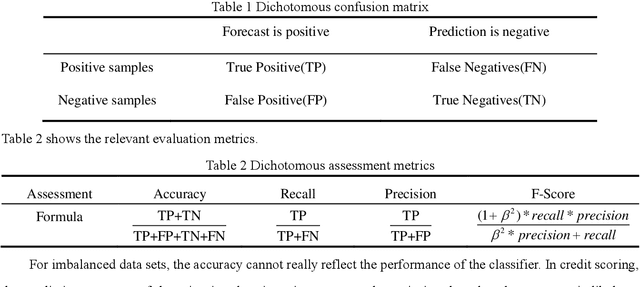
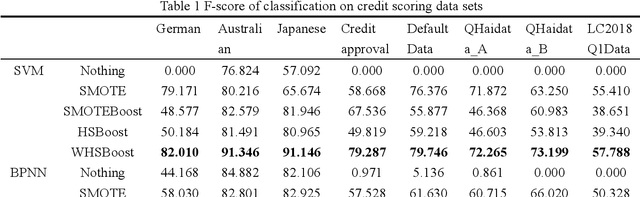
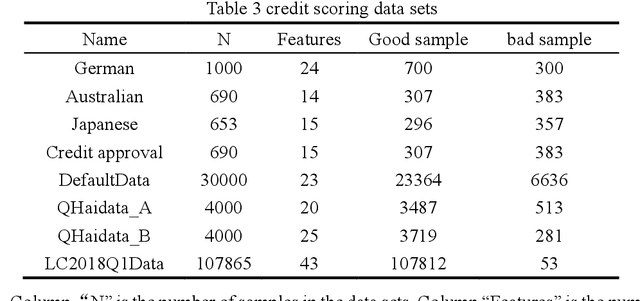
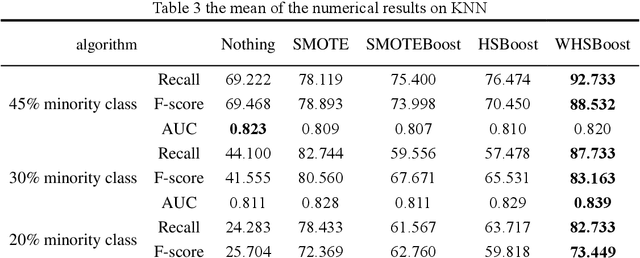
In the era of big data, the utilization of credit-scoring models to determine the credit risk of applicants accurately becomes a trend in the future. The conventional machine learning on credit scoring data sets tends to have poor classification for the minority class, which may bring huge commercial harm to banks. In order to classify imbalanced data sets, we propose a new ensemble algorithm, namely, Weighted-Hybrid-Sampling-Boost (WHSBoost). In data sampling, we process the imbalanced data sets with weights by the Weighted-SMOTE method and the Weighted-Under-Sampling method, and thus obtain a balanced training sample data set with equal weight. In ensemble algorithm, each time we train the base classifier, the balanced data set is given by the method above. In order to verify the applicability and robustness of the WHSBoost algorithm, we performed experiments on the simulation data sets, real benchmark data sets and real credit scoring data sets, comparing WHSBoost with SMOTE, SMOTEBoost and HSBoost based on SVM, BPNN, DT and KNN.
Deep Hedging, Generative Adversarial Networks, and Beyond
Mar 05, 2021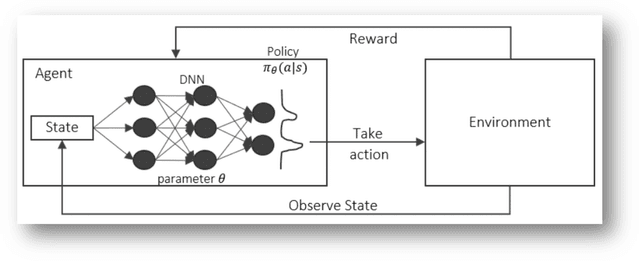
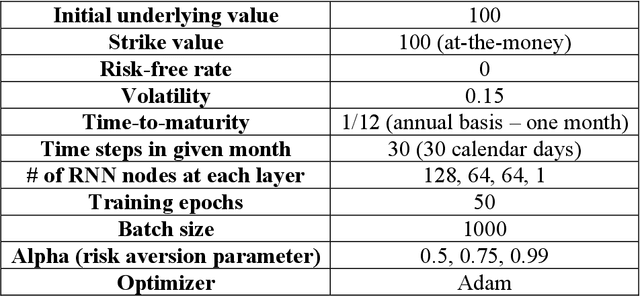

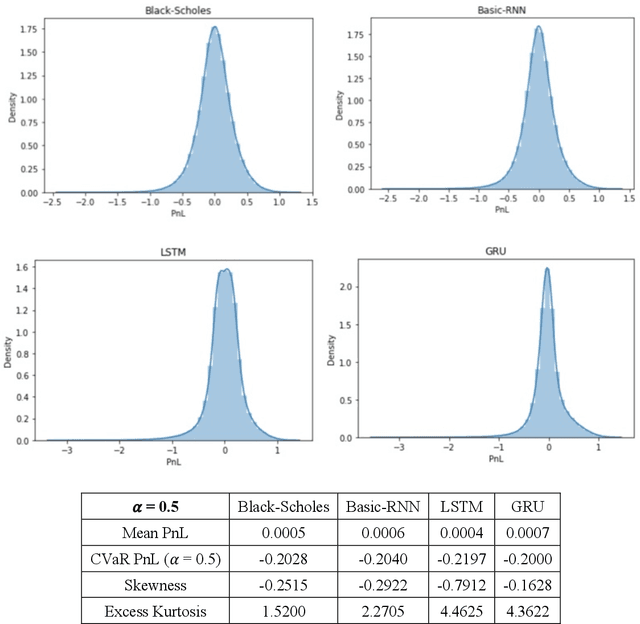
This paper introduces a potential application of deep learning and artificial intelligence in finance, particularly its application in hedging. The major goal encompasses two objectives. First, we present a framework of a direct policy search reinforcement agent replicating a simple vanilla European call option and use the agent for the model-free delta hedging. Through the first part of this paper, we demonstrate how the RNN-based direct policy search RL agents can perform delta hedging better than the classic Black-Scholes model in Q-world based on parametrically generated underlying scenarios, particularly minimizing tail exposures at higher values of the risk aversion parameter. In the second part of this paper, with the non-parametric paths generated by time-series GANs from multi-variate temporal space, we illustrate its delta hedging performance on various values of the risk aversion parameter via the basic RNN-based RL agent introduced in the first part of the paper, showing that we can potentially achieve higher average profits with a rather evident risk-return trade-off. We believe that this RL-based hedging framework is a more efficient way of performing hedging in practice, addressing some of the inherent issues with the classic models, providing promising/intuitive hedging results, and rendering a flexible framework that can be easily paired with other AI-based models for many other purposes.
Integration of deep learning with expectation maximization for spatial cue based speech separation in reverberant conditions
Feb 26, 2021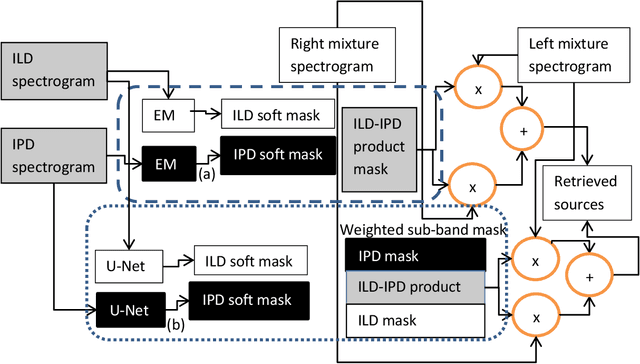
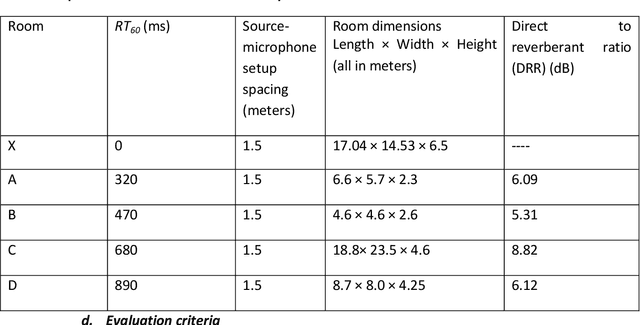
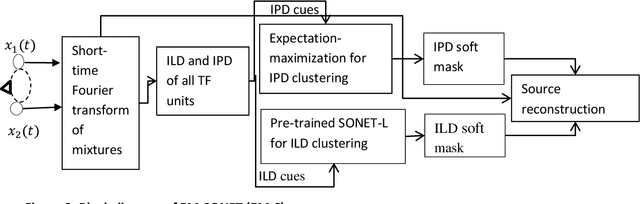

In this paper, we formulate a blind source separation (BSS) framework, which allows integrating U-Net based deep learning source separation network with probabilistic spatial machine learning expectation maximization (EM) algorithm for separating speech in reverberant conditions. Our proposed model uses a pre-trained deep learning convolutional neural network, U-Net, for clustering the interaural level difference (ILD) cues and machine learning expectation maximization (EM) algorithm for clustering the interaural phase difference (IPD) cues. The integrated model exploits the complementary strengths of the two approaches to BSS: the strong modeling power of supervised neural networks and the ease of unsupervised machine learning algorithms, whose few parameters can be estimated on as little as a single segment of an audio mixture. The results show an average improvement of 4.3 dB in signal to distortion ratio (SDR) and 4.3% in short time speech intelligibility (STOI) over the EM based source separation algorithm MESSL-GS (model-based expectation-maximization source separation and localization with garbage source) and 4.5 dB in SDR and 8% in STOI over deep learning convolutional neural network (U-Net) based speech separation algorithm SONET under the reverberant conditions ranging from anechoic to those mostly encountered in the real world.
OTFS Signaling for Uplink NOMA of Heterogeneous Mobility Users
Feb 09, 2021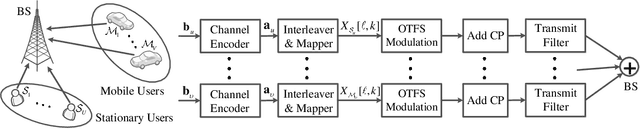
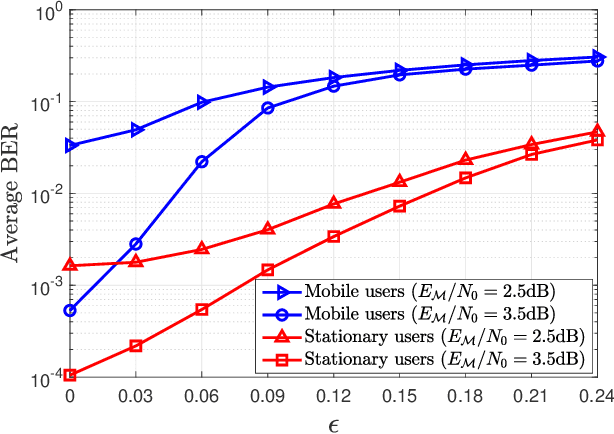
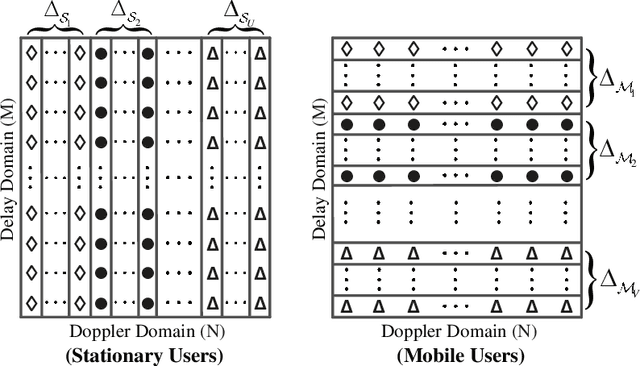
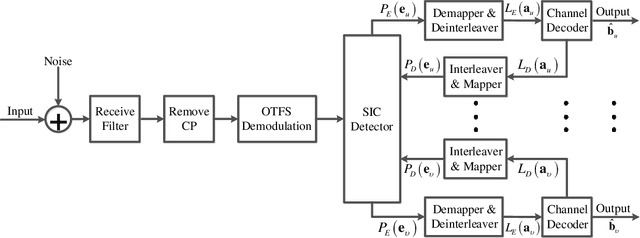
We investigate a coded uplink non-orthogonal multiple access (NOMA) configuration in which groups of co-channel users are modulated in accordance with orthogonal time frequency space (OTFS). We take advantage of OTFS characteristics to achieve NOMA spectrum sharing in the delay-Doppler domain between stationary and mobile users. We develop an efficient iterative turbo receiver based on the principle of successive interference cancellation (SIC) to overcome the co-channel interference (CCI). We propose two turbo detector algorithms: orthogonal approximate message passing with linear minimum mean squared error (OAMP-LMMSE) and Gaussian approximate message passing with expectation propagation (GAMP-EP). The interactive OAMP-LMMSE detector and GAMP-EP detector are respectively assigned for the reception of the stationary and mobile users. We analyze the convergence performance of our proposed iterative SIC turbo receiver by utilizing a customized extrinsic information transfer (EXIT) chart and simplify the corresponding detector algorithms to further reduce receiver complexity. Our proposed iterative SIC turbo receiver demonstrates performance improvement over existing receivers and robustness against imperfect SIC process and channel state information uncertainty.
Potential Impacts of Smart Homes on Human Behavior: A Reinforcement Learning Approach
Feb 26, 2021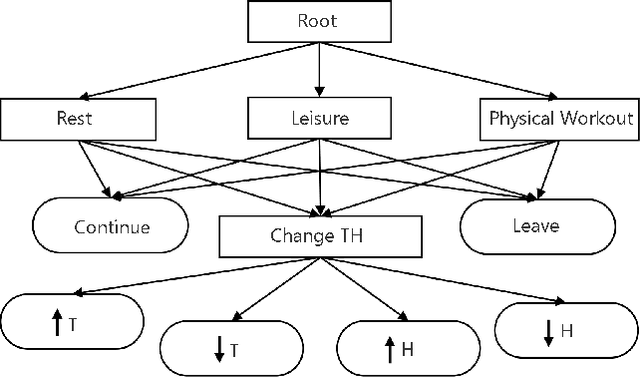
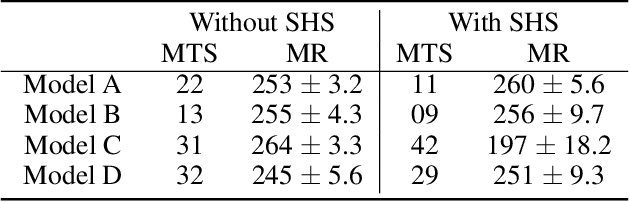

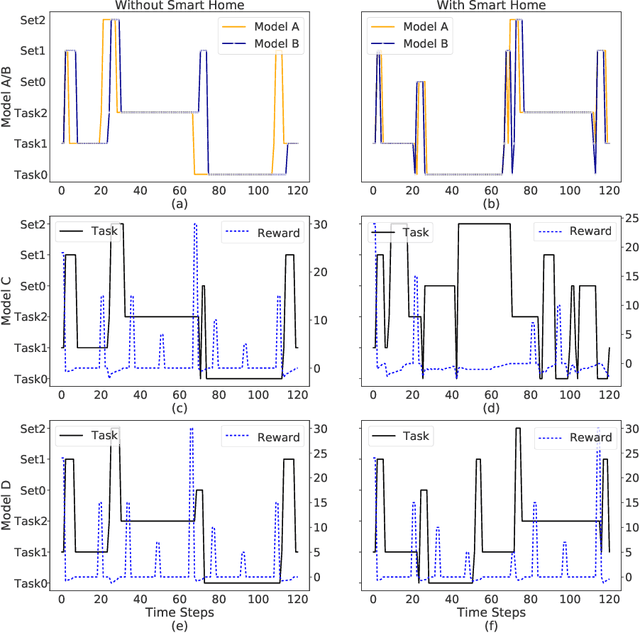
We aim to investigate the potential impacts of smart homes on human behavior. To this end, we simulate a series of human models capable of performing various activities inside a reinforcement learning-based smart home. We then investigate the possibility of human behavior being altered as a result of the smart home and the human model adapting to one-another. We design a semi-Markov decision process human task interleaving model based on hierarchical reinforcement learning that learns to make decisions to either pursue or leave an activity. We then integrate our human model in the smart home which is based on Q-learning. We show that a smart home trained on a generic human model is able to anticipate and learn the thermal preferences of human models with intrinsic rewards similar to the generic model. The hierarchical human model learns to complete each activity and set optimal thermal settings for maximum comfort. With the smart home, the number of time steps required to change the thermal settings are reduced for the human models. Interestingly, we observe that small variations in the human model reward structures can lead to the opposite behavior in the form of unexpected switching between activities which signals changes in human behavior due to the presence of the smart home.