 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Yes We Care! -- Certification for Machine Learning Methods through the Care Label Framework
May 21, 2021
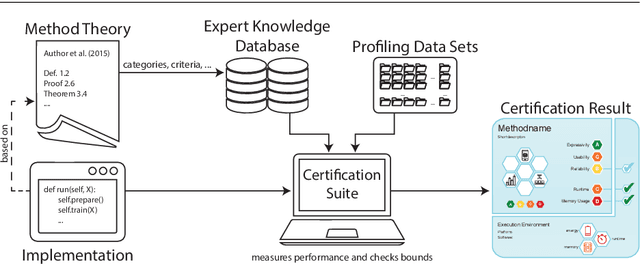
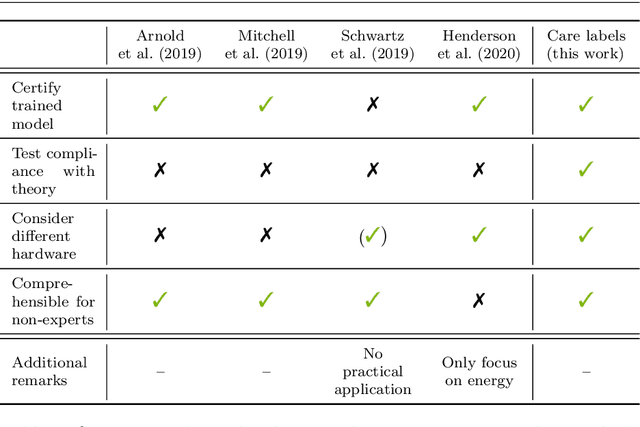
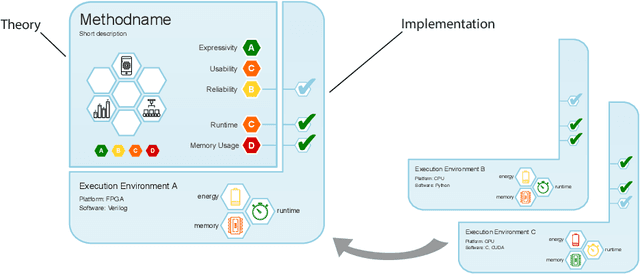
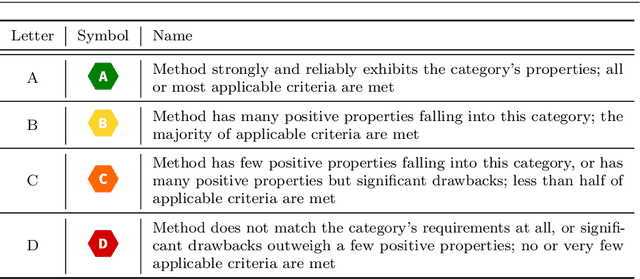
Machine learning applications have become ubiquitous. Their applications from machine embedded control in production over process optimization in diverse areas (e.g., traffic, finance, sciences) to direct user interactions like advertising and recommendations. This has led to an increased effort of making machine learning trustworthy. Explainable and fair AI have already matured. They address knowledgeable users and application engineers. However, there are users that want to deploy a learned model in a similar way as their washing machine. These stakeholders do not want to spend time understanding the model. Instead, they want to rely on guaranteed properties. What are the relevant properties? How can they be expressed to stakeholders without presupposing machine learning knowledge? How can they be guaranteed for a certain implementation of a model? These questions move far beyond the current state-of-the-art and we want to address them here. We propose a unified framework that certifies learning methods via care labels. They are easy to understand and draw inspiration from well-known certificates like textile labels or property cards of electronic devices. Our framework considers both, the machine learning theory and a given implementation. We test the implementation's compliance with theoretical properties and bounds. In this paper, we illustrate care labels by a prototype implementation of a certification suite for a selection of probabilistic graphical models.
Enhancing Safety of Students with Mobile Air Filtration during School Reopening from COVID-19
Apr 29, 2021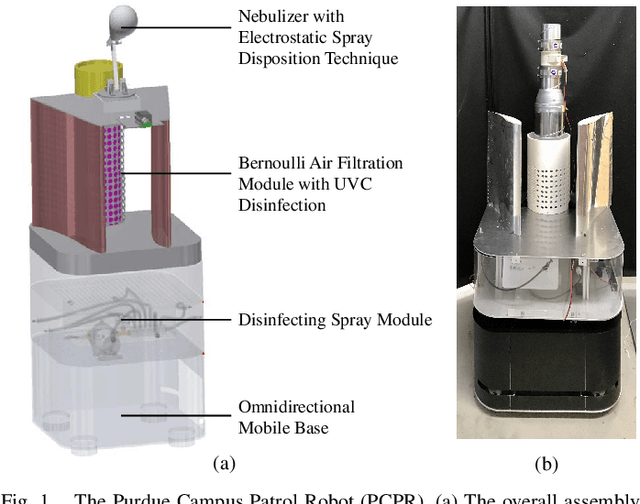
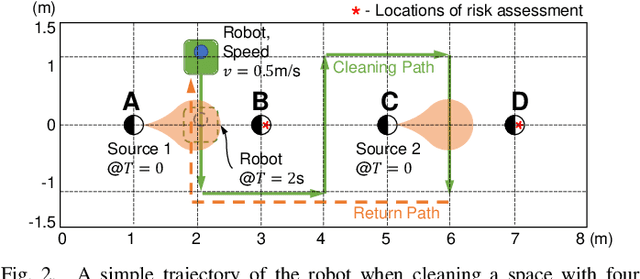
The paper discusses how robots enable occupant-safe continuous protection for students when schools reopen. Conventionally, fixed air filters are not used as a key pandemic prevention method for public indoor spaces because they are unable to trap the airborne pathogens in time in the entire room. However, by combining the mobility of a robot with air filtration, the efficacy of cleaning up the air around multiple people is largely increased. A disinfection co-robot prototype is thus developed to provide continuous and occupant-friendly protection to people gathering indoors, specifically for students in a classroom scenario. In a static classroom with students sitting in a grid pattern, the mobile robot is able to serve up to 14 students per cycle while reducing the worst-case pathogen dosage by 20%, and with higher robustness compared to a static filter. The extent of robot protection is optimized by tuning the passing distance and speed, such that a robot is able to serve more people given a threshold of worst-case dosage a person can receive.
PPFL: Privacy-preserving Federated Learning with Trusted Execution Environments
Apr 29, 2021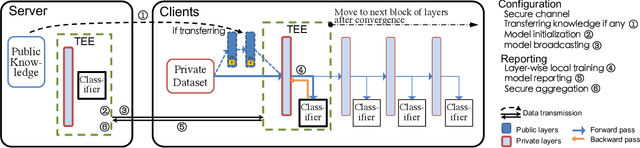

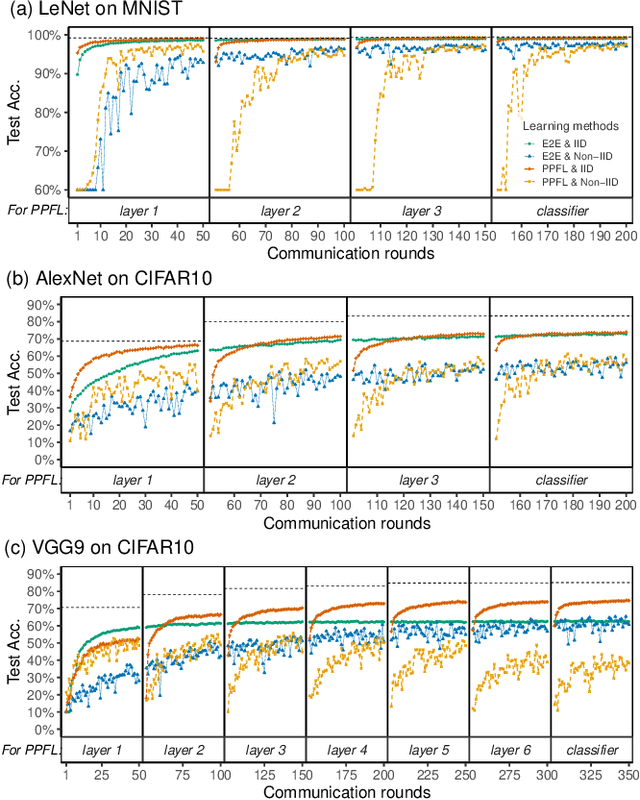
We propose and implement a Privacy-preserving Federated Learning (PPFL) framework for mobile systems to limit privacy leakages in federated learning. Leveraging the widespread presence of Trusted Execution Environments (TEEs) in high-end and mobile devices, we utilize TEEs on clients for local training, and on servers for secure aggregation, so that model/gradient updates are hidden from adversaries. Challenged by the limited memory size of current TEEs, we leverage greedy layer-wise training to train each model's layer inside the trusted area until its convergence. The performance evaluation of our implementation shows that PPFL can significantly improve privacy while incurring small system overheads at the client-side. In particular, PPFL can successfully defend the trained model against data reconstruction, property inference, and membership inference attacks. Furthermore, it can achieve comparable model utility with fewer communication rounds (0.54x) and a similar amount of network traffic (1.002x) compared to the standard federated learning of a complete model. This is achieved while only introducing up to ~15% CPU time, ~18% memory usage, and ~21% energy consumption overhead in PPFL's client-side.
The Generalized Mean Densest Subgraph Problem
Jun 02, 2021



Finding dense subgraphs of a large graph is a standard problem in graph mining that has been studied extensively both for its theoretical richness and its many practical applications. In this paper we introduce a new family of dense subgraph objectives, parameterized by a single parameter $p$, based on computing generalized means of degree sequences of a subgraph. Our objective captures both the standard densest subgraph problem and the maximum $k$-core as special cases, and provides a way to interpolate between and extrapolate beyond these two objectives when searching for other notions of dense subgraphs. In terms of algorithmic contributions, we first show that our objective can be minimized in polynomial time for all $p \geq 1$ using repeated submodular minimization. A major contribution of our work is analyzing the performance of different types of peeling algorithms for dense subgraphs both in theory and practice. We prove that the standard peeling algorithm can perform arbitrarily poorly on our generalized objective, but we then design a more sophisticated peeling method which for $p \geq 1$ has an approximation guarantee that is always at least $1/2$ and converges to 1 as $p \rightarrow \infty$. In practice, we show that this algorithm obtains extremely good approximations to the optimal solution, scales to large graphs, and highlights a range of different meaningful notions of density on graphs coming from numerous domains. Furthermore, it is typically able to approximate the densest subgraph problem better than the standard peeling algorithm, by better accounting for how the removal of one node affects other nodes in its neighborhood.
Stochastic Gradient Descent in Continuous Time: A Central Limit Theorem
Nov 02, 2017Stochastic gradient descent in continuous time (SGDCT) provides a computationally efficient method for the statistical learning of continuous-time models, which are widely used in science, engineering, and finance. The SGDCT algorithm follows a (noisy) descent direction along a continuous stream of data. The parameter updates occur in continuous time and satisfy a stochastic differential equation. This paper analyzes the asymptotic convergence rate of the SGDCT algorithm by proving a central limit theorem for strongly convex objective functions and, under slightly stronger conditions, for non-convex objective functions as well. An L$^p$ convergence rate is also proven for the algorithm in the strongly convex case.
Hierarchical Graph Neural Networks
May 14, 2021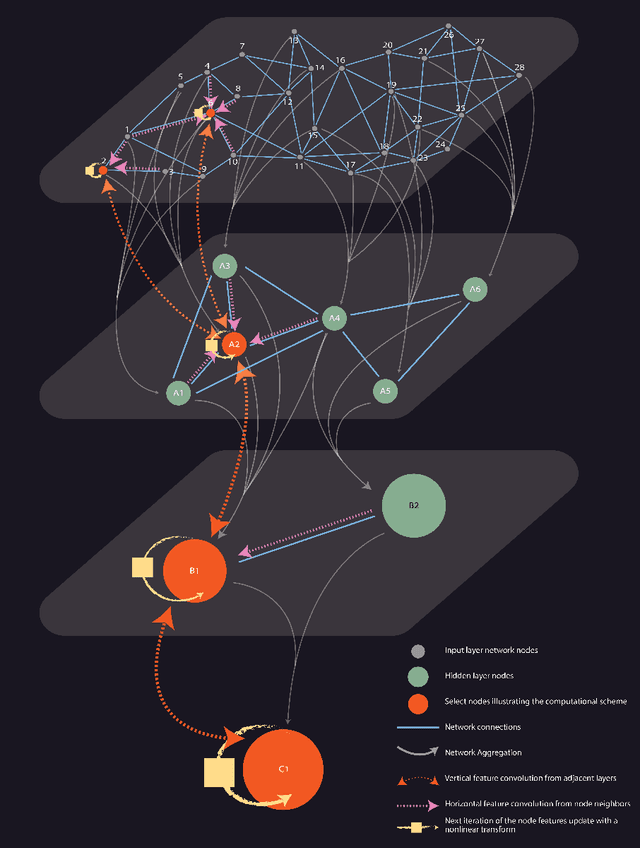
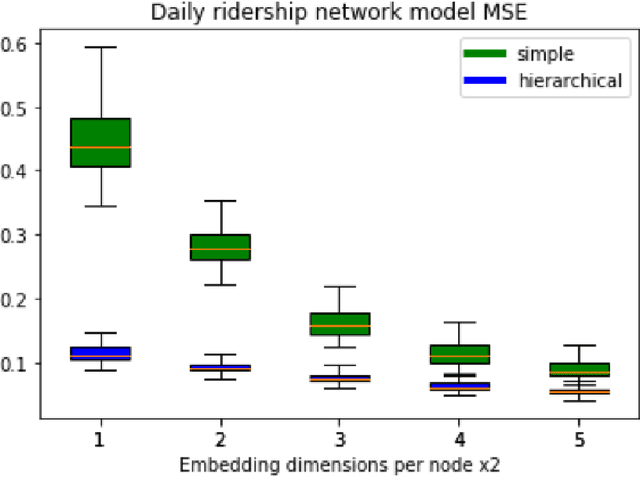
Over the recent years, Graph Neural Networks have become increasingly popular in network analytic and beyond. With that, their architecture noticeable diverges from the classical multi-layered hierarchical organization of the traditional neural networks. At the same time, many conventional approaches in network science efficiently utilize the hierarchical approaches to account for the hierarchical organization of the networks, and recent works emphasize their critical importance. This paper aims to connect the dots between the traditional Neural Network and the Graph Neural Network architectures as well as the network science approaches, harnessing the power of the hierarchical network organization. A Hierarchical Graph Neural Network architecture is proposed, supplementing the original input network layer with the hierarchy of auxiliary network layers and organizing the computational scheme updating the node features through both - horizontal network connections within each layer as well as the vertical connection between the layers. It enables simultaneous learning of the individual node features along with the aggregated network features at variable resolution and uses them to improve the convergence and stability of the individual node feature learning. The proposed Hierarchical Graph Neural network architecture is successfully evaluated on the network embedding and modeling as well as network classification, node labeling, and community tasks and demonstrates increased efficiency in those.
Generalised Structural CNNs (SCNNs) for time series data with arbitrary graph topology
May 30, 2018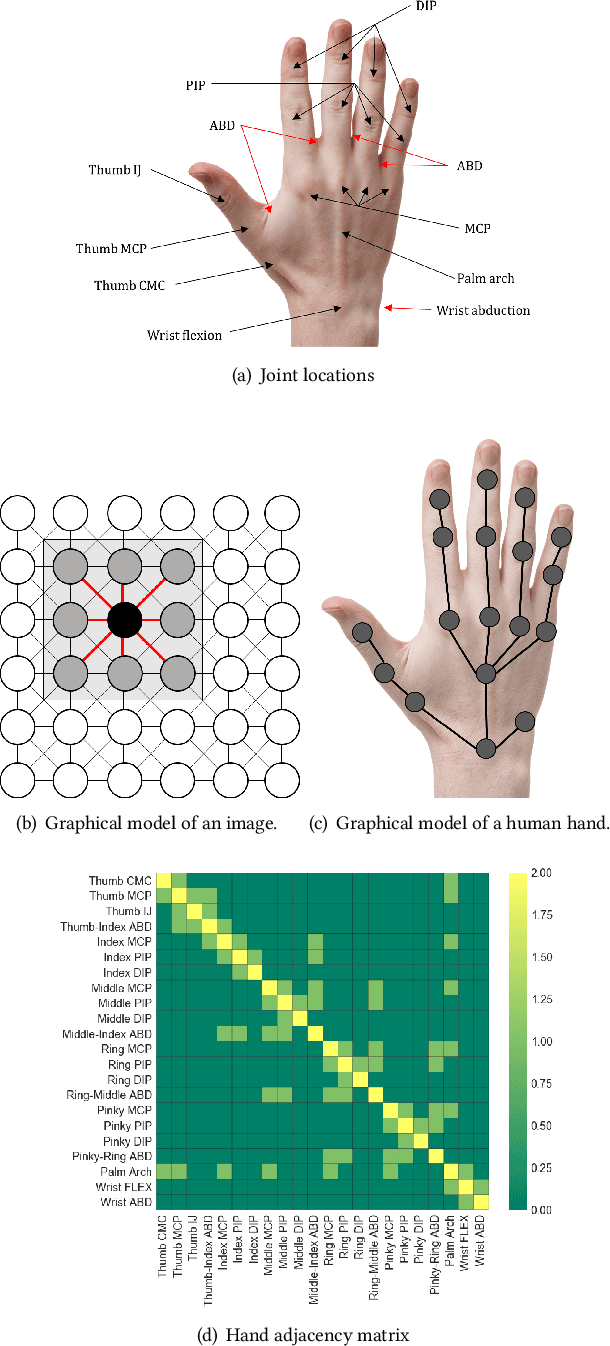
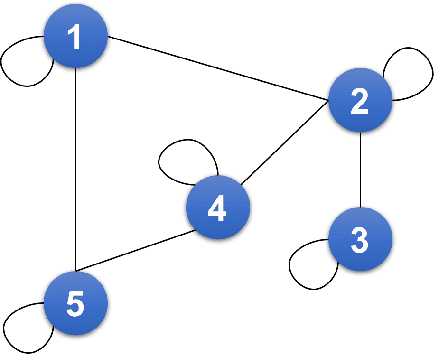
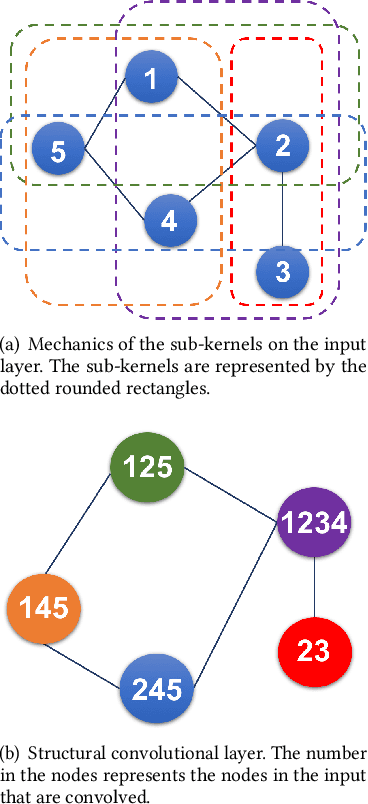
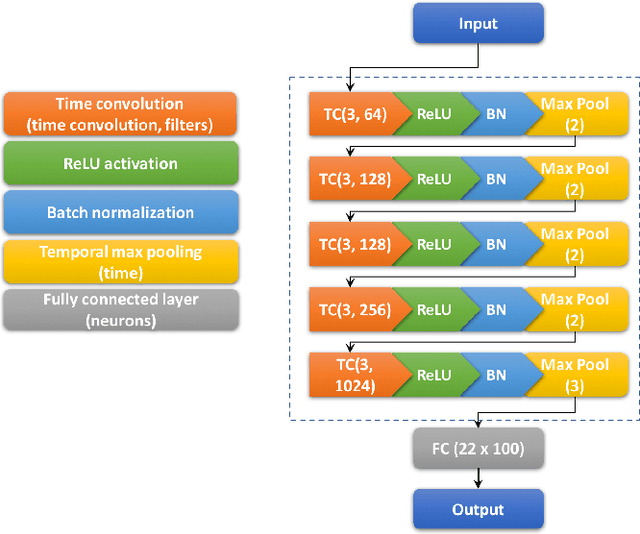
Deep Learning methods, specifically convolutional neural networks (CNNs), have seen a lot of success in the domain of image-based data, where the data offers a clearly structured topology in the regular lattice of pixels. This 4-neighbourhood topological simplicity makes the application of convolutional masks straightforward for time series data, such as video applications, but many high-dimensional time series data are not organised in regular lattices, and instead values may have adjacency relationships with non-trivial topologies, such as small-world networks or trees. In our application case, human kinematics, it is currently unclear how to generalise convolutional kernels in a principled manner. Therefore we define and implement here a framework for general graph-structured CNNs for time series analysis. Our algorithm automatically builds convolutional layers using the specified adjacency matrix of the data dimensions and convolutional masks that scale with the hop distance. In the limit of a lattice-topology our method produces the well-known image convolutional masks. We test our method first on synthetic data of arbitrarily-connected graphs and human hand motion capture data, where the hand is represented by a tree capturing the mechanical dependencies of the joints. We are able to demonstrate, amongst other things, that inclusion of the graph structure of the data dimensions improves model prediction significantly, when compared against a benchmark CNN model with only time convolution layers.
Uncertainty Principles in Risk-Aware Statistical Estimation
Apr 29, 2021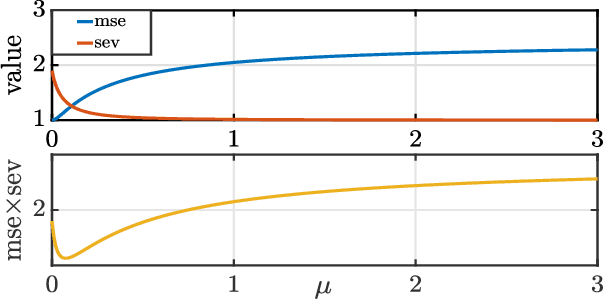
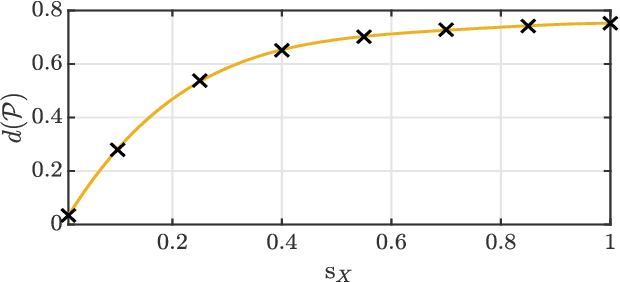
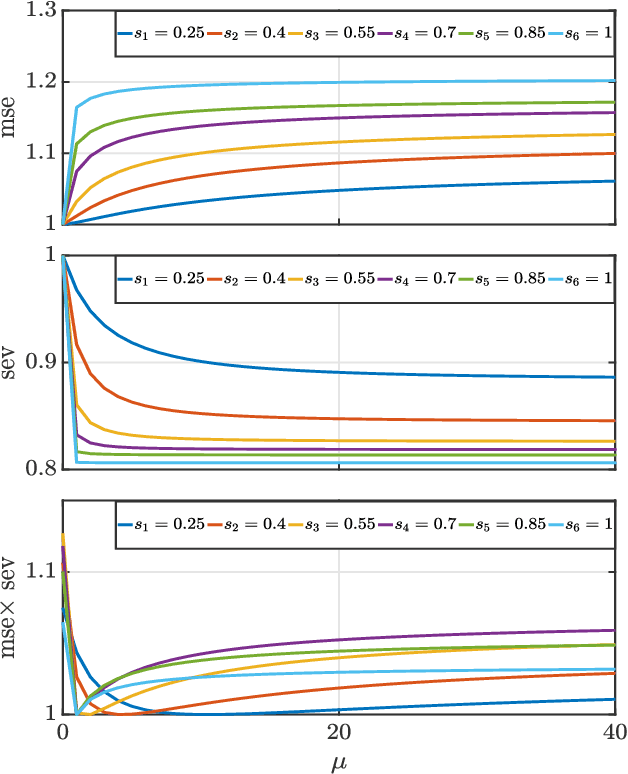
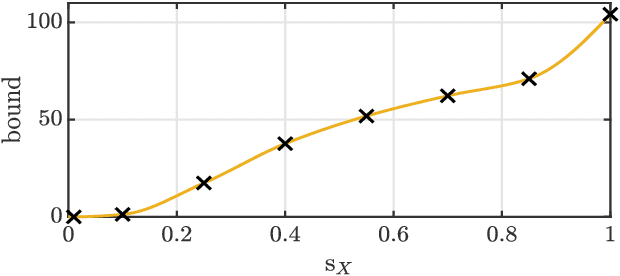
We present a new uncertainty principle for risk-aware statistical estimation, effectively quantifying the inherent trade-off between mean squared error ($\mse$) and risk, the latter measured by the associated average predictive squared error variance ($\sev$), for every admissible estimator of choice. Our uncertainty principle has a familiar form and resembles fundamental and classical results arising in several other areas, such as the Heisenberg principle in statistical and quantum mechanics, and the Gabor limit (time-scale trade-offs) in harmonic analysis. In particular, we prove that, provided a joint generative model of states and observables, the product between $\mse$ and $\sev$ is bounded from below by a computable model-dependent constant, which is explicitly related to the Pareto frontier of a recently studied $\sev$-constrained minimum $\mse$ (MMSE) estimation problem. Further, we show that the aforementioned constant is inherently connected to an intuitive new and rigorously topologically grounded statistical measure of distribution skewness in multiple dimensions, consistent with Pearson's moment coefficient of skewness for variables on the line. Our results are also illustrated via numerical simulations.
VIRDOC: Statistical and Machine Learning by a VIRtual DOCtor to Predict Dengue Fatality
Apr 29, 2021
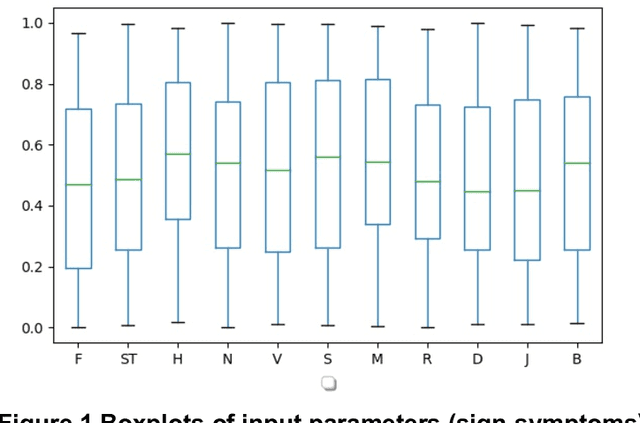
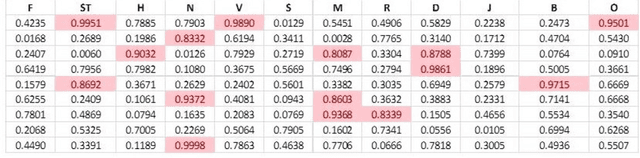
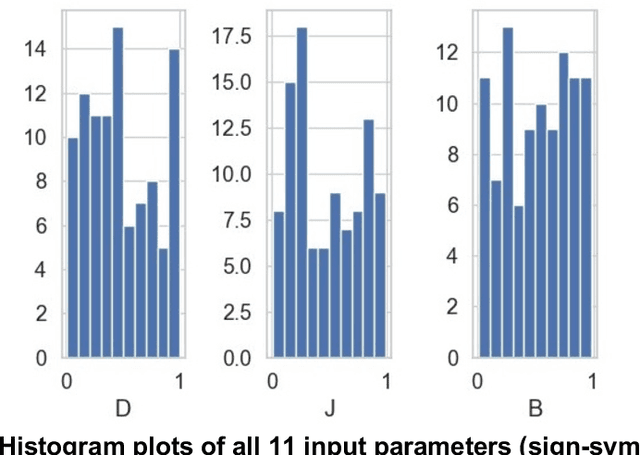
Clinicians conduct routine diagnosis by scrutinizing signs and symptoms of patients in treating epidemics. This skill evolves through trial-and-error and improves with time. The success of the therapeutic regimen relies largely on the accuracy of interpretation of such sign-symptoms, based on which the clinician ranks the potent causes of the epidemic and analyzes their interdependence to devise sustainable containment strategies. This study proposed an alternative medical front, a VIRtual DOCtor (VIRDOC), that can self-consistently rank key contributors of an epidemic and also correctly identify the infection stage, using the language of statistical modelling and Machine Learning. VIRDOC analyzes medical data and then translates these into a vector comprising Multiple Linear Regression (MLR) coefficients to probabilistically predict scores that compare with clinical experience-based assessment. The VIRDOC algorithm, risk managed through ANOVA, has been tested on dengue epidemic data (N=100 with 11 weighted sign-symptoms). Results highly encouraging with ca 75% accurate fatality prediction, compared to 71.4% from traditional diagnosis. The algorithm can be generically extended to analyze other epidemic forms.
Multi-agent Time-based Decision-making for the Search and Action Problem
Mar 13, 2018


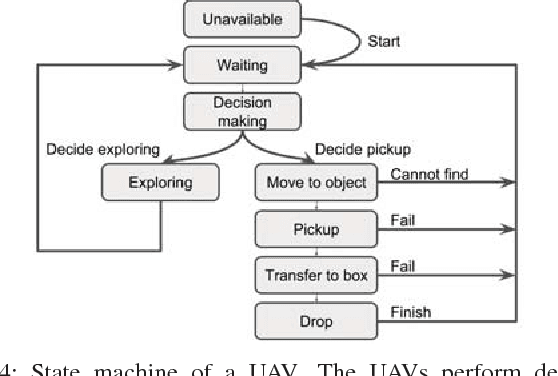
Many robotic applications, such as search-and-rescue, require multiple agents to search for and perform actions on targets. However, such missions present several challenges, including cooperative exploration, task selection and allocation, time limitations, and computational complexity. To address this, we propose a decentralized multi-agent decision-making framework for the search and action problem with time constraints. The main idea is to treat time as an allocated budget in a setting where each agent action incurs a time cost and yields a certain reward. Our approach leverages probabilistic reasoning to make near-optimal decisions leading to maximized reward. We evaluate our method in the search, pick, and place scenario of the Mohamed Bin Zayed International Robotics Challenge (MBZIRC), by using a probability density map and reward prediction function to assess actions. Extensive simulations show that our algorithm outperforms benchmark strategies, and we demonstrate system integration in a Gazebo-based environment, validating the framework's readiness for field application.