 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Traversing the Local Polytopes of ReLU Neural Networks: A Unified Approach for Network Verification
Nov 17, 2021
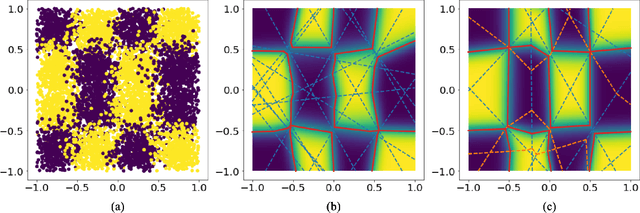
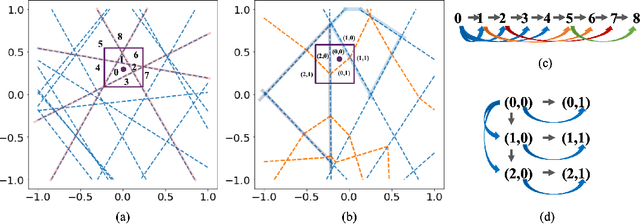
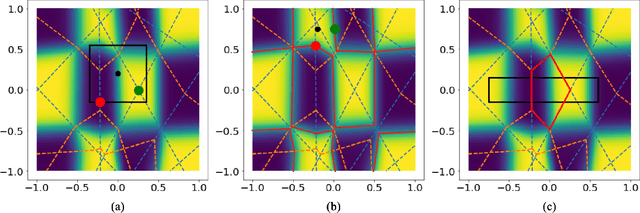
Although neural networks (NNs) with ReLU activation functions have found success in a wide range of applications, their adoption in risk-sensitive settings has been limited by the concerns on robustness and interpretability. Previous works to examine robustness and to improve interpretability partially exploited the piecewise linear function form of ReLU NNs. In this paper, we explore the unique topological structure that ReLU NNs create in the input space, identifying the adjacency among the partitioned local polytopes and developing a traversing algorithm based on this adjacency. Our polytope traversing algorithm can be adapted to verify a wide range of network properties related to robustness and interpretability, providing an unified approach to examine the network behavior. As the traversing algorithm explicitly visits all local polytopes, it returns a clear and full picture of the network behavior within the traversed region. The time and space complexity of the traversing algorithm is determined by the number of a ReLU NN's partitioning hyperplanes passing through the traversing region.
MVLidarNet: Real-Time Multi-Class Scene Understanding for Autonomous Driving Using Multiple Views
Jun 09, 2020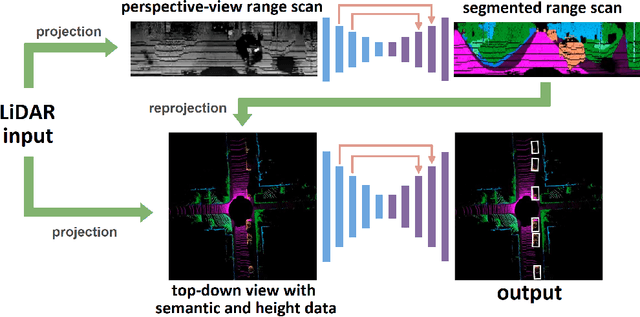
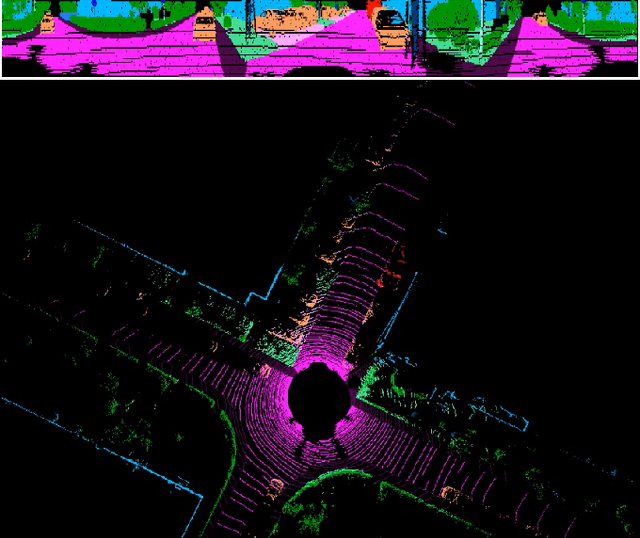


Autonomous driving requires the inference of actionable information such as detecting and classifying objects, and determining the drivable space. To this end, we present a two-stage deep neural network (MVLidarNet) for multi-class object detection and drivable segmentation using multiple views of a single LiDAR point cloud. The first stage processes the point cloud projected onto a perspective view in order to semantically segment the scene. The second stage then processes the point cloud (along with semantic labels from the first stage) projected onto a bird's eye view, to detect and classify objects. Both stages are simple encoder-decoders. We show that our multi-view, multi-stage, multi-class approach is able to detect and classify objects while simultaneously determining the drivable space using a single LiDAR scan as input, in challenging scenes with more than one hundred vehicles and pedestrians at a time. The system operates efficiently at 150 fps on an embedded GPU designed for a self-driving car, including a postprocessing step to maintain identities over time. We show results on both KITTI and a much larger internal dataset, thus demonstrating the method's ability to scale by an order of magnitude.
Classification-Then-Grounding: Reformulating Video Scene Graphs as Temporal Bipartite Graphs
Dec 08, 2021
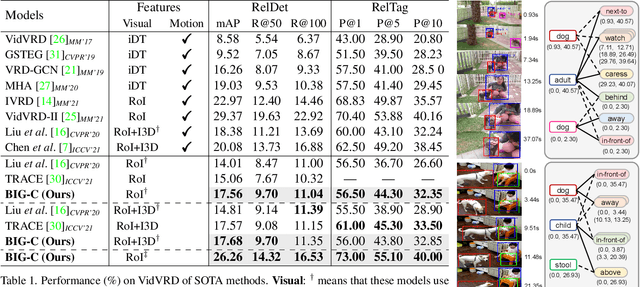
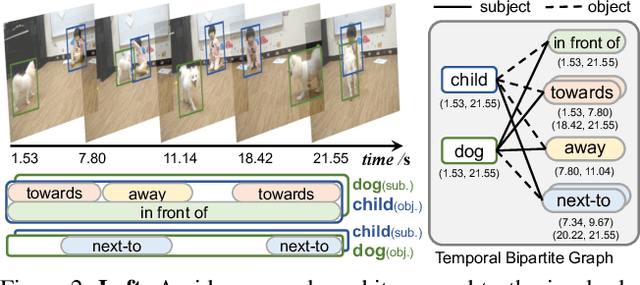
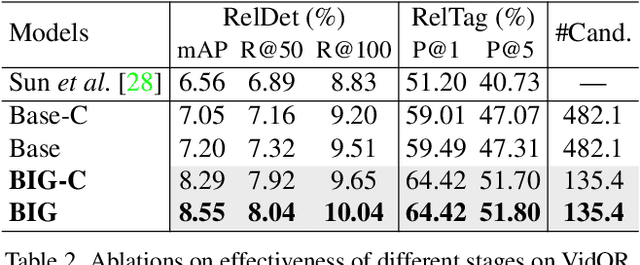
Today's VidSGG models are all proposal-based methods, i.e., they first generate numerous paired subject-object snippets as proposals, and then conduct predicate classification for each proposal. In this paper, we argue that this prevalent proposal-based framework has three inherent drawbacks: 1) The ground-truth predicate labels for proposals are partially correct. 2) They break the high-order relations among different predicate instances of a same subject-object pair. 3) VidSGG performance is upper-bounded by the quality of the proposals. To this end, we propose a new classification-then-grounding framework for VidSGG, which can avoid all the three overlooked drawbacks. Meanwhile, under this framework, we reformulate the video scene graphs as temporal bipartite graphs, where the entities and predicates are two types of nodes with time slots, and the edges denote different semantic roles between these nodes. This formulation takes full advantage of our new framework. Accordingly, we further propose a novel BIpartite Graph based SGG model: BIG. Specifically, BIG consists of two parts: a classification stage and a grounding stage, where the former aims to classify the categories of all the nodes and the edges, and the latter tries to localize the temporal location of each relation instance. Extensive ablations on two VidSGG datasets have attested to the effectiveness of our framework and BIG.
TUNet: A Block-online Bandwidth Extension Model based on Transformers and Self-supervised Pretraining
Oct 26, 2021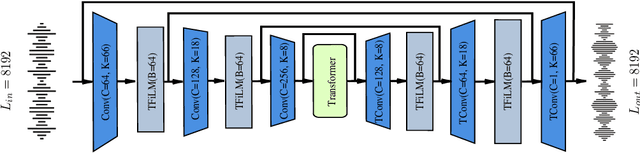
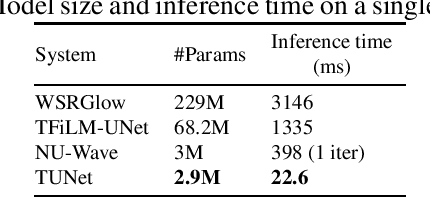
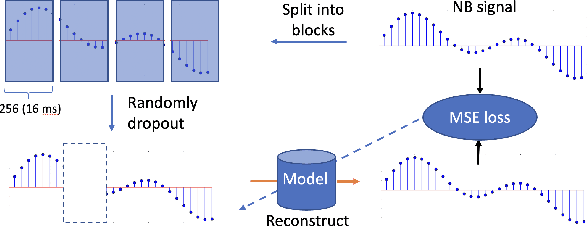
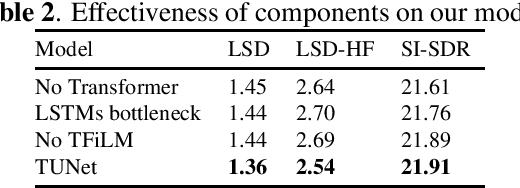
We introduce a block-online variant of the temporal feature-wise linear modulation (TFiLM) model to achieve bandwidth extension. The proposed architecture simplifies the UNet backbone of the TFiLM to reduce inference time and employs an efficient transformer at the bottleneck to alleviate performance degradation. We also utilize self-supervised pretraining and data augmentation to enhance the quality of bandwidth extended signals and reduce the sensitivity with respect to downsampling methods. Experiment results on the VCTK dataset show that the proposed method outperforms several recent baselines in terms of spectral distance and source-to-distortion ratio. Pretraining and filter augmentation also help stabilize and enhance the overall performance.
Transformaly -- Two (Feature Spaces) Are Better Than One
Dec 08, 2021
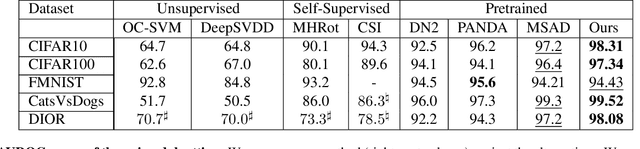
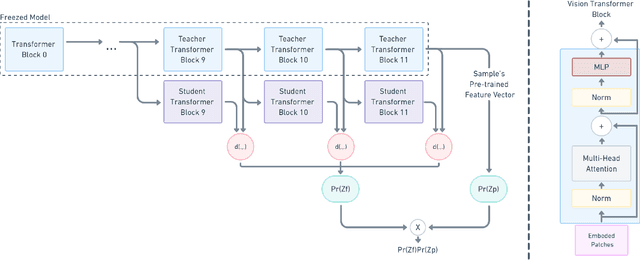
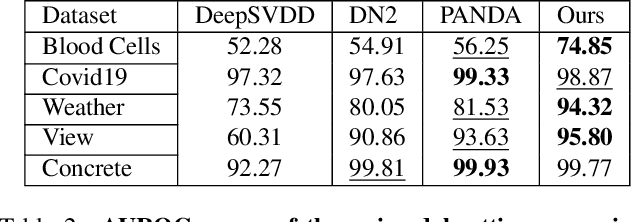
Anomaly detection is a well-established research area that seeks to identify samples outside of a predetermined distribution. An anomaly detection pipeline is comprised of two main stages: (1) feature extraction and (2) normality score assignment. Recent papers used pre-trained networks for feature extraction achieving state-of-the-art results. However, the use of pre-trained networks does not fully-utilize the normal samples that are available at train time. This paper suggests taking advantage of this information by using teacher-student training. In our setting, a pretrained teacher network is used to train a student network on the normal training samples. Since the student network is trained only on normal samples, it is expected to deviate from the teacher network in abnormal cases. This difference can serve as a complementary representation to the pre-trained feature vector. Our method -- Transformaly -- exploits a pre-trained Vision Transformer (ViT) to extract both feature vectors: the pre-trained (agnostic) features and the teacher-student (fine-tuned) features. We report state-of-the-art AUROC results in both the common unimodal setting, where one class is considered normal and the rest are considered abnormal, and the multimodal setting, where all classes but one are considered normal, and just one class is considered abnormal. The code is available at https://github.com/MatanCohen1/Transformaly.
Adaptive exponential power distribution with moving estimator for nonstationary time series
Mar 04, 2020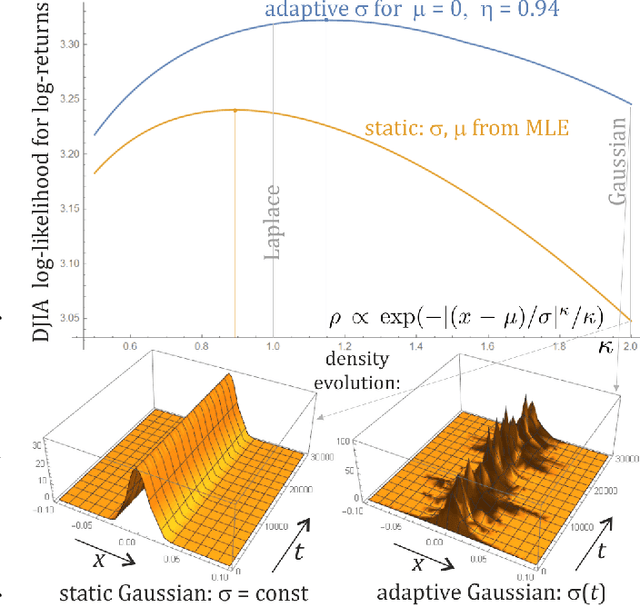
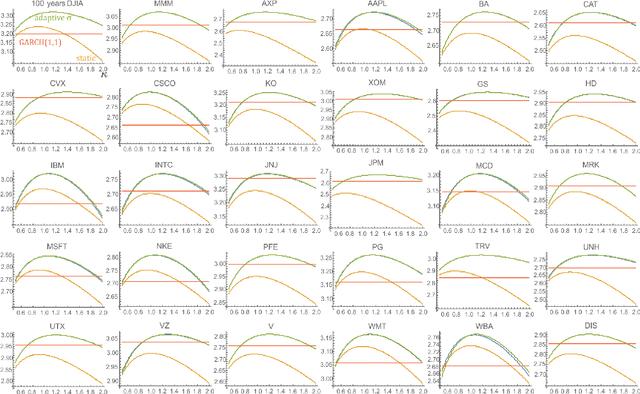
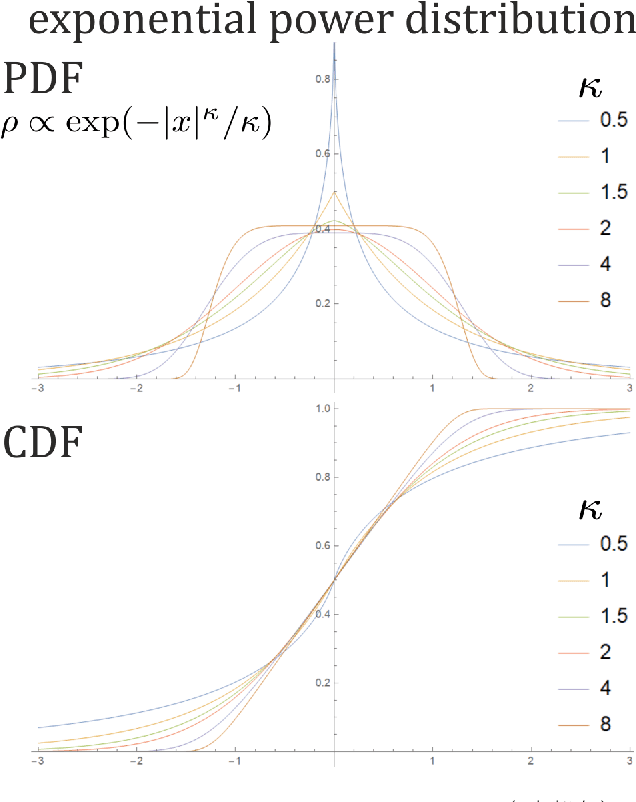
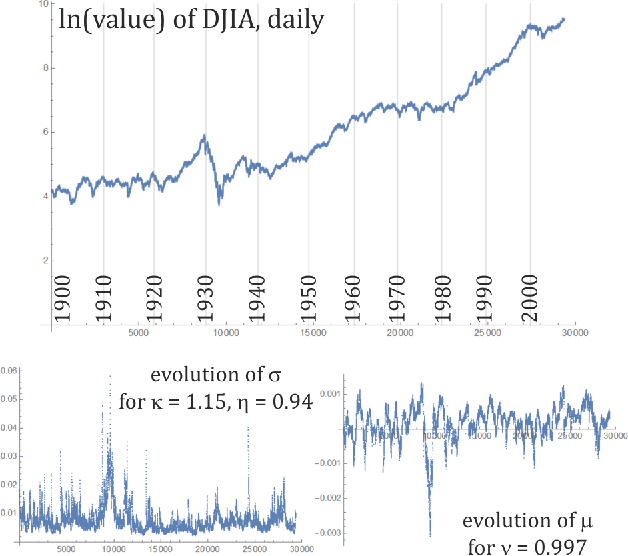
While standard estimation assumes that all datapoints are from probability distribution of the same fixed parameters $\theta$, we will focus on maximum likelihood (ML) adaptive estimation for nonstationary time series: separately estimating parameters $\theta_T$ for each time $T$ based on the earlier values $(x_t)_{t<T}$ using (exponential) moving ML estimator $\theta_T=\arg\max_\theta l_T$ for $l_T=\sum_{t<T} \eta^{T-t} \ln(\rho_\theta (x_t))$ and some $\eta\in(0,1]$. Computational cost of such moving estimator is generally much higher as we need to optimize log-likelihood multiple times, however, in many cases it can be made inexpensive thanks to dependencies. We focus on such example: exponential power distribution (EPD) $\rho(x)\propto \exp(-|(x-\mu)/\sigma|^\kappa/\kappa)$ family, which covers wide range of tail behavior like Gaussian ($\kappa=2$) or Laplace ($\kappa=1$) distribution. It is also convenient for such adaptive estimation of scale parameter $\sigma$ as its standard ML estimation is $\sigma^\kappa$ being average $\|x-\mu\|^\kappa$. By just replacing average with exponential moving average: $(\sigma_{T+1})^\kappa=\eta(\sigma_T)^\kappa +(1-\eta)|x_T-\mu|^\kappa$ we can inexpensively make it adaptive. It is tested on daily log-return series for DJIA companies, leading to essentially better log-likelihoods than standard (static) estimation, surprisingly with optimal $\kappa$ tails types varying between companies. Presented general alternative estimation philosophy provides tools which might be useful for building better models for analysis of nonstationary time-series.
CAPITAL: Optimal Subgroup Identification via Constrained Policy Tree Search
Oct 11, 2021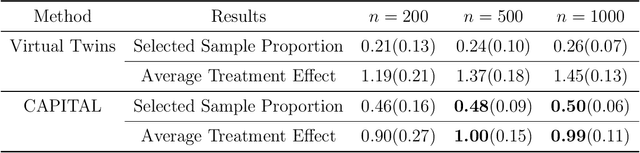
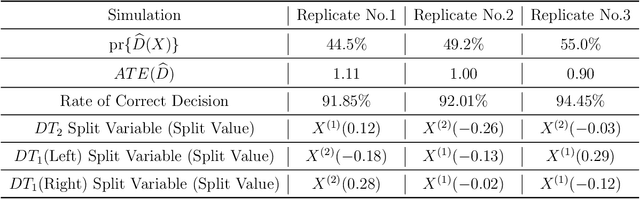
Personalized medicine, a paradigm of medicine tailored to a patient's characteristics, is an increasingly attractive field in health care. An important goal of personalized medicine is to identify a subgroup of patients, based on baseline covariates, that benefits more from the targeted treatment than other comparative treatments. Most of the current subgroup identification methods only focus on obtaining a subgroup with an enhanced treatment effect without paying attention to subgroup size. Yet, a clinically meaningful subgroup learning approach should identify the maximum number of patients who can benefit from the better treatment. In this paper, we present an optimal subgroup selection rule (SSR) that maximizes the number of selected patients, and in the meantime, achieves the pre-specified clinically meaningful mean outcome, such as the average treatment effect. We derive two equivalent theoretical forms of the optimal SSR based on the contrast function that describes the treatment-covariates interaction in the outcome. We further propose a ConstrAined PolIcy Tree seArch aLgorithm (CAPITAL) to find the optimal SSR within the interpretable decision tree class. The proposed method is flexible to handle multiple constraints that penalize the inclusion of patients with negative treatment effects, and to address time to event data using the restricted mean survival time as the clinically interesting mean outcome. Extensive simulations, comparison studies, and real data applications are conducted to demonstrate the validity and utility of our method.
Objective hearing threshold identification from auditory brainstem response measurements using supervised and self-supervised approaches
Dec 16, 2021
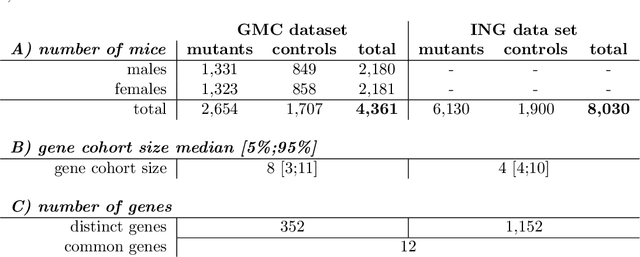
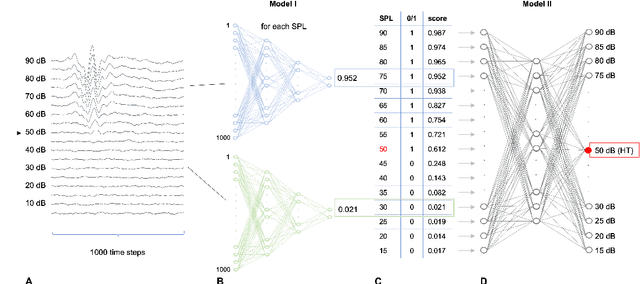
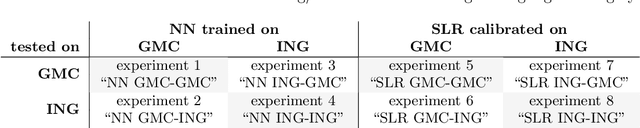
Hearing loss is a major health problem and psychological burden in humans. Mouse models offer a possibility to elucidate genes involved in the underlying developmental and pathophysiological mechanisms of hearing impairment. To this end, large-scale mouse phenotyping programs include auditory phenotyping of single-gene knockout mouse lines. Using the auditory brainstem response (ABR) procedure, the German Mouse Clinic and similar facilities worldwide have produced large, uniform data sets of averaged ABR raw data of mutant and wildtype mice. In the course of standard ABR analysis, hearing thresholds are assessed visually by trained staff from series of signal curves of increasing sound pressure level. This is time-consuming and prone to be biased by the reader as well as the graphical display quality and scale. In an attempt to reduce workload and improve quality and reproducibility, we developed and compared two methods for automated hearing threshold identification from averaged ABR raw data: a supervised approach involving two combined neural networks trained on human-generated labels and a self-supervised approach, which exploits the signal power spectrum and combines random forest sound level estimation with a piece-wise curve fitting algorithm for threshold finding. We show that both models work well, outperform human threshold detection, and are suitable for fast, reliable, and unbiased hearing threshold detection and quality control. In a high-throughput mouse phenotyping environment, both methods perform well as part of an automated end-to-end screening pipeline to detect candidate genes for hearing involvement. Code for both models as well as data used for this work are freely available.
Neural Spectrahedra and Semidefinite Lifts: Global Convex Optimization of Polynomial Activation Neural Networks in Fully Polynomial-Time
Jan 07, 2021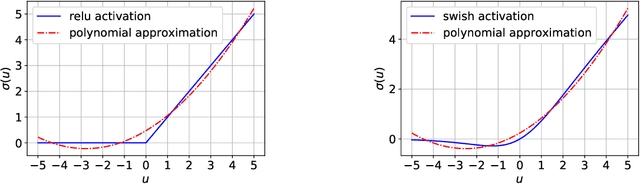
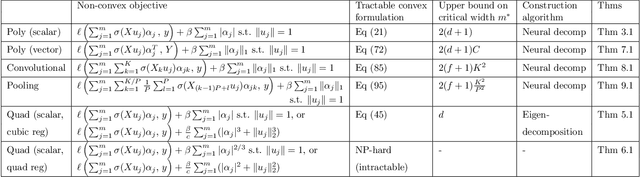

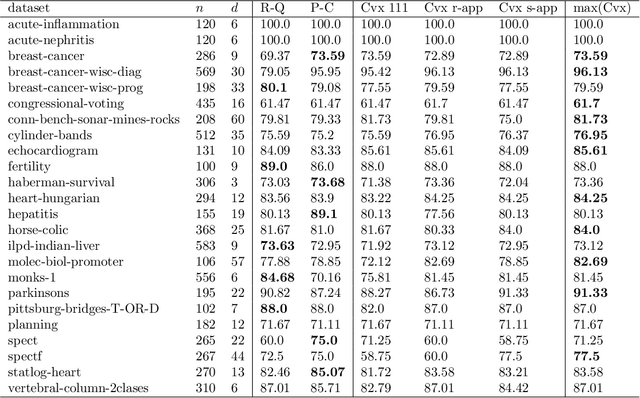
The training of two-layer neural networks with nonlinear activation functions is an important non-convex optimization problem with numerous applications and promising performance in layerwise deep learning. In this paper, we develop exact convex optimization formulations for two-layer neural networks with second degree polynomial activations based on semidefinite programming. Remarkably, we show that semidefinite lifting is always exact and therefore computational complexity for global optimization is polynomial in the input dimension and sample size for all input data. The developed convex formulations are proven to achieve the same global optimal solution set as their non-convex counterparts. More specifically, the globally optimal two-layer neural network with polynomial activations can be found by solving a semidefinite program (SDP) and decomposing the solution using a procedure we call Neural Decomposition. Moreover, the choice of regularizers plays a crucial role in the computational tractability of neural network training. We show that the standard weight decay regularization formulation is NP-hard, whereas other simple convex penalties render the problem tractable in polynomial time via convex programming. We extend the results beyond the fully connected architecture to different neural network architectures including networks with vector outputs and convolutional architectures with pooling. We provide extensive numerical simulations showing that the standard backpropagation approach often fails to achieve the global optimum of the training loss. The proposed approach is significantly faster to obtain better test accuracy compared to the standard backpropagation procedure.
GCN-SE: Attention as Explainability for Node Classification in Dynamic Graphs
Oct 11, 2021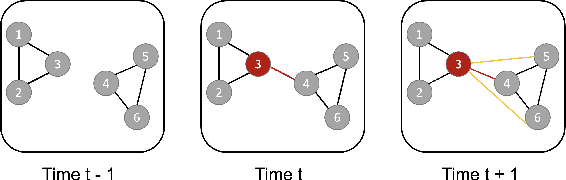
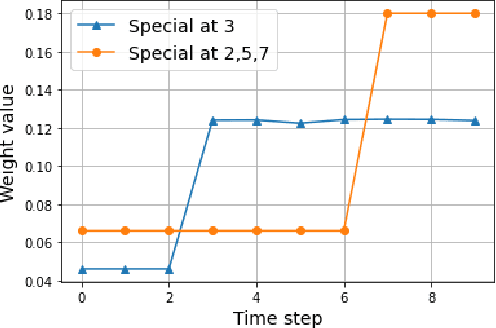
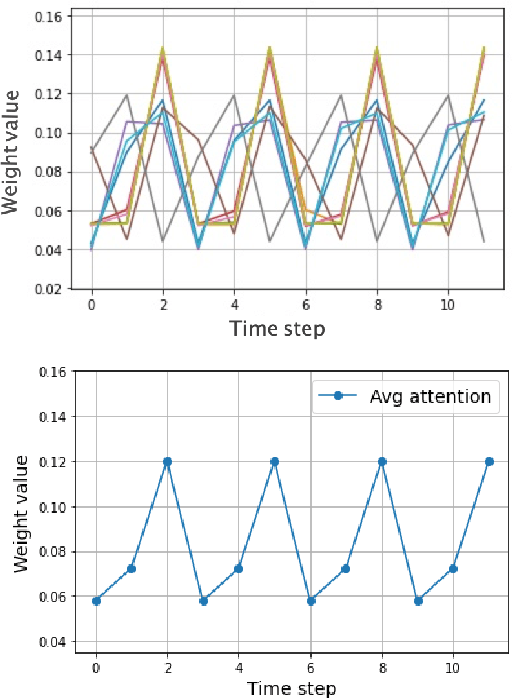
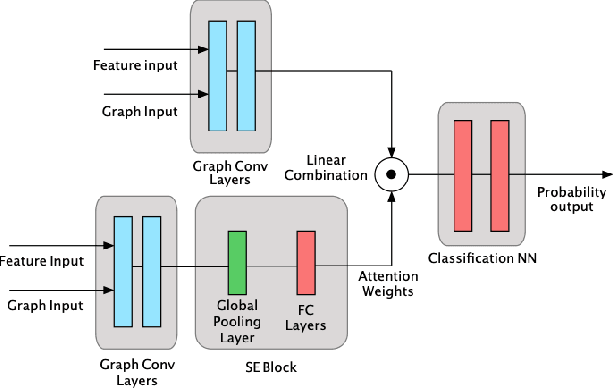
Graph Convolutional Networks (GCNs) are a popular method from graph representation learning that have proved effective for tasks like node classification tasks. Although typical GCN models focus on classifying nodes within a static graph, several recent variants propose node classification in dynamic graphs whose topologies and node attributes change over time, e.g., social networks with dynamic relationships, or literature citation networks with changing co-authorships. These works, however, do not fully address the challenge of flexibly assigning different importance to snapshots of the graph at different times, which depending on the graph dynamics may have more or less predictive power on the labels. We address this challenge by proposing a new method, GCN-SE, that attaches a set of learnable attention weights to graph snapshots at different times, inspired by Squeeze and Excitation Net (SE-Net). We show that GCN-SE outperforms previously proposed node classification methods on a variety of graph datasets. To verify the effectiveness of the attention weight in determining the importance of different graph snapshots, we adapt perturbation-based methods from the field of explainable machine learning to graphical settings and evaluate the correlation between the attention weights learned by GCN-SE and the importance of different snapshots over time. These experiments demonstrate that GCN-SE can in fact identify different snapshots' predictive power for dynamic node classification.