 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of Weight Discretization in QUBO-Based SVM Training
Oct 30, 2025Training Support Vector Machines (SVMs) can be formulated as a QUBO problem, enabling the use of quantum annealing for model optimization. In this work, we study how the number of qubits - linked to the discretization level of dual weights - affects predictive performance across datasets. We compare QUBO-based SVM training to the classical LIBSVM solver and find that even low-precision QUBO encodings (e.g., 1 bit per parameter) yield competitive, and sometimes superior, accuracy. While increased bit-depth enables larger regularization parameters, it does not always improve classification. Our findings suggest that selecting the right support vectors may matter more than their precise weighting. Although current hardware limits the size of solvable QUBOs, our results highlight the potential of quantum annealing for efficient SVM training as quantum devices scale.
Quantum Adiabatic Generation of Human-Like Passwords
Jun 10, 2025Generative Artificial Intelligence (GenAI) for Natural Language Processing (NLP) is the predominant AI technology to date. An important perspective for Quantum Computing (QC) is the question whether QC has the potential to reduce the vast resource requirements for training and operating GenAI models. While large-scale generative NLP tasks are currently out of reach for practical quantum computers, the generation of short semantic structures such as passwords is not. Generating passwords that mimic real user behavior has many applications, for example to test an authentication system against realistic threat models. Classical password generation via deep learning have recently been investigated with significant progress in their ability to generate novel, realistic password candidates. In the present work we investigate the utility of adiabatic quantum computers for this task. More precisely, we study different encodings of token strings and propose novel approaches based on the Quadratic Unconstrained Binary Optimization (QUBO) and the Unit-Disk Maximum Independent Set (UD-MIS) problems. Our approach allows us to estimate the token distribution from data and adiabatically prepare a quantum state from which we eventually sample the generated passwords via measurements. Our results show that relatively small samples of 128 passwords, generated on the QuEra Aquila 256-qubit neutral atom quantum computer, contain human-like passwords such as "Tunas200992" or "teedem28iglove".
Kernel $k$-Medoids as General Vector Quantization
Jun 05, 2025Vector Quantization (VQ) is a widely used technique in machine learning and data compression, valued for its simplicity and interpretability. Among hard VQ methods, $k$-medoids clustering and Kernel Density Estimation (KDE) approaches represent two prominent yet seemingly unrelated paradigms -- one distance-based, the other rooted in probability density matching. In this paper, we investigate their connection through the lens of Quadratic Unconstrained Binary Optimization (QUBO). We compare a heuristic QUBO formulation for $k$-medoids, which balances centrality and diversity, with a principled QUBO derived from minimizing Maximum Mean Discrepancy in KDE-based VQ. Surprisingly, we show that the KDE-QUBO is a special case of the $k$-medoids-QUBO under mild assumptions on the kernel's feature map. This reveals a deeper structural relationship between these two approaches and provides new insight into the geometric interpretation of the weighting parameters used in QUBO formulations for VQ.
Explainable Quantum Machine Learning
Jan 22, 2023Methods of artificial intelligence (AI) and especially machine learning (ML) have been growing ever more complex, and at the same time have more and more impact on people's lives. This leads to explainable AI (XAI) manifesting itself as an important research field that helps humans to better comprehend ML systems. In parallel, quantum machine learning (QML) is emerging with the ongoing improvement of quantum computing hardware combined with its increasing availability via cloud services. QML enables quantum-enhanced ML in which quantum mechanics is exploited to facilitate ML tasks, typically in form of quantum-classical hybrid algorithms that combine quantum and classical resources. Quantum gates constitute the building blocks of gate-based quantum hardware and form circuits that can be used for quantum computations. For QML applications, quantum circuits are typically parameterized and their parameters are optimized classically such that a suitably defined objective function is minimized. Inspired by XAI, we raise the question of explainability of such circuits by quantifying the importance of (groups of) gates for specific goals. To this end, we transfer and adapt the well-established concept of Shapley values to the quantum realm. The resulting attributions can be interpreted as explanations for why a specific circuit works well for a given task, improving the understanding of how to construct parameterized (or variational) quantum circuits, and fostering their human interpretability in general. An experimental evaluation on simulators and two superconducting quantum hardware devices demonstrates the benefits of the proposed framework for classification, generative modeling, transpilation, and optimization. Furthermore, our results shed some light on the role of specific gates in popular QML approaches.
Shapley Values with Uncertain Value Functions
Jan 19, 2023We propose a novel definition of Shapley values with uncertain value functions based on first principles using probability theory. Such uncertain value functions can arise in the context of explainable machine learning as a result of non-deterministic algorithms. We show that random effects can in fact be absorbed into a Shapley value with a noiseless but shifted value function. Hence, Shapley values with uncertain value functions can be used in analogy to regular Shapley values. However, their reliable evaluation typically requires more computational effort.
Quantum Feature Selection
Mar 24, 2022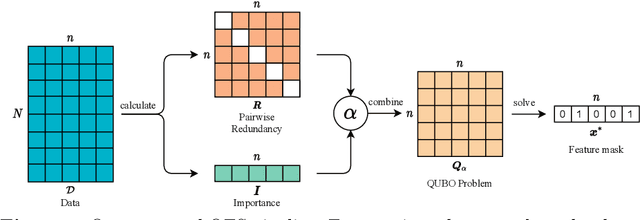


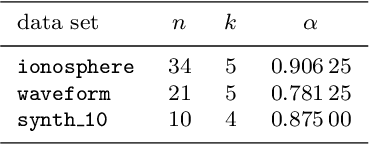
In machine learning, fewer features reduce model complexity. Carefully assessing the influence of each input feature on the model quality is therefore a crucial preprocessing step. We propose a novel feature selection algorithm based on a quadratic unconstrained binary optimization (QUBO) problem, which allows to select a specified number of features based on their importance and redundancy. In contrast to iterative or greedy methods, our direct approach yields higherquality solutions. QUBO problems are particularly interesting because they can be solved on quantum hardware. To evaluate our proposed algorithm, we conduct a series of numerical experiments using a classical computer, a quantum gate computer and a quantum annealer. Our evaluation compares our method to a range of standard methods on various benchmark datasets. We observe competitive performance.
On the effects of biased quantum random numbers on the initialization of artificial neural networks
Aug 30, 2021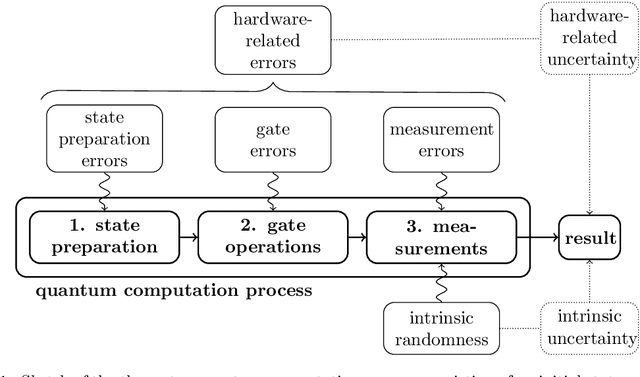
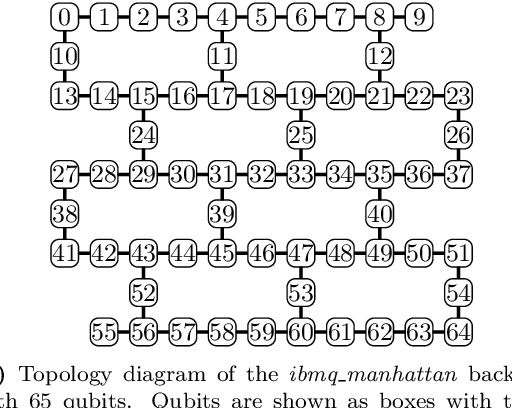
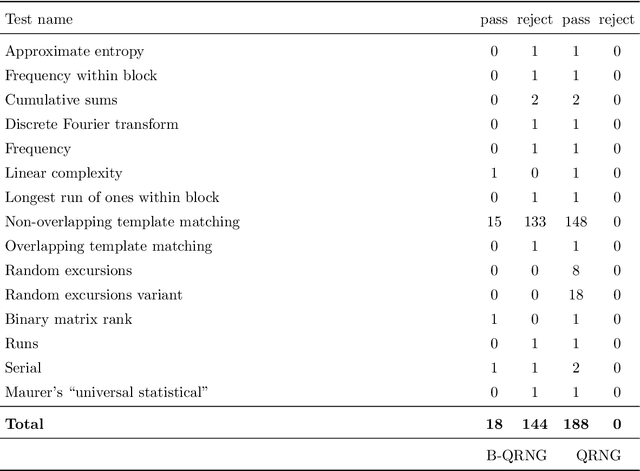
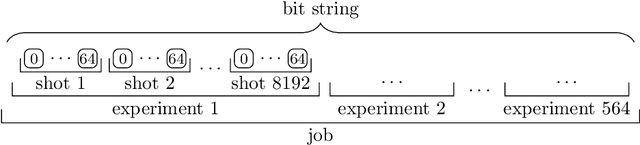
Recent advances in practical quantum computing have led to a variety of cloud-based quantum computing platforms that allow researchers to evaluate their algorithms on noisy intermediate-scale quantum (NISQ) devices. A common property of quantum computers is that they exhibit instances of true randomness as opposed to pseudo-randomness obtained from classical systems. Investigating the effects of such true quantum randomness in the context of machine learning is appealing, and recent results vaguely suggest that benefits can indeed be achieved from the use of quantum random numbers. To shed some more light on this topic, we empirically study the effects of hardware-biased quantum random numbers on the initialization of artificial neural network weights in numerical experiments. We find no statistically significant difference in comparison with unbiased quantum random numbers as well as biased and unbiased random numbers from a classical pseudo-random number generator. The quantum random numbers for our experiments are obtained from real quantum hardware.
Yes We Care! -- Certification for Machine Learning Methods through the Care Label Framework
May 21, 2021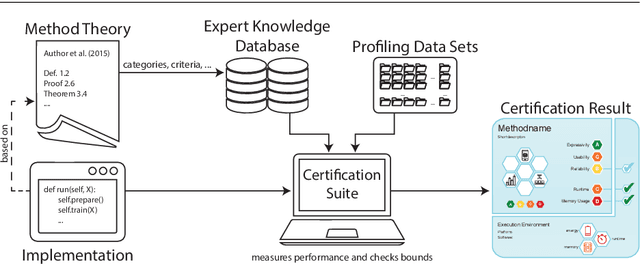
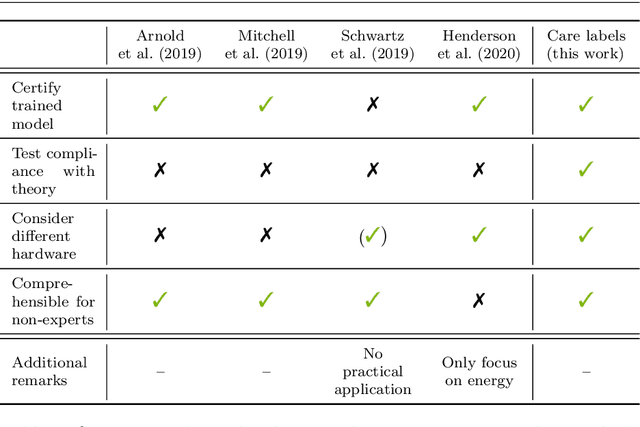
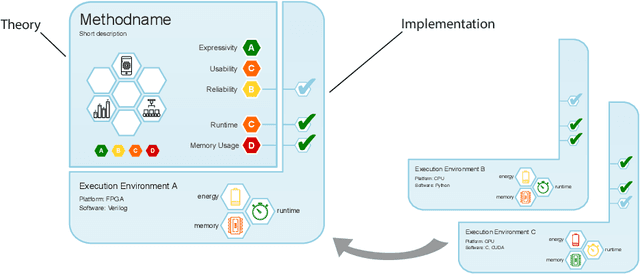
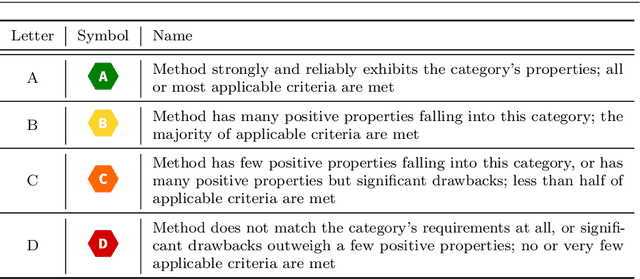
Machine learning applications have become ubiquitous. Their applications from machine embedded control in production over process optimization in diverse areas (e.g., traffic, finance, sciences) to direct user interactions like advertising and recommendations. This has led to an increased effort of making machine learning trustworthy. Explainable and fair AI have already matured. They address knowledgeable users and application engineers. However, there are users that want to deploy a learned model in a similar way as their washing machine. These stakeholders do not want to spend time understanding the model. Instead, they want to rely on guaranteed properties. What are the relevant properties? How can they be expressed to stakeholders without presupposing machine learning knowledge? How can they be guaranteed for a certain implementation of a model? These questions move far beyond the current state-of-the-art and we want to address them here. We propose a unified framework that certifies learning methods via care labels. They are easy to understand and draw inspiration from well-known certificates like textile labels or property cards of electronic devices. Our framework considers both, the machine learning theory and a given implementation. We test the implementation's compliance with theoretical properties and bounds. In this paper, we illustrate care labels by a prototype implementation of a certification suite for a selection of probabilistic graphical models.