 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Continuous-Time Trajectory Optimization for Decentralized Multi-Robot Navigation
Sep 05, 2019

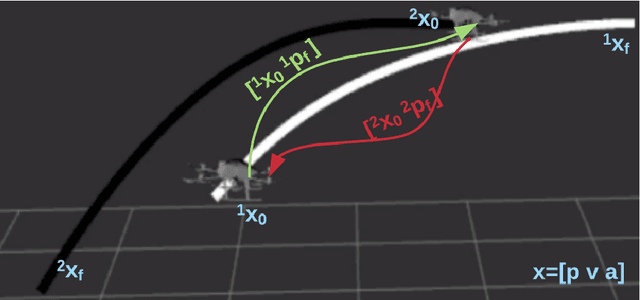
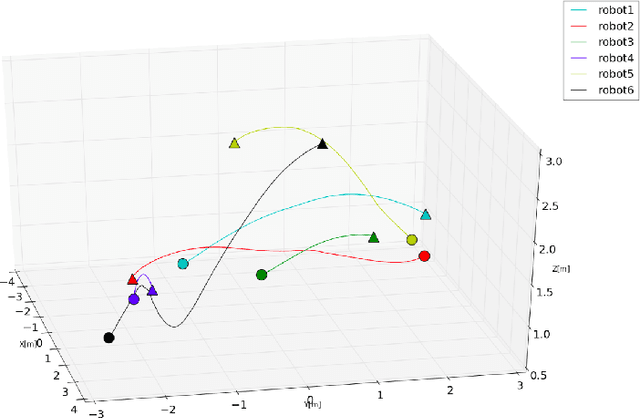
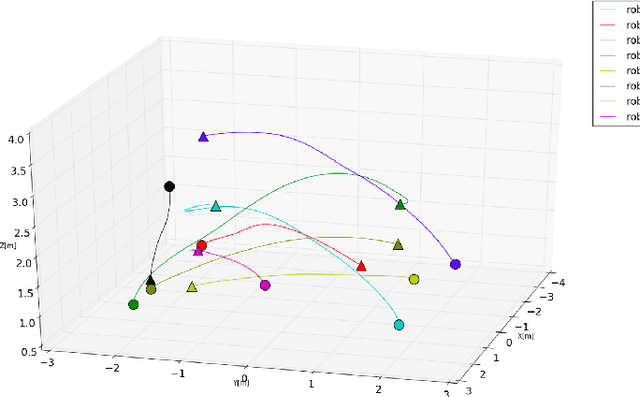
Multi-robot systems have begun to permeate into a variety of different fields, but collision-free navigation in a decentralized manner is still an arduous task. Typically, the navigation of high speed multi-robot systems demands replanning of trajectories to avoid collisions with one another. This paper presents an online replanning algorithm for trajectory optimization in labeled multi-robot scenarios. With reliable communication of states among robots, each robot predicts a smooth continuous-time trajectory for every other remaining robots. Based on the knowledge of these predicted trajectories, each robot then plans a collision-free trajectory for itself. The collision-free trajectory optimization problem is cast as a non linear program (NLP) by exploiting polynomial based trajectory generation. The algorithm was tested in simulations on Gazebo with aerial robots.
Anomaly Detection in Medical Imaging -- A Mini Review
Aug 25, 2021
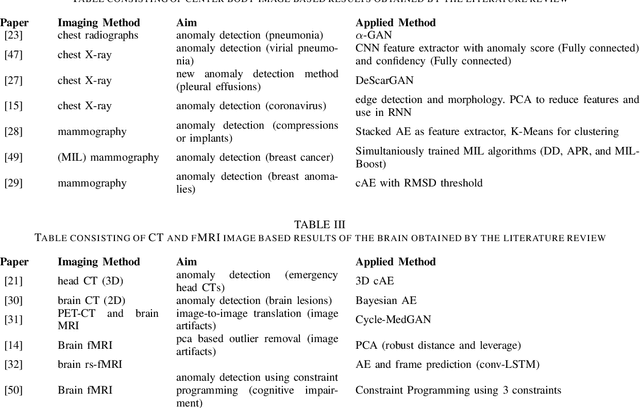
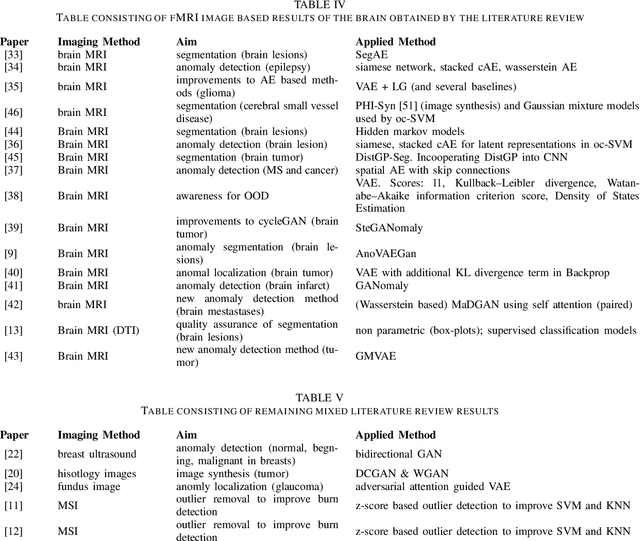
The increasing digitization of medical imaging enables machine learning based improvements in detecting, visualizing and segmenting lesions, easing the workload for medical experts. However, supervised machine learning requires reliable labelled data, which is is often difficult or impossible to collect or at least time consuming and thereby costly. Therefore methods requiring only partly labeled data (semi-supervised) or no labeling at all (unsupervised methods) have been applied more regularly. Anomaly detection is one possible methodology that is able to leverage semi-supervised and unsupervised methods to handle medical imaging tasks like classification and segmentation. This paper uses a semi-exhaustive literature review of relevant anomaly detection papers in medical imaging to cluster into applications, highlight important results, establish lessons learned and give further advice on how to approach anomaly detection in medical imaging. The qualitative analysis is based on google scholar and 4 different search terms, resulting in 120 different analysed papers. The main results showed that the current research is mostly motivated by reducing the need for labelled data. Also, the successful and substantial amount of research in the brain MRI domain shows the potential for applications in further domains like OCT and chest X-ray.
First Exit Time Analysis of Stochastic Gradient Descent Under Heavy-Tailed Gradient Noise
Jun 21, 2019
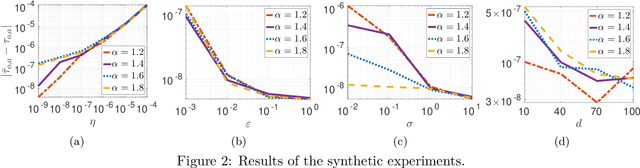
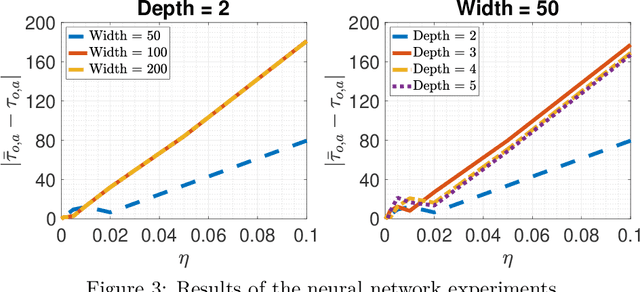
Stochastic gradient descent (SGD) has been widely used in machine learning due to its computational efficiency and favorable generalization properties. Recently, it has been empirically demonstrated that the gradient noise in several deep learning settings admits a non-Gaussian, heavy-tailed behavior. This suggests that the gradient noise can be modeled by using $\alpha$-stable distributions, a family of heavy-tailed distributions that appear in the generalized central limit theorem. In this context, SGD can be viewed as a discretization of a stochastic differential equation (SDE) driven by a L\'{e}vy motion, and the metastability results for this SDE can then be used for illuminating the behavior of SGD, especially in terms of `preferring wide minima'. While this approach brings a new perspective for analyzing SGD, it is limited in the sense that, due to the time discretization, SGD might admit a significantly different behavior than its continuous-time limit. Intuitively, the behaviors of these two systems are expected to be similar to each other only when the discretization step is sufficiently small; however, to the best of our knowledge, there is no theoretical understanding on how small the step-size should be chosen in order to guarantee that the discretized system inherits the properties of the continuous-time system. In this study, we provide formal theoretical analysis where we derive explicit conditions for the step-size such that the metastability behavior of the discrete-time system is similar to its continuous-time limit. We show that the behaviors of the two systems are indeed similar for small step-sizes and we identify how the error depends on the algorithm and problem parameters. We illustrate our results with simulations on a synthetic model and neural networks.
Continuous Deep Q-Learning with Simulator for Stabilization of Uncertain Discrete-Time Systems
Jan 13, 2021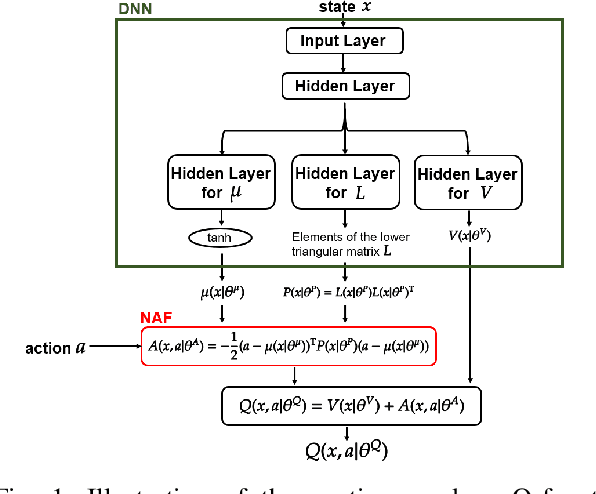
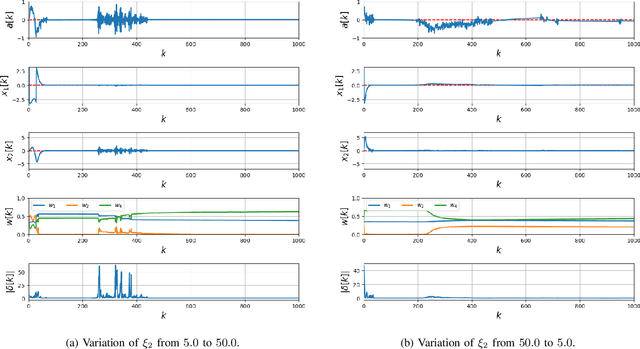
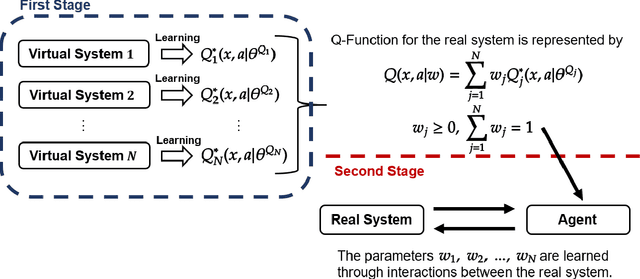
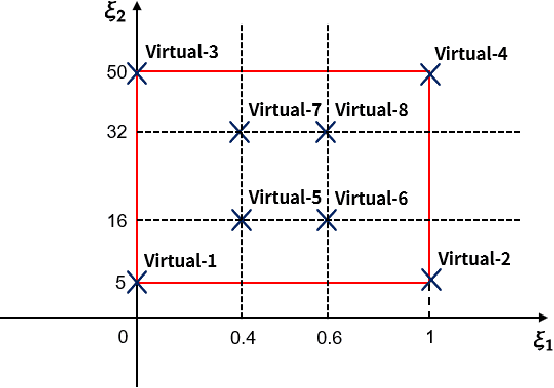
Applications of reinforcement learning (RL) to stabilization problems of real systems are restricted since an agent needs many experiences to learn an optimal policy and may determine dangerous actions during its exploration. If we know a mathematical model of a real system, a simulator is useful because it predicates behaviors of the real system using the mathematical model with a given system parameter vector. We can collect many experiences more efficiently than interactions with the real system. However, it is difficult to identify the system parameter vector accurately. If we have an identification error, experiences obtained by the simulator may degrade the performance of the learned policy. Thus, we propose a practical RL algorithm that consists of two stages. At the first stage, we choose multiple system parameter vectors. Then, we have a mathematical model for each system parameter vector, which is called a virtual system. We obtain optimal Q-functions for multiple virtual systems using the continuous deep Q-learning algorithm. At the second stage, we represent a Q-function for the real system by a linear approximated function whose basis functions are optimal Q-functions learned at the first stage. The agent learns the Q-function through interactions with the real system online. By numerical simulations, we show the usefulness of our proposed method.
QUINT: Node embedding using network hashing
Sep 11, 2021
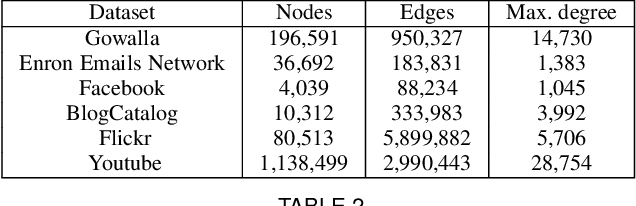
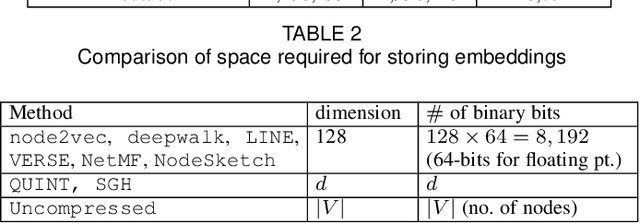
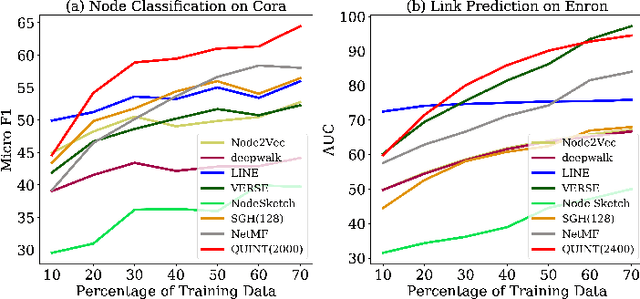
Representation learning using network embedding has received tremendous attention due to its efficacy to solve downstream tasks. Popular embedding methods (such as deepwalk, node2vec, LINE) are based on a neural architecture, thus unable to scale on large networks both in terms of time and space usage. Recently, we proposed BinSketch, a sketching technique for compressing binary vectors to binary vectors. In this paper, we show how to extend BinSketch and use it for network hashing. Our proposal named QUINT is built upon BinSketch, and it embeds nodes of a sparse network onto a low-dimensional space using simple bi-wise operations. QUINT is the first of its kind that provides tremendous gain in terms of speed and space usage without compromising much on the accuracy of the downstream tasks. Extensive experiments are conducted to compare QUINT with seven state-of-the-art network embedding methods for two end tasks - link prediction and node classification. We observe huge performance gain for QUINT in terms of speedup (up to 7000x) and space saving (up to 80x) due to its bit-wise nature to obtain node embedding. Moreover, QUINT is a consistent top-performer for both the tasks among the baselines across all the datasets. Our empirical observations are backed by rigorous theoretical analysis to justify the effectiveness of QUINT. In particular, we prove that QUINT retains enough structural information which can be used further to approximate many topological properties of networks with high confidence.
Achieving Small Test Error in Mildly Overparameterized Neural Networks
Apr 24, 2021Recent theoretical works on over-parameterized neural nets have focused on two aspects: optimization and generalization. Many existing works that study optimization and generalization together are based on neural tangent kernel and require a very large width. In this work, we are interested in the following question: for a binary classification problem with two-layer mildly over-parameterized ReLU network, can we find a point with small test error in polynomial time? We first show that the landscape of loss functions with explicit regularization has the following property: all local minima and certain other points which are only stationary in certain directions achieve small test error. We then prove that for convolutional neural nets, there is an algorithm which finds one of these points in polynomial time (in the input dimension and the number of data points). In addition, we prove that for a fully connected neural net, with an additional assumption on the data distribution, there is a polynomial time algorithm.
Adaptive Inducing Points Selection For Gaussian Processes
Jul 21, 2021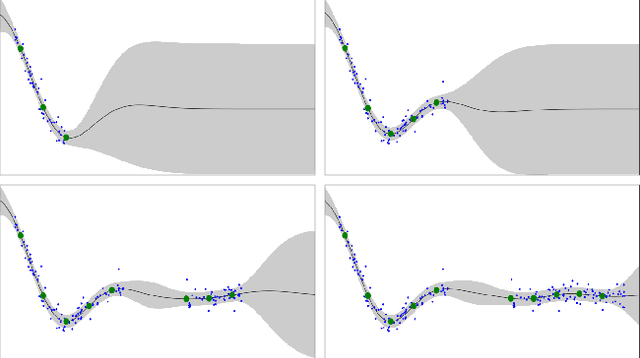
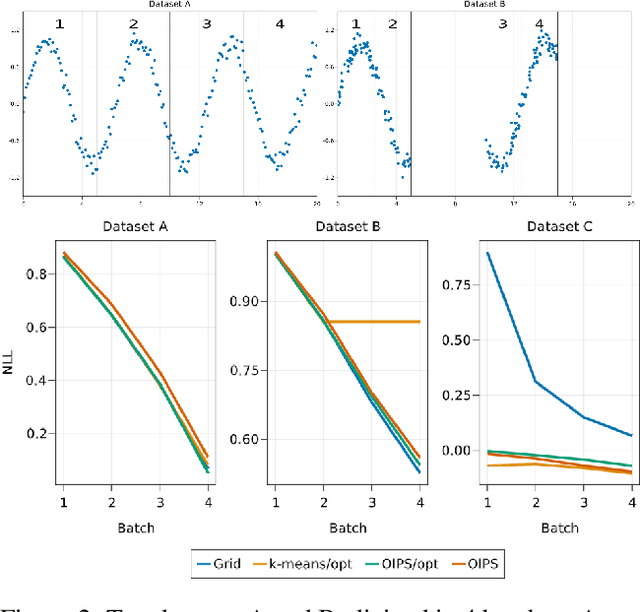
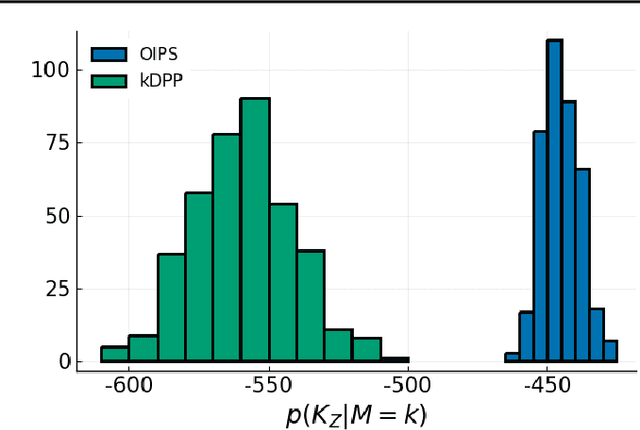
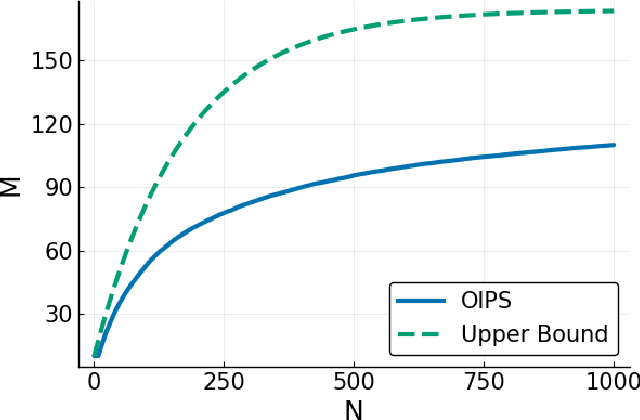
Gaussian Processes (\textbf{GPs}) are flexible non-parametric models with strong probabilistic interpretation. While being a standard choice for performing inference on time series, GPs have few techniques to work in a streaming setting. \cite{bui2017streaming} developed an efficient variational approach to train online GPs by using sparsity techniques: The whole set of observations is approximated by a smaller set of inducing points (\textbf{IPs}) and moved around with new data. Both the number and the locations of the IPs will affect greatly the performance of the algorithm. In addition to optimizing their locations, we propose to adaptively add new points, based on the properties of the GP and the structure of the data.
MMGET: A Markov model for generalized evidence theory
May 12, 2021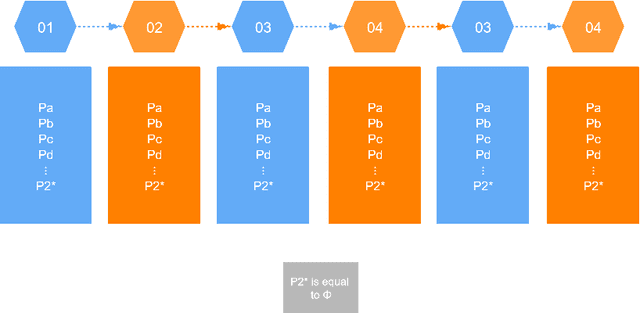
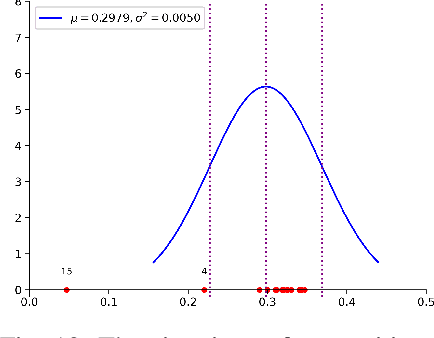
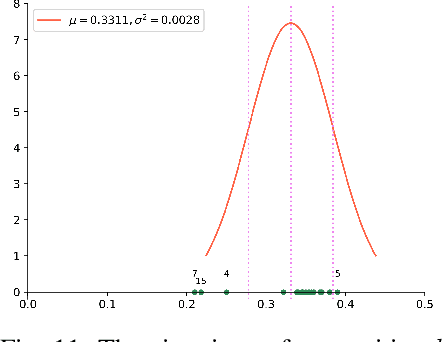
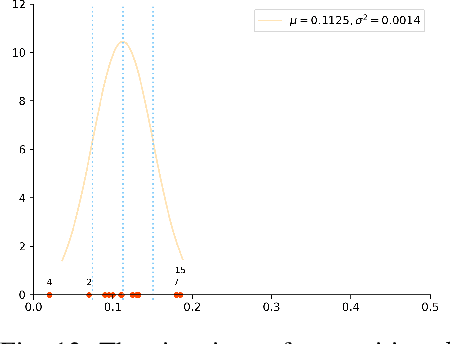
In real life, lots of information merges from time to time. To appropriately describe the actual situations, lots of theories have been proposed. Among them, Dempster-Shafer evidence theory is a very useful tool in managing uncertain information. To better adapt to complex situations of open world, a generalized evidence theory is designed. However, everything occurs in sequence and owns some underlying relationships with each other. In order to further embody the details of information and better conforms to situations of real world, a Markov model is introduced into the generalized evidence theory which helps extract complete information volume from evidence provided. Besides, some numerical examples is offered to verify the correctness and rationality of the proposed method.
ConvTimeNet: A Pre-trained Deep Convolutional Neural Network for Time Series Classification
May 02, 2019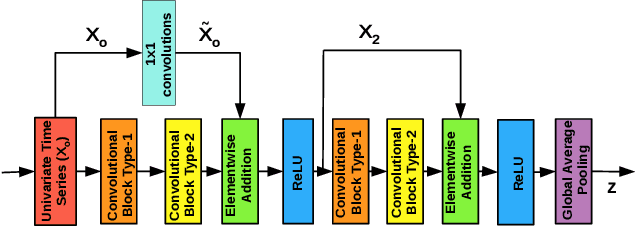
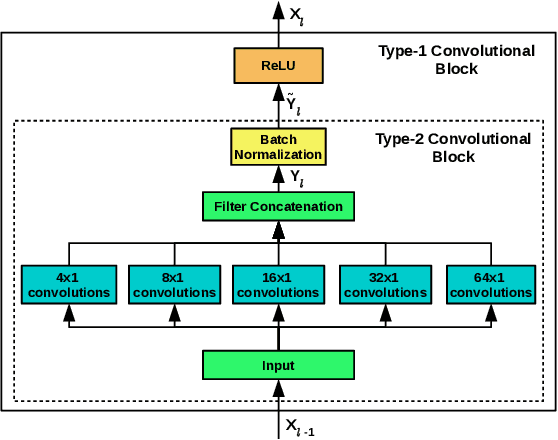
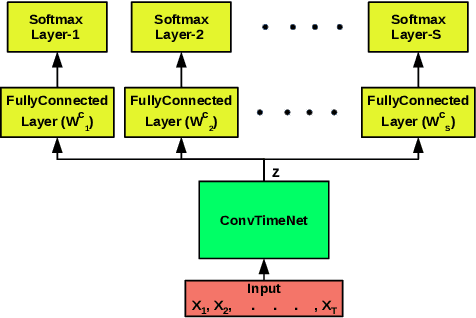
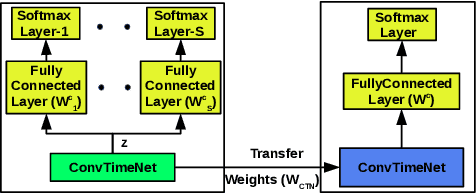
Training deep neural networks often requires careful hyper-parameter tuning and significant computational resources. In this paper, we propose ConvTimeNet (CTN): an off-the-shelf deep convolutional neural network (CNN) trained on diverse univariate time series classification (TSC) source tasks. Once trained, CTN can be easily adapted to new TSC target tasks via a small amount of fine-tuning using labeled instances from the target tasks. We note that the length of convolutional filters is a key aspect when building a pre-trained model that can generalize to time series of different lengths across datasets. To achieve this, we incorporate filters of multiple lengths in all convolutional layers of CTN to capture temporal features at multiple time scales. We consider all 65 datasets with time series of lengths up to 512 points from the UCR TSC Benchmark for training and testing transferability of CTN: We train CTN on a randomly chosen subset of 24 datasets using a multi-head approach with a different softmax layer for each training dataset, and study generalizability and transferability of the learned filters on the remaining 41 TSC datasets. We observe significant gains in classification accuracy as well as computational efficiency when using pre-trained CTN as a starting point for subsequent task-specific fine-tuning compared to existing state-of-the-art TSC approaches. We also provide qualitative insights into the working of CTN by: i) analyzing the activations and filters of first convolution layer suggesting the filters in CTN are generically useful, ii) analyzing the impact of the design decision to incorporate multiple length decisions, and iii) finding regions of time series that affect the final classification decision via occlusion sensitivity analysis.
Rethinking Perturbations in Encoder-Decoders for Fast Training
Apr 05, 2021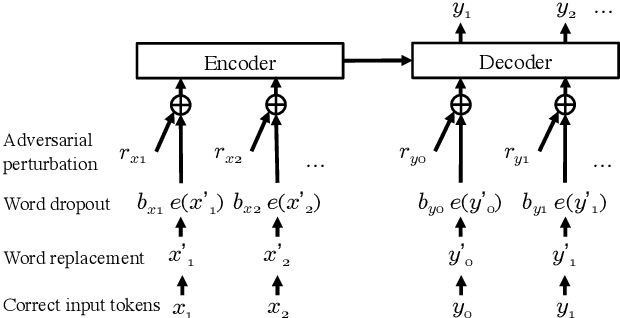
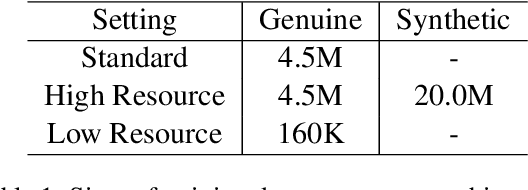
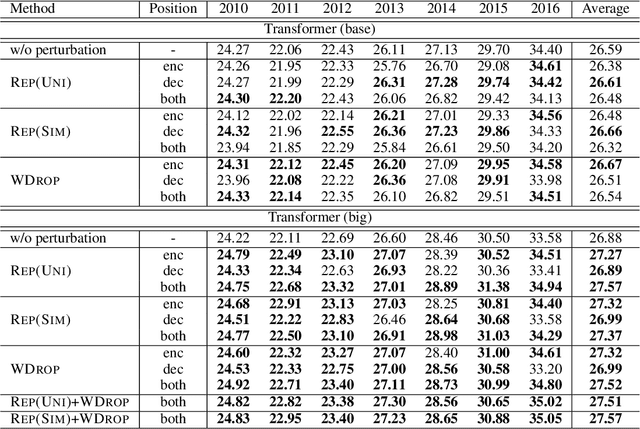
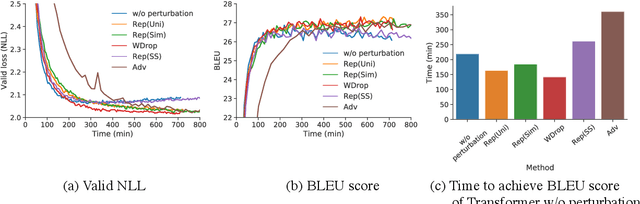
We often use perturbations to regularize neural models. For neural encoder-decoders, previous studies applied the scheduled sampling (Bengio et al., 2015) and adversarial perturbations (Sato et al., 2019) as perturbations but these methods require considerable computational time. Thus, this study addresses the question of whether these approaches are efficient enough for training time. We compare several perturbations in sequence-to-sequence problems with respect to computational time. Experimental results show that the simple techniques such as word dropout (Gal and Ghahramani, 2016) and random replacement of input tokens achieve comparable (or better) scores to the recently proposed perturbations, even though these simple methods are faster. Our code is publicly available at https://github.com/takase/rethink_perturbations.