 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Handwritten Digit Recognition using Machine and Deep Learning Algorithms
Jun 23, 2021
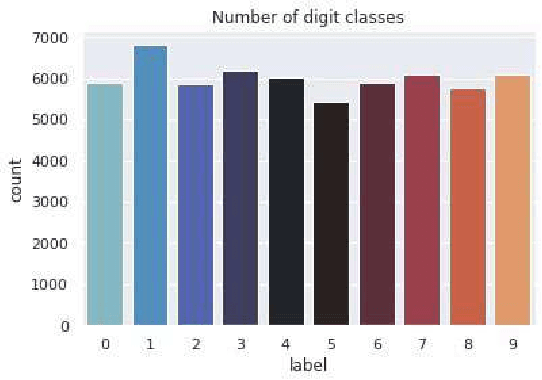
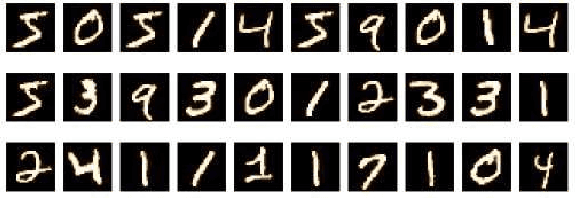
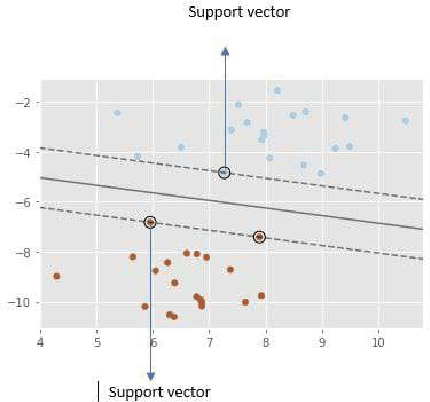
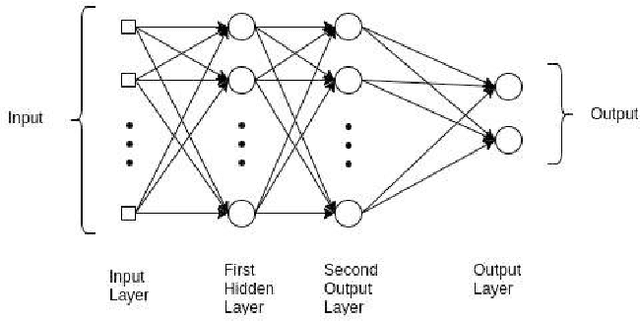
The reliance of humans over machines has never been so high such that from object classification in photographs to adding sound to silent movies everything can be performed with the help of deep learning and machine learning algorithms. Likewise, Handwritten text recognition is one of the significant areas of research and development with a streaming number of possibilities that could be attained. Handwriting recognition (HWR), also known as Handwritten Text Recognition (HTR), is the ability of a computer to receive and interpret intelligible handwritten input from sources such as paper documents, photographs, touch-screens and other devices [1]. Apparently, in this paper, we have performed handwritten digit recognition with the help of MNIST datasets using Support Vector Machines (SVM), Multi-Layer Perceptron (MLP) and Convolution Neural Network (CNN) models. Our main objective is to compare the accuracy of the models stated above along with their execution time to get the best possible model for digit recognition.
* 6 Pages, 13 figures, and 1 table
Short-term Renewable Energy Forecasting in Greece using Prophet Decomposition and Tree-based Ensembles
Jul 08, 2021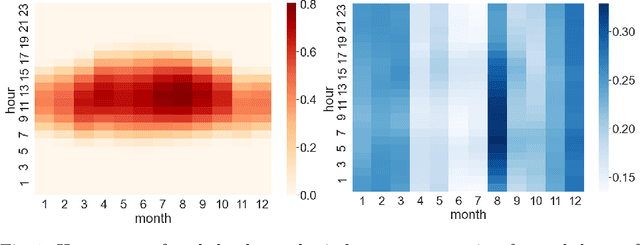
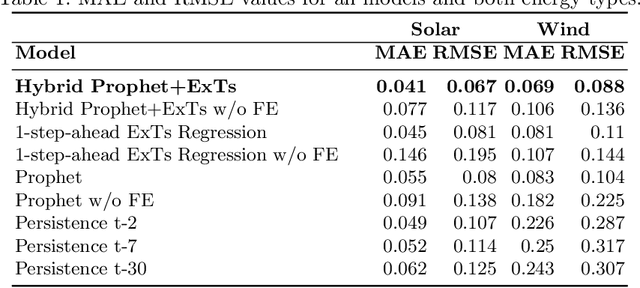
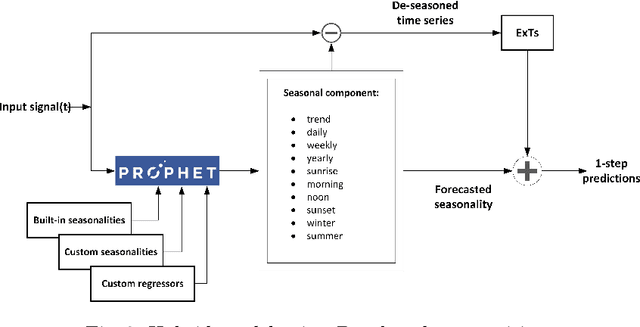
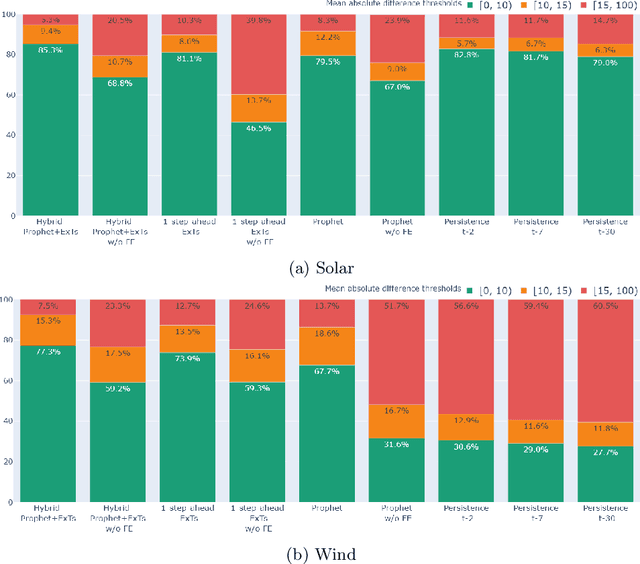
Energy production using renewable sources exhibits inherent uncertainties due to their intermittent nature. Nevertheless, the unified European energy market promotes the increasing penetration of renewable energy sources (RES) by the regional energy system operators. Consequently, RES forecasting can assist in the integration of these volatile energy sources, since it leads to higher reliability and reduced ancillary operational costs for power systems. This paper presents a new dataset for solar and wind energy generation forecast in Greece and introduces a feature engineering pipeline that enriches the dimensional space of the dataset. In addition, we propose a novel method that utilizes the innovative Prophet model, an end-to-end forecasting tool that considers several kinds of nonlinear trends in decomposing the energy time series before a tree-based ensemble provides short-term predictions. The performance of the system is measured through representative evaluation metrics, and by estimating the model's generalization under an industryprovided scheme of absolute error thresholds. The proposed hybrid model competes with baseline persistence models, tree-based regression ensembles, and the Prophet model, managing to outperform them, presenting both lower error rates and more favorable error distribution.
Real-time Multiple People Hand Localization in 4D Point Clouds
Mar 05, 2019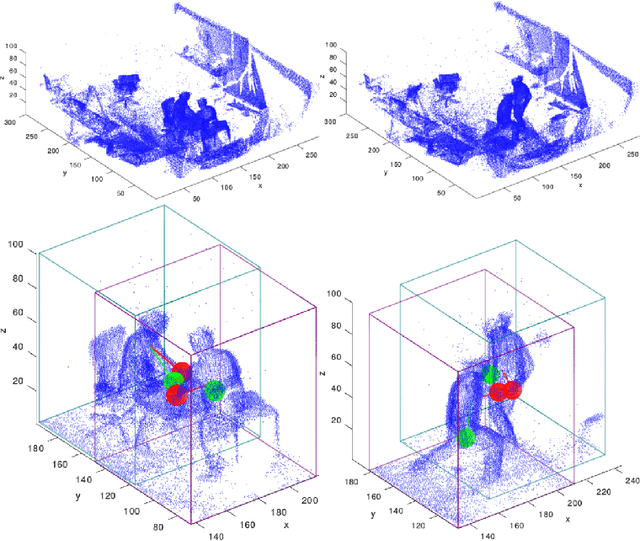

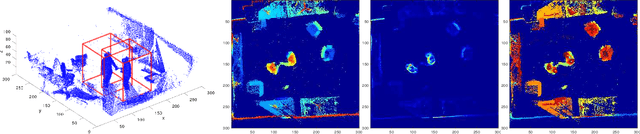
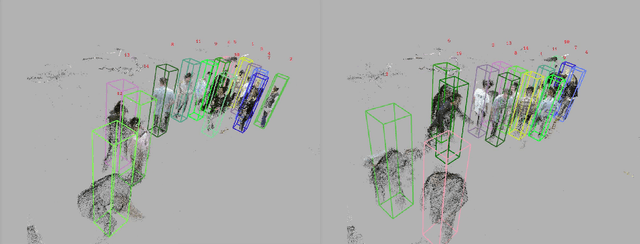
We propose novel real-time algorithm to localize hands and find their associations with multiple people in the cluttered 4D volumetric data (dynamic 3D volumes). Different from the traditional multiple view approaches, which find key points in 2D and then triangulate to recover the 3D locations, our method directly processes the dynamic 3D data that involve both clutter and crowd. The volumetric representation is more desirable than the partial observations from different view points and enables more robust and accurate results. However, due to the large amount of data in the volumetric representation brute force 3D schemes are slow. In this paper, we propose novel real-time methods to tackle the problem to achieve both higher accuracy and faster speed than previous approaches. Our method detects the 3D bounding box of each subject and localizes the hands of each person. We develop new 2D features for fast candidate proposals and optimize the trajectory linking using a new max-covering bipartite matching formulation, which is critical for robust performance. We propose a novel decomposition method to reduce the key point localization in each person 3D volume to a sequence of efficient 2D problems. Our experiments show that the proposed method is faster than different competing methods and it gives almost half the localization error.
On The Impact of Client Sampling on Federated Learning Convergence
Jul 26, 2021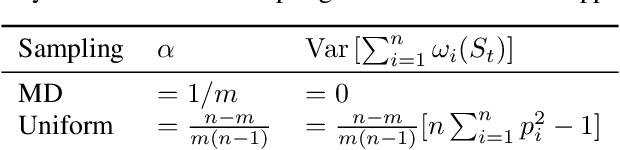
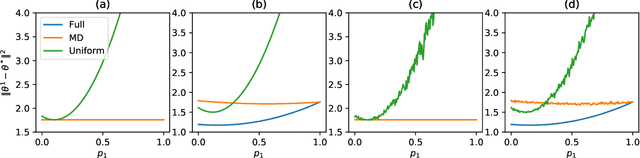
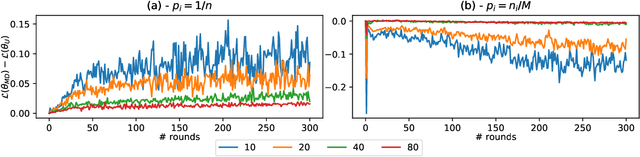

While clients' sampling is a central operation of current state-of-the-art federated learning (FL) approaches, the impact of this procedure on the convergence and speed of FL remains to date under-investigated. In this work we introduce a novel decomposition theorem for the convergence of FL, allowing to clearly quantify the impact of client sampling on the global model update. Contrarily to previous convergence analyses, our theorem provides the exact decomposition of a given convergence step, thus enabling accurate considerations about the role of client sampling and heterogeneity. First, we provide a theoretical ground for previously reported results on the relationship between FL convergence and the variance of the aggregation weights. Second, we prove for the first time that the quality of FL convergence is also impacted by the resulting covariance between aggregation weights. Third, we establish that the sum of the aggregation weights is another source of slow-down and should be equal to 1 to improve FL convergence speed. Our theory is general, and is here applied to Multinomial Distribution (MD) and Uniform sampling, the two default client sampling in FL, and demonstrated through a series of experiments in non-iid and unbalanced scenarios. Our results suggest that MD sampling should be used as default sampling scheme, due to the resilience to the changes in data ratio during the learning process, while Uniform sampling is superior only in the special case when clients have the same amount of data.
Accelerating SpMM Kernel with Cache-First Edge Sampling for Graph Neural Networks
Apr 23, 2021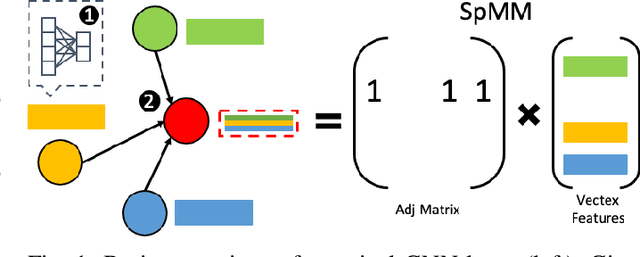
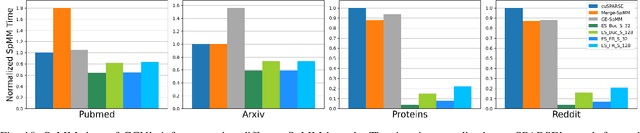
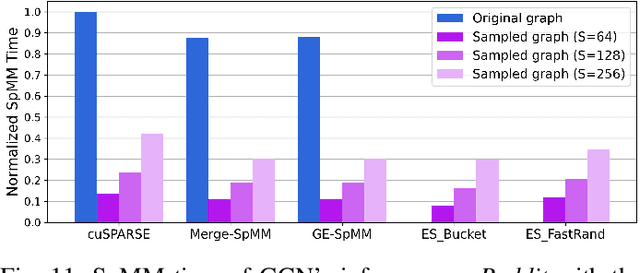
Graph neural networks (GNNs), an emerging deep learning model class, can extract meaningful representations from highly expressive graph-structured data and are therefore gaining popularity for wider ranges of applications. However, current GNNs suffer from the poor performance of their sparse-dense matrix multiplication (SpMM) operator, even when using powerful GPUs. Our analysis shows that 95% of the inference time could be spent on SpMM when running popular GNN models on NVIDIA's advanced V100 GPU. Such SpMM performance bottleneck hinders GNNs' applicability to large-scale problems or the development of more sophisticated GNN models. To address this inference time bottleneck, we introduce ES-SpMM, a cache-first edge sampling mechanism and codesigned SpMM kernel. ES-SpMM uses edge sampling to downsize the graph to fit into GPU's shared memory. It thus reduces the computation cost and improves SpMM's cache locality. To evaluate ES-SpMM's performance, we integrated it with a popular GNN framework, DGL, and tested it using representative GNN models and datasets. Our results show that ES-SpMM outperforms the highly optimized cuSPARSE SpMM kernel by up to 4.35x with no accuracy loss and by 45.3x with less than a 1% accuracy loss.
SETGAN: Scale and Energy Trade-off GANs for Image Applications on Mobile Platforms
Mar 23, 2021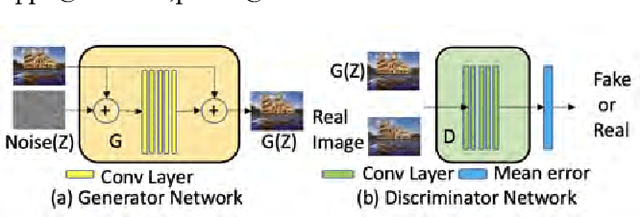

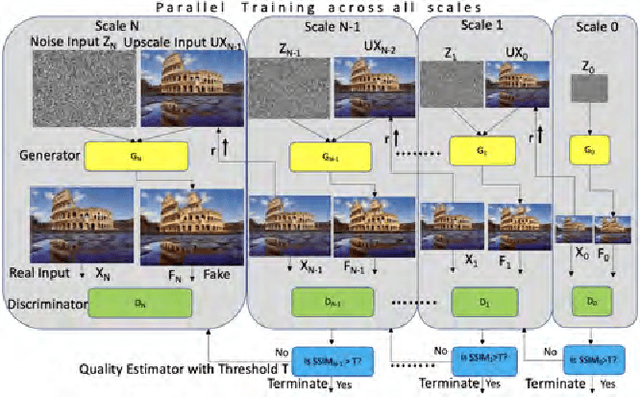
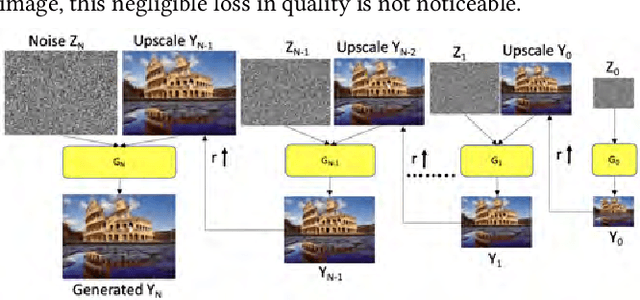
We consider the task of photo-realistic unconditional image generation (generate high quality, diverse samples that carry the same visual content as the image) on mobile platforms using Generative Adversarial Networks (GANs). In this paper, we propose a novel approach to trade-off image generation accuracy of a GAN for the energy consumed (compute) at run-time called Scale-Energy Tradeoff GAN (SETGAN). GANs usually take a long time to train and consume a huge memory hence making it difficult to run on edge devices. The key idea behind SETGAN for an image generation task is for a given input image, we train a GAN on a remote server and use the trained model on edge devices. We use SinGAN, a single image unconditional generative model, that contains a pyramid of fully convolutional GANs, each responsible for learning the patch distribution at a different scale of the image. During the training process, we determine the optimal number of scales for a given input image and the energy constraint from the target edge device. Results show that with SETGAN's unique client-server-based architecture, we were able to achieve a 56% gain in energy for a loss of 3% to 12% SSIM accuracy. Also, with the parallel multi-scale training, we obtain around 4x gain in training time on the server.
Sonority Measurement Using System, Source, and Suprasegmental Information
Jul 01, 2021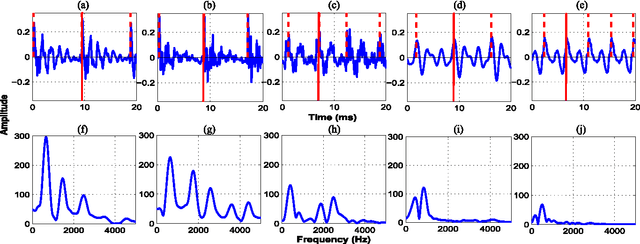
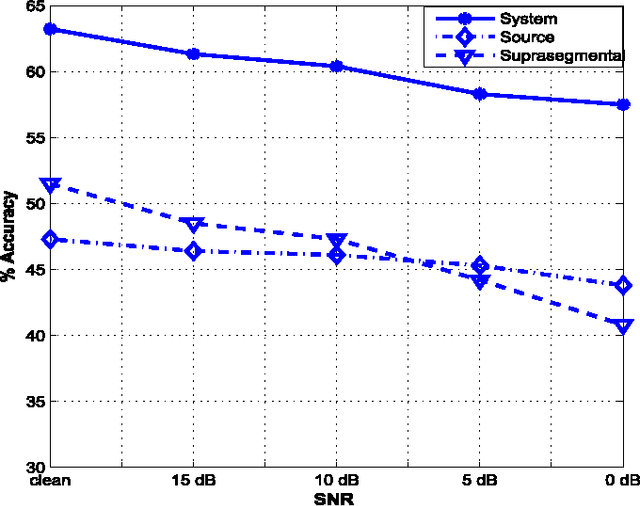
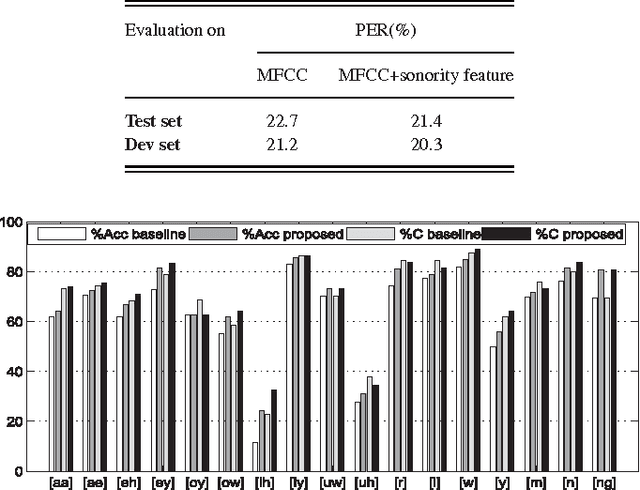
Sonorant sounds are characterized by regions with prominent formant structure, high energy and high degree of periodicity. In this work, the vocal-tract system, excitation source and suprasegmental features derived from the speech signal are analyzed to measure the sonority information present in each of them. Vocal-tract system information is extracted from the Hilbert envelope of numerator of group delay function. It is derived from zero time windowed speech signal that provides better resolution of the formants. A five-dimensional feature set is computed from the estimated formants to measure the prominence of the spectral peaks. A feature representing strength of excitation is derived from the Hilbert envelope of linear prediction residual, which represents the source information. Correlation of speech over ten consecutive pitch periods is used as the suprasegmental feature representing periodicity information. The combination of evidences from the three different aspects of speech provides better discrimination among different sonorant classes, compared to the baseline MFCC features. The usefulness of the proposed sonority feature is demonstrated in the tasks of phoneme recognition and sonorant classification.
AdaXpert: Adapting Neural Architecture for Growing Data
Jul 01, 2021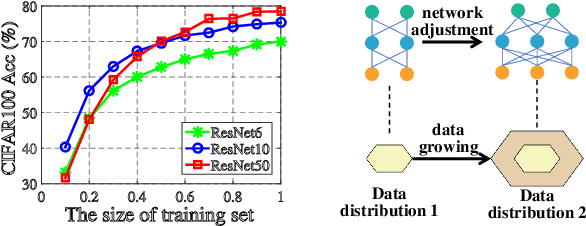
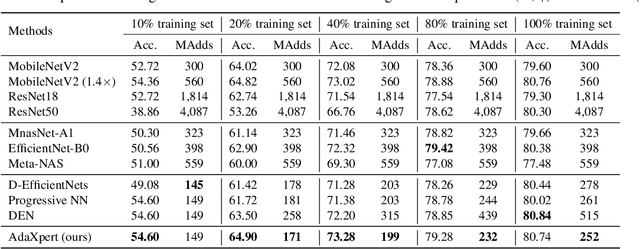
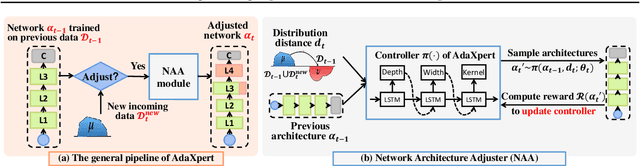
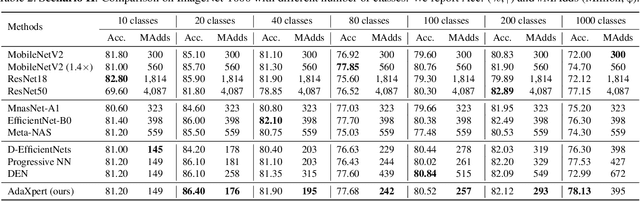
In real-world applications, data often come in a growing manner, where the data volume and the number of classes may increase dynamically. This will bring a critical challenge for learning: given the increasing data volume or the number of classes, one has to instantaneously adjust the neural model capacity to obtain promising performance. Existing methods either ignore the growing nature of data or seek to independently search an optimal architecture for a given dataset, and thus are incapable of promptly adjusting the architectures for the changed data. To address this, we present a neural architecture adaptation method, namely Adaptation eXpert (AdaXpert), to efficiently adjust previous architectures on the growing data. Specifically, we introduce an architecture adjuster to generate a suitable architecture for each data snapshot, based on the previous architecture and the different extent between current and previous data distributions. Furthermore, we propose an adaptation condition to determine the necessity of adjustment, thereby avoiding unnecessary and time-consuming adjustments. Extensive experiments on two growth scenarios (increasing data volume and number of classes) demonstrate the effectiveness of the proposed method.
Worst-Case Polynomial-Time Exact MAP Inference on Discrete Models with Global Dependencies
Dec 27, 2019
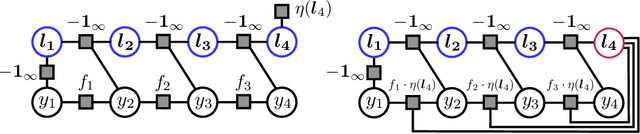
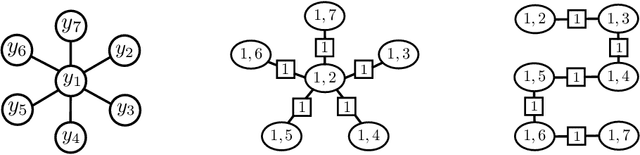
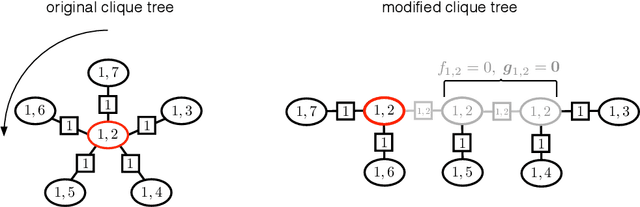
Considering the worst-case scenario, junction tree algorithm remains the most efficient and general solution for exact MAP inference on discrete graphical models. Unfortunately, its main tractability assumption requires the treewidth of a corresponding MRF to be bounded strongly limiting the range of admissible applications. In fact, many practical problems in the area of structured prediction require modelling of global dependencies by either directly introducing global factors or enforcing global constraints on the prediction variables. This, however, always results in a fully-connected graph making exact inference by means of this algorithm intractable. Nevertheless, depending on the structure of the global factors, we can further relax the conditions for an efficient inference. In this paper we reformulate the work in [1] and present a better way to establish the theory also extending the set of handleable problem instances for free - since it requires only a simple modification of the originally presented algorithm. To demonstrate that this extension is not of a purely theoretical interest we identify one further use case in the context of generalisation bounds for structured learning which cannot be handled by the previous formulation. Finally, we accordingly adjust the theoretical guarantees that the modified algorithm always finds an optimal solution in polynomial time.
Automated User Experience Testing through Multi-Dimensional Performance Impact Analysis
Apr 08, 2021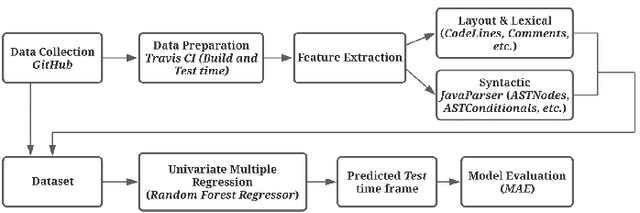
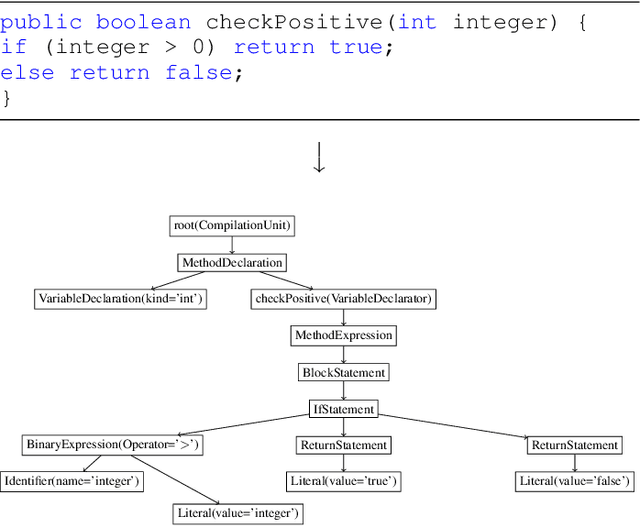
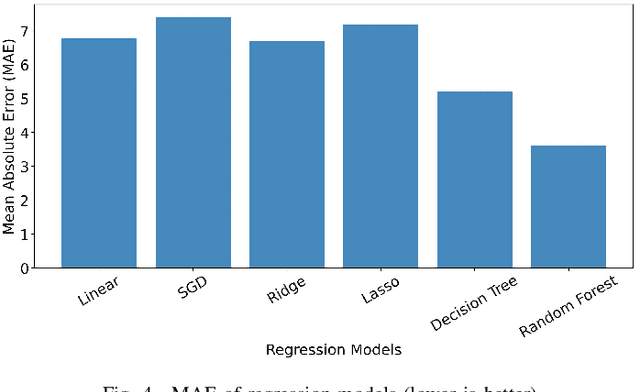
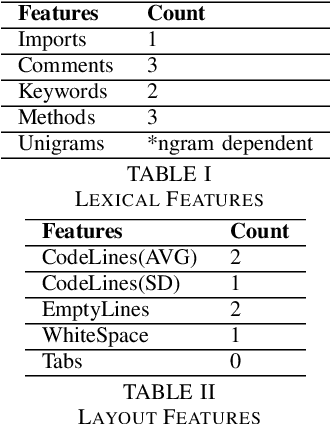
Although there are many automated software testing suites, they usually focus on unit, system, and interface testing. However, especially software updates such as new security features have the potential to diminish user experience. In this paper, we propose a novel automated user experience testing methodology that learns how code changes impact the time unit and system tests take, and extrapolate user experience changes based on this information. Such a tool can be integrated into existing continuous integration pipelines, and it provides software teams immediate user experience feedback. We construct a feature set from lexical, layout, and syntactic characteristics of the code, and using Abstract Syntax Tree-Based Embeddings, we can calculate the approximate semantic distance to feed into a machine learning algorithm. In our experiments, we use several regression methods to estimate the time impact of software updates. Our open-source tool achieved 3.7% mean absolute error rate with a random forest regressor.