 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning What To Do by Simulating the Past
Apr 08, 2021

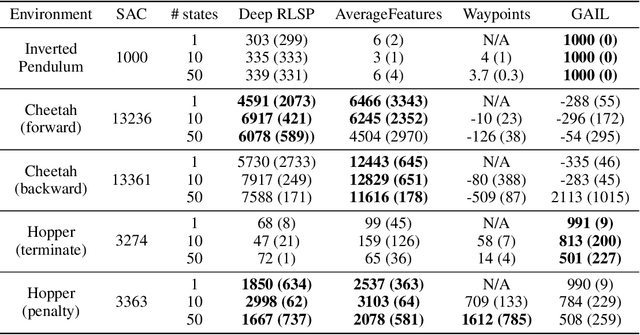

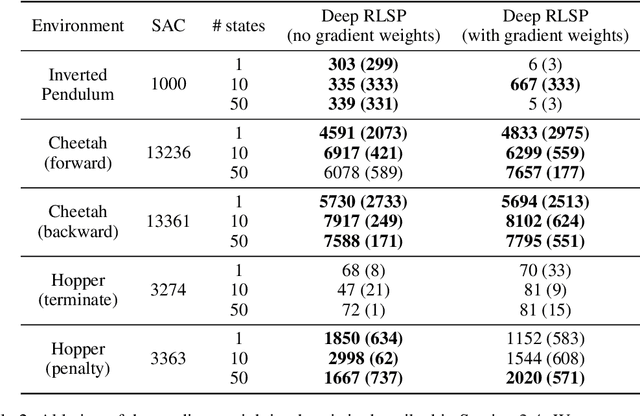
Since reward functions are hard to specify, recent work has focused on learning policies from human feedback. However, such approaches are impeded by the expense of acquiring such feedback. Recent work proposed that agents have access to a source of information that is effectively free: in any environment that humans have acted in, the state will already be optimized for human preferences, and thus an agent can extract information about what humans want from the state. Such learning is possible in principle, but requires simulating all possible past trajectories that could have led to the observed state. This is feasible in gridworlds, but how do we scale it to complex tasks? In this work, we show that by combining a learned feature encoder with learned inverse models, we can enable agents to simulate human actions backwards in time to infer what they must have done. The resulting algorithm is able to reproduce a specific skill in MuJoCo environments given a single state sampled from the optimal policy for that skill.
Continual Semantic Segmentation via Repulsion-Attraction of Sparse and Disentangled Latent Representations
Mar 30, 2021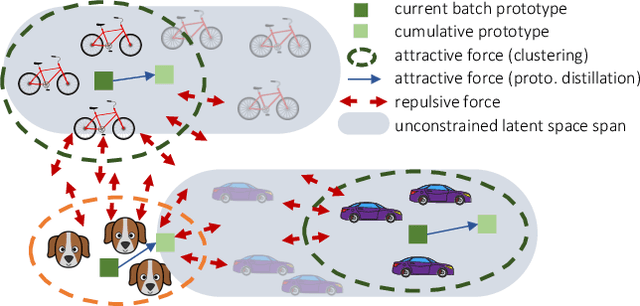
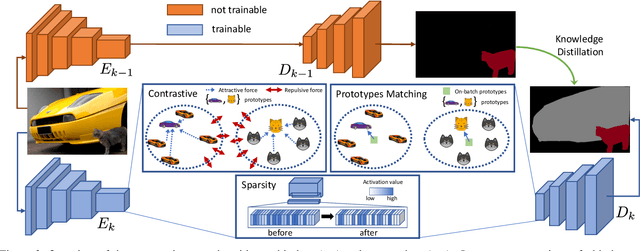
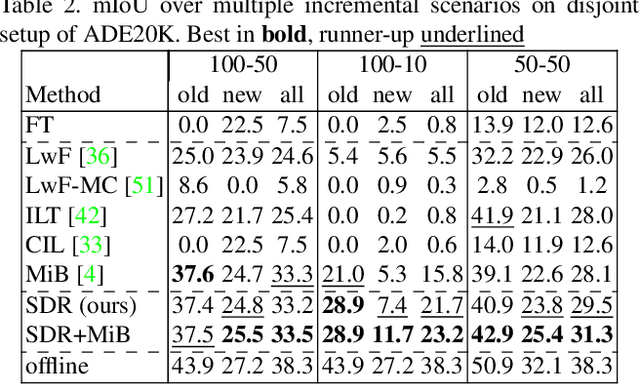

Deep neural networks suffer from the major limitation of catastrophic forgetting old tasks when learning new ones. In this paper we focus on class incremental continual learning in semantic segmentation, where new categories are made available over time while previous training data is not retained. The proposed continual learning scheme shapes the latent space to reduce forgetting whilst improving the recognition of novel classes. Our framework is driven by three novel components which we also combine on top of existing techniques effortlessly. First, prototypes matching enforces latent space consistency on old classes, constraining the encoder to produce similar latent representation for previously seen classes in the subsequent steps. Second, features sparsification allows to make room in the latent space to accommodate novel classes. Finally, contrastive learning is employed to cluster features according to their semantics while tearing apart those of different classes. Extensive evaluation on the Pascal VOC2012 and ADE20K datasets demonstrates the effectiveness of our approach, significantly outperforming state-of-the-art methods.
LSTM-based Space Occupancy Prediction towards Efficient Building Energy Management
Dec 15, 2020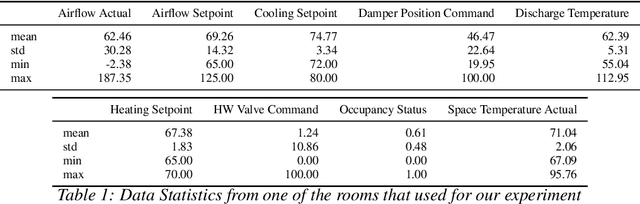
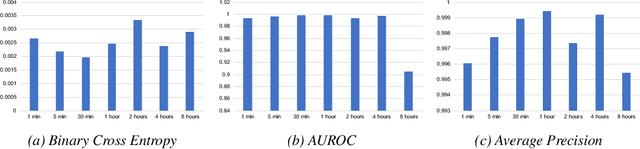
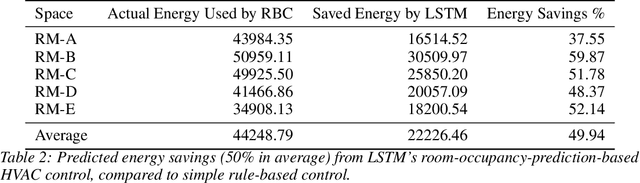
Energy consumed in buildings takes significant portions of the total global energy usage. A large amount of building energy is used for heating, cooling, ventilation, and air-conditioning (HVAC). However, compared to its importance, building energy management systems nowadays are limited in controlling HVAC based on simple rule-based control (RBC) technologies. The ability to design systems that can efficiently manage HVAC can reduce energy usage and greenhouse gas emissions, and, all in all, it can help us to mitigate climate change. This paper proposes predictive time-series models of occupancy patterns using LSTM. Prediction signal for future room occupancy status on the next time span (e.g., next 30 minutes) can be directly used to operate HVAC. For example, based on the prediction and considering the time for cooling or heating, HVAC can be turned on before the room is being used (e.g., turn on 10 minutes earlier). Also, based on the next room empty prediction timing, HVAC can be turned off earlier, and it can help us increase the efficiency of HVAC while not decreasing comfort. We demonstrate our approach's capabilities using real-world energy data collected from multiple rooms of a university building. We show that LSTM's room occupancy prediction based HVAC control could save energy usage by 50% compared to conventional RBC based control.
CSAFL: A Clustered Semi-Asynchronous Federated Learning Framework
Apr 16, 2021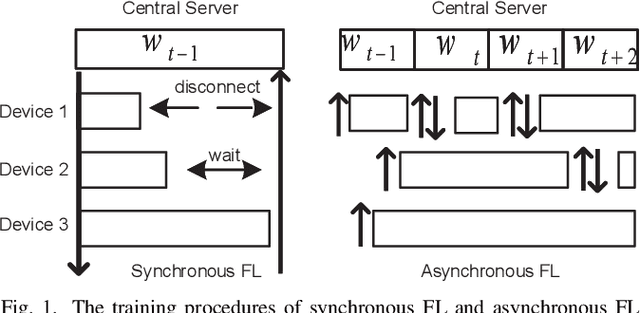
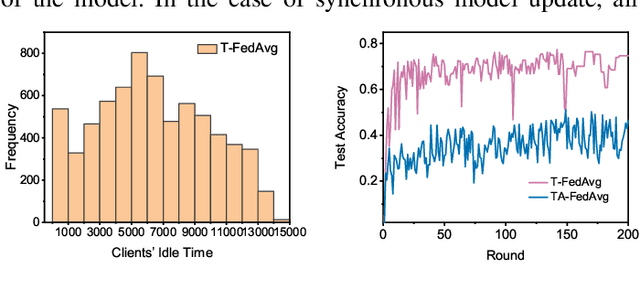
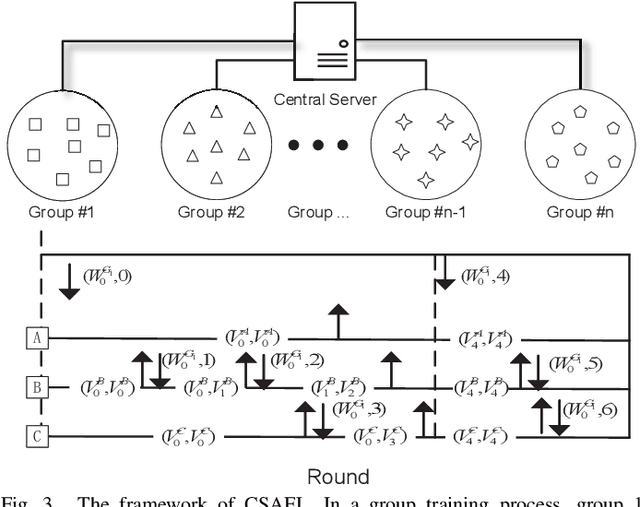
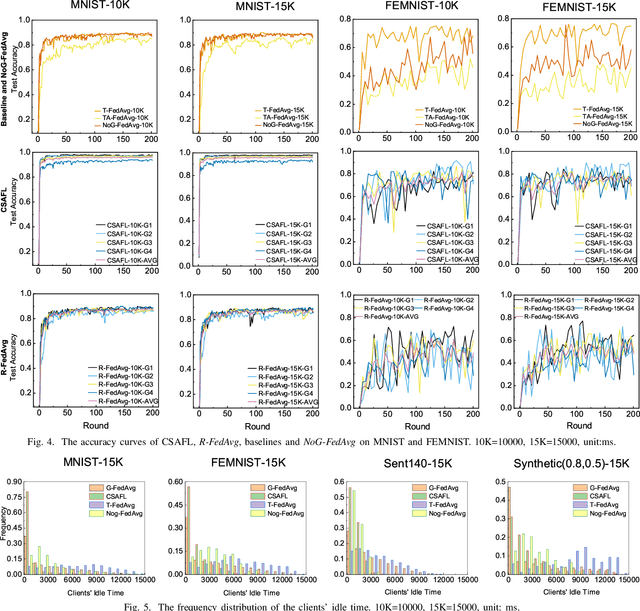
Federated learning (FL) is an emerging distributed machine learning paradigm that protects privacy and tackles the problem of isolated data islands. At present, there are two main communication strategies of FL: synchronous FL and asynchronous FL. The advantages of synchronous FL are that the model has high precision and fast convergence speed. However, this synchronous communication strategy has the risk that the central server waits too long for the devices, namely, the straggler effect which has a negative impact on some time-critical applications. Asynchronous FL has a natural advantage in mitigating the straggler effect, but there are threats of model quality degradation and server crash. Therefore, we combine the advantages of these two strategies to propose a clustered semi-asynchronous federated learning (CSAFL) framework. We evaluate CSAFL based on four imbalanced federated datasets in a non-IID setting and compare CSAFL to the baseline methods. The experimental results show that CSAFL significantly improves test accuracy by more than +5% on the four datasets compared to TA-FedAvg. In particular, CSAFL improves absolute test accuracy by +34.4% on non-IID FEMNIST compared to TA-FedAvg.
Learning Time Series Detection Models from Temporally Imprecise Labels
Apr 13, 2017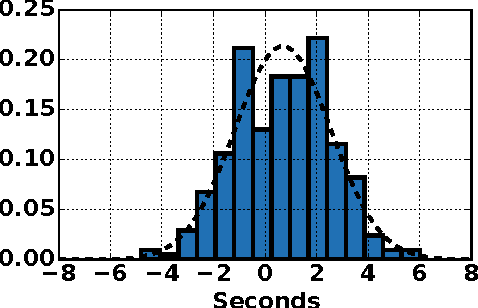
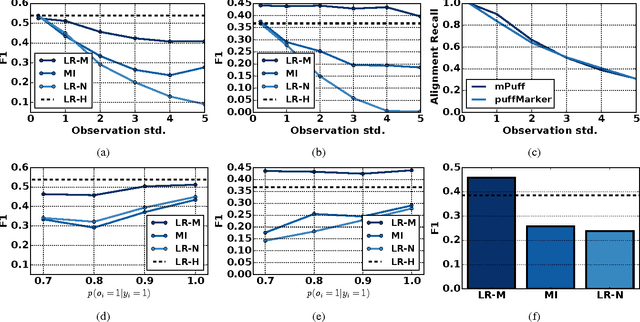
In this paper, we consider a new low-quality label learning problem: learning time series detection models from temporally imprecise labels. In this problem, the data consist of a set of input time series, and supervision is provided by a sequence of noisy time stamps corresponding to the occurrence of positive class events. Such temporally imprecise labels commonly occur in areas like mobile health research where human annotators are tasked with labeling the occurrence of very short duration events. We propose a general learning framework for this problem that can accommodate different base classifiers and noise models. We present results on real mobile health data showing that the proposed framework significantly outperforms a number of alternatives including assuming that the label time stamps are noise-free, transforming the problem into the multiple instance learning framework, and learning on labels that were manually re-aligned.
A machine learning approach to itinerary-level booking prediction in competitive airline markets
Mar 15, 2021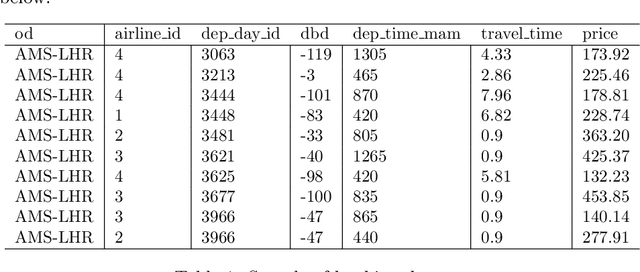
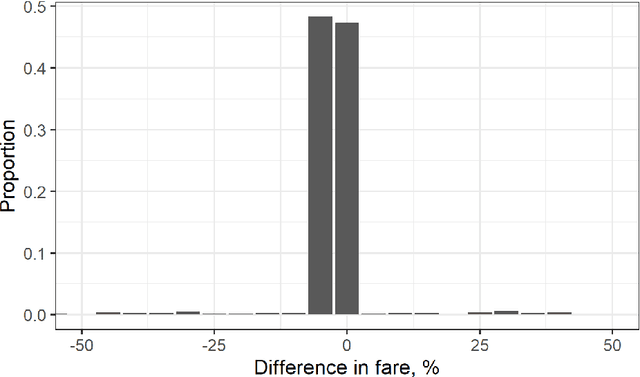
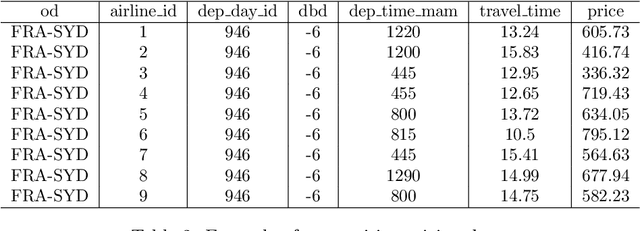
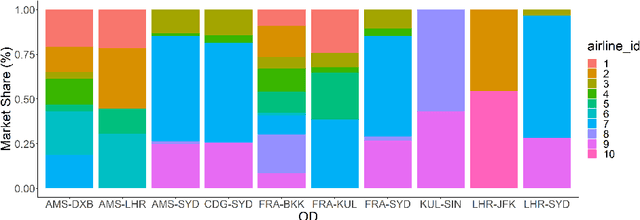
Demand forecasting is extremely important in revenue management. After all, it is one of the inputs to an optimisation method which aim is to maximize revenue. Most, if not all, forecasting methods use historical data to forecast the future, disregarding the "why". In this paper, we combine data from multiple sources, including competitor data, pricing, social media, safety and airline reviews. Next, we study five competitor pricing movements that, we hypothesize, affect customer behavior when presented a set of itineraries. Using real airline data for ten different OD-pairs and by means of Extreme Gradient Boosting, we show that customer behavior can be categorized into price-sensitive, schedule-sensitive and comfort ODs. Through a simulation study, we show that this model produces forecasts that result in higher revenue than traditional, time series forecasts.
One-Round Active Learning
Apr 23, 2021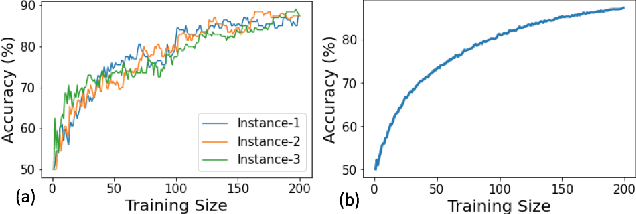

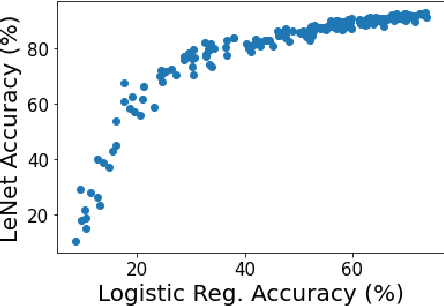
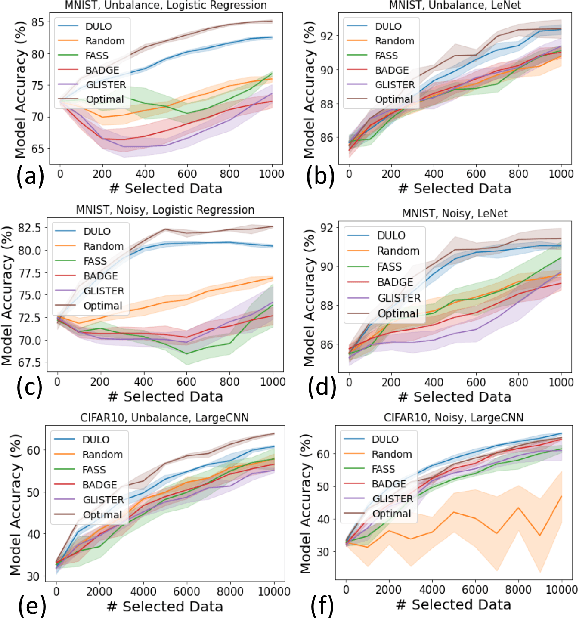
Active learning has been a main solution for reducing data labeling costs. However, existing active learning strategies assume that a data owner can interact with annotators in an online, timely manner, which is usually impractical. Even with such interactive annotators, for existing active learning strategies to be effective, they often require many rounds of interactions between the data owner and annotators, which is often time-consuming. In this work, we initiate the study of one-round active learning, which aims to select a subset of unlabeled data points that achieve the highest utility after being labeled with only the information from initially labeled data points. We propose DULO, a general framework for one-round active learning based on the notion of data utility functions, which map a set of data points to some performance measure of the model trained on the set. We formulate the one-round active learning problem as data utility function maximization. We further propose strategies to make the estimation and optimization of data utility functions scalable to large models and large unlabeled data sets. Our results demonstrate that while existing active learning approaches could succeed with multiple rounds, DULO consistently performs better in the one-round setting.
ConCAD: Contrastive Learning-based Cross Attention for Sleep Apnea Detection
May 07, 2021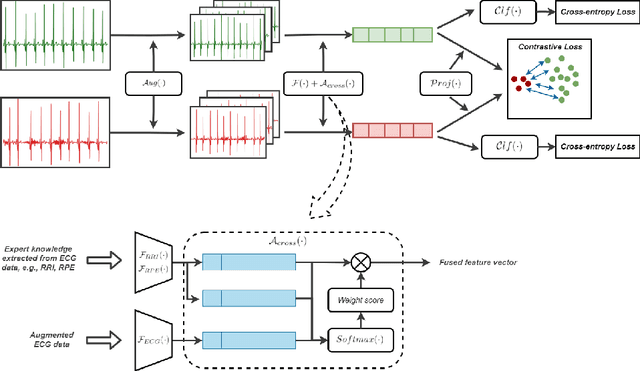
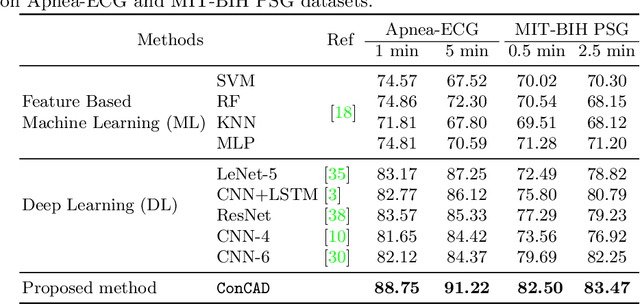
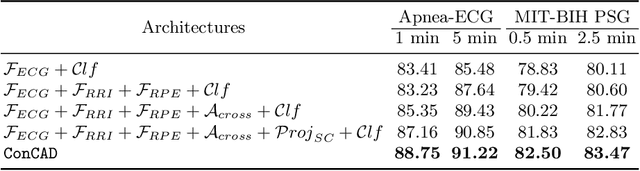
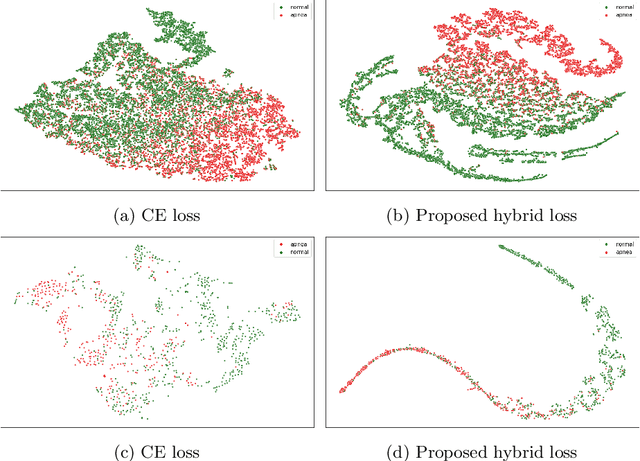
With recent advancements in deep learning methods, automatically learning deep features from the original data is becoming an effective and widespread approach. However, the hand-crafted expert knowledge-based features are still insightful. These expert-curated features can increase the model's generalization and remind the model of some data characteristics, such as the time interval between two patterns. It is particularly advantageous in tasks with the clinically-relevant data, where the data are usually limited and complex. To keep both implicit deep features and expert-curated explicit features together, an effective fusion strategy is becoming indispensable. In this work, we focus on a specific clinical application, i.e., sleep apnea detection. In this context, we propose a contrastive learning-based cross attention framework for sleep apnea detection (named ConCAD). The cross attention mechanism can fuse the deep and expert features by automatically assigning attention weights based on their importance. Contrastive learning can learn better representations by keeping the instances of each class closer and pushing away instances from different classes in the embedding space concurrently. Furthermore, a new hybrid loss is designed to simultaneously conduct contrastive learning and classification by integrating a supervised contrastive loss with a cross-entropy loss. Our proposed framework can be easily integrated into standard deep learning models to utilize expert knowledge and contrastive learning to boost performance. As demonstrated on two public ECG dataset with sleep apnea annotation, ConCAD significantly improves the detection performance and outperforms state-of-art benchmark methods.
Leveraging Machine Learning to Detect Data Curation Activities
Apr 30, 2021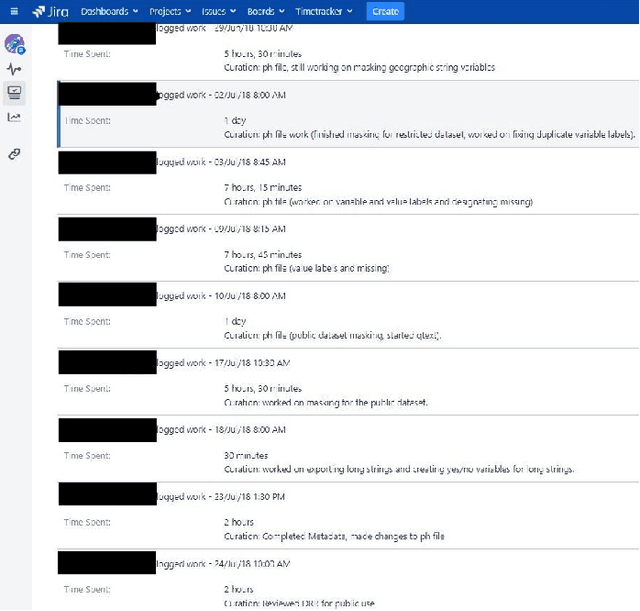
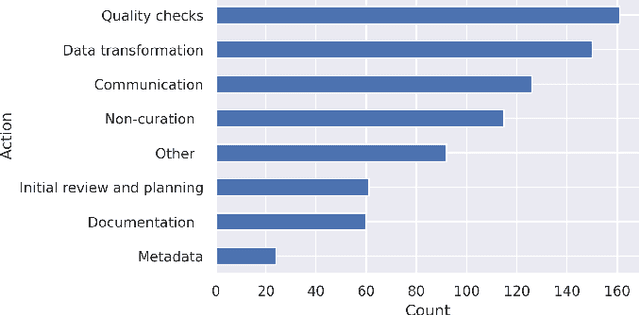
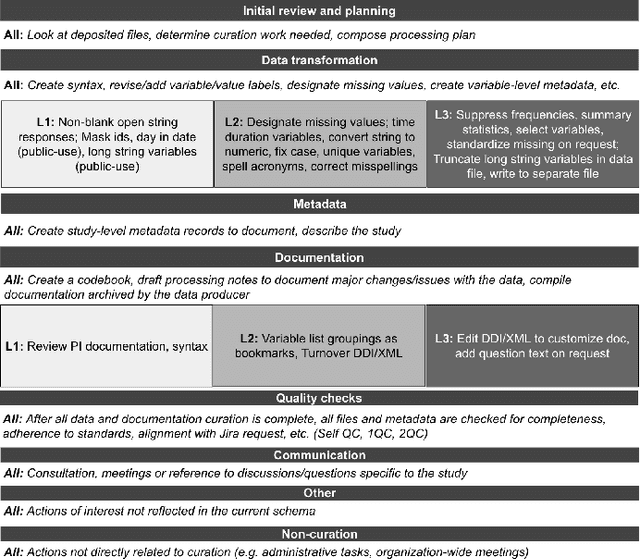
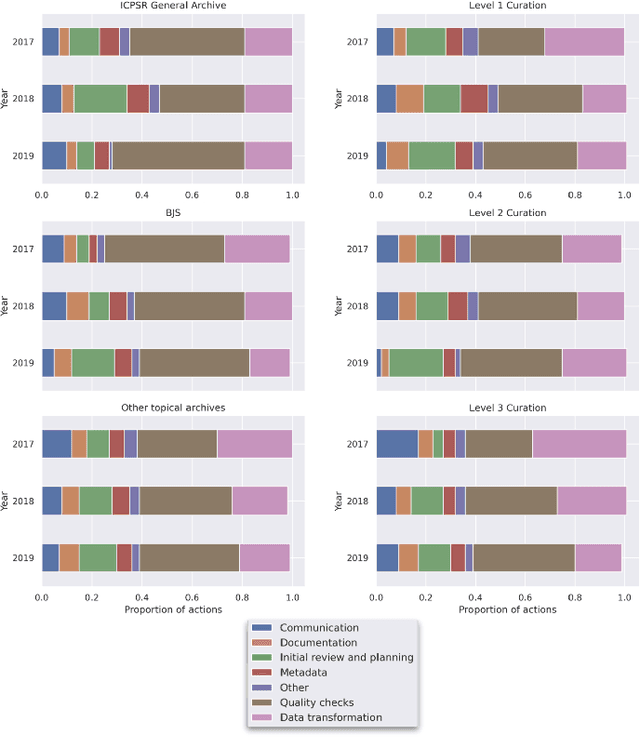
This paper describes a machine learning approach for annotating and analyzing data curation work logs at ICPSR, a large social sciences data archive. The systems we studied track curation work and coordinate team decision-making at ICPSR. Repository staff use these systems to organize, prioritize, and document curation work done on datasets, making them promising resources for studying curation work and its impact on data reuse, especially in combination with data usage analytics. A key challenge, however, is classifying similar activities so that they can be measured and associated with impact metrics. This paper contributes: 1) a schema of data curation activities; 2) a computational model for identifying curation actions in work log descriptions; and 3) an analysis of frequent data curation activities at ICPSR over time. We first propose a schema of data curation actions to help us analyze the impact of curation work. We then use this schema to annotate a set of data curation logs, which contain records of data transformations and project management decisions completed by repository staff. Finally, we train a text classifier to detect the frequency of curation actions in a large set of work logs. Our approach supports the analysis of curation work documented in work log systems as an important step toward studying the relationship between research data curation and data reuse.
PDO-e$\text{S}^\text{2}$CNNs: Partial Differential Operator Based Equivariant Spherical CNNs
Apr 08, 2021
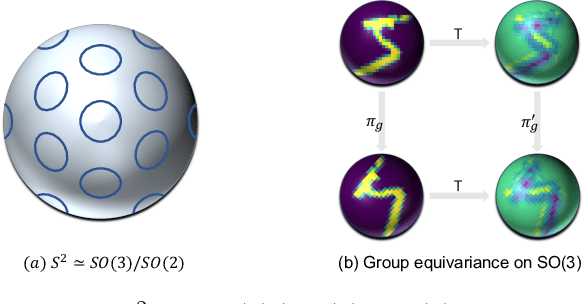
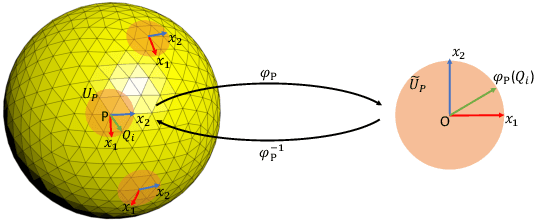
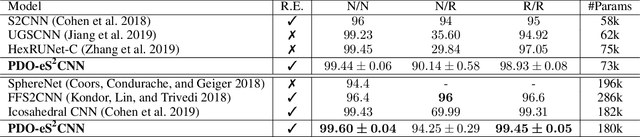
Spherical signals exist in many applications, e.g., planetary data, LiDAR scans and digitalization of 3D objects, calling for models that can process spherical data effectively. It does not perform well when simply projecting spherical data into the 2D plane and then using planar convolution neural networks (CNNs), because of the distortion from projection and ineffective translation equivariance. Actually, good principles of designing spherical CNNs are avoiding distortions and converting the shift equivariance property in planar CNNs to rotation equivariance in the spherical domain. In this work, we use partial differential operators (PDOs) to design a spherical equivariant CNN, PDO-e$\text{S}^\text{2}$CNN, which is exactly rotation equivariant in the continuous domain. We then discretize PDO-e$\text{S}^\text{2}$CNNs, and analyze the equivariance error resulted from discretization. This is the first time that the equivariance error is theoretically analyzed in the spherical domain. In experiments, PDO-e$\text{S}^\text{2}$CNNs show greater parameter efficiency and outperform other spherical CNNs significantly on several tasks.