 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
IGLU: Efficient GCN Training via Lazy Updates
Sep 28, 2021
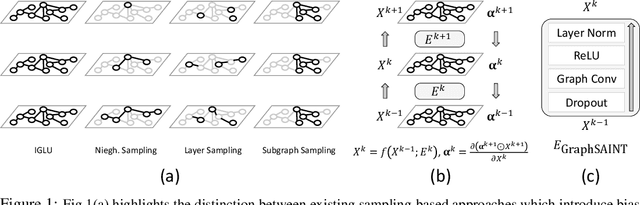
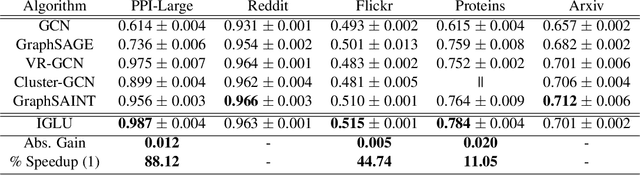
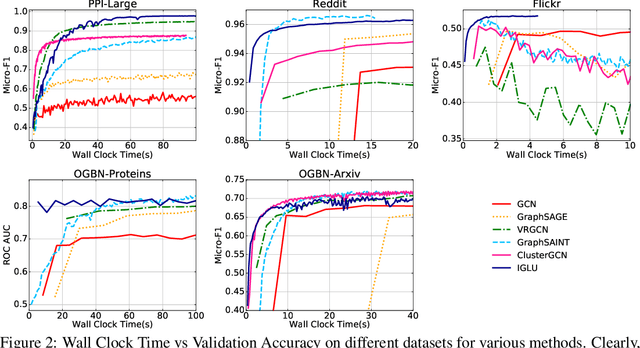

Graph Convolution Networks (GCN) are used in numerous settings involving a large underlying graph as well as several layers. Standard SGD-based training scales poorly here since each descent step ends up updating node embeddings for a large portion of the graph. Recent methods attempt to remedy this by sub-sampling the graph which does reduce the compute load, but at the cost of biased gradients which may offer suboptimal performance. In this work we introduce a new method IGLU that caches forward-pass embeddings for all nodes at various GCN layers. This enables IGLU to perform lazy updates that do not require updating a large number of node embeddings during descent which offers much faster convergence but does not significantly bias the gradients. Under standard assumptions such as objective smoothness, IGLU provably converges to a first-order saddle point. We validate IGLU extensively on a variety of benchmarks, where it offers up to 1.2% better accuracy despite requiring up to 88% less wall-clock time.
Identifying Reasoning Flaws in Planning-Based RL Using Tree Explanations
Sep 28, 2021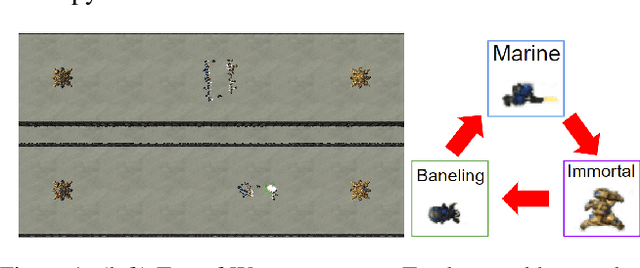

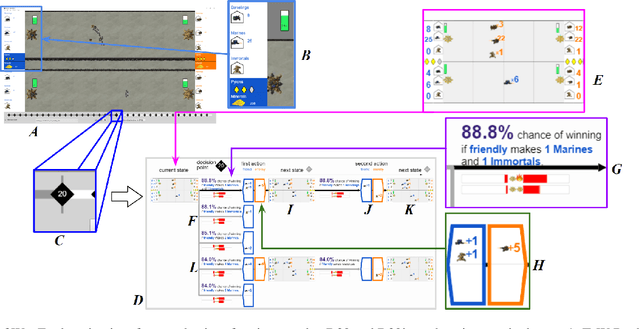
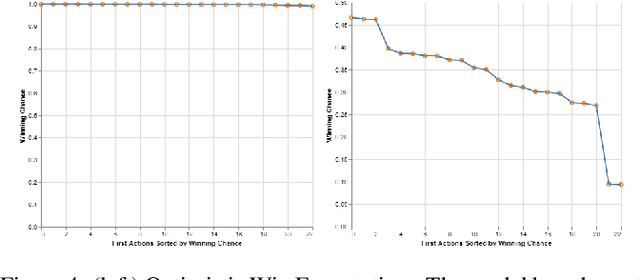
Enabling humans to identify potential flaws in an agent's decision making is an important Explainable AI application. We consider identifying such flaws in a planning-based deep reinforcement learning (RL) agent for a complex real-time strategy game. In particular, the agent makes decisions via tree search using a learned model and evaluation function over interpretable states and actions. This gives the potential for humans to identify flaws at the level of reasoning steps in the tree, even if the entire reasoning process is too complex to understand. However, it is unclear whether humans will be able to identify such flaws due to the size and complexity of trees. We describe a user interface and case study, where a small group of AI experts and developers attempt to identify reasoning flaws due to inaccurate agent learning. Overall, the interface allowed the group to identify a number of significant flaws of varying types, demonstrating the promise of this approach.
On the Explanatory Power of Decision Trees
Sep 04, 2021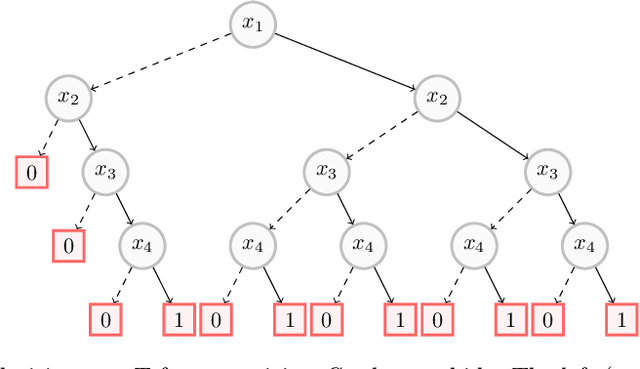
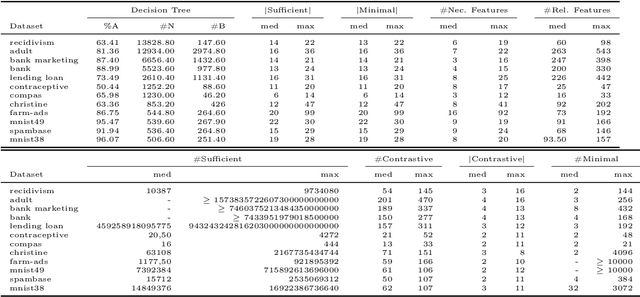
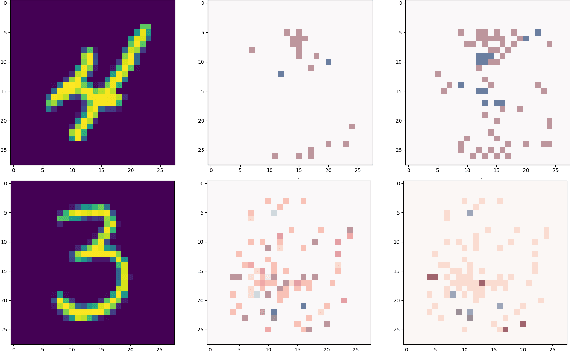
Decision trees have long been recognized as models of choice in sensitive applications where interpretability is of paramount importance. In this paper, we examine the computational ability of Boolean decision trees in deriving, minimizing, and counting sufficient reasons and contrastive explanations. We prove that the set of all sufficient reasons of minimal size for an instance given a decision tree can be exponentially larger than the size of the input (the instance and the decision tree). Therefore, generating the full set of sufficient reasons can be out of reach. In addition, computing a single sufficient reason does not prove enough in general; indeed, two sufficient reasons for the same instance may differ on many features. To deal with this issue and generate synthetic views of the set of all sufficient reasons, we introduce the notions of relevant features and of necessary features that characterize the (possibly negated) features appearing in at least one or in every sufficient reason, and we show that they can be computed in polynomial time. We also introduce the notion of explanatory importance, that indicates how frequent each (possibly negated) feature is in the set of all sufficient reasons. We show how the explanatory importance of a feature and the number of sufficient reasons can be obtained via a model counting operation, which turns out to be practical in many cases. We also explain how to enumerate sufficient reasons of minimal size. We finally show that, unlike sufficient reasons, the set of all contrastive explanations for an instance given a decision tree can be derived, minimized and counted in polynomial time.
In vivo functional and structural retina imaging using multimodal photoacoustic remote sensing microscopy and optical coherence tomography
Aug 26, 2021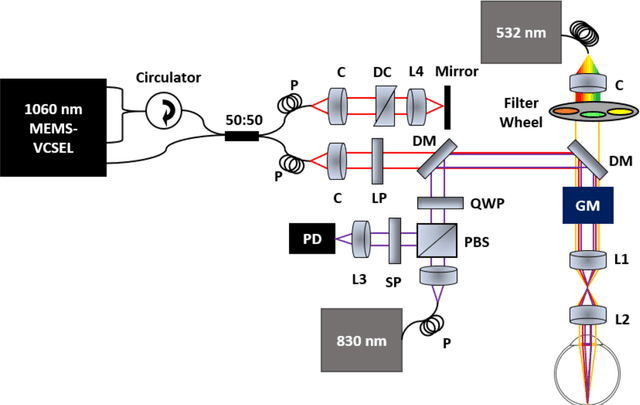

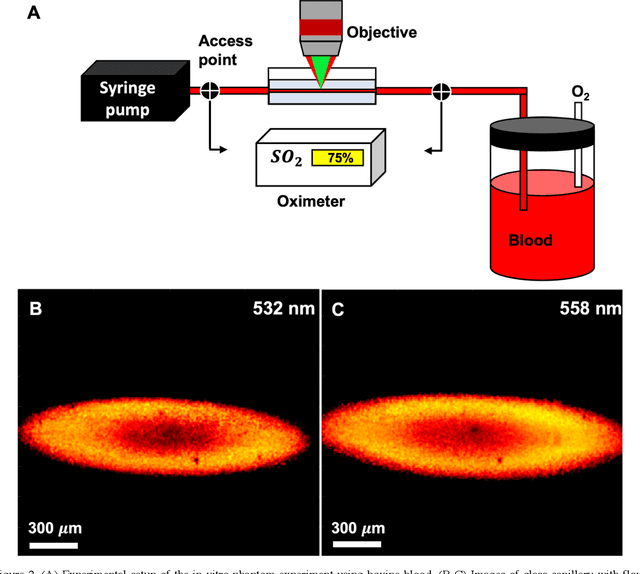
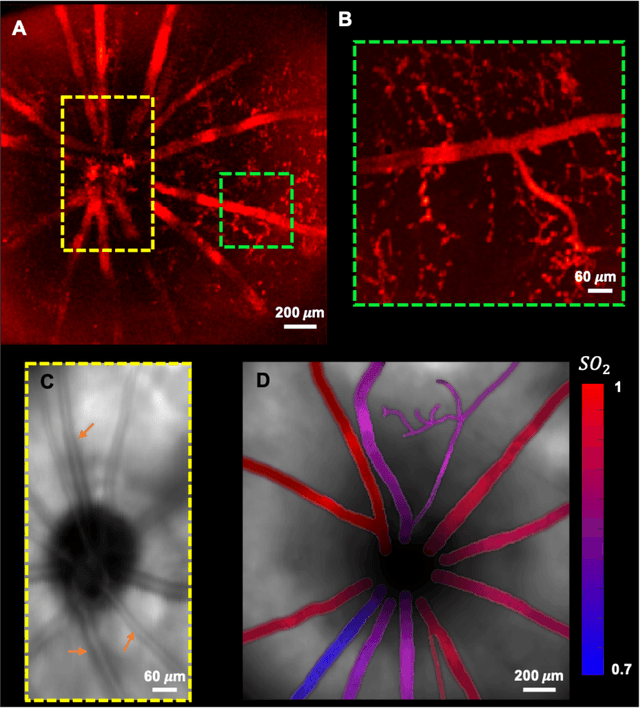
We have developed a multimodal photoacoustic remote sensing (PARS) microscope combined with swept source optical coherence tomography for in vivo, non-contact retinal imaging. Building on the proven strength of multiwavelength PARS imaging, the system is applied for estimating retinal oxygen saturation in the rat retina. The capability of the technology is demonstrated by imaging both microanatomy and the microvasculature of the retina in vivo. To our knowledge this is the first time a non-contact photoacoustic imaging technique is employed for in vivo oxygen saturation measurement in the retina.
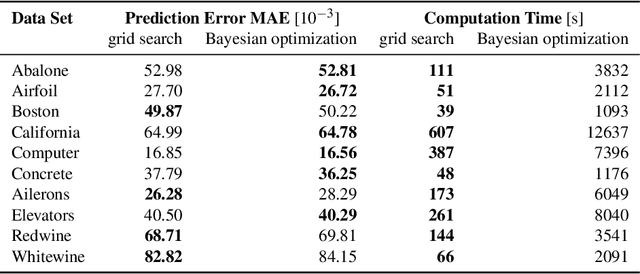
An Empirical Study on Hyperparameter Optimization for Fine-Tuning Pre-trained Language Models
Jun 17, 2021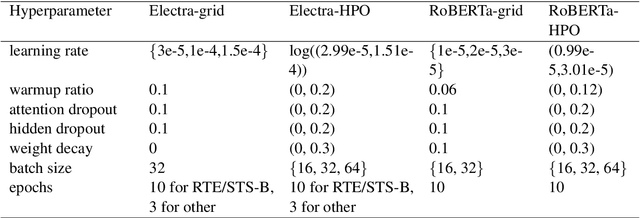
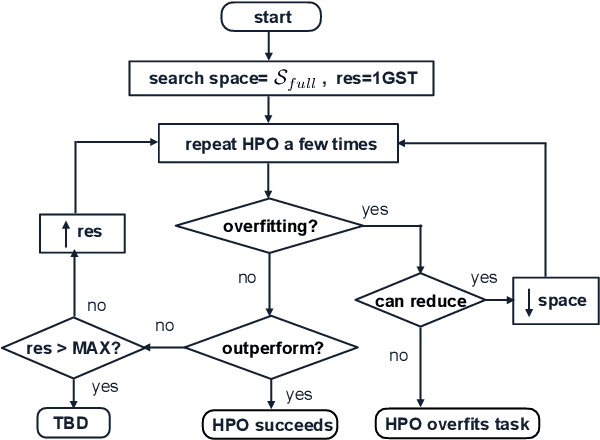
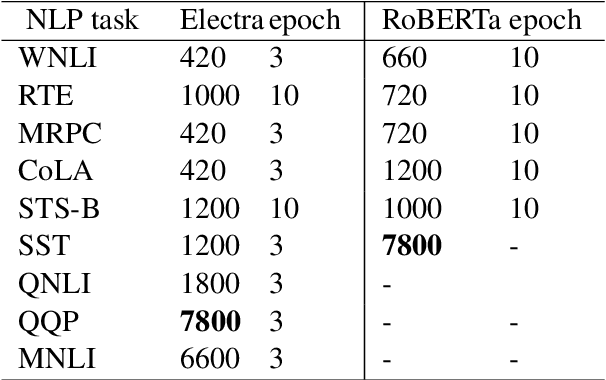
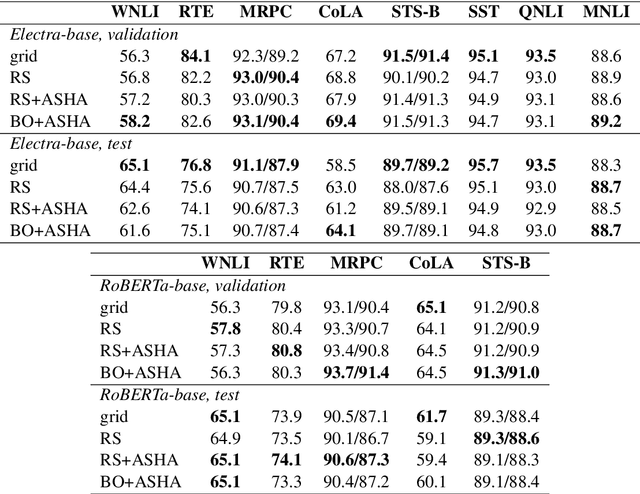
The performance of fine-tuning pre-trained language models largely depends on the hyperparameter configuration. In this paper, we investigate the performance of modern hyperparameter optimization methods (HPO) on fine-tuning pre-trained language models. First, we study and report three HPO algorithms' performances on fine-tuning two state-of-the-art language models on the GLUE dataset. We find that using the same time budget, HPO often fails to outperform grid search due to two reasons: insufficient time budget and overfitting. We propose two general strategies and an experimental procedure to systematically troubleshoot HPO's failure cases. By applying the procedure, we observe that HPO can succeed with more appropriate settings in the search space and time budget; however, in certain cases overfitting remains. Finally, we make suggestions for future work. Our implementation can be found in https://github.com/microsoft/FLAML/tree/main/flaml/nlp/.
PARIS: Personalized Activity Recommendation for Improving Sleep Quality
Oct 26, 2021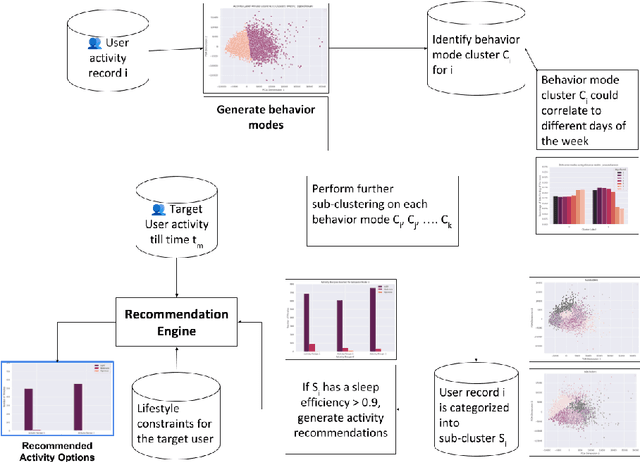
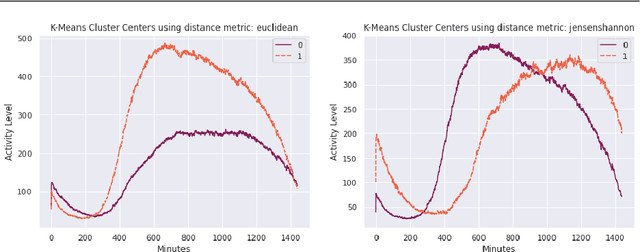
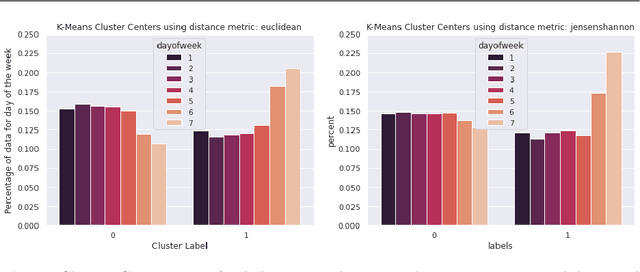
The quality of sleep has a deep impact on people's physical and mental health. People with insufficient sleep are more likely to report physical and mental distress, activity limitation, anxiety, and pain. Moreover, in the past few years, there has been an explosion of applications and devices for activity monitoring and health tracking. Signals collected from these wearable devices can be used to study and improve sleep quality. In this paper, we utilize the relationship between physical activity and sleep quality to find ways of assisting people improve their sleep using machine learning techniques. People usually have several behavior modes that their bio-functions can be divided into. Performing time series clustering on activity data, we find cluster centers that would correlate to the most evident behavior modes for a specific subject. Activity recipes are then generated for good sleep quality for each behavior mode within each cluster. These activity recipes are supplied to an activity recommendation engine for suggesting a mix of relaxed to intense activities to subjects during their daily routines. The recommendations are further personalized based on the subjects' lifestyle constraints, i.e. their age, gender, body mass index (BMI), resting heart rate, etc, with the objective of the recommendation being the improvement of that night's quality of sleep. This would in turn serve a longer-term health objective, like lowering heart rate, improving the overall quality of sleep, etc.
On Homophony and Rényi Entropy
Sep 28, 2021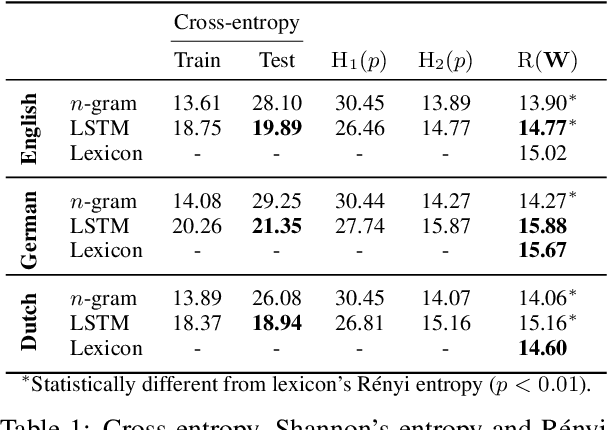
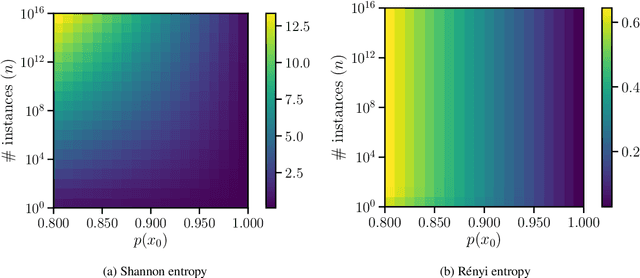
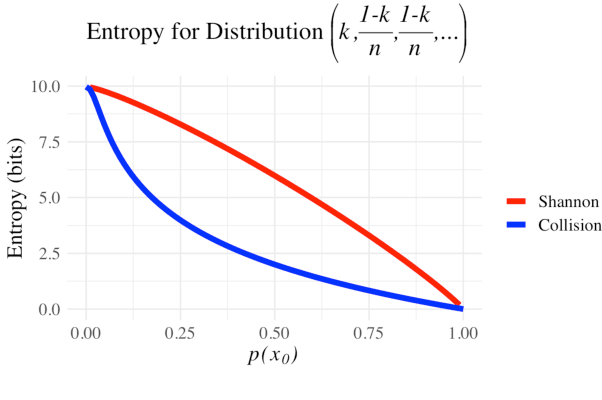
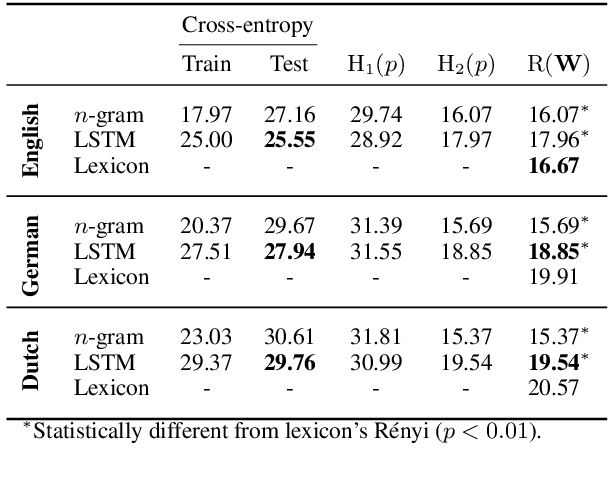
Homophony's widespread presence in natural languages is a controversial topic. Recent theories of language optimality have tried to justify its prevalence, despite its negative effects on cognitive processing time; e.g., Piantadosi et al. (2012) argued homophony enables the reuse of efficient wordforms and is thus beneficial for languages. This hypothesis has recently been challenged by Trott and Bergen (2020), who posit that good wordforms are more often homophonous simply because they are more phonotactically probable. In this paper, we join in on the debate. We first propose a new information-theoretic quantification of a language's homophony: the sample R\'enyi entropy. Then, we use this quantification to revisit Trott and Bergen's claims. While their point is theoretically sound, a specific methodological issue in their experiments raises doubts about their results. After addressing this issue, we find no clear pressure either towards or against homophony -- a much more nuanced result than either Piantadosi et al.'s or Trott and Bergen's findings.
MAAD: A Model and Dataset for "Attended Awareness" in Driving
Oct 16, 2021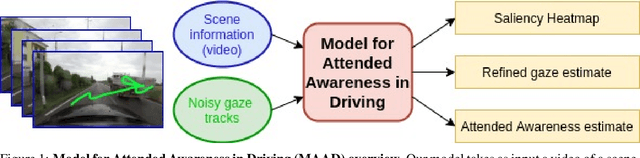
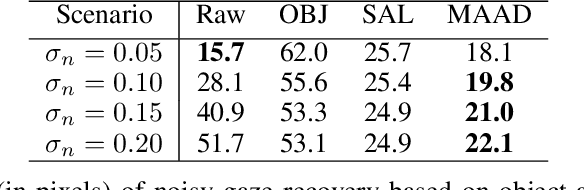
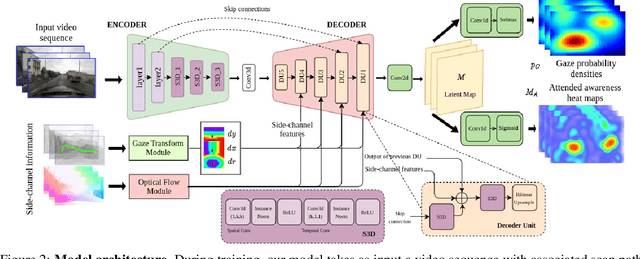

We propose a computational model to estimate a person's attended awareness of their environment. We define attended awareness to be those parts of a potentially dynamic scene which a person has attended to in recent history and which they are still likely to be physically aware of. Our model takes as input scene information in the form of a video and noisy gaze estimates, and outputs visual saliency, a refined gaze estimate, and an estimate of the person's attended awareness. In order to test our model, we capture a new dataset with a high-precision gaze tracker including 24.5 hours of gaze sequences from 23 subjects attending to videos of driving scenes. The dataset also contains third-party annotations of the subjects' attended awareness based on observations of their scan path. Our results show that our model is able to reasonably estimate attended awareness in a controlled setting, and in the future could potentially be extended to real egocentric driving data to help enable more effective ahead-of-time warnings in safety systems and thereby augment driver performance. We also demonstrate our model's effectiveness on the tasks of saliency, gaze calibration, and denoising, using both our dataset and an existing saliency dataset. We make our model and dataset available at https://github.com/ToyotaResearchInstitute/att-aware/.
Concepts for Automated Machine Learning in Smart Grid Applications
Oct 26, 2021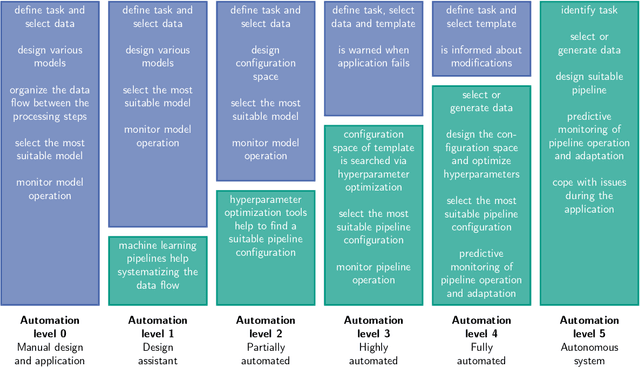
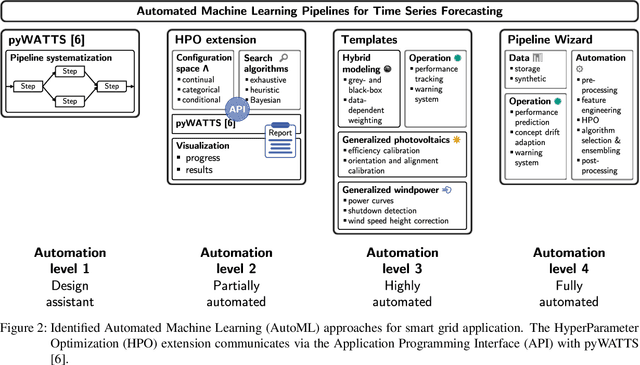
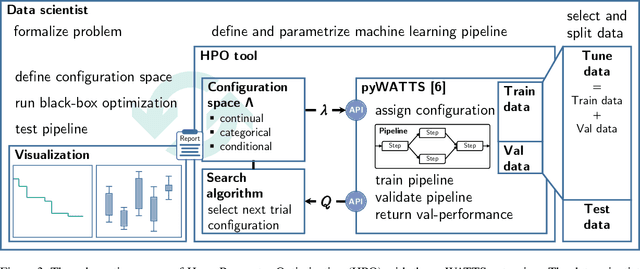
Undoubtedly, the increase of available data and competitive machine learning algorithms has boosted the popularity of data-driven modeling in energy systems. Applications are forecasts for renewable energy generation and energy consumption. Forecasts are elementary for sector coupling, where energy-consuming sectors are interconnected with the power-generating sector to address electricity storage challenges by adding flexibility to the power system. However, the large-scale application of machine learning methods in energy systems is impaired by the need for expert knowledge, which covers machine learning expertise and a profound understanding of the application's process. The process knowledge is required for the problem formalization, as well as the model validation and application. The machine learning skills include the processing steps of i) data pre-processing, ii) feature engineering, extraction, and selection, iii) algorithm selection, iv) hyperparameter optimization, and possibly v) post-processing of the model's output. Tailoring a model for a particular application requires selecting the data, designing various candidate models and organizing the data flow between the processing steps, selecting the most suitable model, and monitoring the model during operation - an iterative and time-consuming procedure. Automated design and operation of machine learning aim to reduce the human effort to address the increasing demand for data-driven models. We define five levels of automation for forecasting in alignment with the SAE standard for autonomous vehicles, where manual design and application reflect Automation level 0.
Tetra-Tagging: Word-Synchronous Parsing with Linear-Time Inference
Apr 22, 2019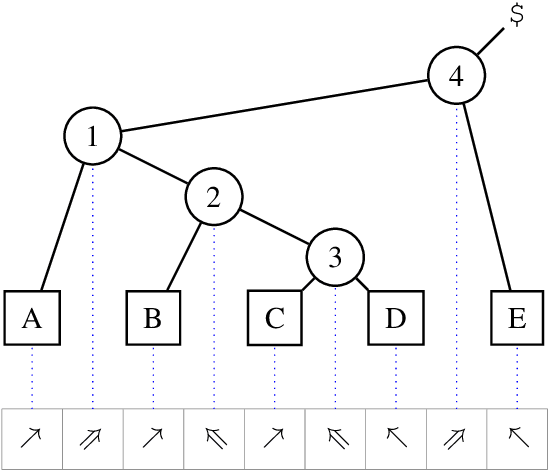

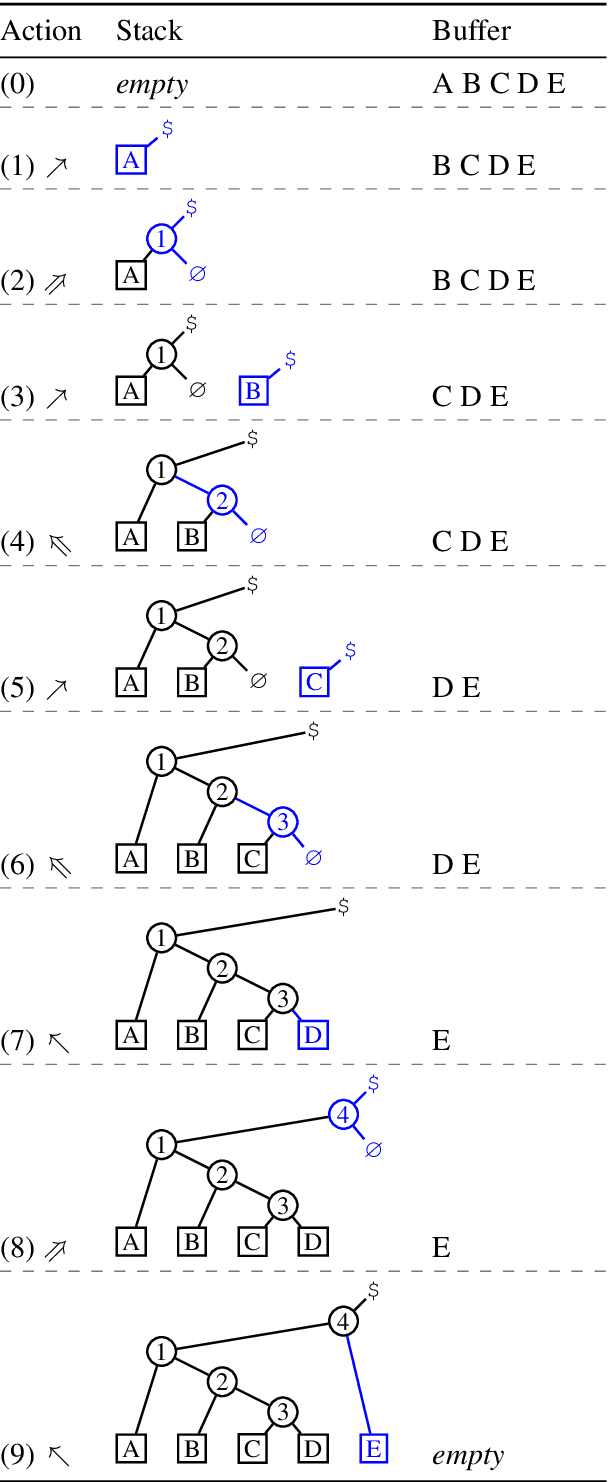
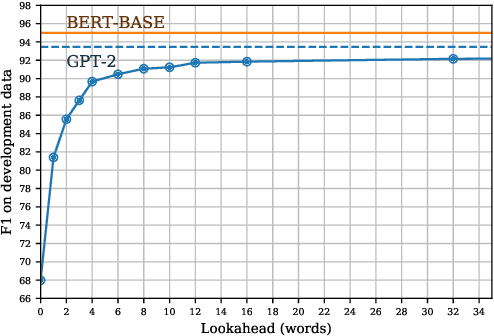
We present a constituency parsing algorithm that maps from word-aligned contextualized feature vectors to parse trees. Our algorithm proceeds strictly left-to-right, processing one word at a time by assigning it a label from a small vocabulary. We show that, with mild assumptions, our inference procedure requires constant computation time per word. Our method gets 95.4 F1 on the WSJ test set.