 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Interactive Learning for Identifying Relevant Tweets to Support Real-time Situational Awareness
Aug 01, 2019
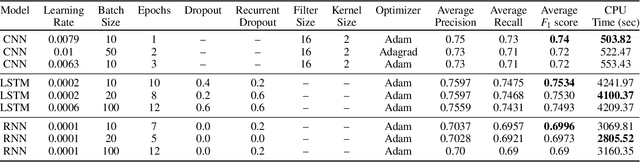
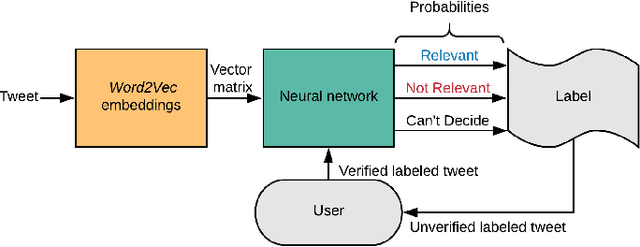
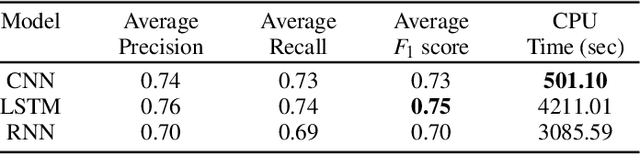
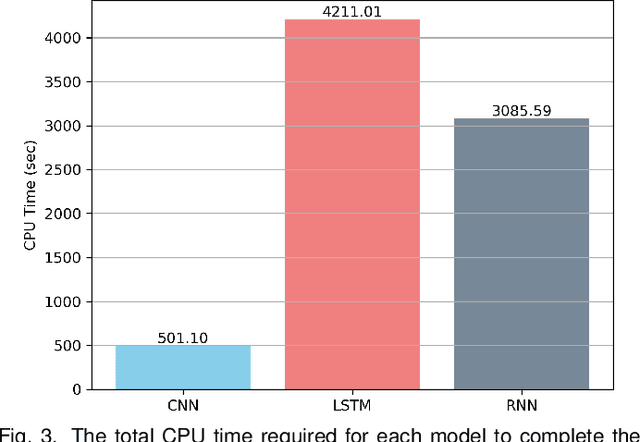
Various domain users are increasingly leveraging real-time social media data to gain rapid situational awareness. However, due to the high noise in the deluge of data, effectively determining semantically relevant information can be difficult, further complicated by the changing definition of relevancy by each end user for different events. The majority of existing methods for short text relevance classification fail to incorporate users' knowledge into the classification process. Existing methods that incorporate interactive user feedback focus on historical datasets. Therefore, classifiers cannot be interactively retrained for specific events or user-dependent needs in real-time. This limits real-time situational awareness, as streaming data that is incorrectly classified cannot be corrected immediately, permitting the possibility for important incoming data to be incorrectly classified as well. We present a novel interactive learning framework to improve the classification process in which the user iteratively corrects the relevancy of tweets in real-time to train the classification model on-the-fly for immediate predictive improvements. We computationally evaluate our classification model adapted to learn at interactive rates. Our results show that our approach outperforms state-of-the-art machine learning models. In addition, we integrate our framework with the extended Social Media Analytics and Reporting Toolkit (SMART) 2.0 system, allowing the use of our interactive learning framework within a visual analytics system tailored for real-time situational awareness. To demonstrate our framework's effectiveness, we provide domain expert feedback from first responders who used the extended SMART 2.0 system.
FOCUS: Familiar Objects in Common and Uncommon Settings
Oct 07, 2021
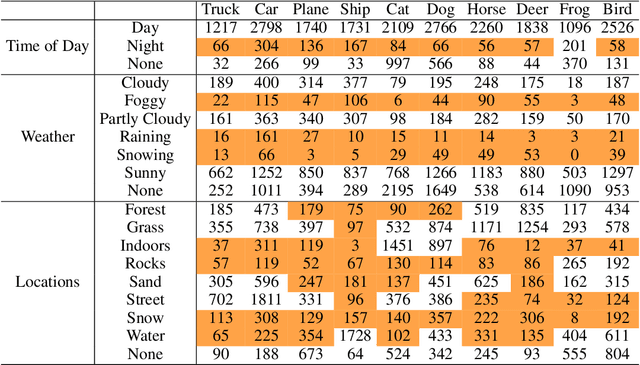

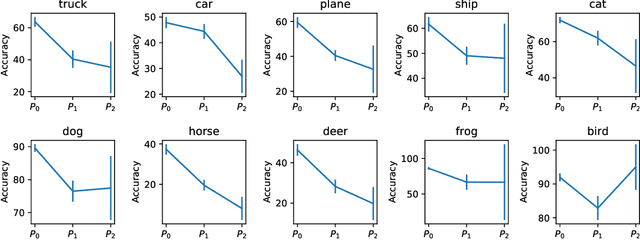
Standard training datasets for deep learning often contain objects in common settings (e.g., "a horse on grass" or "a ship in water") since they are usually collected by randomly scraping the web. Uncommon and rare settings (e.g., "a plane on water", "a car in snowy weather") are thus severely under-represented in the training data. This can lead to an undesirable bias in model predictions towards common settings and create a false sense of accuracy. In this paper, we introduce FOCUS (Familiar Objects in Common and Uncommon Settings), a dataset for stress-testing the generalization power of deep image classifiers. By leveraging the power of modern search engines, we deliberately gather data containing objects in common and uncommon settings in a wide range of locations, weather conditions, and time of day. We present a detailed analysis of the performance of various popular image classifiers on our dataset and demonstrate a clear drop in performance when classifying images in uncommon settings. By analyzing deep features of these models, we show that such errors can be due to the use of spurious features in model predictions. We believe that our dataset will aid researchers in understanding the inability of deep models to generalize well to uncommon settings and drive future work on improving their distributional robustness.
De-randomizing MCMC dynamics with the diffusion Stein operator
Oct 07, 2021

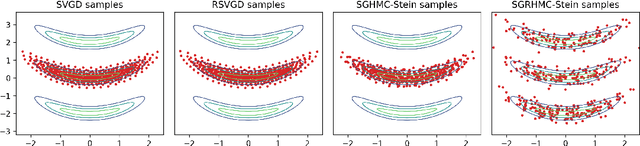
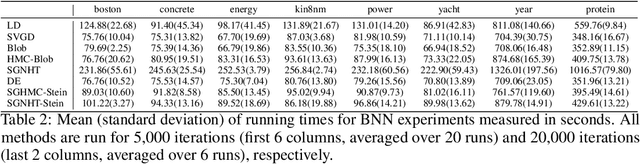
Approximate Bayesian inference estimates descriptors of an intractable target distribution - in essence, an optimization problem within a family of distributions. For example, Langevin dynamics (LD) extracts asymptotically exact samples from a diffusion process because the time evolution of its marginal distributions constitutes a curve that minimizes the KL-divergence via steepest descent in the Wasserstein space. Parallel to LD, Stein variational gradient descent (SVGD) similarly minimizes the KL, albeit endowed with a novel Stein-Wasserstein distance, by deterministically transporting a set of particle samples, thus de-randomizes the stochastic diffusion process. We propose de-randomized kernel-based particle samplers to all diffusion-based samplers known as MCMC dynamics. Following previous work in interpreting MCMC dynamics, we equip the Stein-Wasserstein space with a fiber-Riemannian Poisson structure, with the capacity of characterizing a fiber-gradient Hamiltonian flow that simulates MCMC dynamics. Such dynamics discretizes into generalized SVGD (GSVGD), a Stein-type deterministic particle sampler, with particle updates coinciding with applying the diffusion Stein operator to a kernel function. We demonstrate empirically that GSVGD can de-randomize complex MCMC dynamics, which combine the advantages of auxiliary momentum variables and Riemannian structure, while maintaining the high sample quality from an interacting particle system.
Learning to Minimize Age of Information over an Unreliable Channel with Energy Harvesting
Jun 30, 2021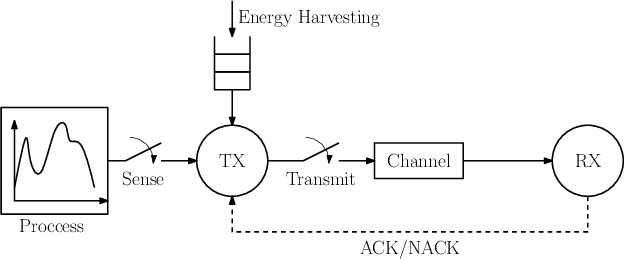
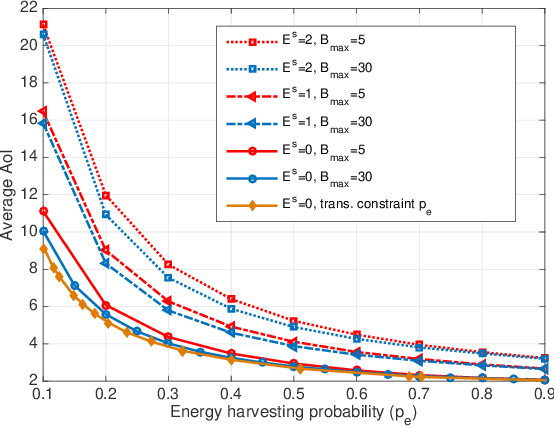
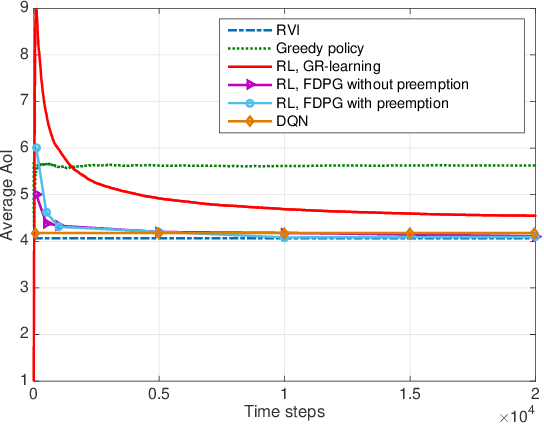
The time average expected age of information (AoI) is studied for status updates sent over an error-prone channel from an energy-harvesting transmitter with a finite-capacity battery. Energy cost of sensing new status updates is taken into account as well as the transmission energy cost better capturing practical systems. The optimal scheduling policy is first studied under the hybrid automatic repeat request (HARQ) protocol when the channel and energy harvesting statistics are known, and the existence of a threshold-based optimal policy is shown. For the case of unknown environments, average-cost reinforcement-learning algorithms are proposed that learn the system parameters and the status update policy in real-time. The effectiveness of the proposed methods is demonstrated through numerical results.
Learning Zero-sum Stochastic Games with Posterior Sampling
Sep 08, 2021In this paper, we propose Posterior Sampling Reinforcement Learning for Zero-sum Stochastic Games (PSRL-ZSG), the first online learning algorithm that achieves Bayesian regret bound of $O(HS\sqrt{AT})$ in the infinite-horizon zero-sum stochastic games with average-reward criterion. Here $H$ is an upper bound on the span of the bias function, $S$ is the number of states, $A$ is the number of joint actions and $T$ is the horizon. We consider the online setting where the opponent can not be controlled and can take any arbitrary time-adaptive history-dependent strategy. This improves the best existing regret bound of $O(\sqrt[3]{DS^2AT^2})$ by Wei et. al., 2017 under the same assumption and matches the theoretical lower bound in $A$ and $T$.
IPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition
Apr 20, 2020


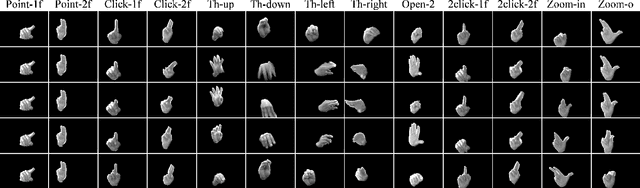
In the research community of continuous hand gesture recognition (HGR), the current publicly available datasets lack real-world elements needed to build responsive and efficient HGR systems. In this paper, we introduce a new benchmark dataset named IPN Hand with sufficient size, variation, and real-world elements able to train and evaluate deep neural networks. This dataset contains more than 4 000 gesture samples and 800 000 RGB frames from 50 distinct subjects. We design 13 different static and dynamic gestures focused on interaction with touchless screens. We especially consider the scenario when continuous gestures are performed without transition states, and when subjects perform natural movements with their hands as non-gesture actions. Gestures were collected from about 30 diverse scenes, with real-world variation in background and illumination. With our dataset, the performance of three 3D-CNN models is evaluated on the tasks of isolated and continuous real-time HGR. Furthermore, we analyze the possibility of increasing the recognition accuracy by adding multiple modalities derived from RGB frames, i.e., optical flow and semantic segmentation, while keeping the real-time performance of the 3D-CNN model. Our empirical study also provides a comparison with the publicly available nvGesture (NVIDIA) dataset. The experimental results show that the state-of-the-art ResNext-101 model decreases about 30% accuracy when using our real-world dataset, demonstrating that the IPN Hand dataset can be used as a benchmark, and may help the community to step forward in the continuous HGR. Our dataset and pre-trained models used in the evaluation are publicly available at https://github.com/GibranBenitez/IPN-hand.
Minimizing Time-to-Rank: A Learning and Recommendation Approach
May 27, 2019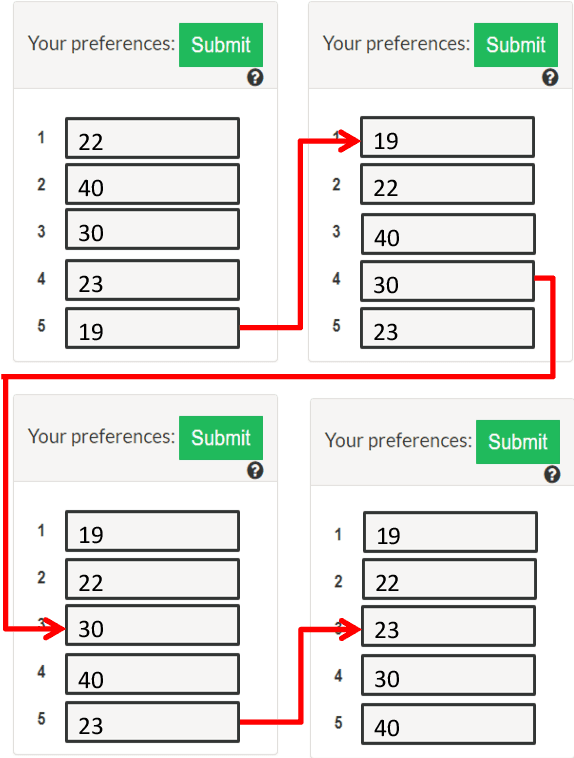
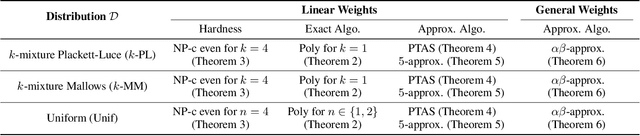


Consider the following problem faced by an online voting platform: A user is provided with a list of alternatives, and is asked to rank them in order of preference using only drag-and-drop operations. The platform's goal is to recommend an initial ranking that minimizes the time spent by the user in arriving at her desired ranking. We develop the first optimization framework to address this problem, and make theoretical as well as practical contributions. On the practical side, our experiments on Amazon Mechanical Turk provide two interesting insights about user behavior: First, that users' ranking strategies closely resemble selection or insertion sort, and second, that the time taken for a drag-and-drop operation depends linearly on the number of positions moved. These insights directly motivate our theoretical model of the optimization problem. We show that computing an optimal recommendation is NP-hard, and provide exact and approximation algorithms for a variety of special cases of the problem. Experimental evaluation on MTurk shows that, compared to a random recommendation strategy, the proposed approach reduces the (average) time-to-rank by up to 50%.
Ship Performance Monitoring using Machine-learning
Oct 07, 2021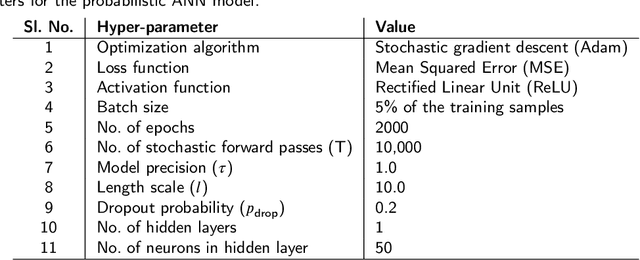
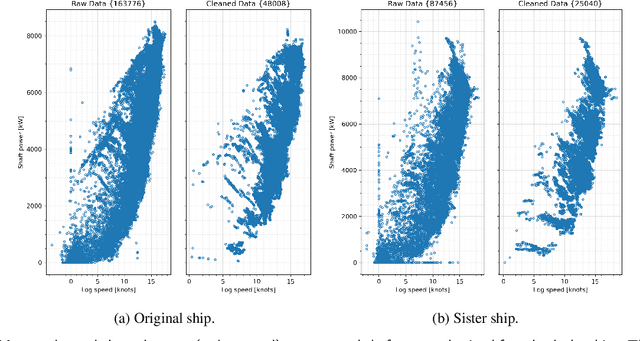
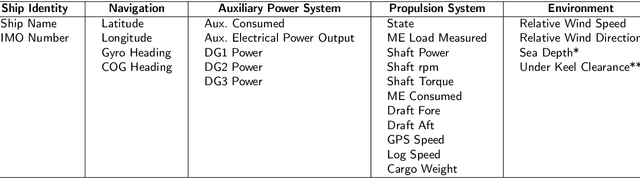
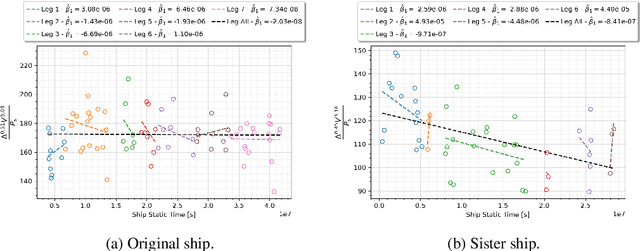
The hydrodynamic performance of a sea-going ship varies over its lifespan due to factors like marine fouling and the condition of the anti-fouling paint system. In order to accurately estimate the power demand and fuel consumption for a planned voyage, it is important to assess the hydrodynamic performance of the ship. The current work uses machine-learning (ML) methods to estimate the hydrodynamic performance of a ship using the onboard recorded in-service data. Three ML methods, NL-PCR, NL-PLSR and probabilistic ANN, are calibrated using the data from two sister ships. The calibrated models are used to extract the varying trend in ship's hydrodynamic performance over time and predict the change in performance through several propeller and hull cleaning events. The predicted change in performance is compared with the corresponding values estimated using the fouling friction coefficient ($\Delta C_F$). The ML methods are found to be performing well while modelling the hydrodynamic state variables of the ships with probabilistic ANN model performing the best, but the results from NL-PCR and NL-PLSR are not far behind, indicating that it may be possible to use simple methods to solve such problems with the help of domain knowledge.
Risk Conditioned Neural Motion Planning
Aug 04, 2021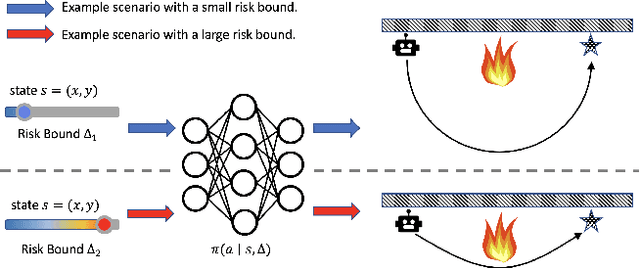
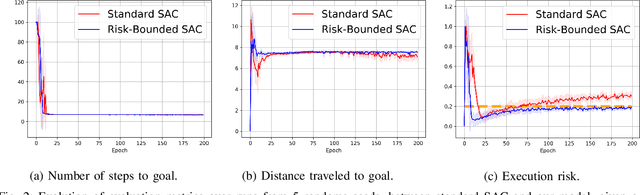
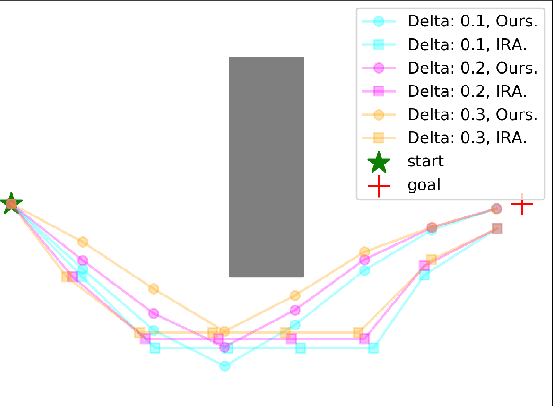
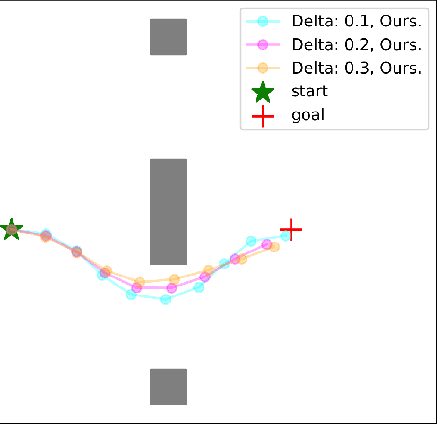
Risk-bounded motion planning is an important yet difficult problem for safety-critical tasks. While existing mathematical programming methods offer theoretical guarantees in the context of constrained Markov decision processes, they either lack scalability in solving larger problems or produce conservative plans. Recent advances in deep reinforcement learning improve scalability by learning policy networks as function approximators. In this paper, we propose an extension of soft actor critic model to estimate the execution risk of a plan through a risk critic and produce risk-bounded policies efficiently by adding an extra risk term in the loss function of the policy network. We define the execution risk in an accurate form, as opposed to approximating it through a summation of immediate risks at each time step that leads to conservative plans. Our proposed model is conditioned on a continuous spectrum of risk bounds, allowing the user to adjust the risk-averse level of the agent on the fly. Through a set of experiments, we show the advantage of our model in terms of both computational time and plan quality, compared to a state-of-the-art mathematical programming baseline, and validate its performance in more complicated scenarios, including nonlinear dynamics and larger state space.
A Time-Temperature Dataset for the Strawberry Cold Chain Across Multiple Shipments and Locations
Mar 23, 2021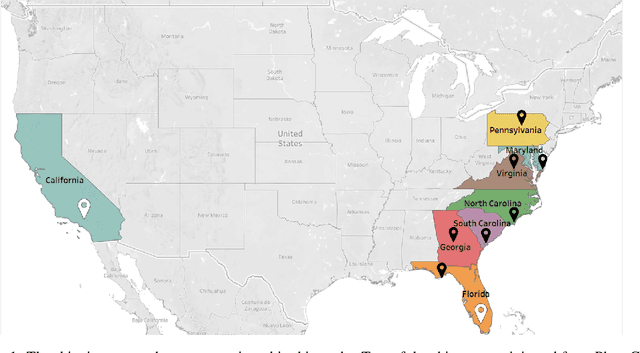

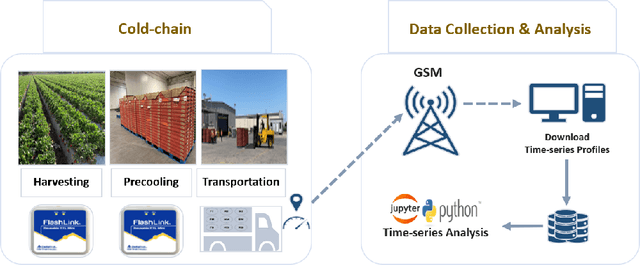
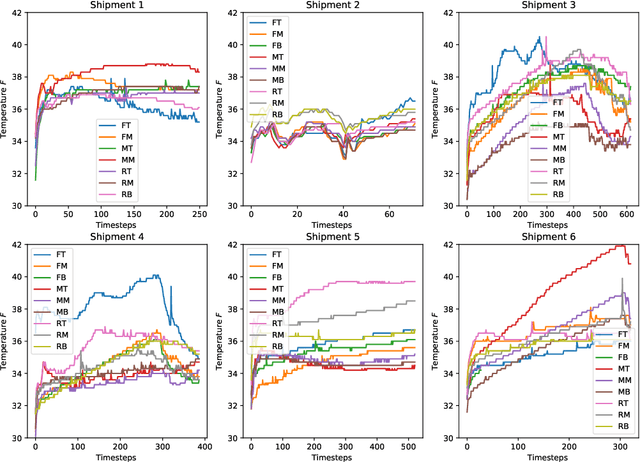
This article describes location aware temperature profiles from six strawberry shipments across the continental United States. Three pallets were instrumented in each shipment with three vertically placed loggers to take a longitudinal and latitudinal snapshot of 9 strategically different locations (including the top, middle and bottom layers of the pallets placed in the back, middle and the front of the shipping container) for a combined 54 measurement points across shipments of varying lengths. The sensors were instrumented in the field, right at the point of harvest, recorded temperatures every every 5 to 10 minutes depending on the shipment, and uploaded their data periodically via cellular radios on each device. The data is a result of significant collaboration between stakeholders from farmers to distributors to retailers to academics, which can play an important role for researchers and educators in food engineering, cold-chain, machine learning, and data mining, as well as in other disciplines related to food and transportation.