 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Batch Normalization for Training Low-latency Deep Spiking Neural Networks from Scratch
Paper and Code
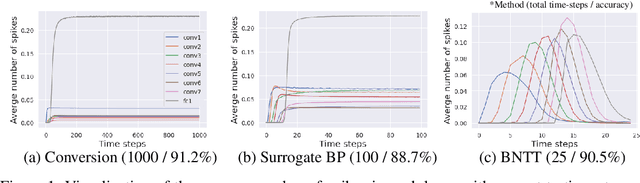
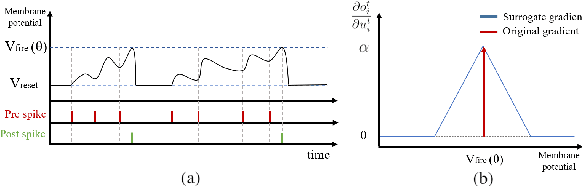
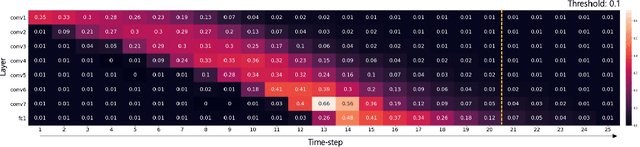

Spiking Neural Networks (SNNs) have recently emerged as an alternative to deep learning owing to sparse, asynchronous and binary event (or spike) driven processing, that can yield huge energy efficiency benefits on neuromorphic hardware. Most existing approaches to create SNNs either convert the weights from pre-trained Artificial Neural Networks (ANNs) or directly train SNNs with surrogate gradient backpropagation. Each approach presents its pros and cons. The ANN-to-SNN conversion method requires at least hundreds of time-steps for inference to yield competitive accuracy that in turn reduces the energy savings. Training SNNs with surrogate gradients from scratch reduces the latency or total number of time-steps, but the training becomes slow/problematic and has convergence issues. Thus, the latter approach of training SNNs has been limited to shallow networks on simple datasets. To address this training issue in SNNs, we revisit batch normalization and propose a temporal Batch Normalization Through Time (BNTT) technique. Most prior SNN works till now have disregarded batch normalization deeming it ineffective for training temporal SNNs. Different from previous works, our proposed BNTT decouples the parameters in a BNTT layer along the time axis to capture the temporal dynamics of spikes. The temporally evolving learnable parameters in BNTT allow a neuron to control its spike rate through different time-steps, enabling low-latency and low-energy training from scratch. We conduct experiments on CIFAR-10, CIFAR-100, Tiny-ImageNet and event-driven DVS-CIFAR10 datasets. BNTT allows us to train deep SNN architectures from scratch, for the first time, on complex datasets with just few 25-30 time-steps. We also propose an early exit algorithm using the distribution of parameters in BNTT to reduce the latency at inference, that further improves the energy-efficiency.