 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MIMO: Mutual Integration of Patient Journey and Medical Ontology for Healthcare Representation Learning
Jul 21, 2021
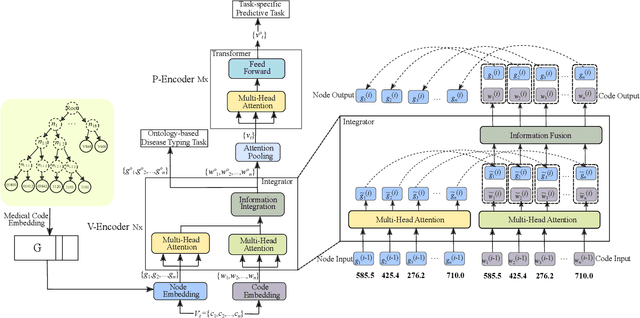
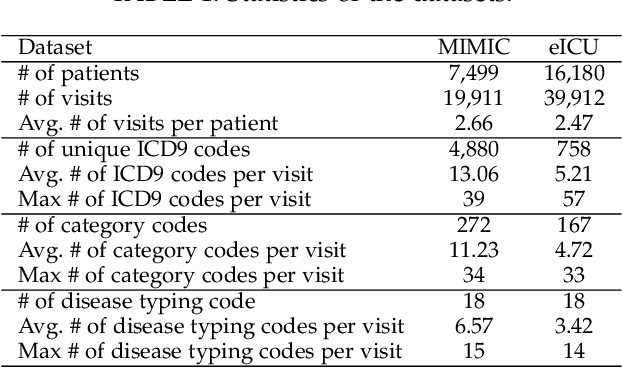
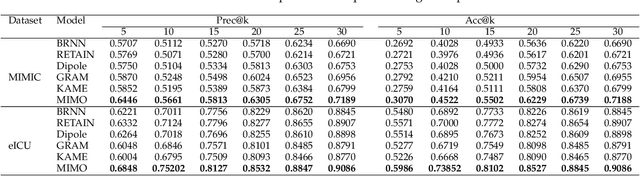
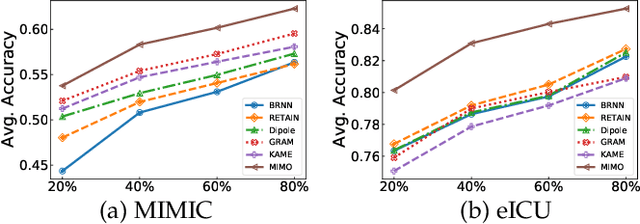
Healthcare representation learning on the Electronic Health Record (EHR) is seen as crucial for predictive analytics in the medical field. Many natural language processing techniques, such as word2vec, RNN and self-attention, have been adapted for use in hierarchical and time stamped EHR data, but fail when they lack either general or task-specific data. Hence, some recent works train healthcare representations by incorporating medical ontology (a.k.a. knowledge graph), by self-supervised tasks like diagnosis prediction, but (1) the small-scale, monotonous ontology is insufficient for robust learning, and (2) critical contexts or dependencies underlying patient journeys are never exploited to enhance ontology learning. To address this, we propose an end-to-end robust Transformer-based solution, Mutual Integration of patient journey and Medical Ontology (MIMO) for healthcare representation learning and predictive analytics. Specifically, it consists of task-specific representation learning and graph-embedding modules to learn both patient journey and medical ontology interactively. Consequently, this creates a mutual integration to benefit both healthcare representation learning and medical ontology embedding. Moreover, such integration is achieved by a joint training of both task-specific predictive and ontology-based disease typing tasks based on fused embeddings of the two modules. Experiments conducted on two real-world diagnosis prediction datasets show that, our healthcare representation model MIMO not only achieves better predictive results than previous state-of-the-art approaches regardless of sufficient or insufficient training data, but also derives more interpretable embeddings of diagnoses.
Periodic Freight Demand Forecasting for Large-scale Tactical Planning
May 19, 2021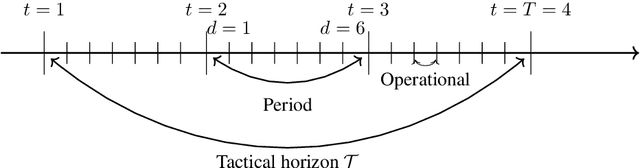
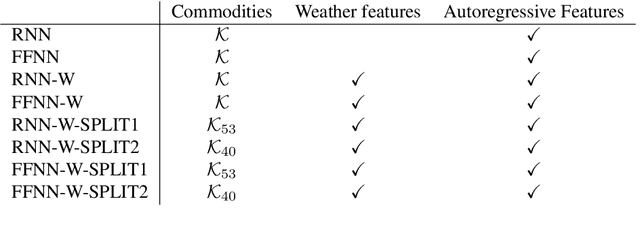
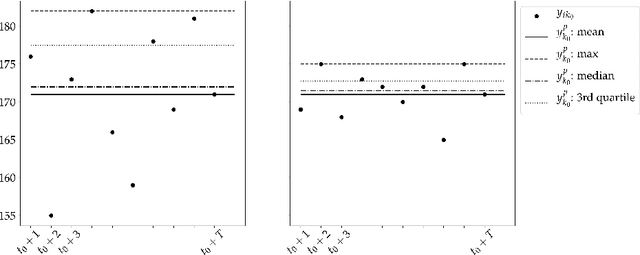
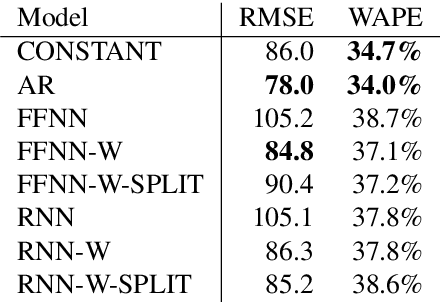
Crucial to freight carriers is the tactical planning of the service network. The aim is to obtain a cyclic plan over a given tactical planning horizon that satisfies predicted demand at a minimum cost. A central input to the planning process is the periodic demand, that is, the demand expected to repeat in every period in the planning horizon. We focus on large-scale tactical planning problems that require deterministic models for computational tractability. The problem of estimating periodic demand in this setting broadly present in practice has hitherto been overlooked in the literature. We address this gap by formally introducing the periodic demand estimation problem and propose a two-step methodology: Based on time series forecasts obtained in the first step, we propose, in the second step, to solve a multilevel mathematical programming formulation whose solution is a periodic demand estimate that minimizes fixed costs, and variable costs incurred by adapting the tactical plan at an operational level. We report results in an extensive empirical study of a real large-scale application from the Canadian National Railway Company. We compare our periodic demand estimates to the approach commonly used in practice which simply consists in using the mean of the time series forecasts. The results clearly show the importance of the periodic demand estimation problem. Indeed, the planning costs exhibit an important variation over different periodic demand estimates, and using an estimate different from the mean forecast can lead to substantial cost reductions. For example, the costs associated with the period demand estimates based on forecasts were comparable to, or even better than those obtained using the mean of actual demand.
Retinal OCT Denoising with Pseudo-Multimodal Fusion Network
Jul 09, 2021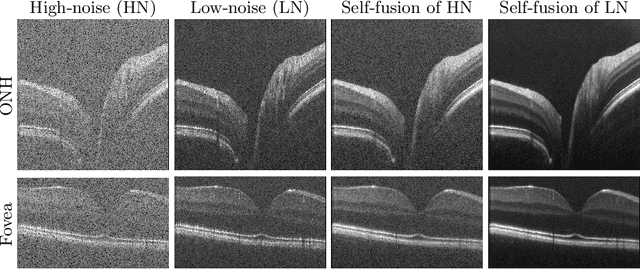
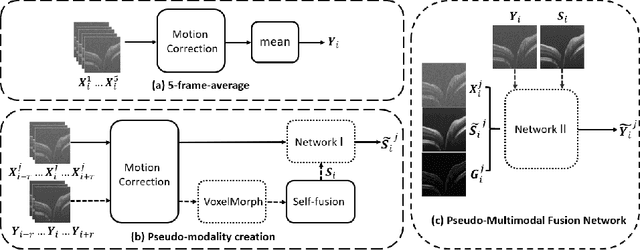
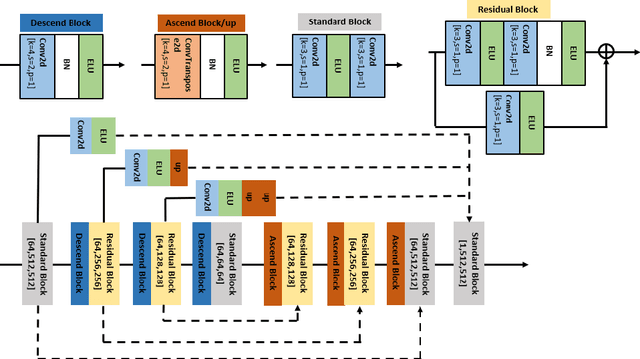
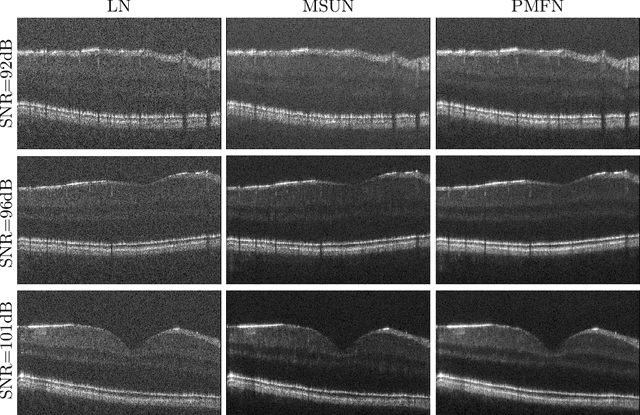
Optical coherence tomography (OCT) is a prevalent imaging technique for retina. However, it is affected by multiplicative speckle noise that can degrade the visibility of essential anatomical structures, including blood vessels and tissue layers. Although averaging repeated B-scan frames can significantly improve the signal-to-noise-ratio (SNR), this requires longer acquisition time, which can introduce motion artifacts and cause discomfort to patients. In this study, we propose a learning-based method that exploits information from the single-frame noisy B-scan and a pseudo-modality that is created with the aid of the self-fusion method. The pseudo-modality provides good SNR for layers that are barely perceptible in the noisy B-scan but can over-smooth fine features such as small vessels. By using a fusion network, desired features from each modality can be combined, and the weight of their contribution is adjustable. Evaluated by intensity-based and structural metrics, the result shows that our method can effectively suppress the speckle noise and enhance the contrast between retina layers while the overall structure and small blood vessels are preserved. Compared to the single modality network, our method improves the structural similarity with low noise B-scan from 0.559 +\- 0.033 to 0.576 +\- 0.031.
A mechanistic-based data-driven approach to accelerate structural topology optimization through finite element convolutional neural network (FE-CNN)
Jun 25, 2021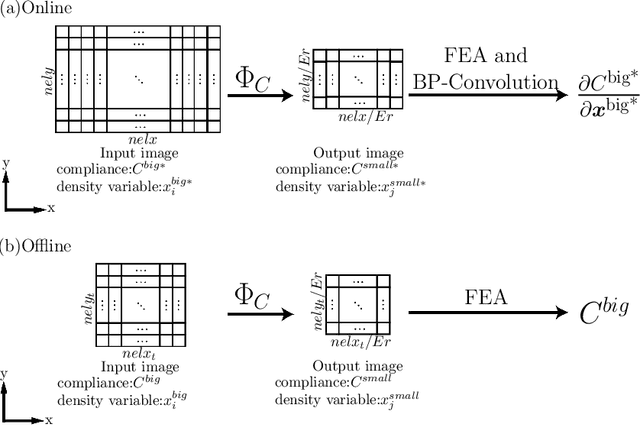
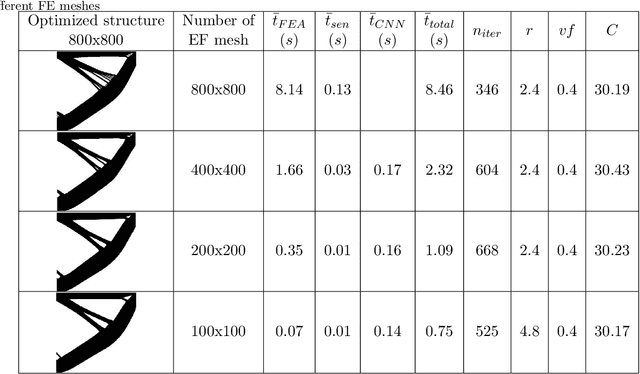
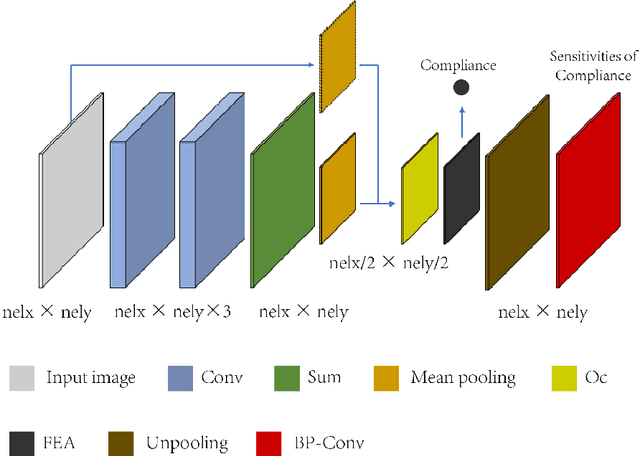
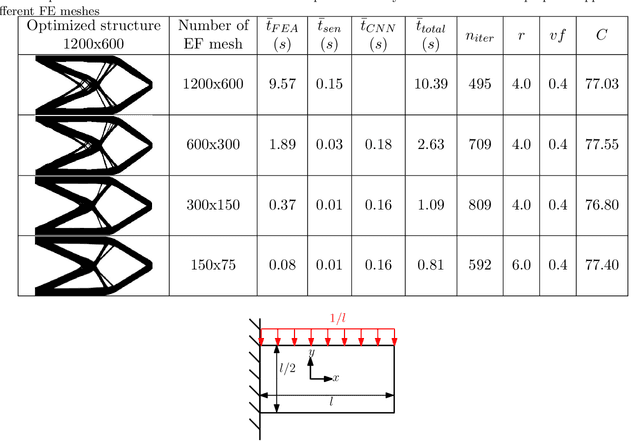
In this paper, a mechanistic data-driven approach is proposed to accelerate structural topology optimization, employing an in-house developed finite element convolutional neural network (FE-CNN). Our approach can be divided into two stages: offline training, and online optimization. During offline training, a mapping function is built between high and low resolution representations of a given design domain. The mapping is expressed by a FE-CNN, which targets a common objective function value (e.g., structural compliance) across design domains of differing resolutions. During online optimization, an arbitrary design domain of high resolution is reduced to low resolution through the trained mapping function. The original high-resolution domain is thus designed by computations performed on only the low-resolution version, followed by an inverse mapping back to the high-resolution domain. Numerical examples demonstrate that this approach can accelerate optimization by up to an order of magnitude in computational time. Our proposed approach therefore shows great potential to overcome the curse-of-dimensionality incurred by density-based structural topology optimization. The limitation of our present approach is also discussed.
Fast Pixel-Matching for Video Object Segmentation
Jul 09, 2021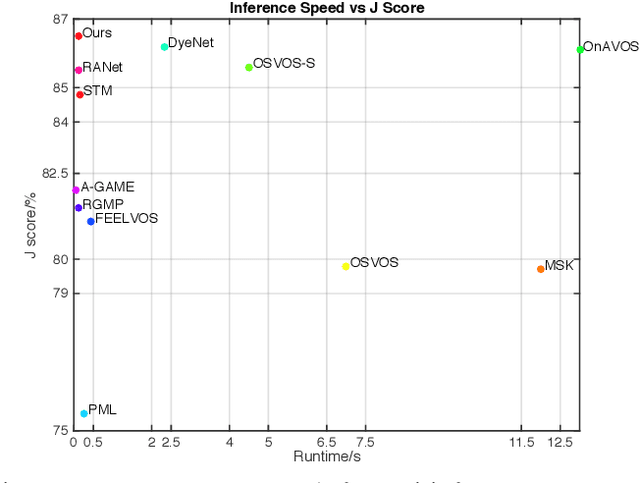
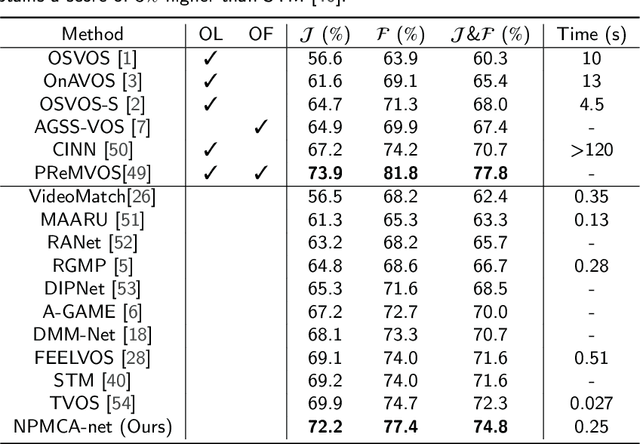
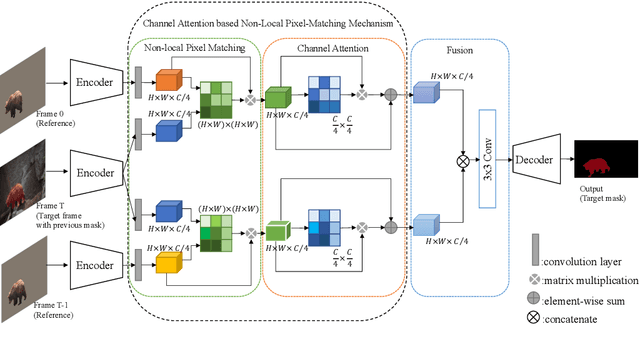
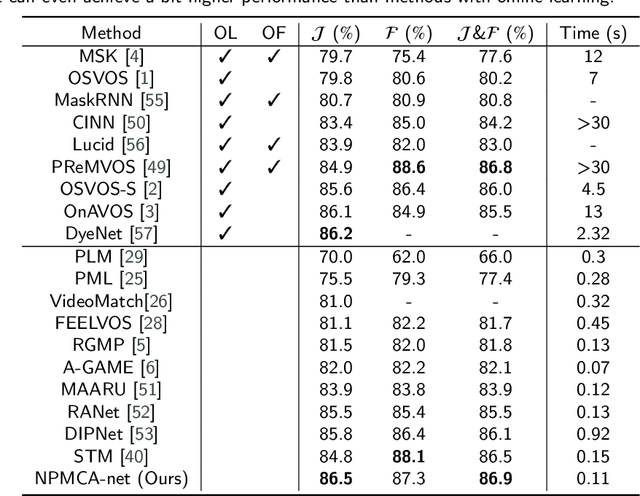
Video object segmentation, aiming to segment the foreground objects given the annotation of the first frame, has been attracting increasing attentions. Many state-of-the-art approaches have achieved great performance by relying on online model updating or mask-propagation techniques. However, most online models require high computational cost due to model fine-tuning during inference. Most mask-propagation based models are faster but with relatively low performance due to failure to adapt to object appearance variation. In this paper, we are aiming to design a new model to make a good balance between speed and performance. We propose a model, called NPMCA-net, which directly localizes foreground objects based on mask-propagation and non-local technique by matching pixels in reference and target frames. Since we bring in information of both first and previous frames, our network is robust to large object appearance variation, and can better adapt to occlusions. Extensive experiments show that our approach can achieve a new state-of-the-art performance with a fast speed at the same time (86.5% IoU on DAVIS-2016 and 72.2% IoU on DAVIS-2017, with speed of 0.11s per frame) under the same level comparison. Source code is available at https://github.com/siyueyu/NPMCA-net.
Chebyshev-Cantelli PAC-Bayes-Bennett Inequality for the Weighted Majority Vote
Jun 25, 2021
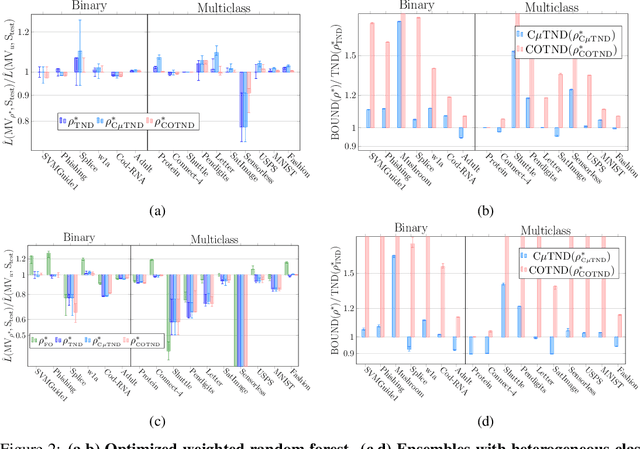
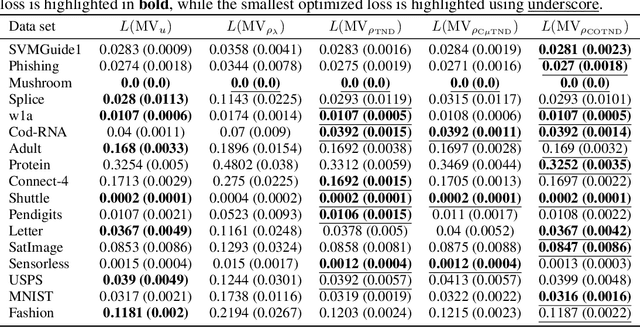
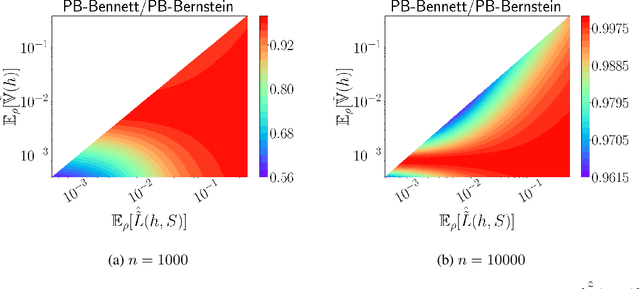
We present a new second-order oracle bound for the expected risk of a weighted majority vote. The bound is based on a novel parametric form of the Chebyshev-Cantelli inequality (a.k.a.\ one-sided Chebyshev's), which is amenable to efficient minimization. The new form resolves the optimization challenge faced by prior oracle bounds based on the Chebyshev-Cantelli inequality, the C-bounds [Germain et al., 2015], and, at the same time, it improves on the oracle bound based on second order Markov's inequality introduced by Masegosa et al. [2020]. We also derive the PAC-Bayes-Bennett inequality, which we use for empirical estimation of the oracle bound. The PAC-Bayes-Bennett inequality improves on the PAC-Bayes-Bernstein inequality by Seldin et al. [2012]. We provide an empirical evaluation demonstrating that the new bounds can improve on the work by Masegosa et al. [2020]. Both the parametric form of the Chebyshev-Cantelli inequality and the PAC-Bayes-Bennett inequality may be of independent interest for the study of concentration of measure in other domains.
Improving On-Screen Sound Separation for Open Domain Videos with Audio-Visual Self-attention
Jun 17, 2021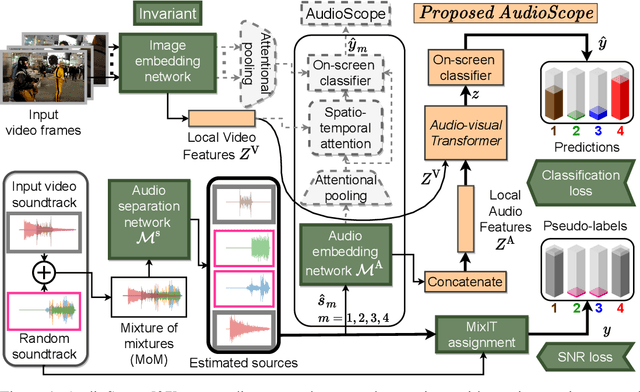
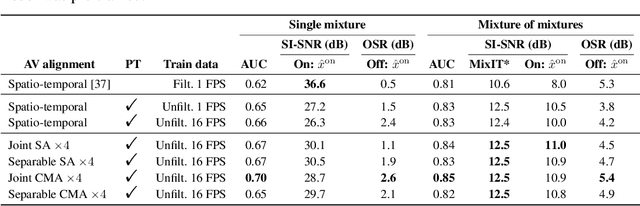
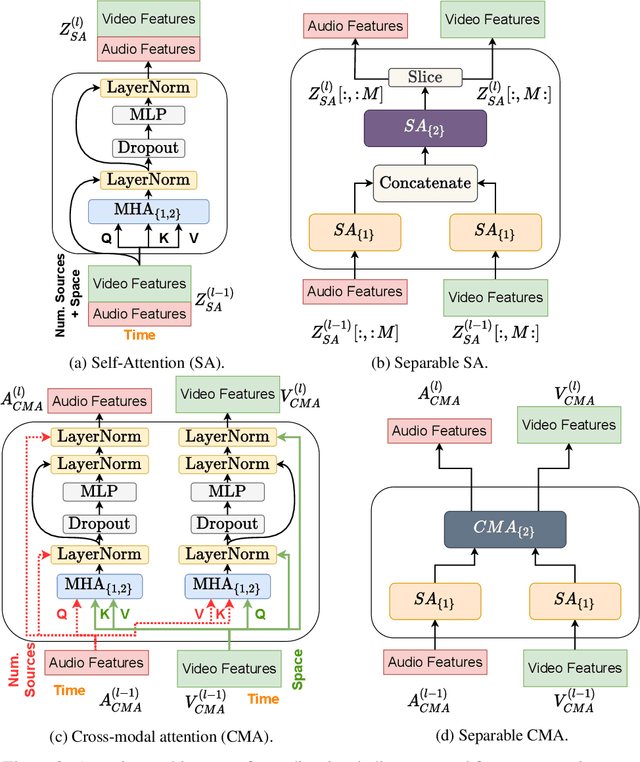
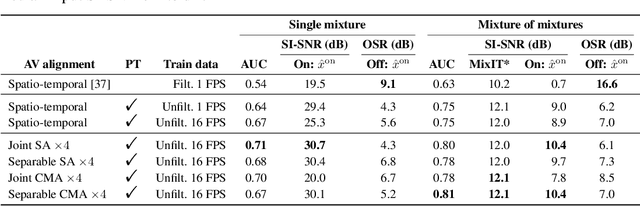
We introduce a state-of-the-art audio-visual on-screen sound separation system which is capable of learning to separate sounds and associate them with on-screen objects by looking at in-the-wild videos. We identify limitations of previous work on audiovisual on-screen sound separation, including the simplicity and coarse resolution of spatio-temporal attention, and poor convergence of the audio separation model. Our proposed model addresses these issues using cross-modal and self-attention modules that capture audio-visual dependencies at a finer resolution over time, and by unsupervised pre-training of audio separation model. These improvements allow the model to generalize to a much wider set of unseen videos. For evaluation and semi-supervised training, we collected human annotations of on-screen audio from a large database of in-the-wild videos (YFCC100M). Our results show marked improvements in on-screen separation performance, in more general conditions than previous methods.
Non-intrusive Nonlinear Model Reduction via Machine Learning Approximations to Low-dimensional Operators
Jun 17, 2021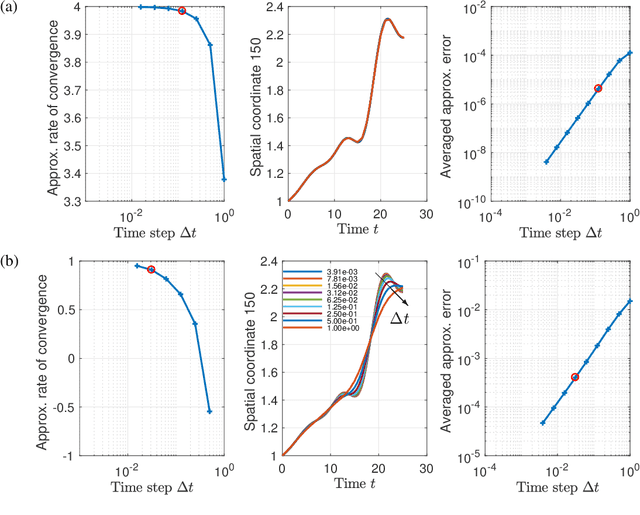
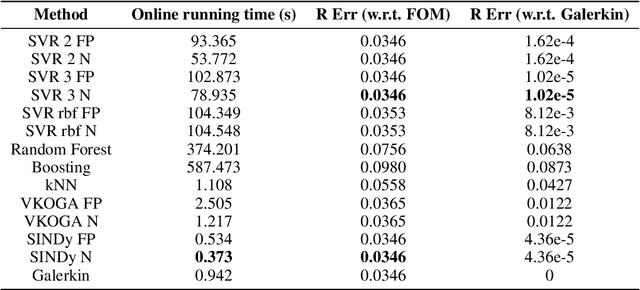
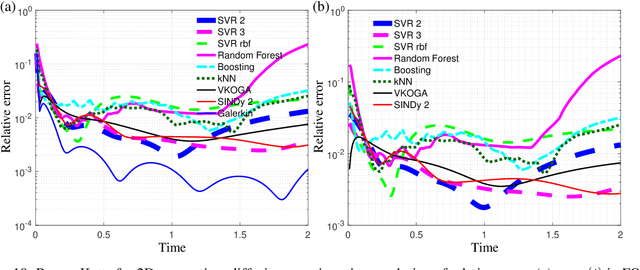
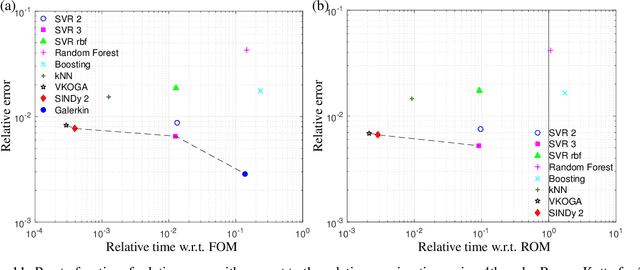
Although projection-based reduced-order models (ROMs) for parameterized nonlinear dynamical systems have demonstrated exciting results across a range of applications, their broad adoption has been limited by their intrusivity: implementing such a reduced-order model typically requires significant modifications to the underlying simulation code. To address this, we propose a method that enables traditionally intrusive reduced-order models to be accurately approximated in a non-intrusive manner. Specifically, the approach approximates the low-dimensional operators associated with projection-based reduced-order models (ROMs) using modern machine-learning regression techniques. The only requirement of the simulation code is the ability to export the velocity given the state and parameters as this functionality is used to train the approximated low-dimensional operators. In addition to enabling nonintrusivity, we demonstrate that the approach also leads to very low computational complexity, achieving up to $1000\times$ reduction in run time. We demonstrate the effectiveness of the proposed technique on two types of PDEs.
Training a Deep Neural Network via Policy Gradients for Blind Source Separation in Polyphonic Music Recordings
Jul 09, 2021
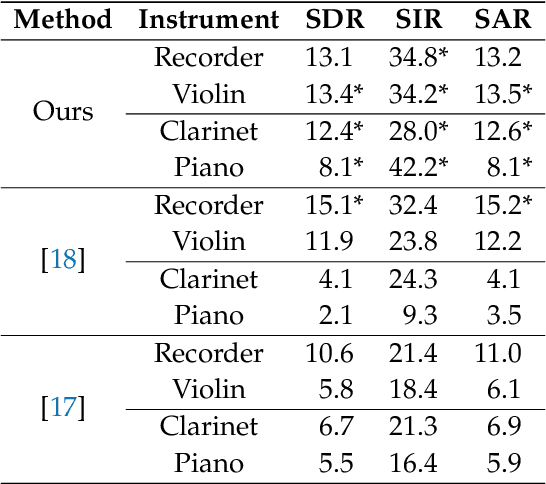
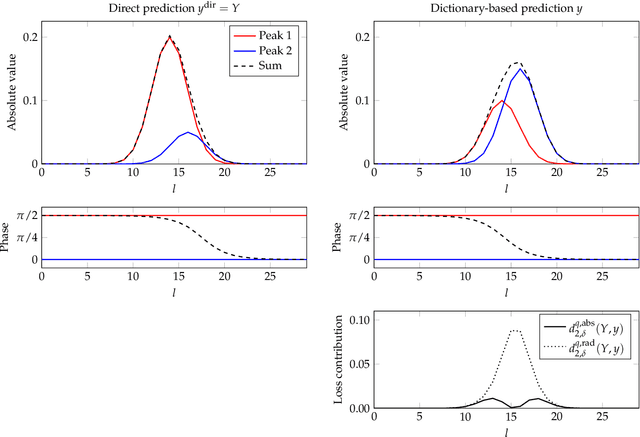
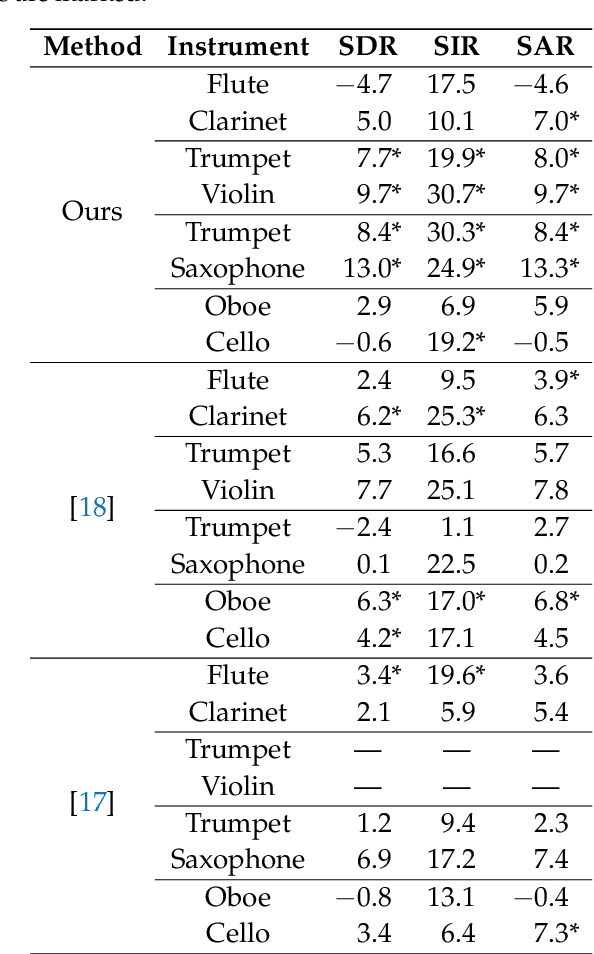
We propose a method for the blind separation of sounds of musical instruments in audio signals. We describe the individual tones via a parametric model, training a dictionary to capture the relative amplitudes of the harmonics. The model parameters are predicted via a U-Net, which is a type of deep neural network. The network is trained without ground truth information, based on the difference between the model prediction and the individual STFT time frames. Since some of the model parameters do not yield a useful backpropagation gradient, we model them stochastically and employ the policy gradient instead. To provide phase information and account for inaccuracies in the dictionary-based representation, we also let the network output a direct prediction, which we then use to resynthesize the audio signals for the individual instruments. Due to the flexibility of the neural network, inharmonicity can be incorporated seamlessly and no preprocessing of the input spectra is required. Our algorithm yields high-quality separation results with particularly low interference on a variety of different audio samples, both acoustic and synthetic, provided that the sample contains enough data for the training and that the spectral characteristics of the musical instruments are sufficiently stable to be approximated by the dictionary.
Self-Organizing mmWave MIMO Cell-Free Networks With Hybrid Beamforming: A Hierarchical DRL-Based Design
Mar 17, 2021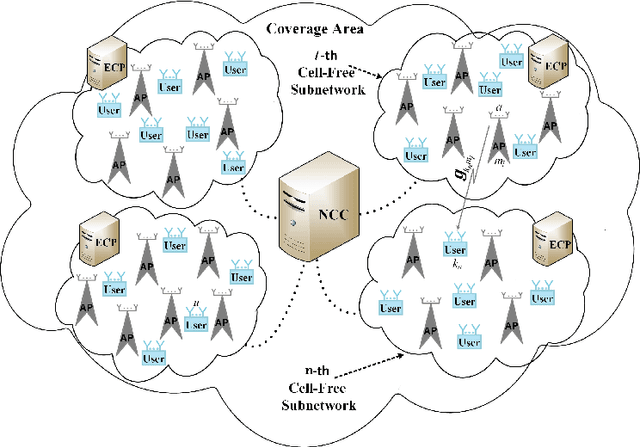
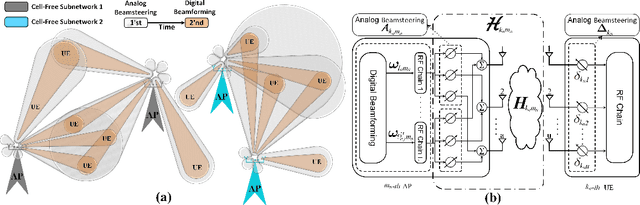
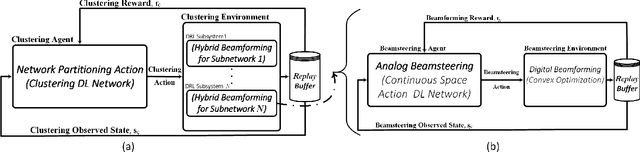
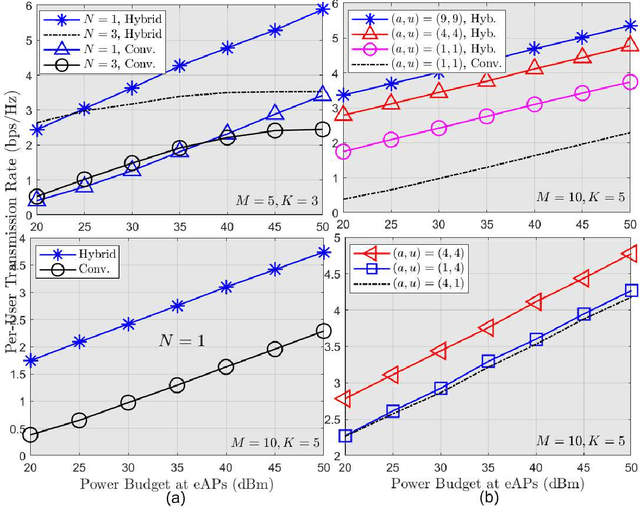
In a cell-free wireless network, distributed access points (APs) jointly serve all user equipments (UEs) within the their coverage area by using the same time/frequency resources. In this paper, we develop a novel downlink cell-free multiple-input multiple-output (MIMO) millimeter wave (mmWave) network architecture that enables all APs and UEs to dynamically self-partition into a set of independent cell-free subnetworks in a time-slot basis. For this, we propose several network partitioning algorithms based on deep reinforcement learning (DRL). Furthermore, to mitigate interference between different cell-free subnetworks, we develop a novel hybrid analog beamsteering-digital beamforming model that zero-forces interference among cell-free subnetworks and at the same time maximizes the instantaneous sum-rate of all UEs within each subnetwork. Specifically, the hybrid beamforming model is implemented by using a novel mixed DRL-convex optimization method in which analog beamsteering between APs and UEs is conducted based on DRL while digital beamforming is modeled and solved as a convex optimization problem. The DRL models for network clustering and hybrid beamsteering are combined into a single hierarchical DRL design that enables exchange of DRL agents' experiences during both network training and operation. We also benchmark the performance of DRL models for clustering and beamsteering in terms of network performance, convergence rate, and computational complexity.