 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Category-orthogonal object features guide information processing in recurrent neural networks trained for object categorization
Nov 15, 2021
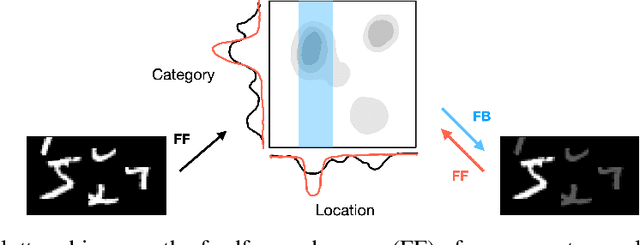
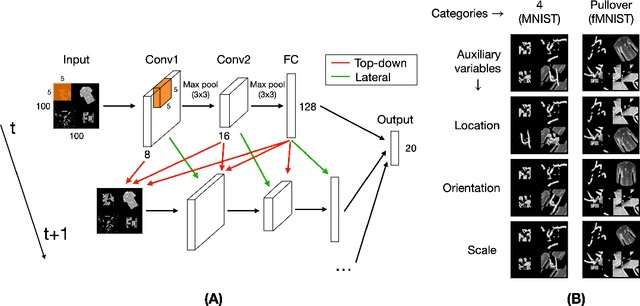
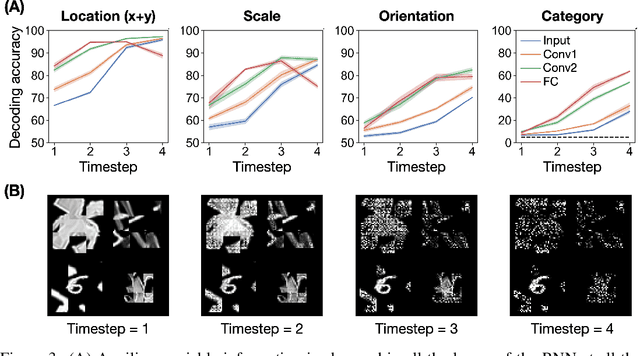
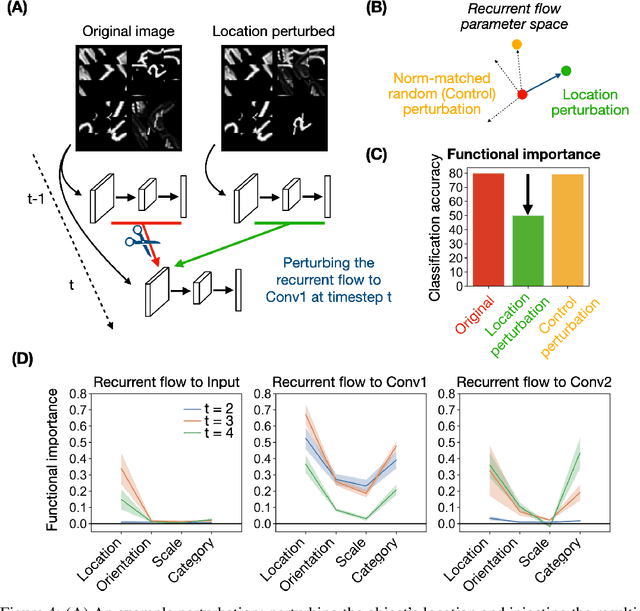
Recurrent neural networks (RNNs) have been shown to perform better than feedforward architectures in visual object categorization tasks, especially in challenging conditions such as cluttered images. However, little is known about the exact computational role of recurrent information flow in these conditions. Here we test RNNs trained for object categorization on the hypothesis that recurrence iteratively aids object categorization via the communication of category-orthogonal auxiliary variables (the location, orientation, and scale of the object). Using diagnostic linear readouts, we find that: (a) information about auxiliary variables increases across time in all network layers, (b) this information is indeed present in the recurrent information flow, and (c) its manipulation significantly affects task performance. These observations confirm the hypothesis that category-orthogonal auxiliary variable information is conveyed through recurrent connectivity and is used to optimize category inference in cluttered environments.
Geometry-Guided Progressive NeRF for Generalizable and Efficient Neural Human Rendering
Dec 08, 2021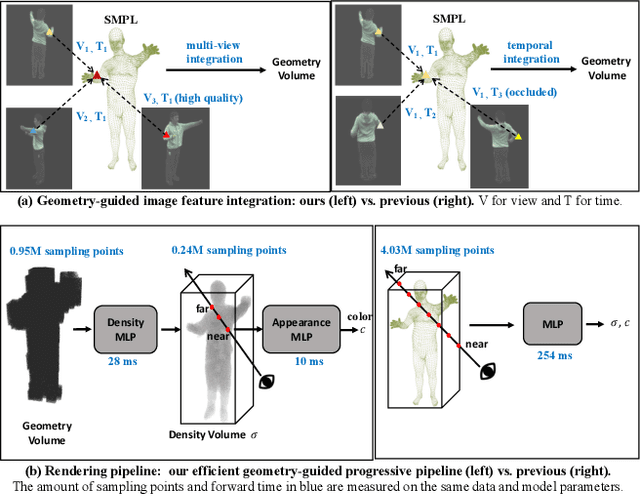
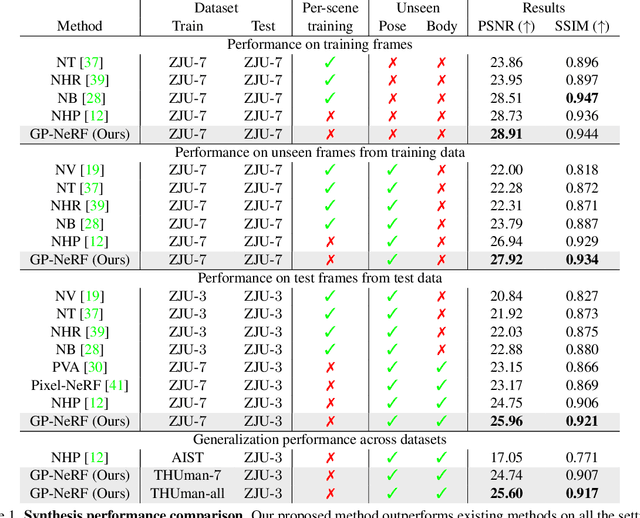
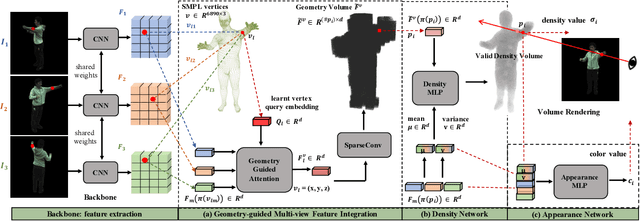
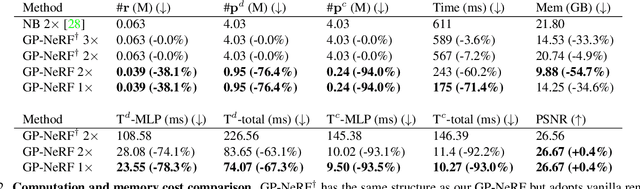
In this work we develop a generalizable and efficient Neural Radiance Field (NeRF) pipeline for high-fidelity free-viewpoint human body synthesis under settings with sparse camera views. Though existing NeRF-based methods can synthesize rather realistic details for human body, they tend to produce poor results when the input has self-occlusion, especially for unseen humans under sparse views. Moreover, these methods often require a large number of sampling points for rendering, which leads to low efficiency and limits their real-world applicability. To address these challenges, we propose a Geometry-guided Progressive NeRF~(GP-NeRF). In particular, to better tackle self-occlusion, we devise a geometry-guided multi-view feature integration approach that utilizes the estimated geometry prior to integrate the incomplete information from input views and construct a complete geometry volume for the target human body. Meanwhile, for achieving higher rendering efficiency, we introduce a geometry-guided progressive rendering pipeline, which leverages the geometric feature volume and the predicted density values to progressively reduce the number of sampling points and speed up the rendering process. Experiments on the ZJU-MoCap and THUman datasets show that our method outperforms the state-of-the-arts significantly across multiple generalization settings, while the time cost is reduced >70% via applying our efficient progressive rendering pipeline.
Holistic Interpretation of Public Scenes Using Computer Vision and Temporal Graphs to Identify Social Distancing Violations
Dec 13, 2021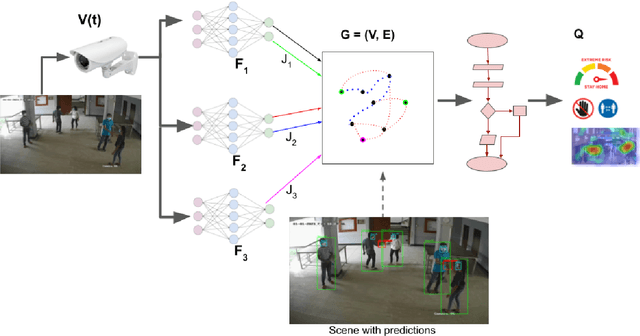

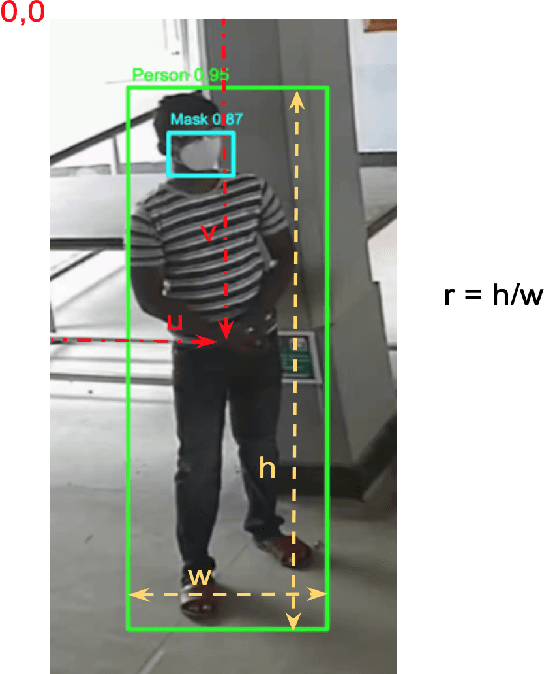

The COVID-19 pandemic has caused an unprecedented global public health crisis. Given its inherent nature, social distancing measures are proposed as the primary strategies to curb the spread of this pandemic. Therefore, identifying situations where these protocols are violated, has implications for curtailing the spread of the disease and promoting a sustainable lifestyle. This paper proposes a novel computer vision-based system to analyze CCTV footage to provide a threat level assessment of COVID-19 spread. The system strives to holistically capture and interpret the information content of CCTV footage spanning multiple frames to recognize instances of various violations of social distancing protocols, across time and space, as well as identification of group behaviors. This functionality is achieved primarily by utilizing a temporal graph-based structure to represent the information of the CCTV footage and a strategy to holistically interpret the graph and quantify the threat level of the given scene. The individual components are tested and validated on a range of scenarios and the complete system is tested against human expert opinion. The results reflect the dependence of the threat level on people, their physical proximity, interactions, protective clothing, and group dynamics. The system performance has an accuracy of 76%, thus enabling a deployable threat monitoring system in cities, to permit normalcy and sustainability in the society.
Learned Image Compression with Separate Hyperprior Decoders
Oct 31, 2021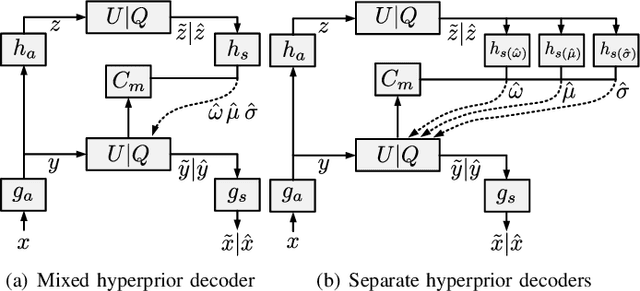
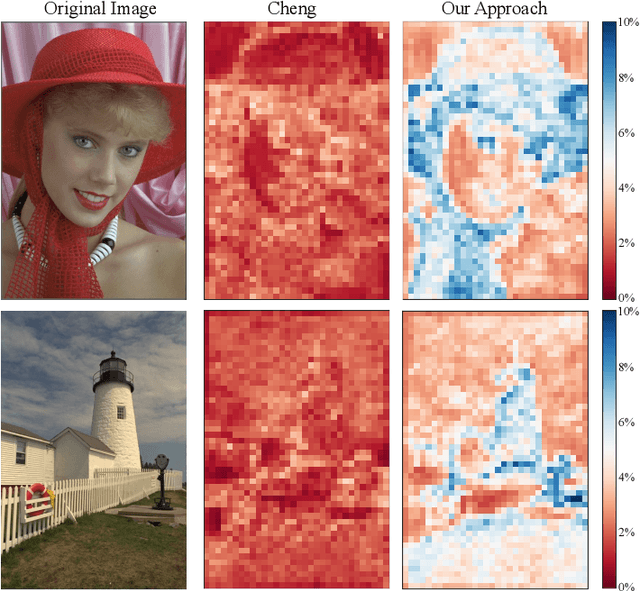
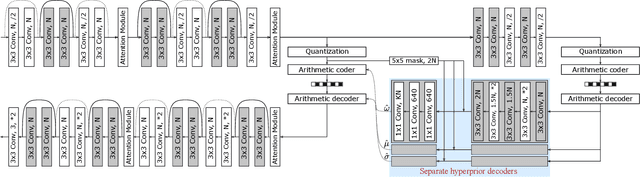
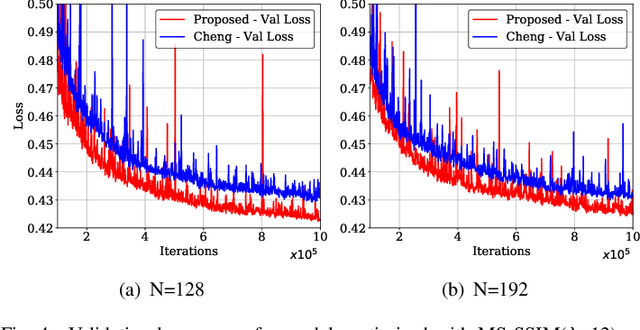
Learned image compression techniques have achieved considerable development in recent years. In this paper, we find that the performance bottleneck lies in the use of a single hyperprior decoder, in which case the ternary Gaussian model collapses to a binary one. To solve this, we propose to use three hyperprior decoders to separate the decoding process of the mixed parameters in discrete Gaussian mixture likelihoods, achieving more accurate parameters estimation. Experimental results demonstrate the proposed method optimized by MS-SSIM achieves on average 3.36% BD-rate reduction compared with state-of-the-art approach. The contribution of the proposed method to the coding time and FLOPs is negligible.
A Nonlinear Model for Time Synchronization
Mar 01, 2019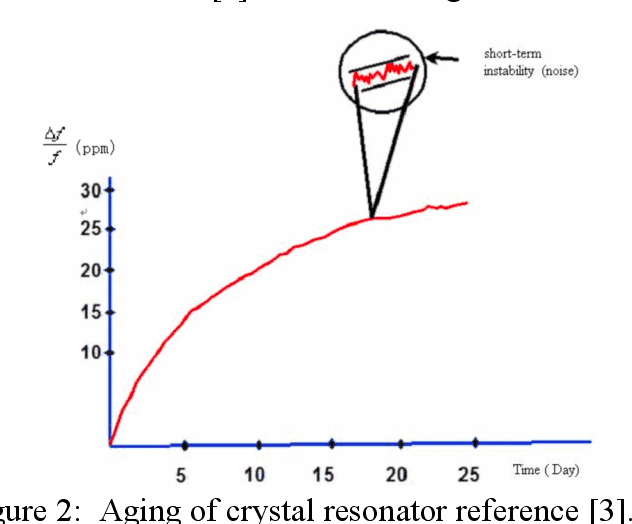



The current algorithms are based on linear model, for example, Precision Time Protocol (PTP) which requires frequent synchronization in order to handle the effects of clock frequency drift. This paper introduces a nonlinear approach to clock time synchronize. This approach can accurately model the frequency shift. Therefore, the required time interval to synchronize clocks can be longer. Meanwhile, it also offers better performance and relaxes the synchronization process. The idea of the nonlinear algorithm and some numerical examples will be presented in this paper in detail.
The Box Size Confidence Bias Harms Your Object Detector
Dec 03, 2021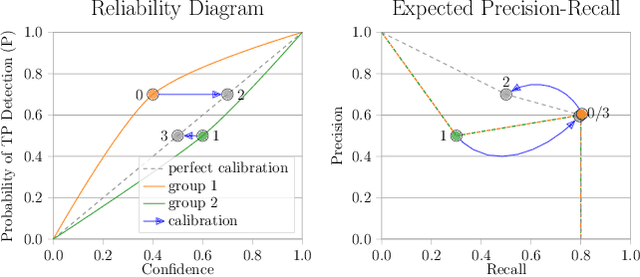
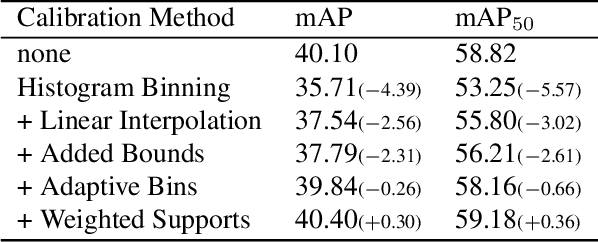
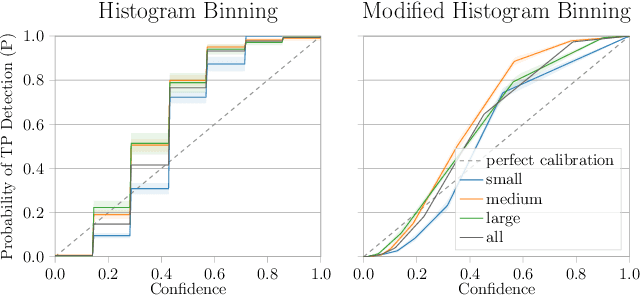

Countless applications depend on accurate predictions with reliable confidence estimates from modern object detectors. It is well known, however, that neural networks including object detectors produce miscalibrated confidence estimates. Recent work even suggests that detectors' confidence predictions are biased with respect to object size and position, but it is still unclear how this bias relates to the performance of the affected object detectors. We formally prove that the conditional confidence bias is harming the expected performance of object detectors and empirically validate these findings. Specifically, we demonstrate how to modify the histogram binning calibration to not only avoid performance impairment but also improve performance through conditional confidence calibration. We further find that the confidence bias is also present in detections generated on the training data of the detector, which we leverage to perform our de-biasing without using additional data. Moreover, Test Time Augmentation magnifies this bias, which results in even larger performance gains from our calibration method. Finally, we validate our findings on a diverse set of object detection architectures and show improvements of up to 0.6 mAP and 0.8 mAP50 without extra data or training.
Long-Range Transformers for Dynamic Spatiotemporal Forecasting
Sep 24, 2021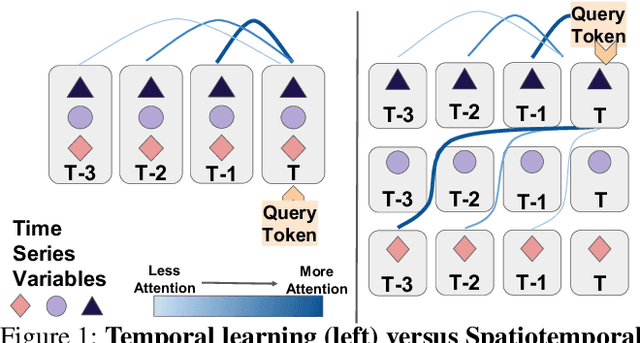
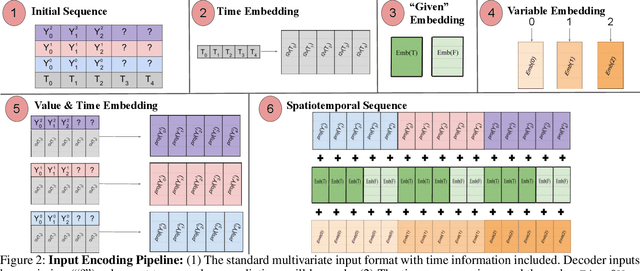
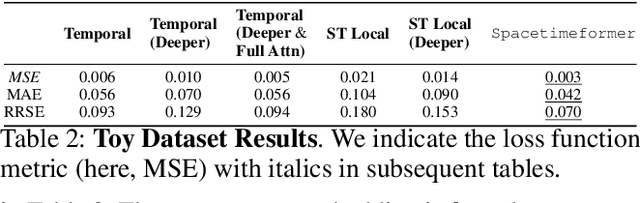
Multivariate Time Series Forecasting (TSF) focuses on the prediction of future values based on historical context. In these problems, dependent variables provide additional information or early warning signs of changes in future behavior. State-of-the-art forecasting models rely on neural attention between timesteps. This allows for temporal learning but fails to consider distinct spatial relationships between variables. This paper addresses the problem by translating multivariate TSF into a novel spatiotemporal sequence formulation where each input token represents the value of a single variable at a given timestep. Long-Range Transformers can then learn interactions between space, time, and value information jointly along this extended sequence. Our method, which we call Spacetimeformer, scales to high dimensional forecasting problems dominated by Graph Neural Networks that rely on predefined variable graphs. We achieve competitive results on benchmarks from traffic forecasting to electricity demand and weather prediction while learning spatial and temporal relationships purely from data.
Spectral Efficiency of OTFS Based Orthogonal Multiple Access with Rectangular Pulses
Oct 17, 2021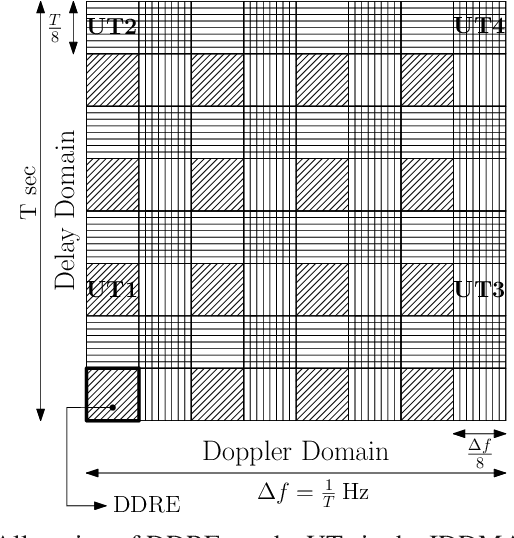
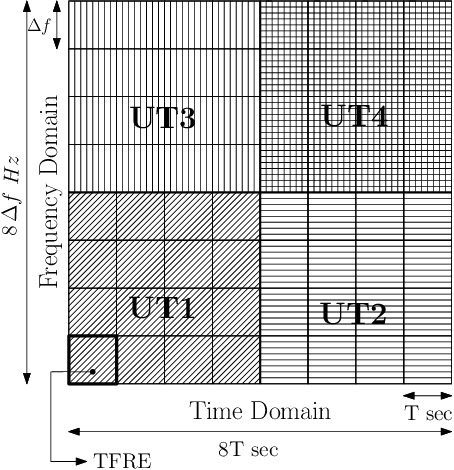
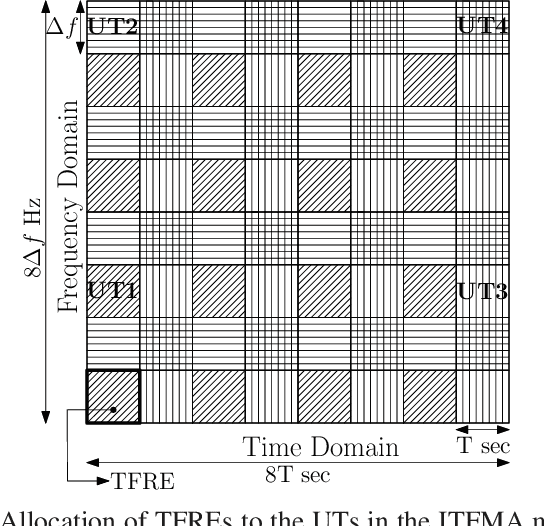
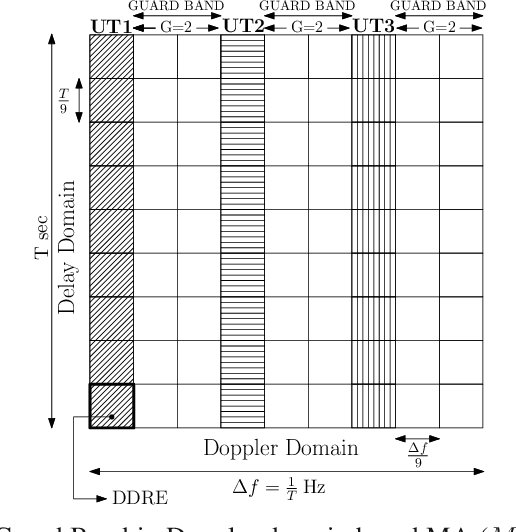
In this paper we consider Orthogonal Time Frequency Space (OTFS) modulation based multiple-access (MA). We specifically consider Orthogonal MA methods (OMA) where the user terminals (UTs) are allocated non-overlapping physical resource in the delay-Doppler (DD) and/or time-frequency (TF) domain. To the best of our knowledge, in prior literature, the performance of OMA methods have been reported only for ideal transmit and receive pulses. In [20] and [21], OMA methods were proposed which were shown to achieve multi-user interference (MUI) free communication with ideal pulses. Since ideal pulses are not realizable, in this paper we study the spectral efficiency (SE) performance of these OMA methods with practical rectangular pulses. For these OMA methods, we derive the expression for the received DD domain symbols at the base station (BS) receiver and the effective DD domain channel matrix when rectangular pulses are used. We then derive the expression for the achievable sum SE. These expressions are also derived for another well known OMA method where guard bands (GB) are used to reduce MUI (called as the GB based MA methods) [19]. Through simulations, we observe that with rectangular pulses the sum SE achieved by the method in [21] is almost invariant of the Doppler shift and is higher than that achieved by the methods in [19], [20] at practical values of the received signal-to-noise ratio.
Lightweight Decoding Strategies for Increasing Specificity
Oct 22, 2021
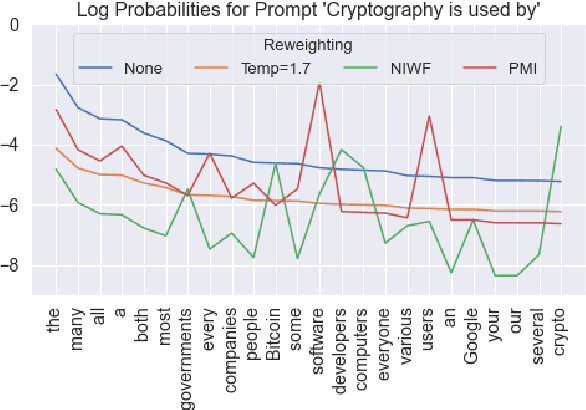

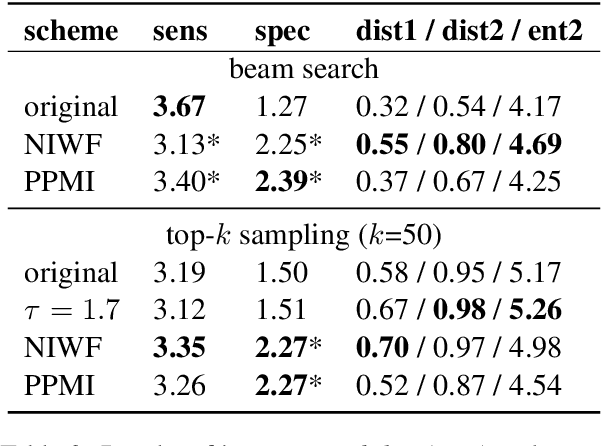
Language models are known to produce vague and generic outputs. We propose two unsupervised decoding strategies based on either word-frequency or point-wise mutual information to increase the specificity of any model that outputs a probability distribution over its vocabulary at generation time. We test the strategies in a prompt completion task; with human evaluations, we find that both strategies increase the specificity of outputs with only modest decreases in sensibility. We also briefly present a summarization use case, where these strategies can produce more specific summaries.
General linear-time inference for Gaussian Processes on one dimension
Mar 11, 2020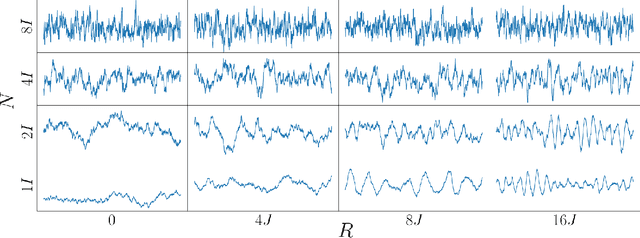
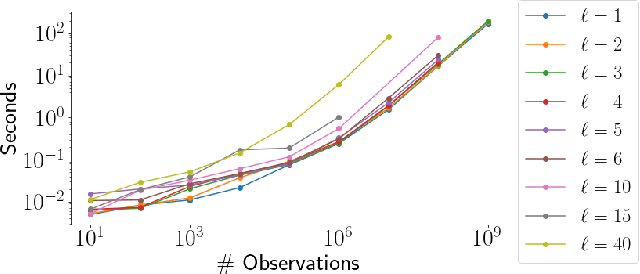
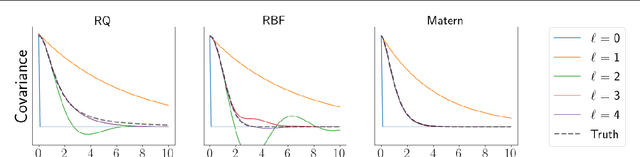
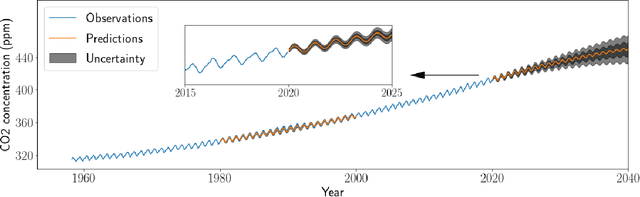
Gaussian Processes (GPs) provide a powerful probabilistic framework for interpolation, forecasting, and smoothing, but have been hampered by computational scaling issues. Here we prove that for data sampled on one dimension (e.g., a time series sampled at arbitrarily-spaced intervals), approximate GP inference at any desired level of accuracy requires computational effort that scales linearly with the number of observations; this new theorem enables inference on much larger datasets than was previously feasible. To achieve this improved scaling we propose a new family of stationary covariance kernels: the Latent Exponentially Generated (LEG) family, which admits a convenient stable state-space representation that allows linear-time inference. We prove that any continuous integrable stationary kernel can be approximated arbitrarily well by some member of the LEG family. The proof draws connections to Spectral Mixture Kernels, providing new insight about the flexibility of this popular family of kernels. We propose parallelized algorithms for performing inference and learning in the LEG model, test the algorithm on real and synthetic data, and demonstrate scaling to datasets with billions of samples.