 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-TIDE: Fast, Structure-Preserving Motion Forecasting from Event Sequences
Mar 29, 2026Event-based cameras capture visual information as asynchronous streams of per-pixel brightness changes, generating sparse, temporally precise data. Compared to conventional frame-based sensors, they offer significant advantages in capturing high-speed dynamics while consuming substantially less power. Predicting future event representations from past observations is an important problem, enabling downstream tasks such as future semantic segmentation or object tracking without requiring access to future sensor measurements. While recent state-of-the-art approaches achieve strong performance, they often rely on computationally heavy backbones and, in some cases, large-scale pretraining, limiting their applicability in resource-constrained scenarios. In this work, we introduce E-TIDE, a lightweight, end-to-end trainable architecture for event-tensor prediction that is designed to operate efficiently without large-scale pretraining. Our approach employs the TIDE module (Temporal Interaction for Dynamic Events), motivated by efficient spatiotemporal interaction design for sparse event tensors, to capture temporal dependencies via large-kernel mixing and activity-aware gating while maintaining low computational complexity. Experiments on standard event-based datasets demonstrate that our method achieves competitive performance with significantly reduced model size and training requirements, making it well-suited for real-time deployment under tight latency and memory budgets.
QUINT: Node embedding using network hashing
Sep 11, 2021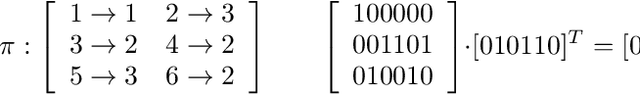
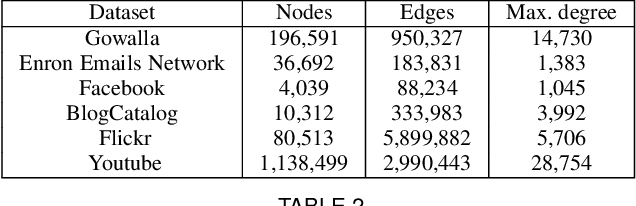
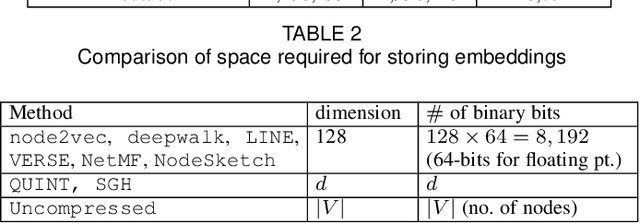
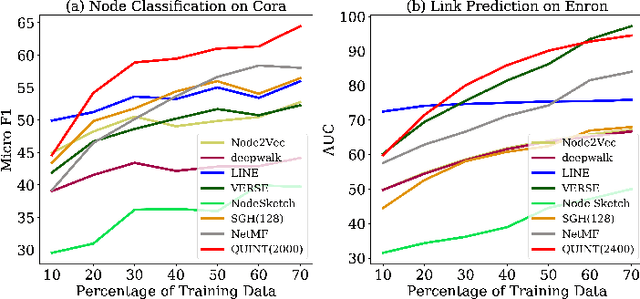
Representation learning using network embedding has received tremendous attention due to its efficacy to solve downstream tasks. Popular embedding methods (such as deepwalk, node2vec, LINE) are based on a neural architecture, thus unable to scale on large networks both in terms of time and space usage. Recently, we proposed BinSketch, a sketching technique for compressing binary vectors to binary vectors. In this paper, we show how to extend BinSketch and use it for network hashing. Our proposal named QUINT is built upon BinSketch, and it embeds nodes of a sparse network onto a low-dimensional space using simple bi-wise operations. QUINT is the first of its kind that provides tremendous gain in terms of speed and space usage without compromising much on the accuracy of the downstream tasks. Extensive experiments are conducted to compare QUINT with seven state-of-the-art network embedding methods for two end tasks - link prediction and node classification. We observe huge performance gain for QUINT in terms of speedup (up to 7000x) and space saving (up to 80x) due to its bit-wise nature to obtain node embedding. Moreover, QUINT is a consistent top-performer for both the tasks among the baselines across all the datasets. Our empirical observations are backed by rigorous theoretical analysis to justify the effectiveness of QUINT. In particular, we prove that QUINT retains enough structural information which can be used further to approximate many topological properties of networks with high confidence.