 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Echocardiography Segmentation with Enforced Temporal Consistency
Dec 03, 2021
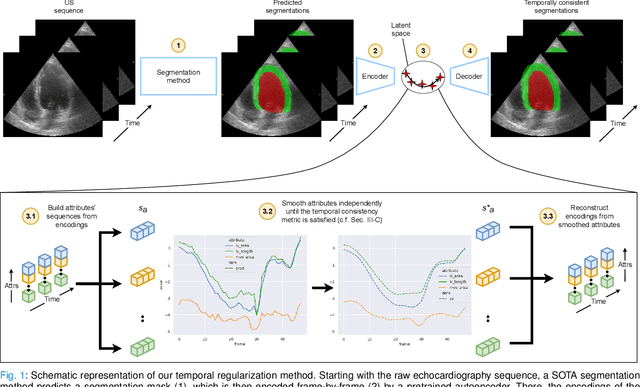
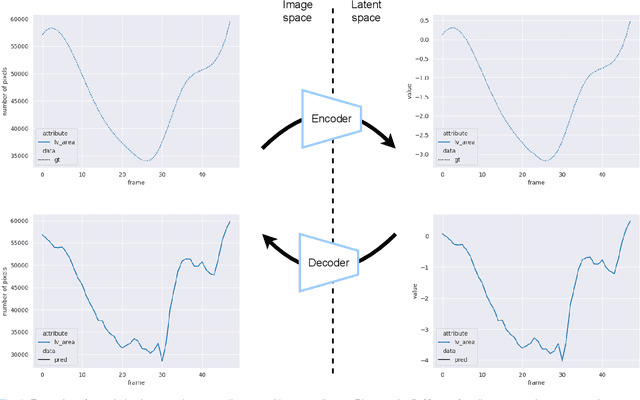

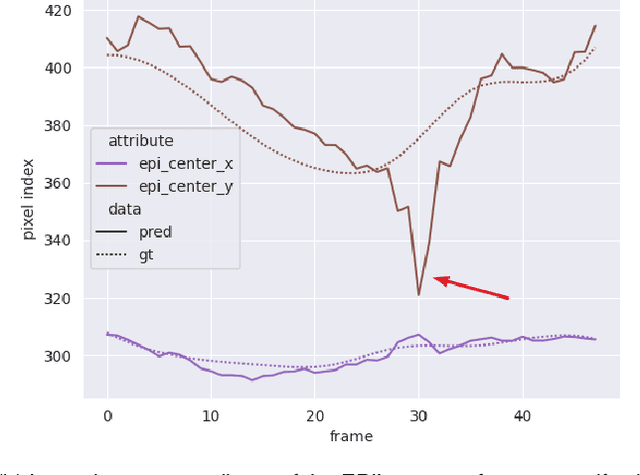
Convolutional neural networks (CNN) have demonstrated their ability to segment 2D cardiac ultrasound images. However, despite recent successes according to which the intra-observer variability on end-diastole and end-systole images has been reached, CNNs still struggle to leverage temporal information to provide accurate and temporally consistent segmentation maps across the whole cycle. Such consistency is required to accurately describe the cardiac function, a necessary step in diagnosing many cardiovascular diseases. In this paper, we propose a framework to learn the 2D+time long-axis cardiac shape such that the segmented sequences can benefit from temporal and anatomical consistency constraints. Our method is a post-processing that takes as input segmented echocardiographic sequences produced by any state-of-the-art method and processes it in two steps to (i) identify spatio-temporal inconsistencies according to the overall dynamics of the cardiac sequence and (ii) correct the inconsistencies. The identification and correction of cardiac inconsistencies relies on a constrained autoencoder trained to learn a physiologically interpretable embedding of cardiac shapes, where we can both detect and fix anomalies. We tested our framework on 98 full-cycle sequences from the CAMUS dataset, which will be rendered public alongside this paper. Our temporal regularization method not only improves the accuracy of the segmentation across the whole sequences, but also enforces temporal and anatomical consistency.
Survey on English Entity Linking on Wikidata
Dec 03, 2021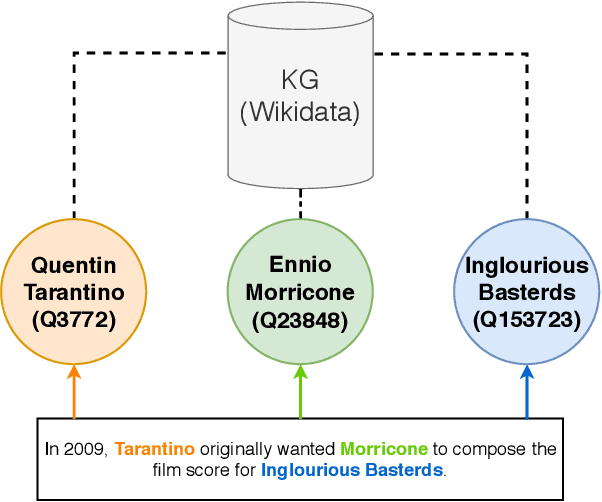

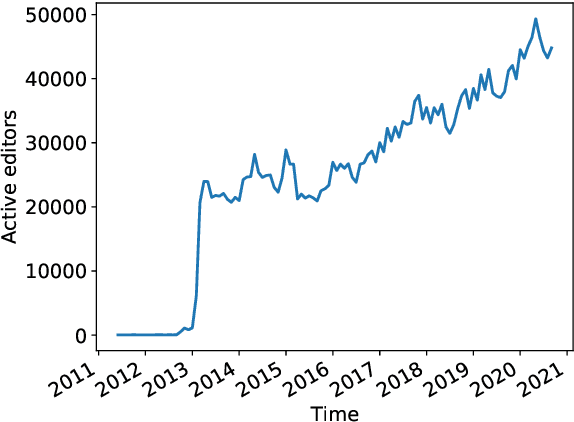
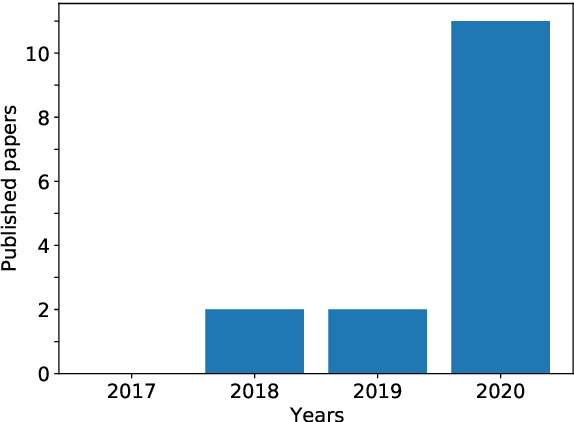
Wikidata is a frequently updated, community-driven, and multilingual knowledge graph. Hence, Wikidata is an attractive basis for Entity Linking, which is evident by the recent increase in published papers. This survey focuses on four subjects: (1) Which Wikidata Entity Linking datasets exist, how widely used are they and how are they constructed? (2) Do the characteristics of Wikidata matter for the design of Entity Linking datasets and if so, how? (3) How do current Entity Linking approaches exploit the specific characteristics of Wikidata? (4) Which Wikidata characteristics are unexploited by existing Entity Linking approaches? This survey reveals that current Wikidata-specific Entity Linking datasets do not differ in their annotation scheme from schemes for other knowledge graphs like DBpedia. Thus, the potential for multilingual and time-dependent datasets, naturally suited for Wikidata, is not lifted. Furthermore, we show that most Entity Linking approaches use Wikidata in the same way as any other knowledge graph missing the chance to leverage Wikidata-specific characteristics to increase quality. Almost all approaches employ specific properties like labels and sometimes descriptions but ignore characteristics such as the hyper-relational structure. Hence, there is still room for improvement, for example, by including hyper-relational graph embeddings or type information. Many approaches also include information from Wikipedia, which is easily combinable with Wikidata and provides valuable textual information, which Wikidata lacks.
Single-Modal Entropy based Active Learning for Visual Question Answering
Nov 18, 2021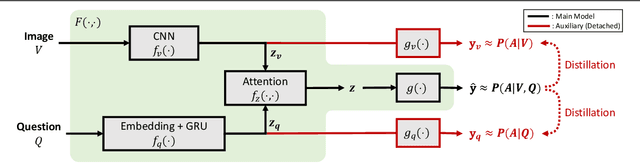
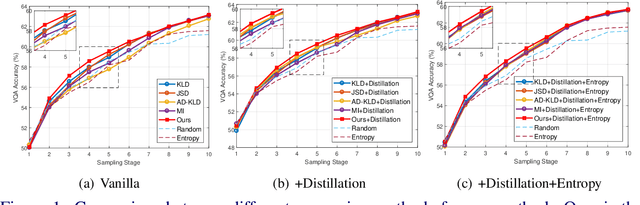
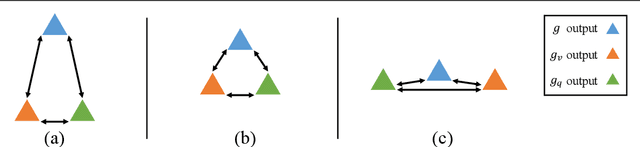
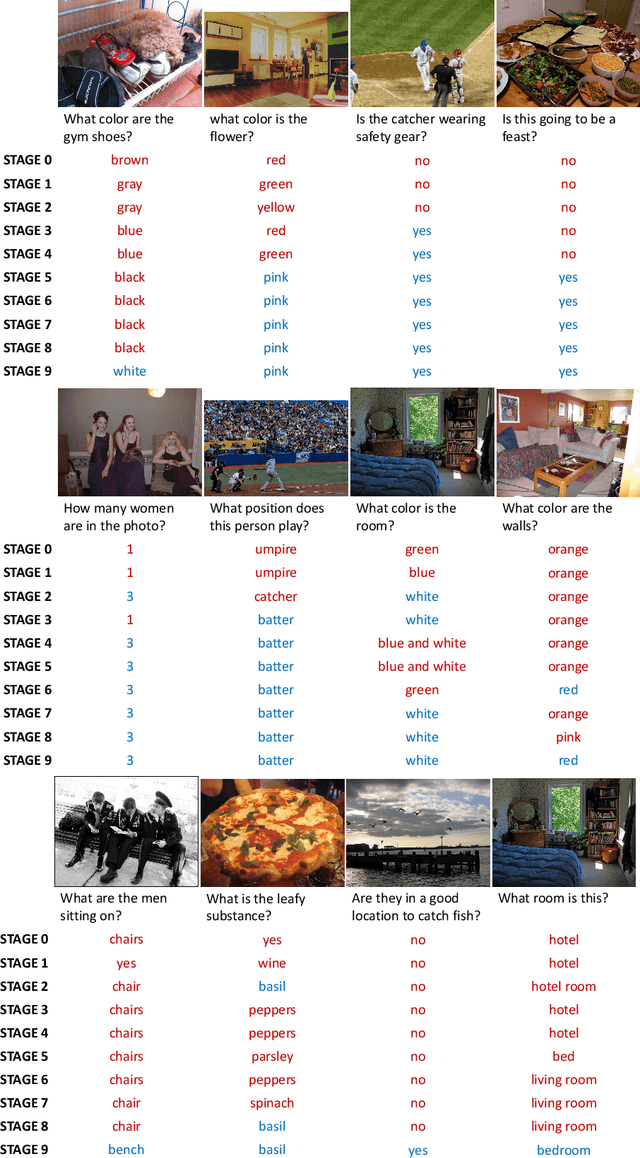
Constructing a large-scale labeled dataset in the real world, especially for high-level tasks (eg, Visual Question Answering), can be expensive and time-consuming. In addition, with the ever-growing amounts of data and architecture complexity, Active Learning has become an important aspect of computer vision research. In this work, we address Active Learning in the multi-modal setting of Visual Question Answering (VQA). In light of the multi-modal inputs, image and question, we propose a novel method for effective sample acquisition through the use of ad hoc single-modal branches for each input to leverage its information. Our mutual information based sample acquisition strategy Single-Modal Entropic Measure (SMEM) in addition to our self-distillation technique enables the sample acquisitor to exploit all present modalities and find the most informative samples. Our novel idea is simple to implement, cost-efficient, and readily adaptable to other multi-modal tasks. We confirm our findings on various VQA datasets through state-of-the-art performance by comparing to existing Active Learning baselines.
Graph Spectral Embedding for Parsimonious Transmission of Multivariate Time Series
Oct 10, 2019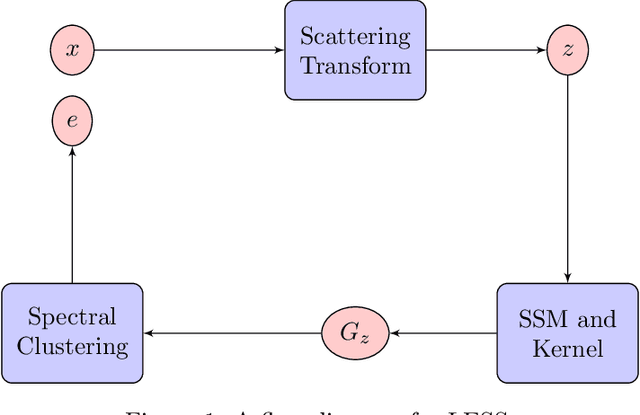
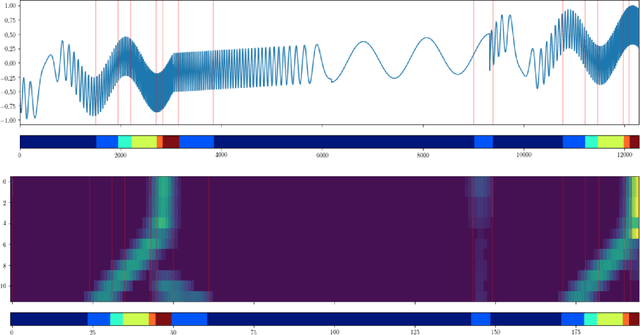
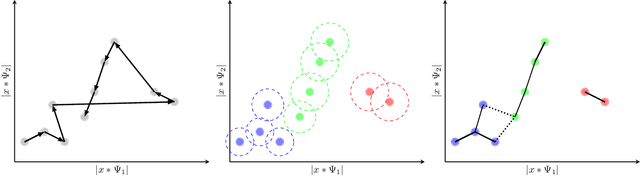
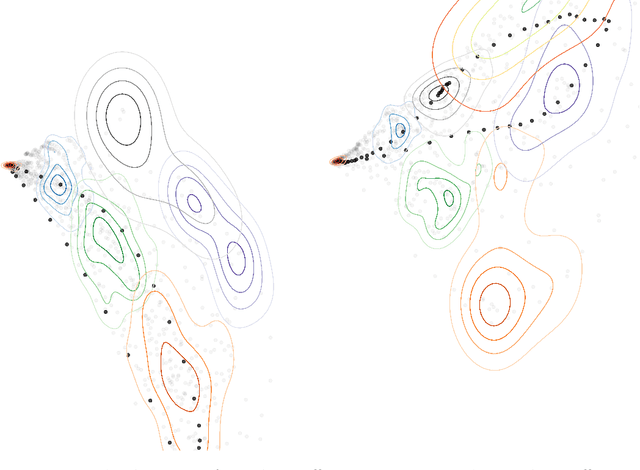
We propose a graph spectral representation of time series data that 1) is parsimoniously encoded to user-demanded resolution; 2) is unsupervised and performant in data-constrained scenarios; 3) captures event and event-transition structure within the time series; and 4) has near-linear computational complexity in both signal length and ambient dimension. This representation, which we call Laplacian Events Signal Segmentation (LESS), can be computed on time series of arbitrary dimension and originating from sensors of arbitrary type. Hence, time series originating from sensors of heterogeneous type can be compressed to levels demanded by constrained-communication environments, before being fused at a common center. Temporal dynamics of the data is summarized without explicit partitioning or probabilistic modeling. As a proof-of-principle, we apply this technique on high dimensional wavelet coefficients computed from the Free Spoken Digit Dataset to generate a memory efficient representation that is interpretable. Due to its unsupervised and non-parametric nature, LESS representations remain performant in the digit classification task despite the absence of labels and limited data.
A New Image Codec Paradigm for Human and Machine Uses
Dec 19, 2021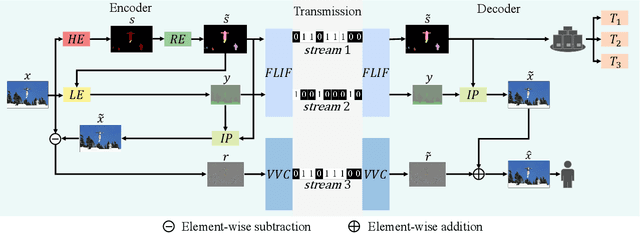
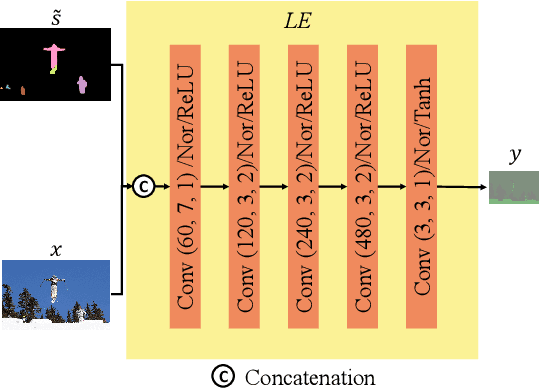
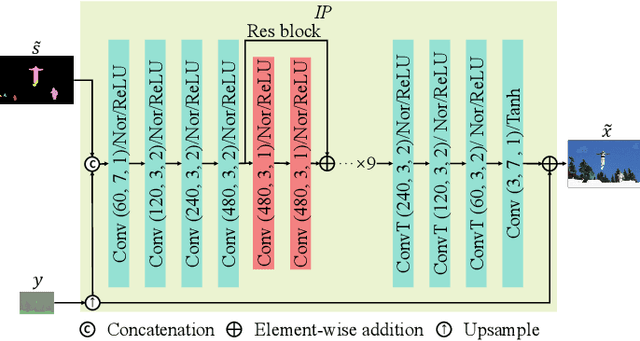
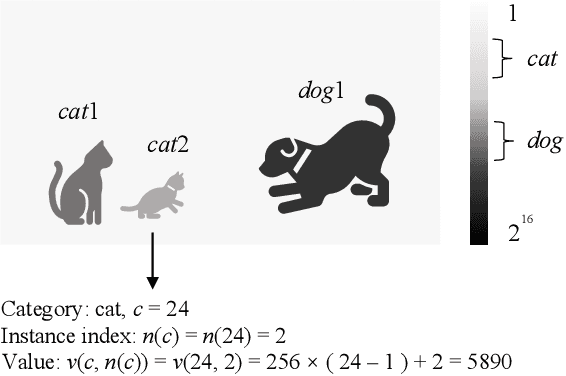
With the AI of Things (AIoT) development, a huge amount of visual data, e.g., images and videos, are produced in our daily work and life. These visual data are not only used for human viewing or understanding but also for machine analysis or decision-making, e.g., intelligent surveillance, automated vehicles, and many other smart city applications. To this end, a new image codec paradigm for both human and machine uses is proposed in this work. Firstly, the high-level instance segmentation map and the low-level signal features are extracted with neural networks. Then, the instance segmentation map is further represented as a profile with the proposed 16-bit gray-scale representation. After that, both 16-bit gray-scale profile and signal features are encoded with a lossless codec. Meanwhile, an image predictor is designed and trained to achieve the general-quality image reconstruction with the 16-bit gray-scale profile and signal features. Finally, the residual map between the original image and the predicted one is compressed with a lossy codec, used for high-quality image reconstruction. With such designs, on the one hand, we can achieve scalable image compression to meet the requirements of different human consumption; on the other hand, we can directly achieve several machine vision tasks at the decoder side with the decoded 16-bit gray-scale profile, e.g., object classification, detection, and segmentation. Experimental results show that the proposed codec achieves comparable results as most learning-based codecs and outperforms the traditional codecs (e.g., BPG and JPEG2000) in terms of PSNR and MS-SSIM for image reconstruction. At the same time, it outperforms the existing codecs in terms of the mAP for object detection and segmentation.
Simulating the Effects of Eco-Friendly Transportation Selections for Air Pollution Reduction
Sep 10, 2021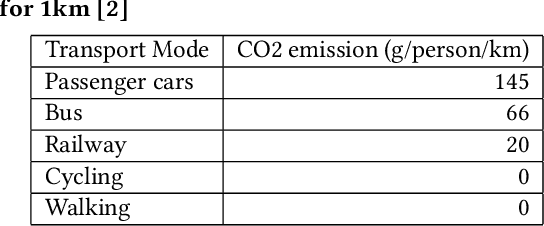
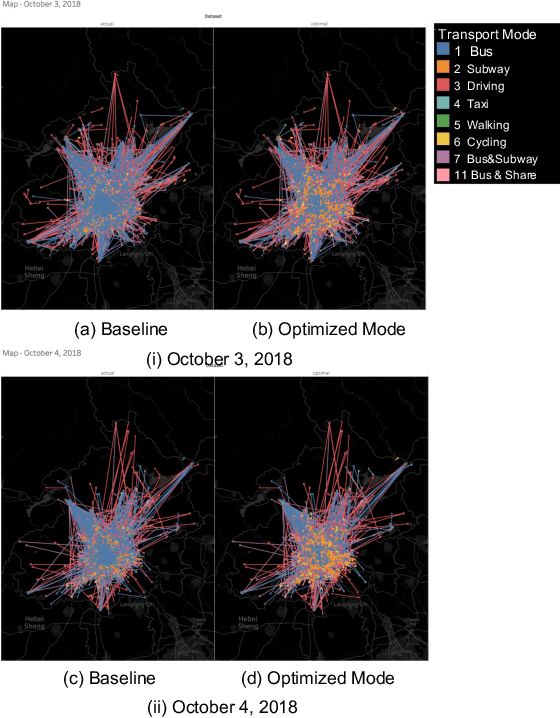
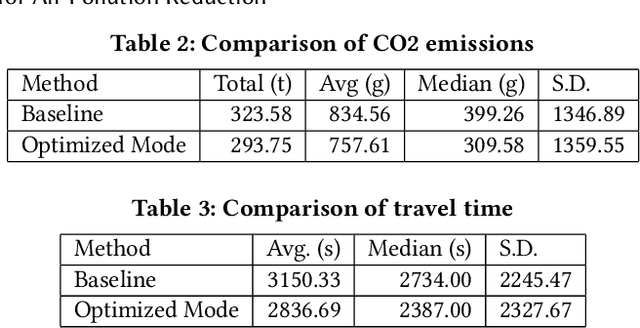

Reducing air pollution, such as CO2 and PM2.5 emissions, is one of the most important issues for many countries worldwide. Selecting an environmentally friendly transport mode can be an effective approach of individuals to reduce air pollution in daily life. In this study, we propose a method to simulate the effectiveness of an eco-friendly transport mode selection for reducing air pollution by using map search logs. We formulate the transport mode selection as a combinatorial optimization problem with the constraints regarding the total amount of CO2 emissions as an example of air pollution and the average travel time. The optimization results show that the total amount of CO2 emissions can be reduced by 9.23%, whereas the average travel time can in fact be reduced by 9.96%. Our research proposal won first prize in Regular Machine Learning Competition Track Task 2 at KDD Cup 2019.
Lidar with Velocity: Motion Distortion Correction of Point Clouds from Oscillating Scanning Lidars
Nov 18, 2021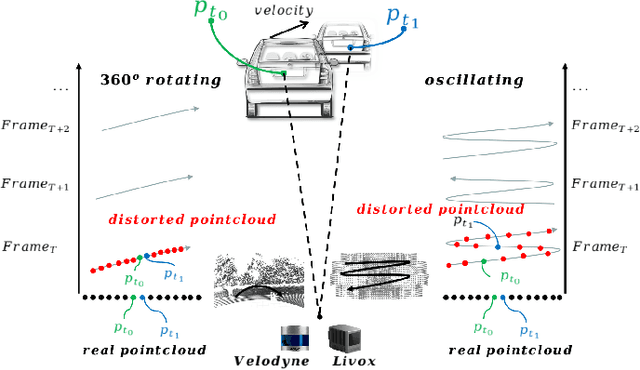
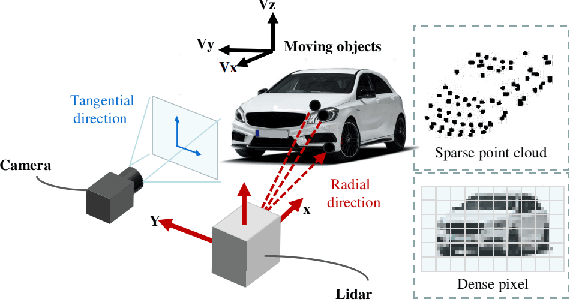
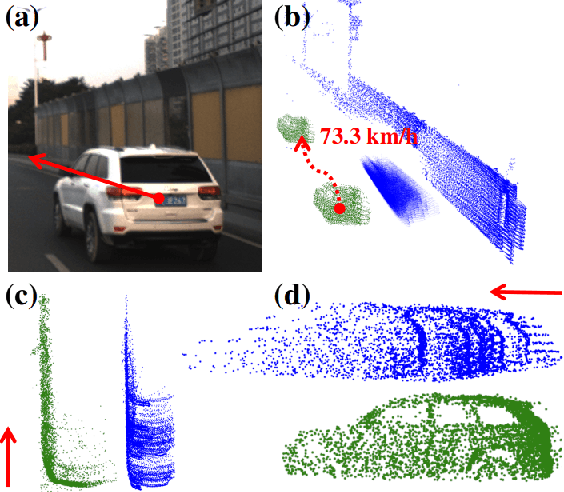
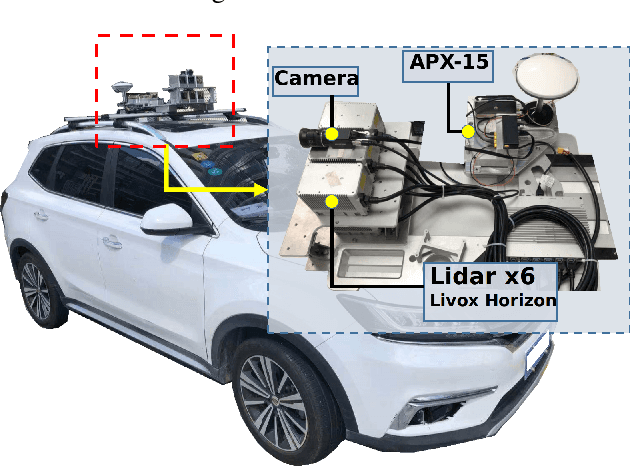
Lidar point cloud distortion from moving object is an important problem in autonomous driving, and recently becomes even more demanding with the emerging of newer lidars, which feature back-and-forth scanning patterns. Accurately estimating moving object velocity would not only provide a tracking capability but also correct the point cloud distortion with more accurate description of the moving object. Since lidar measures the time-of-flight distance but with a sparse angular resolution, the measurement is precise in the radial measurement but lacks angularly. Camera on the other hand provides a dense angular resolution. In this paper, Gaussian-based lidar and camera fusion is proposed to estimate the full velocity and correct the lidar distortion. A probabilistic Kalman-filter framework is provided to track the moving objects, estimate their velocities and simultaneously correct the point clouds distortions. The framework is evaluated on real road data and the fusion method outperforms the traditional ICP-based and point-cloud only method. The complete working framework is open-sourced (https://github.com/ISEE-Technology/lidar-with-velocity) to accelerate the adoption of the emerging lidars.
R-TOD: Real-Time Object Detector with Minimized End-to-End Delay for Autonomous Driving
Oct 23, 2020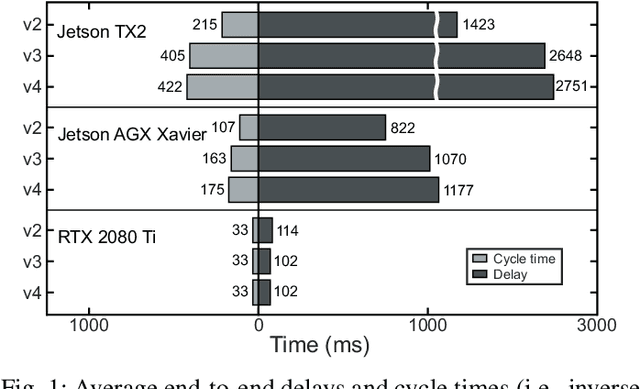
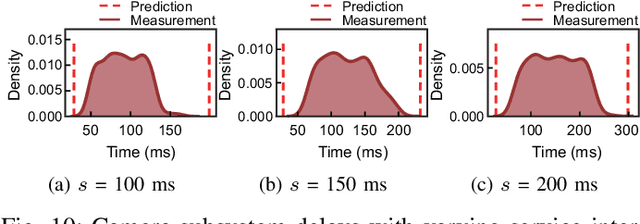
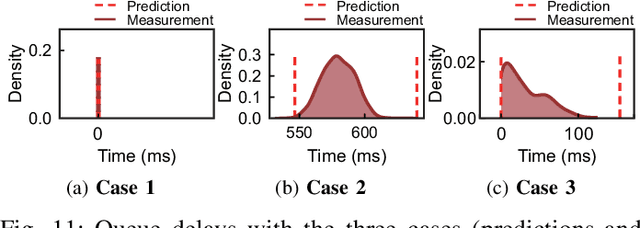
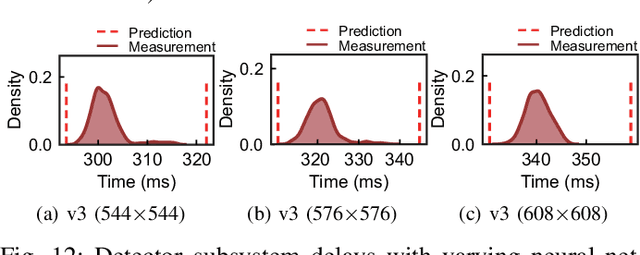
For realizing safe autonomous driving, the end-to-end delays of real-time object detection systems should be thoroughly analyzed and minimized. However, despite recent development of neural networks with minimized inference delays, surprisingly little attention has been paid to their end-to-end delays from an object's appearance until its detection is reported. With this motivation, this paper aims to provide more comprehensive understanding of the end-to-end delay, through which precise best- and worst-case delay predictions are formulated, and three optimization methods are implemented: (i) on-demand capture, (ii) zero-slack pipeline, and (iii) contention-free pipeline. Our experimental results show a 76% reduction in the end-to-end delay of Darknet YOLO (You Only Look Once) v3 (from 1070 ms to 261 ms), thereby demonstrating the great potential of exploiting the end-to-end delay analysis for autonomous driving. Furthermore, as we only modify the system architecture and do not change the neural network architecture itself, our approach incurs no penalty on the detection accuracy.
Stock Portfolio Optimization Using a Deep Learning LSTM Model
Nov 08, 2021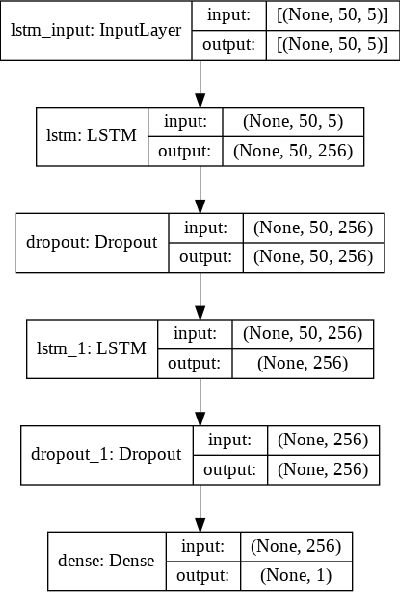
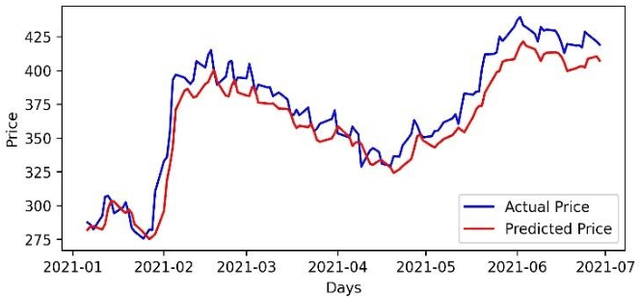
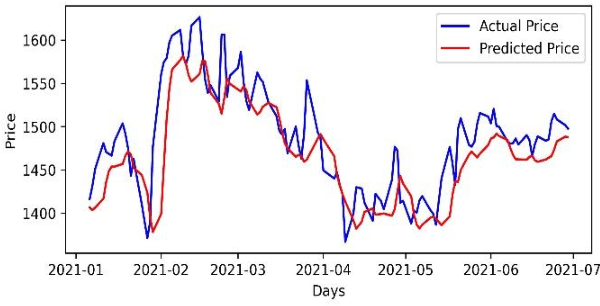
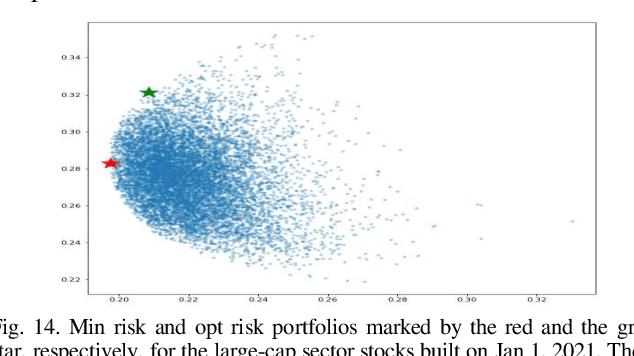
Predicting future stock prices and their movement patterns is a complex problem. Hence, building a portfolio of capital assets using the predicted prices to achieve the optimization between its return and risk is an even more difficult task. This work has carried out an analysis of the time series of the historical prices of the top five stocks from the nine different sectors of the Indian stock market from January 1, 2016, to December 31, 2020. Optimum portfolios are built for each of these sectors. For predicting future stock prices, a long-and-short-term memory (LSTM) model is also designed and fine-tuned. After five months of the portfolio construction, the actual and the predicted returns and risks of each portfolio are computed. The predicted and the actual returns of each portfolio are found to be high, indicating the high precision of the LSTM model.
Bayesian Framework for Gradient Leakage
Nov 08, 2021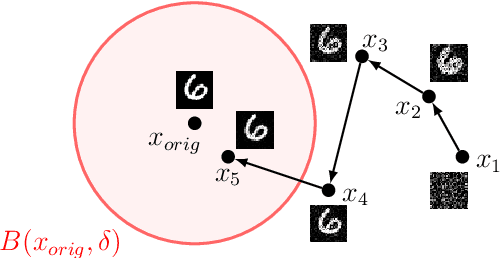

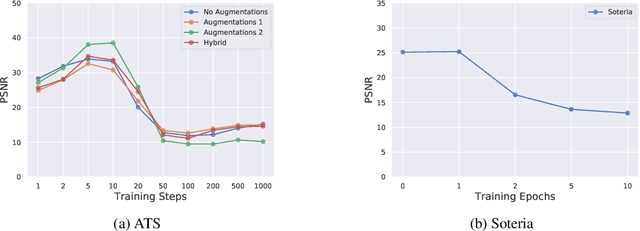
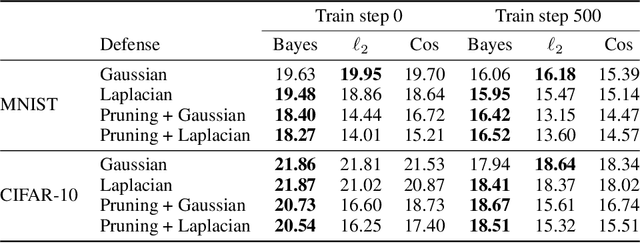
Federated learning is an established method for training machine learning models without sharing training data. However, recent work has shown that it cannot guarantee data privacy as shared gradients can still leak sensitive information. To formalize the problem of gradient leakage, we propose a theoretical framework that enables, for the first time, analysis of the Bayes optimal adversary phrased as an optimization problem. We demonstrate that existing leakage attacks can be seen as approximations of this optimal adversary with different assumptions on the probability distributions of the input data and gradients. Our experiments confirm the effectiveness of the Bayes optimal adversary when it has knowledge of the underlying distribution. Further, our experimental evaluation shows that several existing heuristic defenses are not effective against stronger attacks, especially early in the training process. Thus, our findings indicate that the construction of more effective defenses and their evaluation remains an open problem.