 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Texture Based Classification of High Resolution Remotely Sensed Imagery using Weber Local Descriptor
Apr 18, 2021

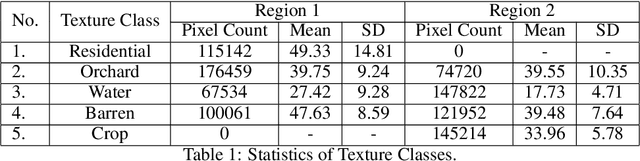
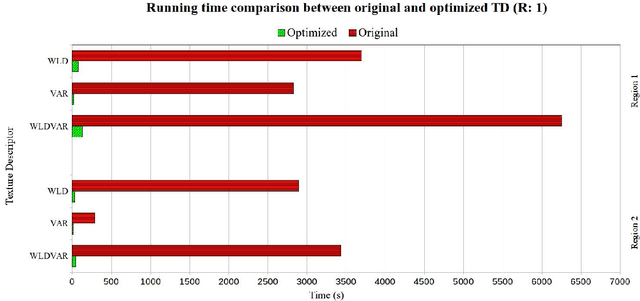
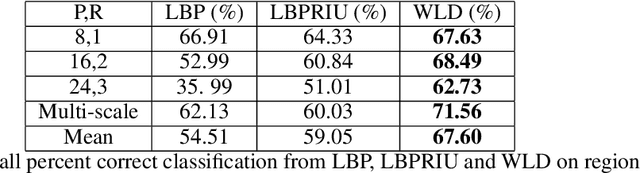
Traditional image classification techniques often produce unsatisfactory results when applied to high spatial resolution data because classes in high resolution images are not spectrally homogeneous. Texture offers an alternative source of information for classifying these images. This paper evaluates a recently developed, computationally simple texture metric called Weber Local Descriptor (WLD) for use in classifying high resolution QuickBird panchromatic data. We compared WLD with state-of-the art texture descriptors (TD) including Local Binary Pattern (LBP) and its rotation-invariant version LBPRIU. We also investigated whether incorporating VAR, a TD that captures brightness variation, would improve the accuracy of LBPRIU and WLD. We found that WLD generally produces more accurate classification results than the other TD we examined, and is also more robust to varying parameters. We have implemented an optimised algorithm for calculating WLD which makes the technique practical in terms of computation time. Overall, our results indicate that WLD is a promising approach for classifying high resolution remote sensing data.
Reinforced Attention for Few-Shot Learning and Beyond
Apr 09, 2021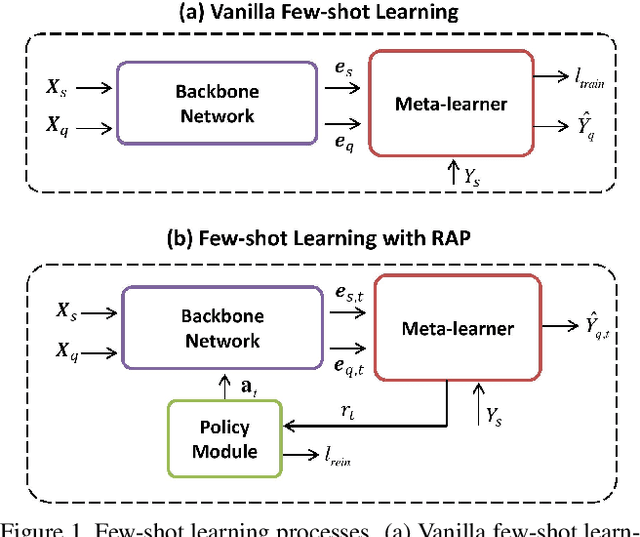
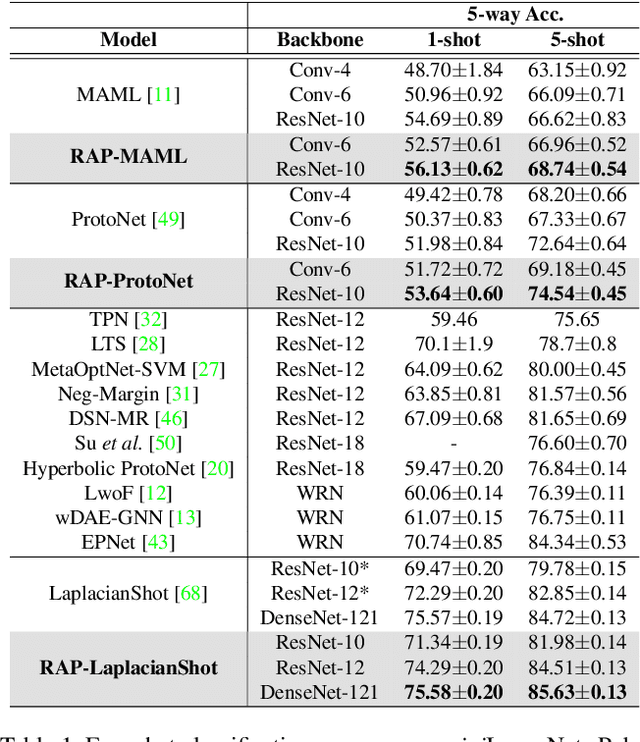
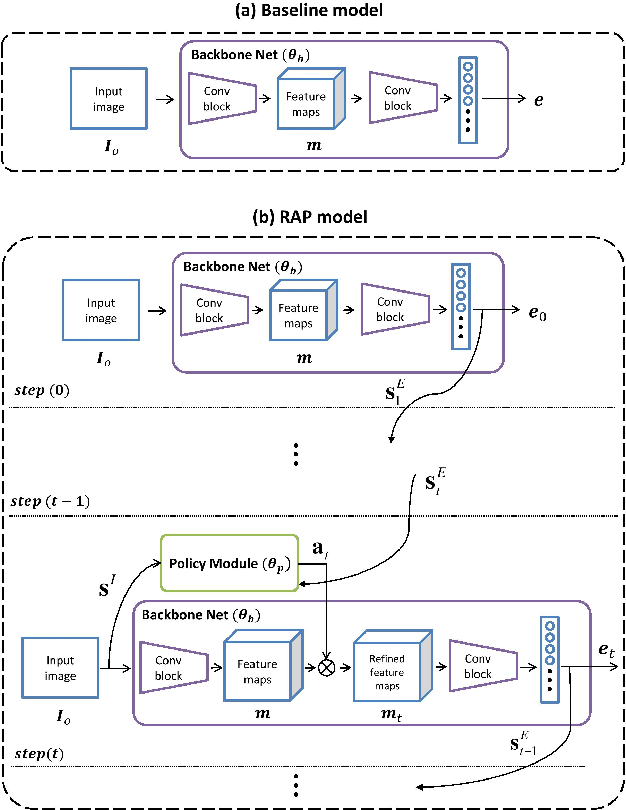
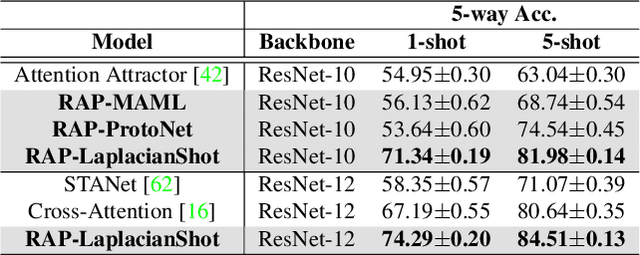
Few-shot learning aims to correctly recognize query samples from unseen classes given a limited number of support samples, often by relying on global embeddings of images. In this paper, we propose to equip the backbone network with an attention agent, which is trained by reinforcement learning. The policy gradient algorithm is employed to train the agent towards adaptively localizing the representative regions on feature maps over time. We further design a reward function based on the prediction of the held-out data, thus helping the attention mechanism to generalize better across the unseen classes. The extensive experiments show, with the help of the reinforced attention, that our embedding network has the capability to progressively generate a more discriminative representation in few-shot learning. Moreover, experiments on the task of image classification also show the effectiveness of the proposed design.
Dynamic Prioritization for Conflict-Free Path Planning of Multi-Robot Systems
Jan 06, 2021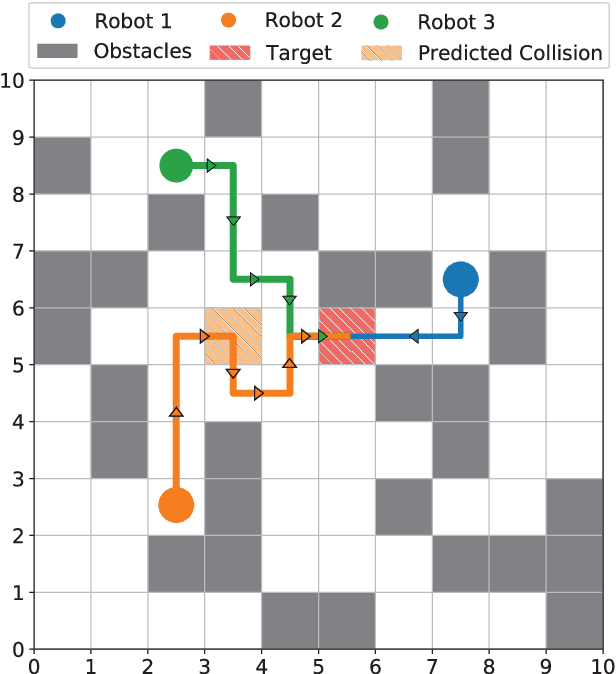
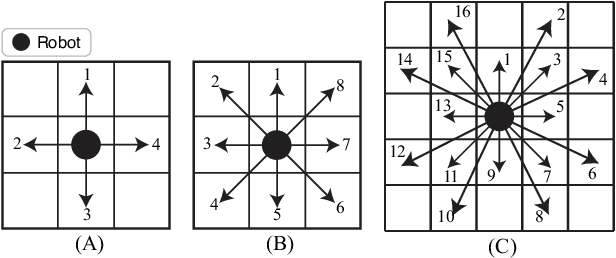
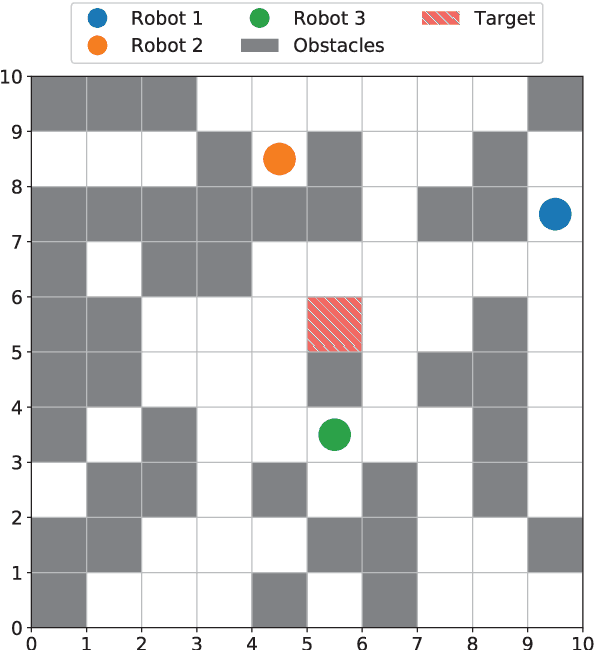
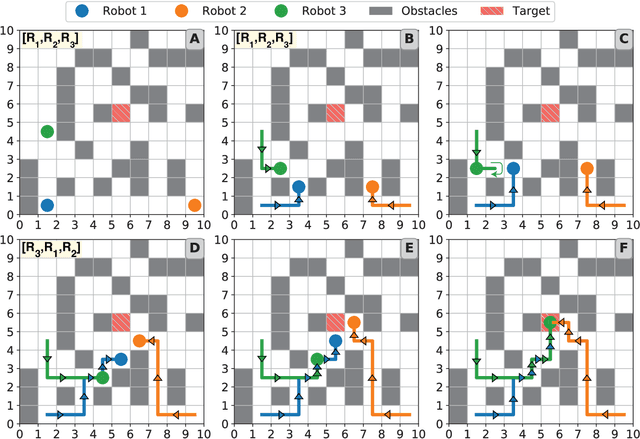
Planning collision-free paths for multi-robot systems (MRS) is a challenging problem because of the safety and efficiency constraints required for real-world solutions. Even though coupled path planning approaches provide optimal collision-free paths for each agent of the MRS, they search the composite space of all the agents and therefore, suffer from exponential increase in computation with the number of robots. On the other hand, prioritized approaches provide a practical solution to applications with large number of robots, especially when path computation time and collision avoidance take precedence over guaranteed globally optimal solution. While most centrally-planned algorithms use static prioritization, a dynamic prioritization algorithm, PD*, is proposed that employs a novel metric, called freedom index, to decide the priority order of the robots at each time step. This allows the PD* algorithm to simultaneously plan the next step for all robots while ensuring collision-free operation in obstacle ridden environments. Extensive simulations were performed to test and compare the performance of the proposed PD* scheme with other state-of-the-art algorithms. It was found that PD* improves upon the computational time by 25% while providing solutions of similar path lengths. Increase in efficiency was particularly prominent in scenarios with large number of robots and/or higher obstacle densities, where the probability of collisions is higher, suggesting the suitability of PD* in solving such problems.
A Novel Uncertainty-aware Collaborative Learning Method for Remote Sensing Image Classification Under Multi-Label Noise
May 12, 2021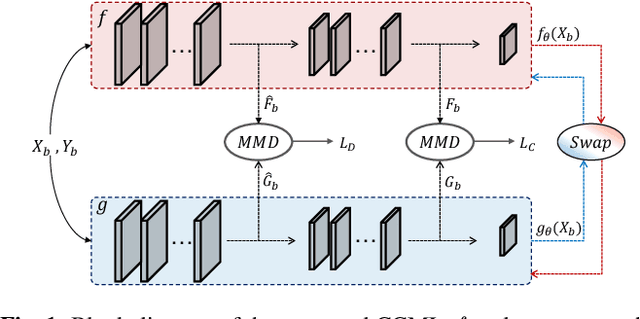
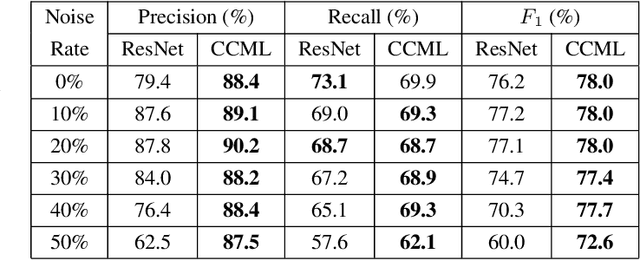
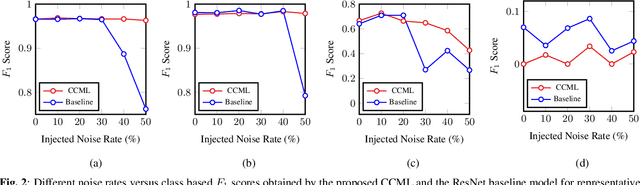
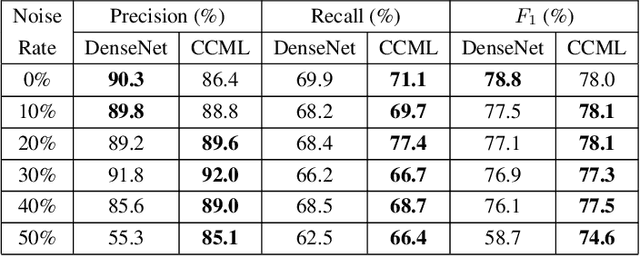
In remote sensing (RS), collecting a large number of reliable training images annotated by multiple land-cover class labels for multi-label classification (MLC) is time-consuming and costly. To address this problem, the publicly available thematic products are often used for annotating RS images with zero-labeling cost. However, in this case the training set can include noisy multi-labels that distort the learning process, resulting in inaccurate predictions. This paper proposes an architect-independent Consensual Collaborative Multi-Label Learning (CCML) method to train deep classifiers under input-dependent (heteroscedastic) multi-label noise in the MLC problems. The proposed CCML identifies, ranks, and corrects noisy multi-label images through four main modules: 1) group lasso module; 2) discrepancy module; 3) flipping module; and 4) swap module. The group lasso module detects the potentially noisy labels by estimating the label uncertainty based on the aggregation of two collaborative networks. The discrepancy module ensures that the two networks learn diverse features, while obtaining the same predictions. The flipping module corrects the identified noisy labels, and the swap module exchanges the ranking information between the two networks. The experiments conducted on the multi-label RS image archive IR-BigEarthNet confirm the robustness of the proposed CCML under extreme multi-label noise rates.
Interpretable performance analysis towards offline reinforcement learning: A dataset perspective
May 12, 2021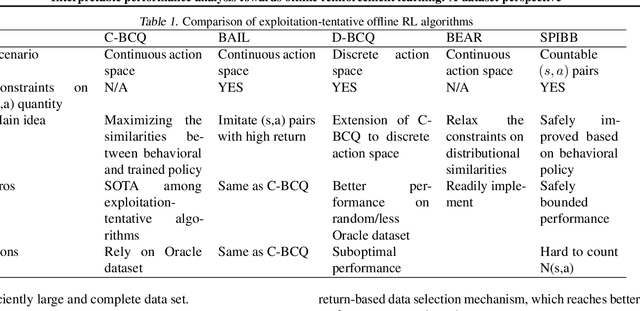
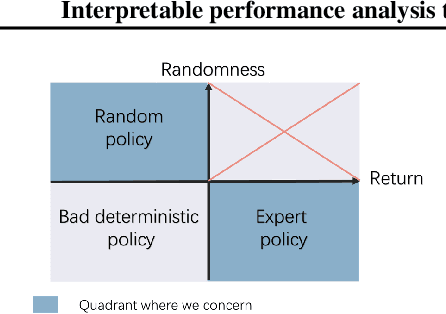

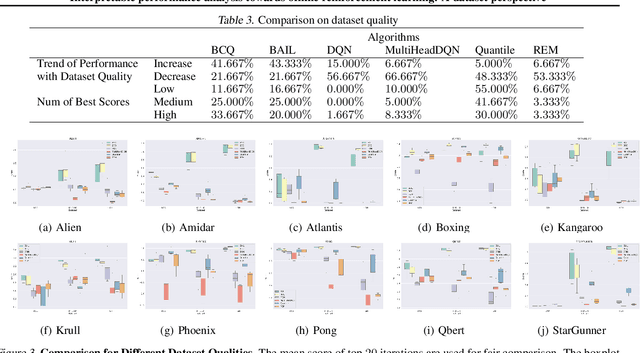
Offline reinforcement learning (RL) has increasingly become the focus of the artificial intelligent research due to its wide real-world applications where the collection of data may be difficult, time-consuming, or costly. In this paper, we first propose a two-fold taxonomy for existing offline RL algorithms from the perspective of exploration and exploitation tendency. Secondly, we derive the explicit expression of the upper bound of extrapolation error and explore the correlation between the performance of different types of algorithms and the distribution of actions under states. Specifically, we relax the strict assumption on the sufficiently large amount of state-action tuples. Accordingly, we provably explain why batch constrained Q-learning (BCQ) performs better than other existing techniques. Thirdly, after identifying the weakness of BCQ on dataset of low mean episode returns, we propose a modified variant based on top return selection mechanism, which is proved to be able to gain state-of-the-art performance on various datasets. Lastly, we create a benchmark platform on the Atari domain, entitled RL easy go (RLEG), at an estimated cost of more than 0.3 million dollars. We make it open-source for fair and comprehensive competitions between offline RL algorithms with complete datasets and checkpoints being provided.
Boosted Genetic Algorithm using Machine Learning for traffic control optimization
Mar 11, 2021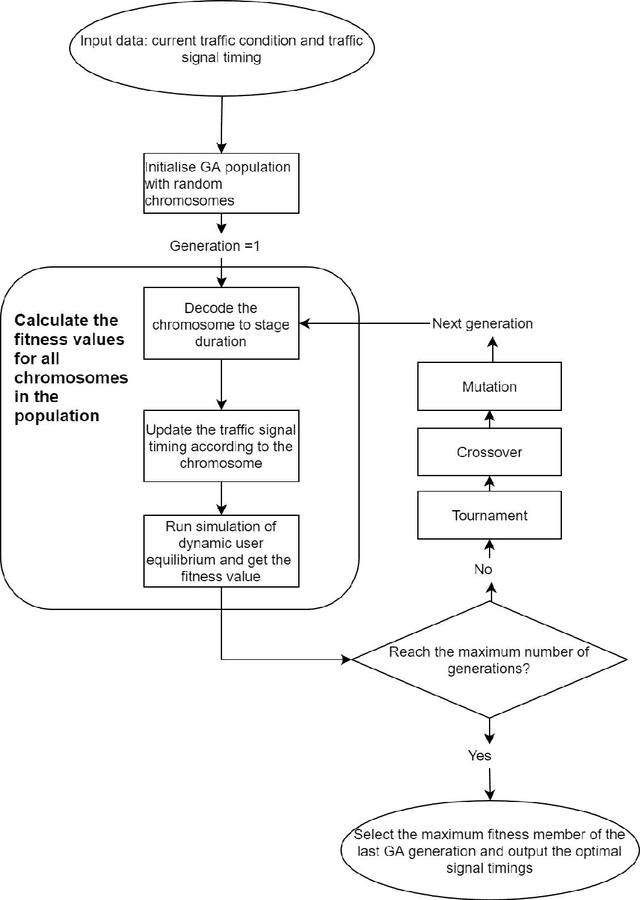
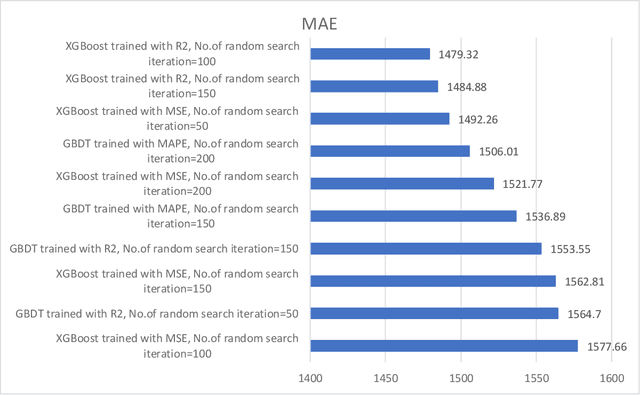
Traffic control optimization is a challenging task for various traffic centers around the world and the majority of existing approaches focus only on developing adaptive methods under normal (recurrent) traffic conditions. Optimizing the control plans when severe incidents occur still remains an open problem, especially when a high number of lanes or entire intersections are affected. This paper aims at tackling this problem and presents a novel methodology for optimizing the traffic signal timings in signalized urban intersections, under non-recurrent traffic incidents. With the purpose of producing fast and reliable decisions, we combine the fast running Machine Learning (ML) algorithms and the reliable Genetic Algorithms (GA) into a single optimization framework. As a benchmark, we first start with deploying a typical GA algorithm by considering the phase duration as the decision variable and the objective function to minimize the total travel time in the network. We fine tune the GA for crossover, mutation, fitness calculation and obtain the optimal parameters. Secondly, we train various machine learning regression models to predict the total travel time of the studied traffic network, and select the best performing regressor which we further hyper-tune to find the optimal training parameters. Lastly, we propose a new algorithm BGA-ML combining the GA algorithm and the extreme-gradient decision-tree, which is the best performing regressor, together in a single optimization framework. Comparison and results show that the new BGA-ML is much faster than the original GA algorithm and can be successfully applied under non-recurrent incident conditions.
One-time learning in a biologically-inspired Salience-affected Artificial Neural Network (SANN)
Aug 23, 2019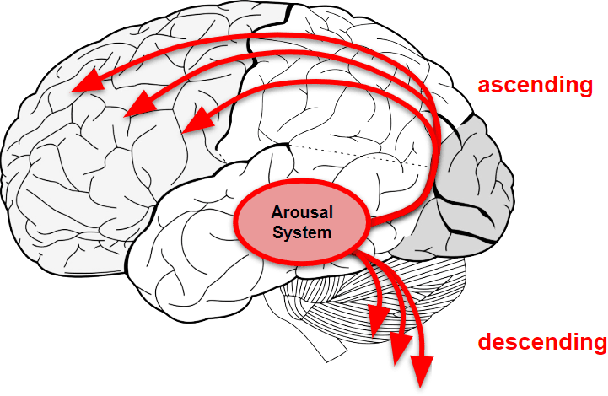
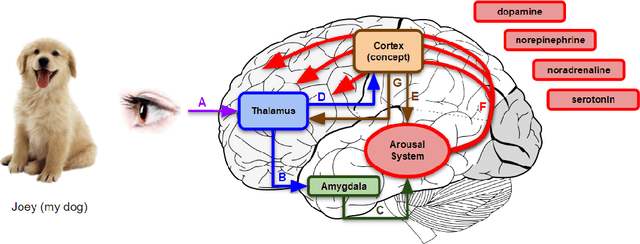
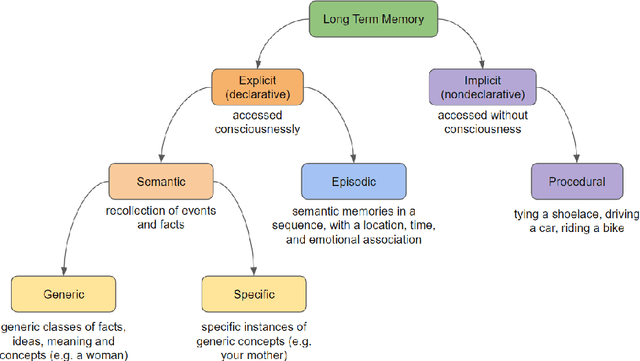
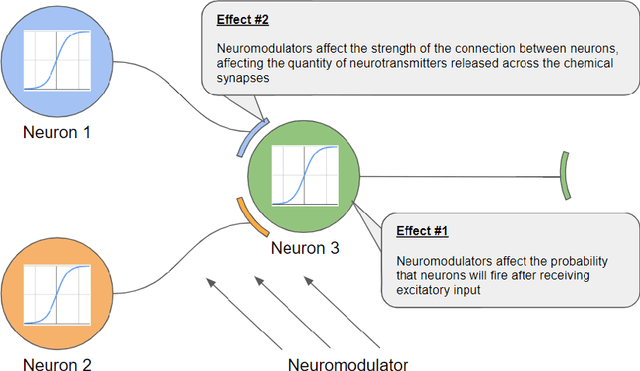
Standard artificial neural networks (ANNs), loosely based on the structure of columns in the cortex, model key cognitive aspects of brain function such as learning and classification, but do not model the affective (emotional) aspects of brain function. However these are a key feature of the brain (the associated `ascending systems' have been hard-wired into the brain by evolutionary processes). These emotions are associated with memories when neuromodulators such as dopamine and noradrenaline affect entire patterns of synaptically activated neurons. Here we present a bio-inspired ANN architecture which we call a Salience-Affected Neural Network (SANN), which, at the same time as local network processing of task-specific information, includes non-local salience (significance) effects responding to an input salience signal. During pattern recognition, inputs similar to the salience-affected inputs in the training data will produce reverse salience signals corresponding to those experienced when the memories were laid down. In addition, training with salience affects the weights of connections between nodes, and improves the overall accuracy of a classification of images similar to the salience-tagged input after just a single iteration of training. Note that we are not aiming to present an accurate model of the biological salience system; rather we present an artificial neural network inspired by those biological systems in the human brain, that has unique strengths.
Structured Black Box Variational Inference for Latent Time Series Models
Jul 04, 2017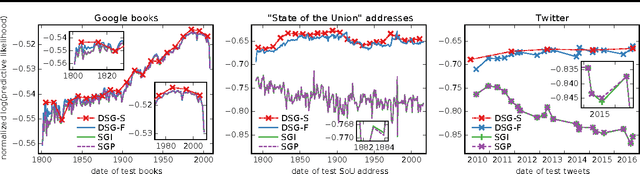
Continuous latent time series models are prevalent in Bayesian modeling; examples include the Kalman filter, dynamic collaborative filtering, or dynamic topic models. These models often benefit from structured, non mean field variational approximations that capture correlations between time steps. Black box variational inference with reparameterization gradients (BBVI) allows us to explore a rich new class of Bayesian non-conjugate latent time series models; however, a naive application of BBVI to such structured variational models would scale quadratically in the number of time steps. We describe a BBVI algorithm analogous to the forward-backward algorithm which instead scales linearly in time. It allows us to efficiently sample from the variational distribution and estimate the gradients of the ELBO. Finally, we show results on the recently proposed dynamic word embedding model, which was trained using our method.
Sparsification via Compressed Sensing for Automatic Speech Recognition
Feb 09, 2021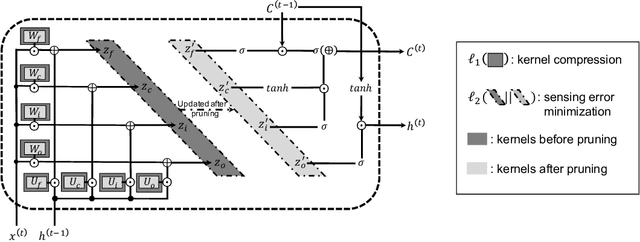
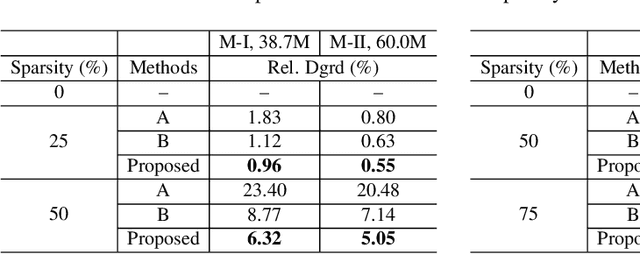
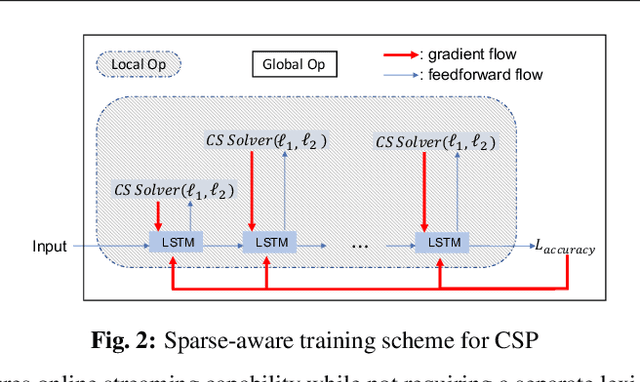
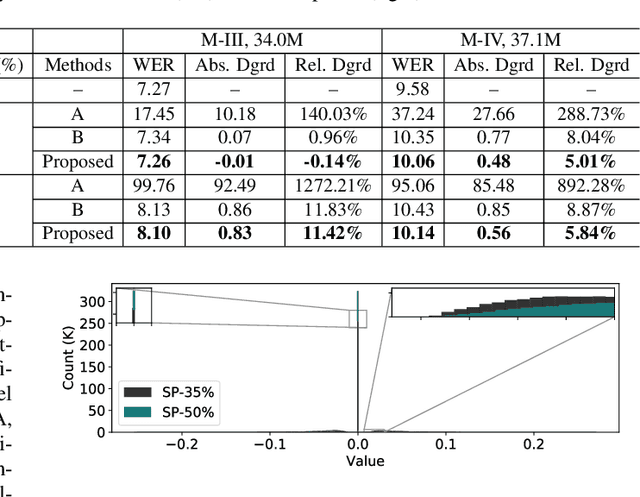
In order to achieve high accuracy for machine learning (ML) applications, it is essential to employ models with a large number of parameters. Certain applications, such as Automatic Speech Recognition (ASR), however, require real-time interactions with users, hence compelling the model to have as low latency as possible. Deploying large scale ML applications thus necessitates model quantization and compression, especially when running ML models on resource constrained devices. For example, by forcing some of the model weight values into zero, it is possible to apply zero-weight compression, which reduces both the model size and model reading time from the memory. In the literature, such methods are referred to as sparse pruning. The fundamental questions are when and which weights should be forced to zero, i.e. be pruned. In this work, we propose a compressed sensing based pruning (CSP) approach to effectively address those questions. By reformulating sparse pruning as a sparsity inducing and compression-error reduction dual problem, we introduce the classic compressed sensing process into the ML model training process. Using ASR task as an example, we show that CSP consistently outperforms existing approaches in the literature.
Revisiting Batch Normalization for Training Low-latency Deep Spiking Neural Networks from Scratch
Oct 27, 2020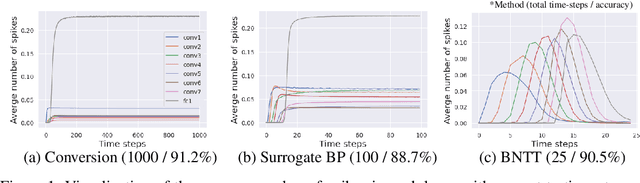
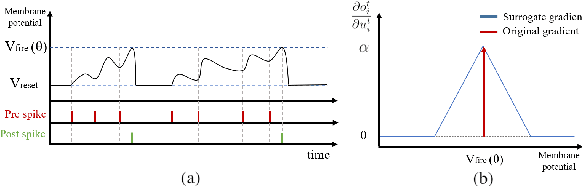
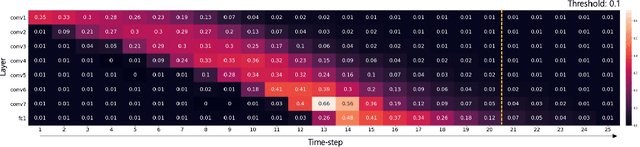

Spiking Neural Networks (SNNs) have recently emerged as an alternative to deep learning owing to sparse, asynchronous and binary event (or spike) driven processing, that can yield huge energy efficiency benefits on neuromorphic hardware. Most existing approaches to create SNNs either convert the weights from pre-trained Artificial Neural Networks (ANNs) or directly train SNNs with surrogate gradient backpropagation. Each approach presents its pros and cons. The ANN-to-SNN conversion method requires at least hundreds of time-steps for inference to yield competitive accuracy that in turn reduces the energy savings. Training SNNs with surrogate gradients from scratch reduces the latency or total number of time-steps, but the training becomes slow/problematic and has convergence issues. Thus, the latter approach of training SNNs has been limited to shallow networks on simple datasets. To address this training issue in SNNs, we revisit batch normalization and propose a temporal Batch Normalization Through Time (BNTT) technique. Most prior SNN works till now have disregarded batch normalization deeming it ineffective for training temporal SNNs. Different from previous works, our proposed BNTT decouples the parameters in a BNTT layer along the time axis to capture the temporal dynamics of spikes. The temporally evolving learnable parameters in BNTT allow a neuron to control its spike rate through different time-steps, enabling low-latency and low-energy training from scratch. We conduct experiments on CIFAR-10, CIFAR-100, Tiny-ImageNet and event-driven DVS-CIFAR10 datasets. BNTT allows us to train deep SNN architectures from scratch, for the first time, on complex datasets with just few 25-30 time-steps. We also propose an early exit algorithm using the distribution of parameters in BNTT to reduce the latency at inference, that further improves the energy-efficiency.