 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep reinforcement learning under signal temporal logic constraints using Lagrangian relaxation
Jan 29, 2022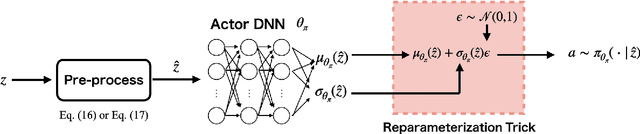
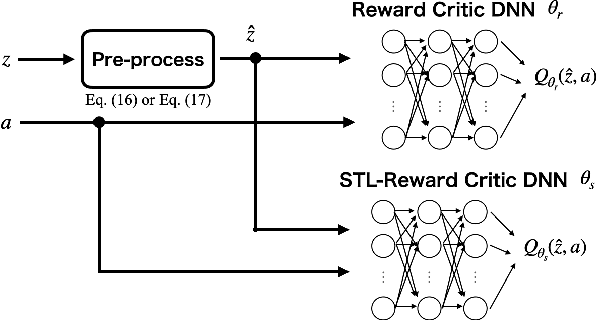
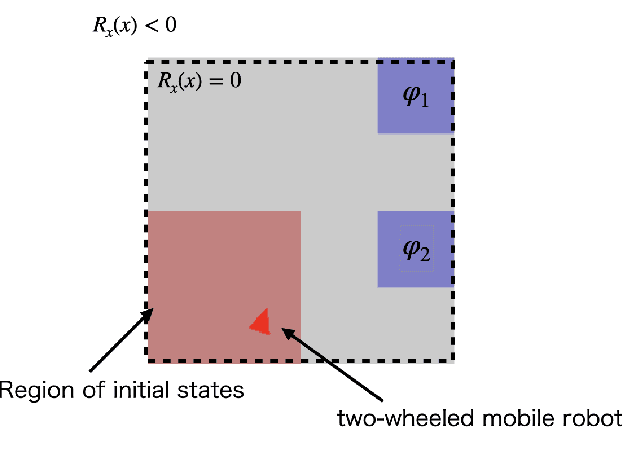
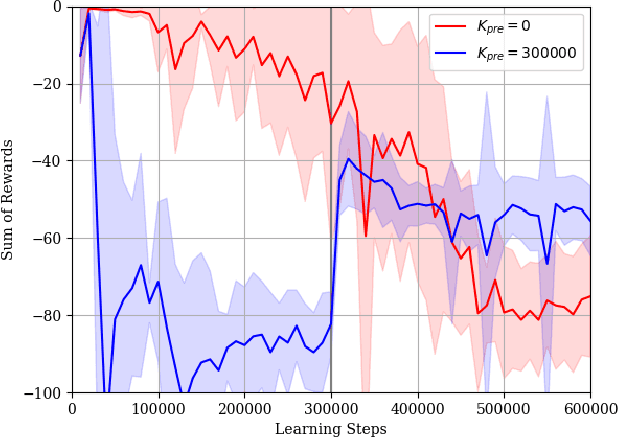
Deep reinforcement learning (DRL) has attracted much attention as an approach to solve sequential decision making problems without mathematical models of systems or environments. In general, a constraint may be imposed on the decision making. In this study, we consider the optimal decision making problems with constraints to complete temporal high-level tasks in the continuous state-action domain. We describe the constraints using signal temporal logic (STL), which is useful for time sensitive control tasks since it can specify continuous signals within a bounded time interval. To deal with the STL constraints, we introduce an extended constrained Markov decision process (CMDP), which is called a $\tau$-CMDP. We formulate the STL constrained optimal decision making problem as the $\tau$-CMDP and propose a two-phase constrained DRL algorithm using the Lagrangian relaxation method. Through simulations, we also demonstrate the learning performance of the proposed algorithm.
Deep Reinforcement Learning Based Networked Control with Network Delays for Signal Temporal Logic Specifications
Aug 03, 2021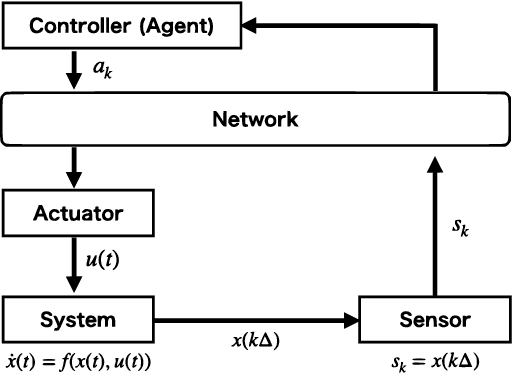
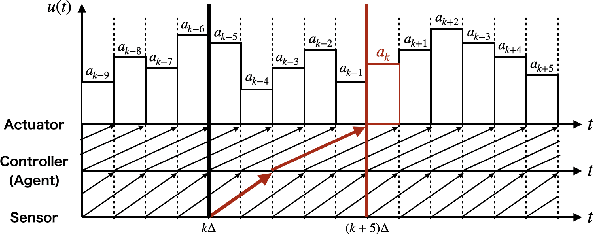
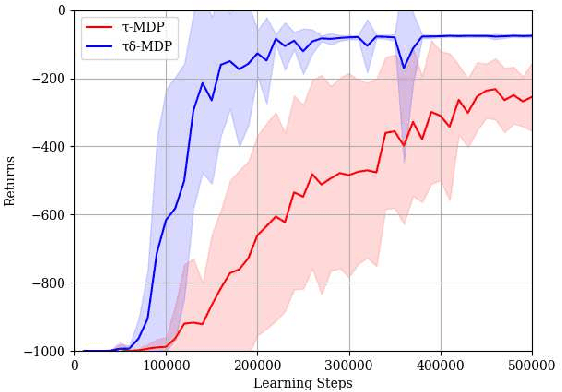
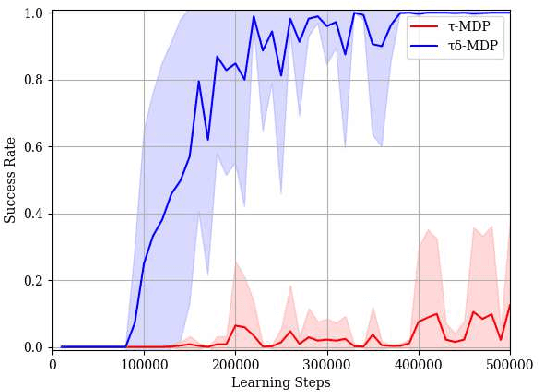
We present a novel deep reinforcement learning (DRL)-based design of a networked controller with network delays for signal temporal logic (STL) specifications. We consider the case in which both the system dynamics and network delays are unknown. Because the satisfaction of an STL formula is based not only on the current state but also on the behavior of the system, we propose an extension of the Markov decision process (MDP), which is called a $\tau\delta$-MDP, such that we can evaluate the satisfaction of the STL formula under the network delays using the $\tau\delta$-MDP. Thereafter, we construct deep neural networks based on the $\tau\delta$-MDP and propose a learning algorithm. Through simulations, we also demonstrate the learning performance of the proposed algorithm.
Continuous Deep Q-Learning with Simulator for Stabilization of Uncertain Discrete-Time Systems
Jan 13, 2021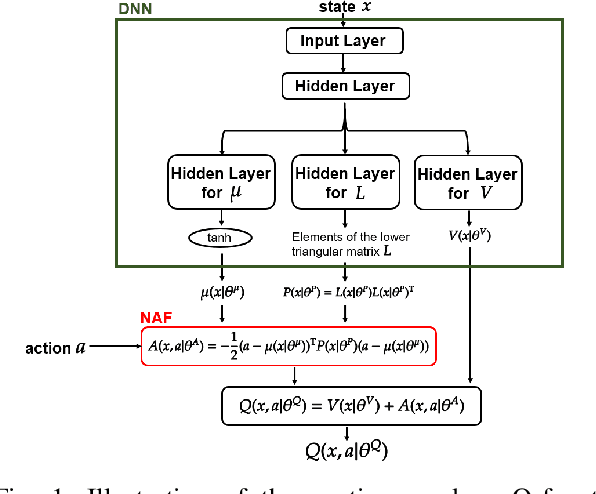
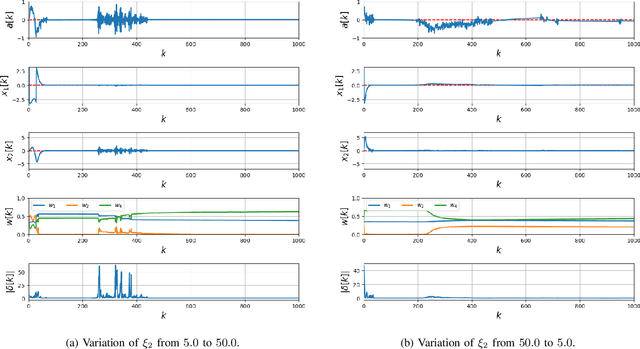
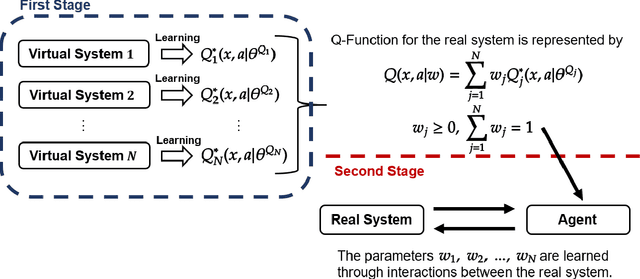
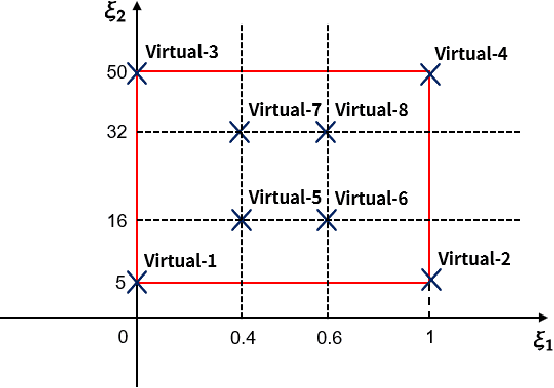
Applications of reinforcement learning (RL) to stabilization problems of real systems are restricted since an agent needs many experiences to learn an optimal policy and may determine dangerous actions during its exploration. If we know a mathematical model of a real system, a simulator is useful because it predicates behaviors of the real system using the mathematical model with a given system parameter vector. We can collect many experiences more efficiently than interactions with the real system. However, it is difficult to identify the system parameter vector accurately. If we have an identification error, experiences obtained by the simulator may degrade the performance of the learned policy. Thus, we propose a practical RL algorithm that consists of two stages. At the first stage, we choose multiple system parameter vectors. Then, we have a mathematical model for each system parameter vector, which is called a virtual system. We obtain optimal Q-functions for multiple virtual systems using the continuous deep Q-learning algorithm. At the second stage, we represent a Q-function for the real system by a linear approximated function whose basis functions are optimal Q-functions learned at the first stage. The agent learns the Q-function through interactions with the real system online. By numerical simulations, we show the usefulness of our proposed method.
Reinforcement Learning of Control Policy for Linear Temporal Logic Specifications Using Limit-Deterministic Generalized Büchi Automata
Feb 21, 2020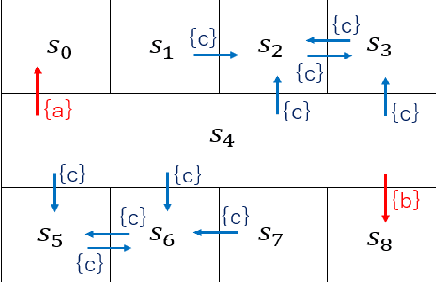
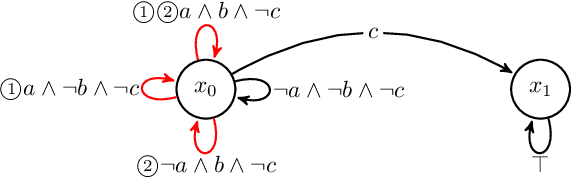
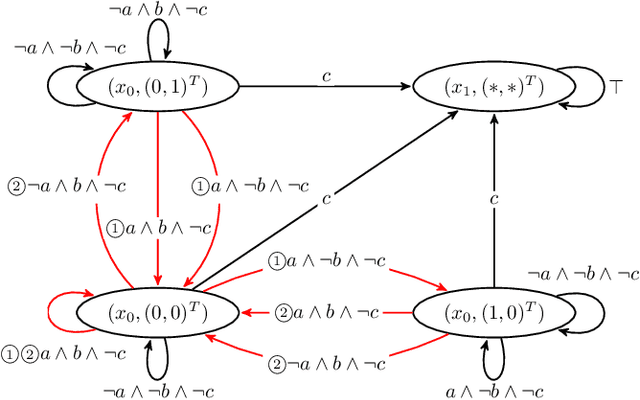
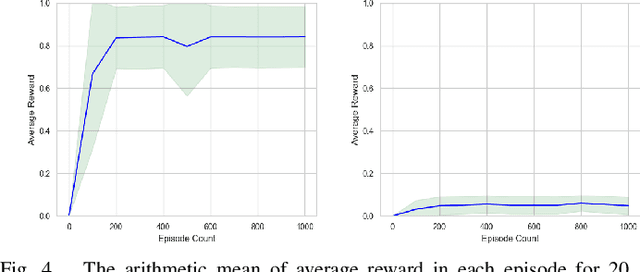
This letter proposes a novel reinforcement learning method for the synthesis of a control policy satisfying a control specification described by a linear temporal logic formula. We assume that the controlled system is modeled by a Markov decision process (MDP). We convert the specification to a limit-deterministic generalized B\"uchi automaton (LDGBA) with several accepting sets that accepts all infinite sequences satisfying the formula. The LDGBA is augmented so that it explicitly records the previous visits to accepting sets. We take a product of the augmented LDGBA and the MDP, based on which we define a reward function. The agent gets rewards whenever state transitions are in an accepting set that has not been visited for a certain number of steps. Consequently, sparsity of rewards is relaxed and optimal circulations among the accepting sets are learned. We show that the proposed method can learn an optimal policy when the discount factor is sufficiently close to one.
Networked Control of Nonlinear Systems under Partial Observation Using Continuous Deep Q-Learning
Aug 30, 2019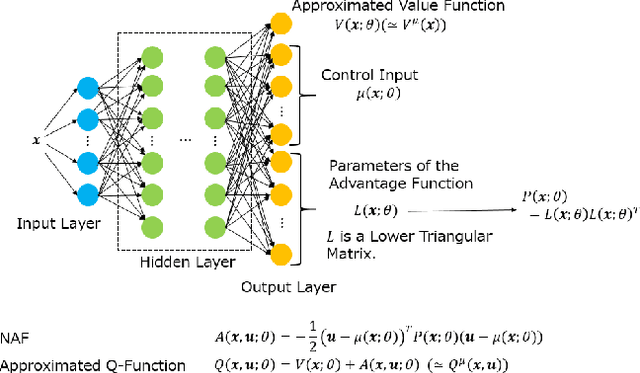
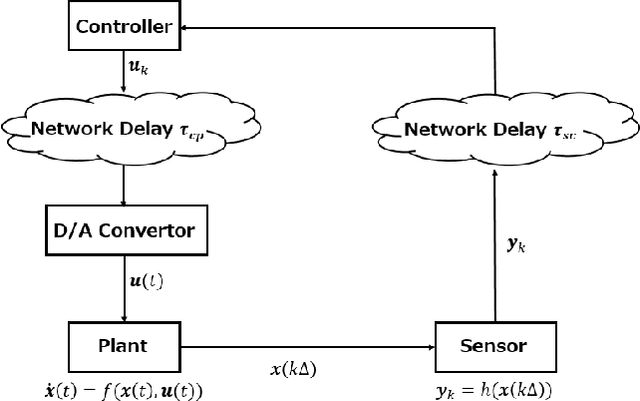
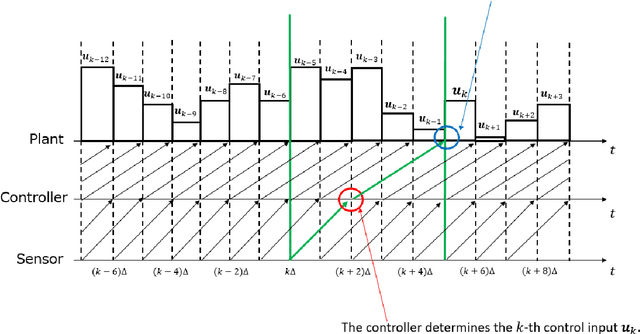

In this paper, we propose a design of a model-free networked controller for a nonlinear plant whose mathematical model is unknown. In a networked control system, the controller and plant are located away from each other and exchange data over a network, which causes network delays that may fluctuate randomly due to network routing. So, in this paper, we assume that the current network delay is not known but the maximum value of fluctuating network delays is known beforehand. Moreover, we also assume that the sensor cannot observe all state variables of the plant. Under these assumption, we apply continuous deep Q-learning to the design of the networked controller. Then, we introduce an extended state consisting of a sequence of past control inputs and outputs as inputs to the deep neural network. By simulation, it is shown that, using the extended state, the controller can learn a control policy robust to the fluctuation of the network delays under the partial observation.
Model-free Control of Chaos with Continuous Deep Q-learning
Aug 24, 2019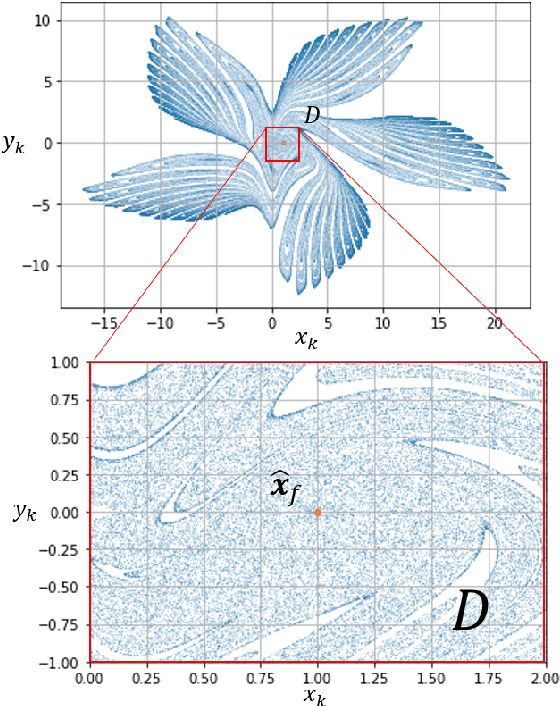
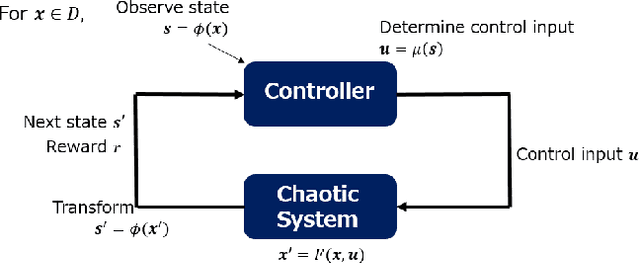
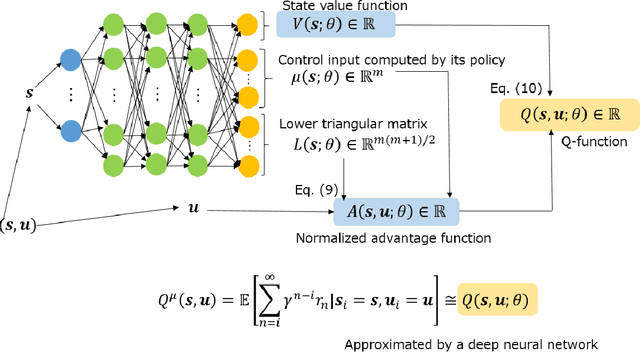
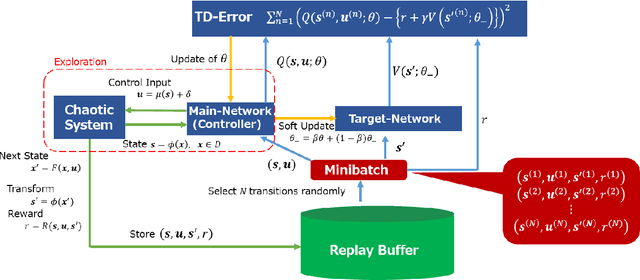
The OGY method is one of control methods for a chaotic system. In the method, we have to calculate a stabilizing periodic orbit embedded in its chaotic attractor. Thus, we cannot use this method in the case where a precise mathematical model of the chaotic system cannot be identified. In this case, the delayed feedback control proposed by Pyragas is useful. However, even in the delayed feedback control, we need the mathematical model to determine a feedback gain that stabilizes the periodic orbit. To overcome this problem, we propose a model-free reinforcement learning algorithm to the design of a controller for the chaotic system. In recent years, model-free reinforcement learning algorithms with deep neural networks have been paid much attention to. Those algorithms make it possible to control complex systems. However, it is known that model-free reinforcement learning algorithms are not efficient because learners must explore their control policies over the entire state space. Moreover, model-free reinforcement learning algorithms with deep neural networks have the disadvantage in taking much time to learn their control optimal policies. Thus, we propose a data-based control policy consisting of two steps, where we determine a region including the stabilizing periodic orbit first, and make the controller learn an optimal control policy for its stabilization. In the proposed method, the controller efficiently explores its control policy only in the region.