 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GNN-DSE: Automated Accelerator Optimization Aided by Graph Neural Networks
Nov 17, 2021
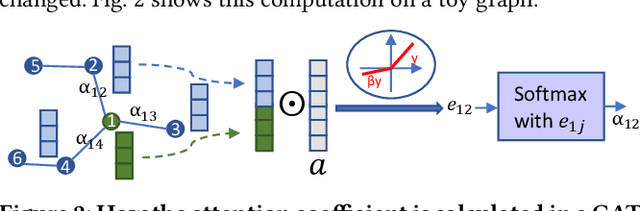

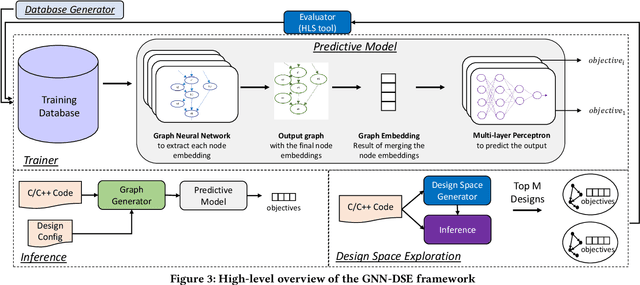

High-level synthesis (HLS) has freed the computer architects from developing their designs in a very low-level language and needing to exactly specify how the data should be transferred in register-level. With the help of HLS, the hardware designers must describe only a high-level behavioral flow of the design. Despite this, it still can take weeks to develop a high-performance architecture mainly because there are many design choices at a higher level that requires more time to explore. It also takes several minutes to hours to get feedback from the HLS tool on the quality of each design candidate. In this paper, we propose to solve this problem by modeling the HLS tool with a graph neural network (GNN) that is trained to be used for a wide range of applications. The experimental results demonstrate that by employing the GNN-based model, we are able to estimate the quality of design in milliseconds with high accuracy which can help us search through the solution space very quickly.
PowerGridworld: A Framework for Multi-Agent Reinforcement Learning in Power Systems
Nov 10, 2021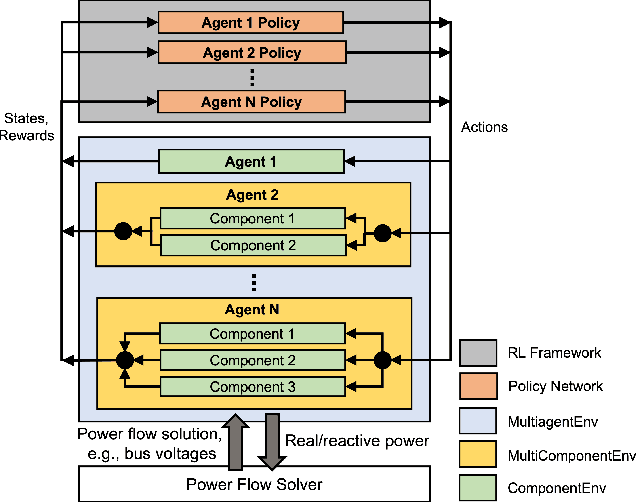
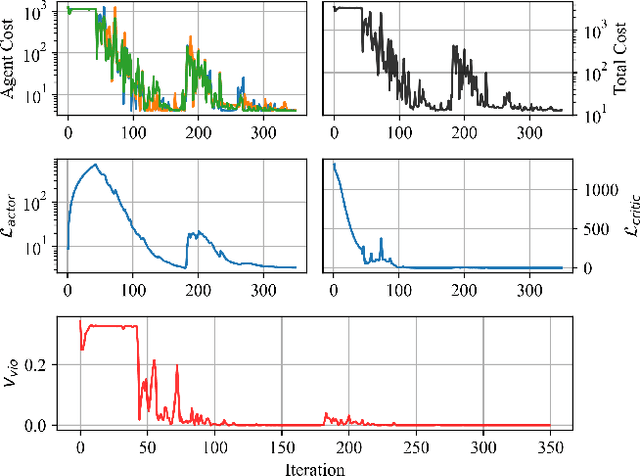
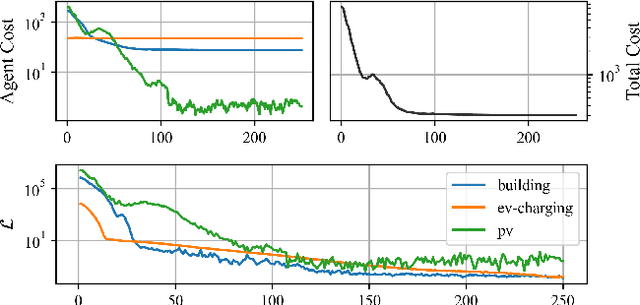
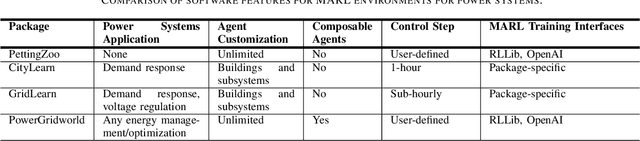
We present the PowerGridworld software package to provide users with a lightweight, modular, and customizable framework for creating power-systems-focused, multi-agent Gym environments that readily integrate with existing training frameworks for reinforcement learning (RL). Although many frameworks exist for training multi-agent RL (MARL) policies, none can rapidly prototype and develop the environments themselves, especially in the context of heterogeneous (composite, multi-device) power systems where power flow solutions are required to define grid-level variables and costs. PowerGridworld is an open-source software package that helps to fill this gap. To highlight PowerGridworld's key features, we present two case studies and demonstrate learning MARL policies using both OpenAI's multi-agent deep deterministic policy gradient (MADDPG) and RLLib's proximal policy optimization (PPO) algorithms. In both cases, at least some subset of agents incorporates elements of the power flow solution at each time step as part of their reward (negative cost) structures.
Ballistic Multibody Estimator for 2D Open Kinematic Chain
Nov 07, 2021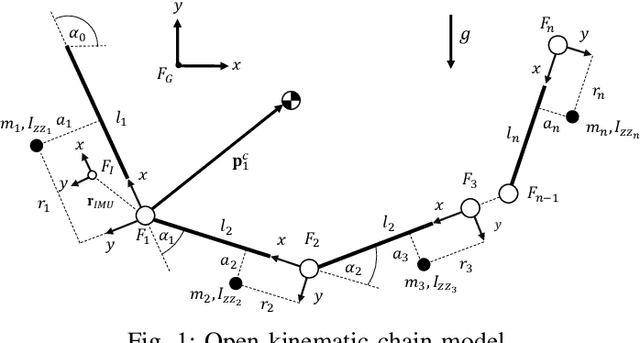
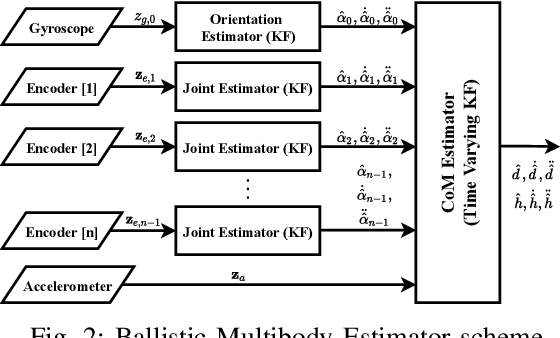
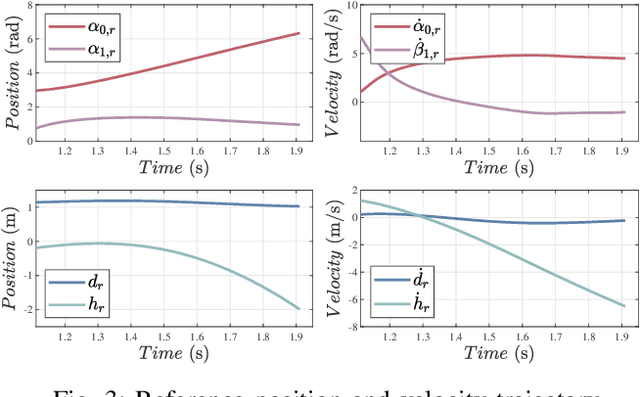
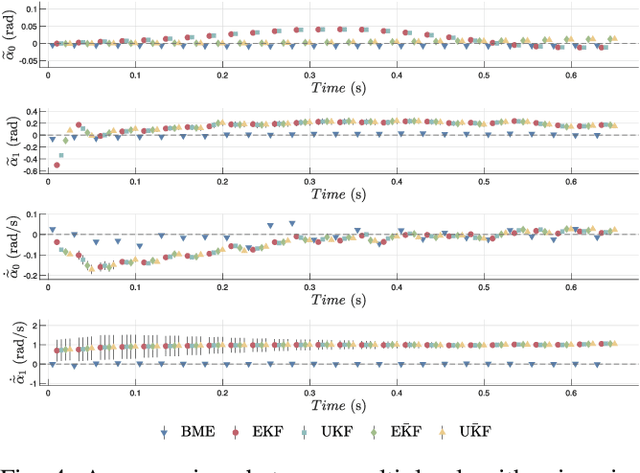
Applications of free-flying robots range from entertainment purposes to aerospace applications. The control algorithm for such systems requires accurate estimation of their states based on sensor feedback. The objective of this paper is to design and verify a lightweight state estimation algorithm for a free-flying open kinematic chain that estimates the state of its center-of-mass and its posture. Instead of utilizing a nonlinear dynamics model, this research proposes a cascade structure of two Kalman filters (KF), which relies on the information from the ballistic motion of free-falling multibody systems together with feedback from an inertial measurement unit (IMU) and encoders. Multiple algorithms are verified in the simulation that mimics real-world circumstances with Simulink. Several uncertain physical parameters are varied, and the result shows that the proposed estimator outperforms EKF and UKF in terms of tracking performance and computational time.
Classification of fetal compromise during labour: signal processing and feature engineering of the cardiotocograph
Oct 31, 2021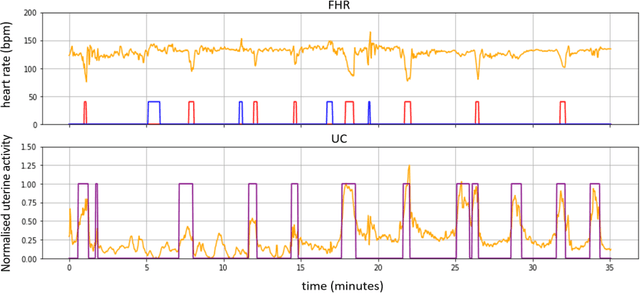
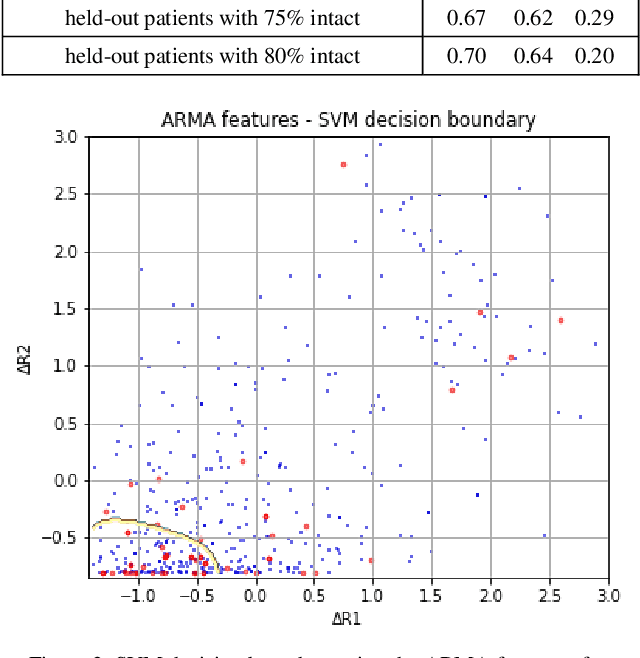
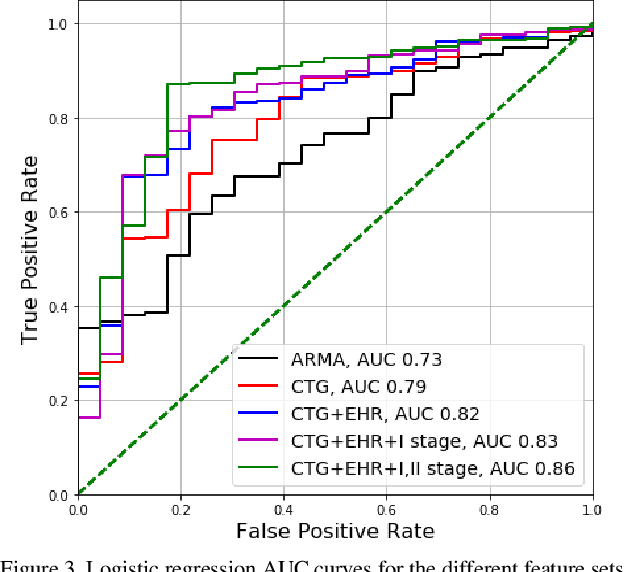
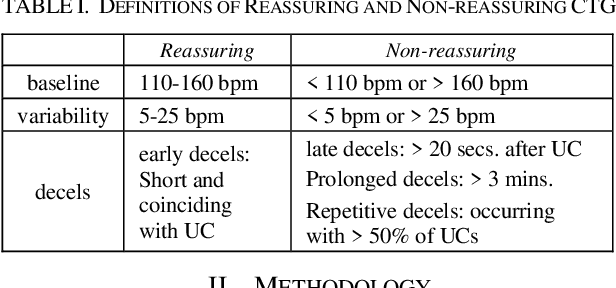
Cardiotocography (CTG) is the main tool used for fetal monitoring during labour. Interpretation of CTG requires dynamic pattern recognition in real time. It is recognised as a difficult task with high inter- and intra-observer disagreement. Machine learning has provided a viable path towards objective and reliable CTG assessment. In this study, novel CTG features are developed based on clinical expertise and system control theory using an autoregressive moving-average (ARMA) model to characterise the response of the fetal heart rate to contractions. The features are evaluated in a machine learning model to assess their efficacy in identifying fetal compromise. ARMA features ranked amongst the top features for detecting fetal compromise. Additionally, including clinical factors in the machine learning model and pruning data based on a signal quality measure improved the performance of the classifier.
Inductive Conformal Recommender System
Sep 18, 2021
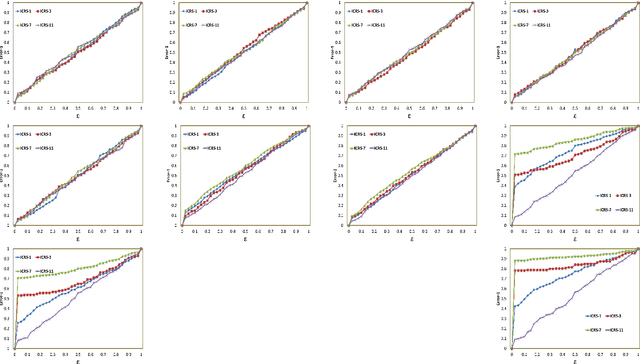
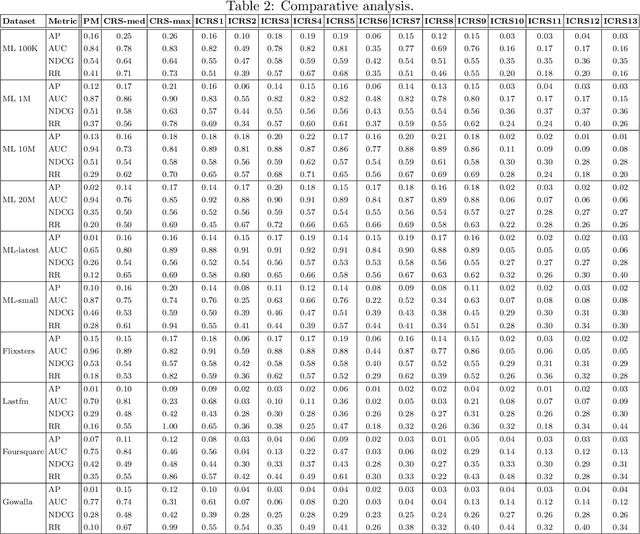
Traditional recommendation algorithms develop techniques that can help people to choose desirable items. However, in many real-world applications, along with a set of recommendations, it is also essential to quantify each recommendation's (un)certainty. The conformal recommender system uses the experience of a user to output a set of recommendations, each associated with a precise confidence value. Given a significance level $\varepsilon$, it provides a bound $\varepsilon$ on the probability of making a wrong recommendation. The conformal framework uses a key concept called nonconformity measure that measure the strangeness of an item concerning other items. One of the significant design challenges of any conformal recommendation framework is integrating nonconformity measure with the recommendation algorithm. In this paper, we introduce an inductive variant of a conformal recommender system. We propose and analyze different nonconformity measures in the inductive setting. We also provide theoretical proofs on the error-bound and the time complexity. Extensive empirical analysis on ten benchmark datasets demonstrates that the inductive variant substantially improves the performance in computation time while preserving the accuracy.
REP: Predicting the Time-Course of Drug Sensitivity
Jul 27, 2019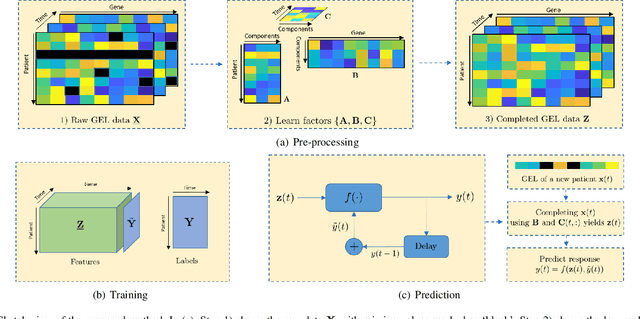
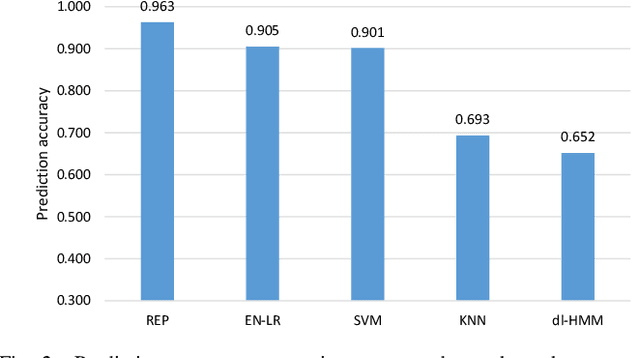
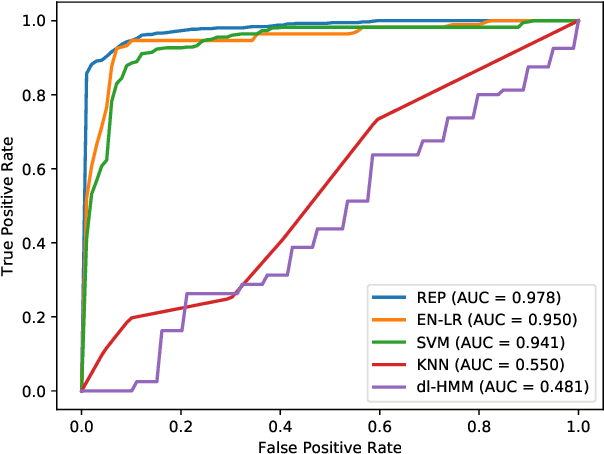
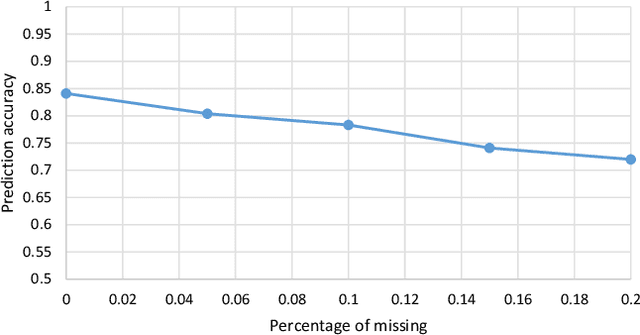
The biological processes involved in a drug's mechanisms of action are oftentimes dynamic, complex and difficult to discern. Time-course gene expression data is a rich source of information that can be used to unravel these complex processes, identify biomarkers of drug sensitivity and predict the response to a drug. However, the majority of previous work has not fully utilized this temporal dimension. In these studies, the gene expression data is either considered at one time-point (before the administration of the drug) or two timepoints (before and after the administration of the drug). This is clearly inadequate in modeling dynamic gene-drug interactions, especially for applications such as long-term drug therapy. In this work, we present a novel REcursive Prediction (REP) framework for drug response prediction by taking advantage of time-course gene expression data. Our goal is to predict drug response values at every stage of a long-term treatment, given the expression levels of genes collected in the previous time-points. To this end, REP employs a built-in recursive structure that exploits the intrinsic time-course nature of the data and integrates past values of drug responses for subsequent predictions. It also incorporates tensor completion that can not only alleviate the impact of noise and missing data, but also predict unseen gene expression levels (GELs). These advantages enable REP to estimate drug response at any stage of a given treatment from some GELs measured in the beginning of the treatment. Extensive experiments on a dataset corresponding to 53 multiple sclerosis patients treated with interferon are included to showcase the effectiveness of REP.
Finite Time Analysis of Linear Two-timescale Stochastic Approximation with Markovian Noise
Feb 04, 2020
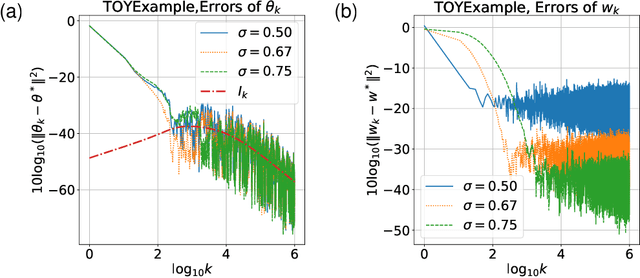
Linear two-timescale stochastic approximation (SA) scheme is an important class of algorithms which has become popular in reinforcement learning (RL), particularly for the policy evaluation problem. Recently, a number of works have been devoted to establishing the finite time analysis of the scheme, especially under the Markovian (non-i.i.d.) noise settings that are ubiquitous in practice. In this paper, we provide a finite-time analysis for linear two timescale SA. Our bounds show that there is no discrepancy in the convergence rate between Markovian and martingale noise, only the constants are affected by the mixing time of the Markov chain. With an appropriate step size schedule, the transient term in the expected error bound is $o(1/k^c)$ and the steady-state term is ${\cal O}(1/k)$, where $c>1$ and $k$ is the iteration number. Furthermore, we present an asymptotic expansion of the expected error with a matching lower bound of $\Omega(1/k)$. A simple numerical experiment is presented to support our theory.
Improving Semantic Image Segmentation via Label Fusion in Semantically Textured Meshes
Nov 22, 2021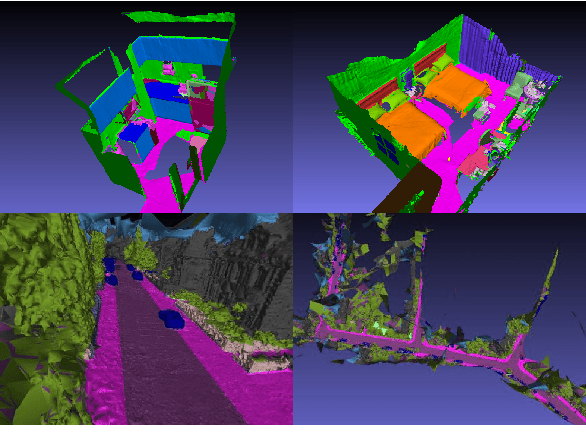

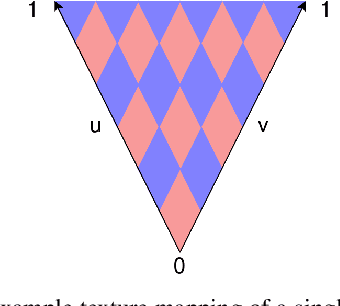
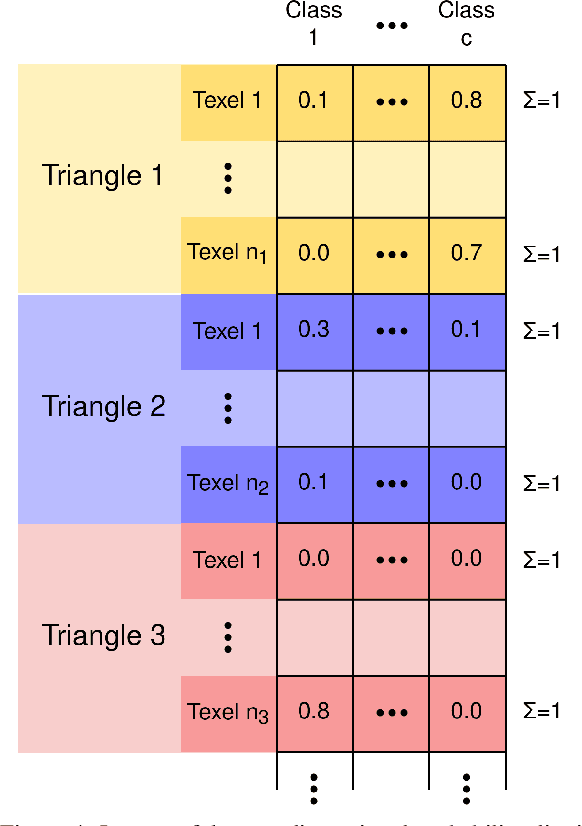
Models for semantic segmentation require a large amount of hand-labeled training data which is costly and time-consuming to produce. For this purpose, we present a label fusion framework that is capable of improving semantic pixel labels of video sequences in an unsupervised manner. We make use of a 3D mesh representation of the environment and fuse the predictions of different frames into a consistent representation using semantic mesh textures. Rendering the semantic mesh using the original intrinsic and extrinsic camera parameters yields a set of improved semantic segmentation images. Due to our optimized CUDA implementation, we are able to exploit the entire $c$-dimensional probability distribution of annotations over $c$ classes in an uncertainty-aware manner. We evaluate our method on the Scannet dataset where we improve annotations produced by the state-of-the-art segmentation network ESANet from $52.05 \%$ to $58.25 \%$ pixel accuracy. We publish the source code of our framework online to foster future research in this area (\url{https://github.com/fferflo/semantic-meshes}). To the best of our knowledge, this is the first publicly available label fusion framework for semantic image segmentation based on meshes with semantic textures.
A Survey of Self-Supervised and Few-Shot Object Detection
Oct 27, 2021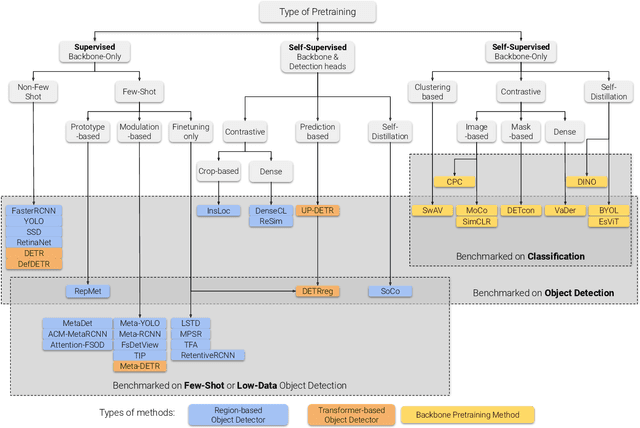

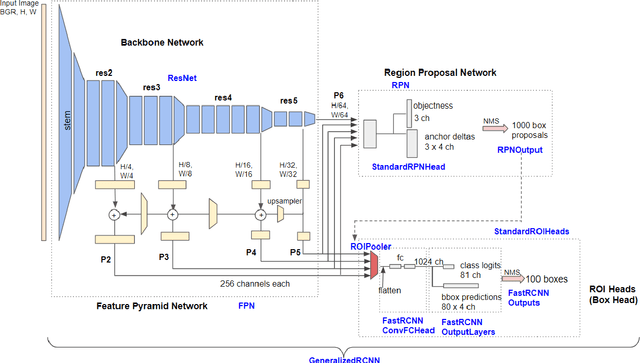
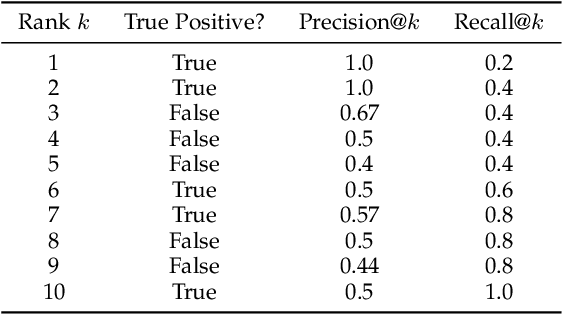
Labeling data is often expensive and time-consuming, especially for tasks such as object detection and instance segmentation, which require dense labeling of the image. While few-shot object detection is about training a model on novel (unseen) object classes with little data, it still requires prior training on many labeled examples of base (seen) classes. On the other hand, self-supervised methods aim at learning representations from unlabeled data which transfer well to downstream tasks such as object detection. Combining few-shot and self-supervised object detection is a promising research direction. In this survey, we review and characterize the most recent approaches on few-shot and self-supervised object detection. Then, we give our main takeaways and discuss future research directions.
Dynamic Realtime z-Shimming: A Feasibility Study
Jul 21, 2021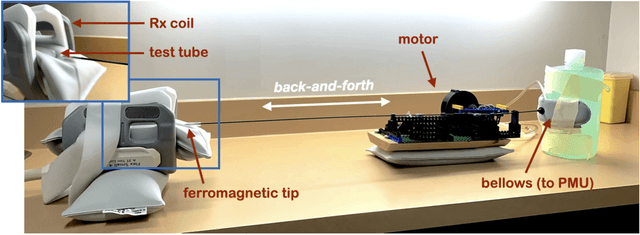
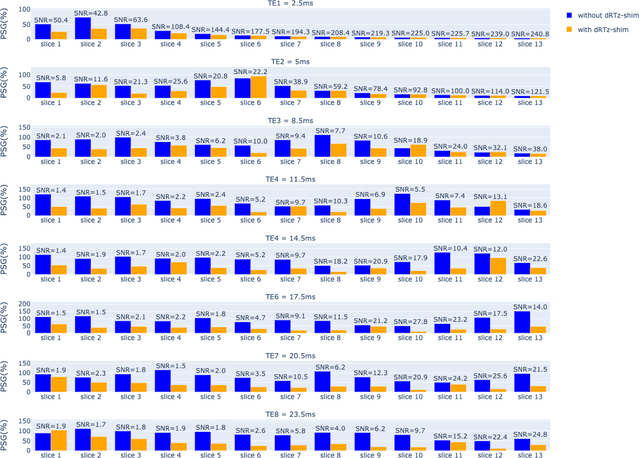
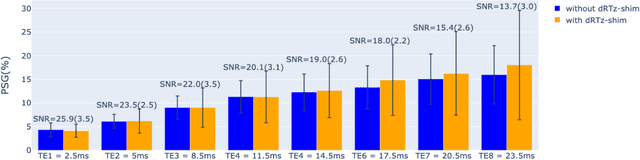
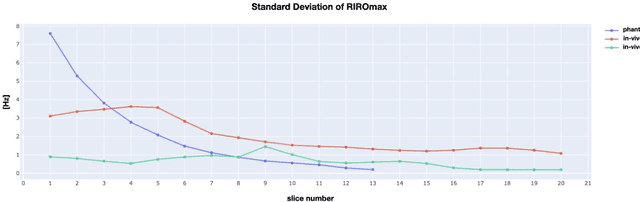
Respiration causes time-varying frequency offsets that can result in ghosting artifacts. We propose a solution, which we term dynamic realtime z-shimming, wherein linear gradients are adjusted dynamically (slice-wise) and in real-time, to reflect magnetic field inhomogeneities that arise during image acquisition. In dynamic z-shimming, a method that is commonly used to reduce static frequency offsets in MR images of the spinal cord and brain, in-plane (static) frequency offsets are assumed to be homogeneous. Here we investigate whether or not that same assumption can be made for time-varying frequency offsets in the cervical spinal cord region. In order to explore the feasibility of dynamic realtime z-shimming, we acquired images using a pneumatic phantom setup, as well as in-vivo. We then simulated the effects of time-varying frequency offsets on MR images acquired with and without dynamic realtime z-shimming in different scenarios. We found that dynamic realtime z-shimming can reduce ghosting if the time-varying frequency offsets have an in-plane variability (standard deviation) of approximately less than 1 Hz. This scenario was achieved in our phantom setup, where we observed a 50.2% reduction in ghosting within multi-echo gradient echo images acquired with dynamic realtime z-shimming, compared to without. On the other hand, we observed that the in-plane variability of the time-varying frequency offsets is too high within the cervical spinal cord region for dynamic realtime z-shimming to be successful. These results can serve as a guideline and starting point for future dynamic realtime z-shimming experiments in which the in-plane variability of frequency offsets are minimized.