 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Visual Microfossil Identificationvia Deep Metric Learning
Dec 17, 2021
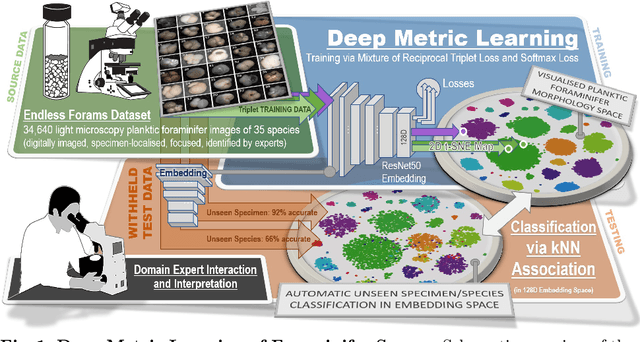
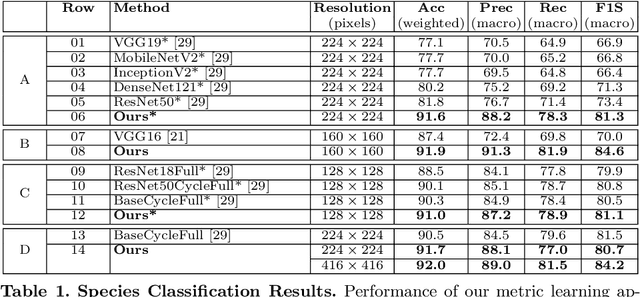
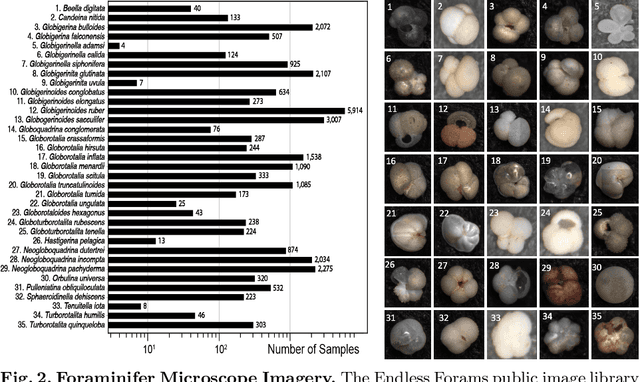
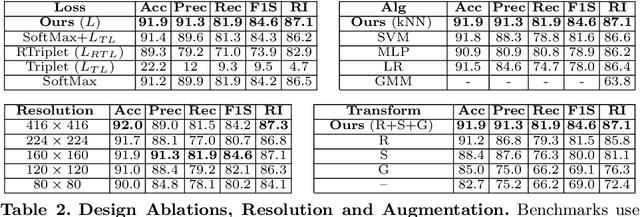
We apply deep metric learning for the first time to the prob-lem of classifying planktic foraminifer shells on microscopic images. This species recognition task is an important information source and scientific pillar for reconstructing past climates. All foraminifer CNN recognition pipelines in the literature produce black-box classifiers that lack visualisation options for human experts and cannot be applied to open set problems. Here, we benchmark metric learning against these pipelines, produce the first scientific visualisation of the phenotypic planktic foraminifer morphology space, and demonstrate that metric learning can be used to cluster species unseen during training. We show that metric learning out-performs all published CNN-based state-of-the-art benchmarks in this domain. We evaluate our approach on the 34,640 expert-annotated images of the Endless Forams public library of 35 modern planktic foraminifera species. Our results on this data show leading 92% accuracy (at 0.84 F1-score) in reproducing expert labels on withheld test data, and 66.5% accuracy (at 0.70 F1-score) when clustering species never encountered in training. We conclude that metric learning is highly effective for this domain and serves as an important tool towards expert-in-the-loop automation of microfossil identification. Key code, network weights, and data splits are published with this paper for full reproducibility.
Dynamic Compressed Sensing of Unsteady Flows with a Mobile Robot
Oct 16, 2021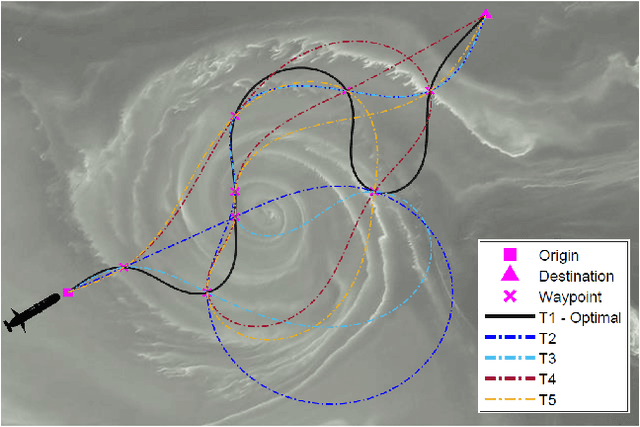
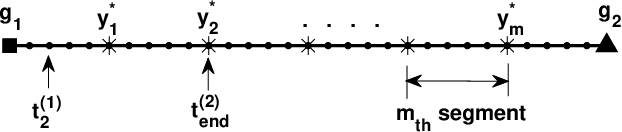
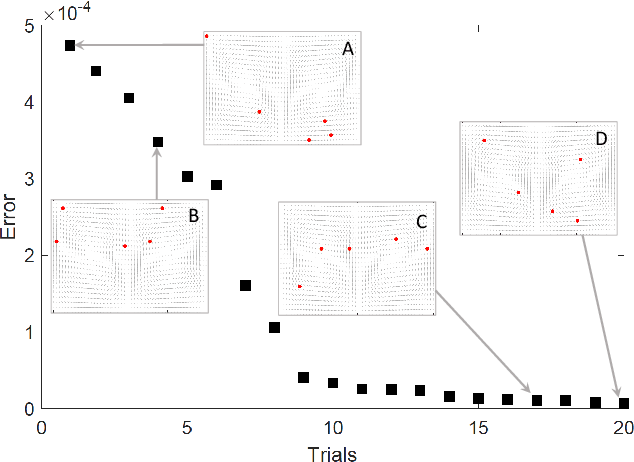
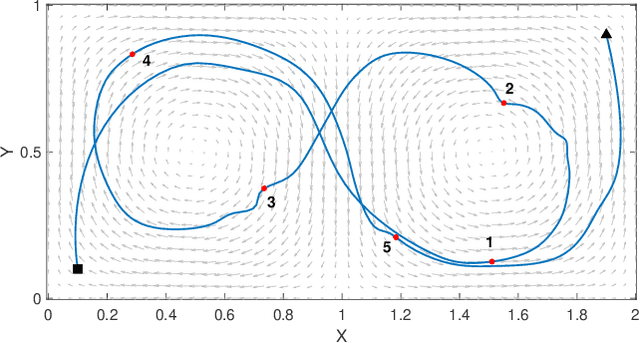
Large-scale environmental sensing with a finite number of mobile sensor is a challenging task that requires a lot of resources and time. This is especially true when features in the environment are spatiotemporally changing with unknown or partially known dynamics. However, these dynamic features often evolve in a low-dimensional space, making it possible to capture their dynamics sufficiently well with only one or several properly planned mobile sensors. This paper investigates the problem of dynamic compressed sensing (DCS) of an unsteady flow field, which takes advantage of the inherently low dimensionality of the underlying flow dynamics to reduce number of waypoints for a mobile sensing robot. The optimal sensing waypoints are identified by an iterative compressed sensing algorithm that optimizes the flow reconstruction based on the proper orthogonal decomposition (POD) modes. An optimized robot trajectory is then found to traverse these waypoints while minimizing the energy consumption, time, and flow reconstruction error. Simulation results in an unsteady double-gyre flow field is presented to demonstrate the efficacy of the proposed algorithms. Experimental results with an indoor quadcopter are presented to show the feasibility of the resulting trajectory.
Neural Network Adversarial Attack Method Based on Improved Genetic Algorithm
Oct 05, 2021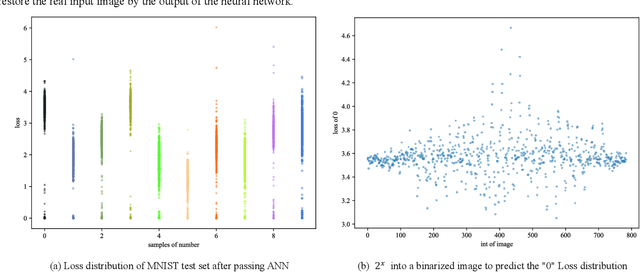
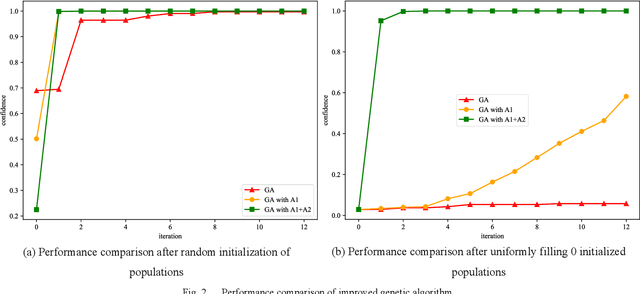
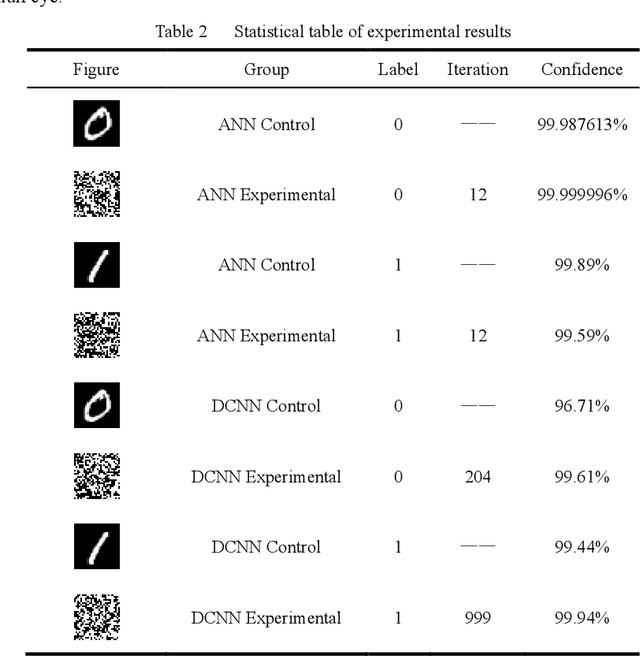
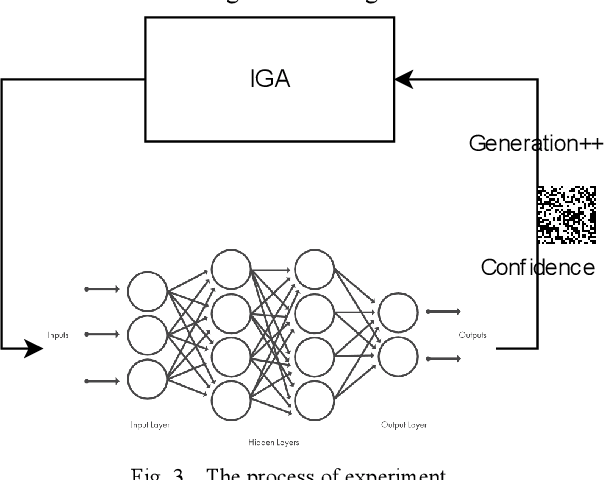
Deep learning algorithms are widely used in fields such as computer vision and natural language processing, but they are vulnerable to security threats from adversarial attacks because of their internal presence of a large number of nonlinear functions and parameters leading to their uninterpretability. In this paper, we propose a neural network adversarial attack method based on an improved genetic algorithm. The improved genetic algorithm improves the variation and crossover links based on the original genetic optimization algorithm, which greatly improves the iteration efficiency and shortens the running time. The method does not need the internal structure and parameter information of the neural network model, and it can obtain the adversarial samples with high confidence in a short time by the classification and confidence information of the neural network. The experimental results show that the method in this paper has a wide range of applicability and high efficiency for the model, and provides a new idea for the adversarial attack.
Tesla-Rapture: A Lightweight Gesture Recognition System from mmWave Radar Point Clouds
Sep 14, 2021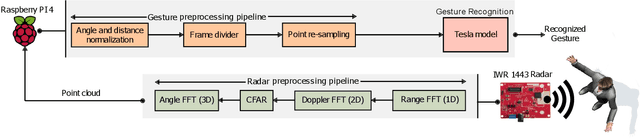
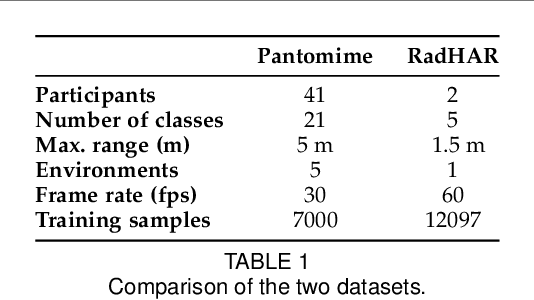
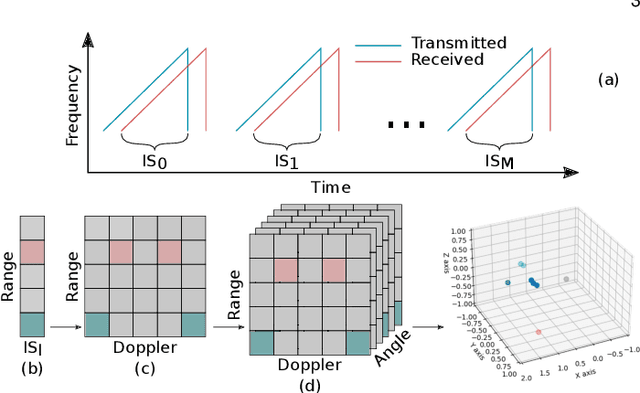
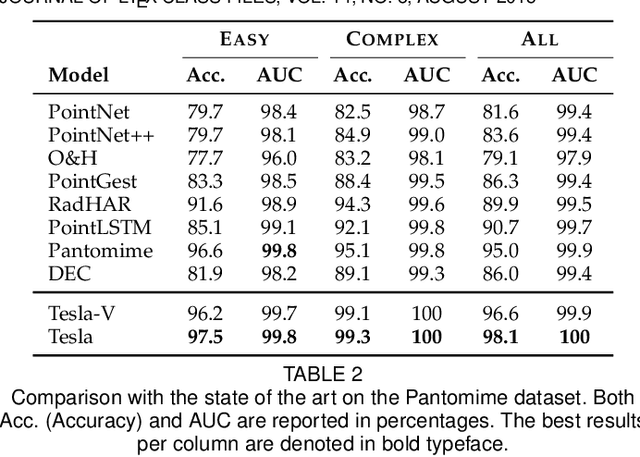
We present Tesla-Rapture, a gesture recognition interface for point clouds generated by mmWave Radars. State of the art gesture recognition models are either too resource consuming or not sufficiently accurate for integration into real-life scenarios using wearable or constrained equipment such as IoT devices (e.g. Raspberry PI), XR hardware (e.g. HoloLens), or smart-phones. To tackle this issue, we developed Tesla, a Message Passing Neural Network (MPNN) graph convolution approach for mmWave radar point clouds. The model outperforms the state of the art on two datasets in terms of accuracy while reducing the computational complexity and, hence, the execution time. In particular, the approach, is able to predict a gesture almost 8 times faster than the most accurate competitor. Our performance evaluation in different scenarios (environments, angles, distances) shows that Tesla generalizes well and improves the accuracy up to 20% in challenging scenarios like a through-wall setting and sensing at extreme angles. Utilizing Tesla, we develop Tesla-Rapture, a real-time implementation using a mmWave Radar on a Raspberry PI 4 and evaluate its accuracy and time-complexity. We also publish the source code, the trained models, and the implementation of the model for embedded devices.
Budget Sensitive Reannotation of Noisy Relation Classification Data Using Label Hierarchy
Dec 26, 2021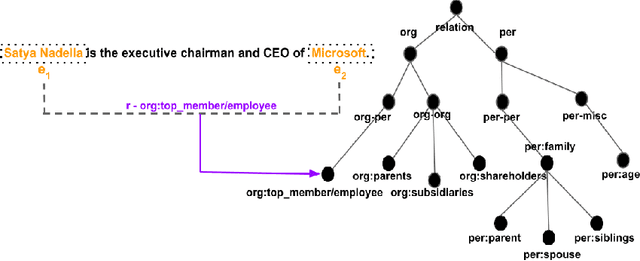
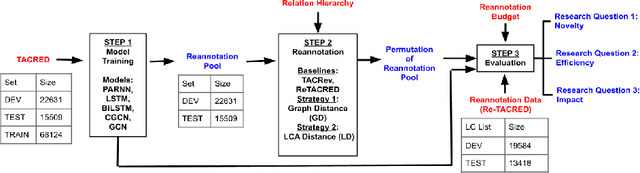
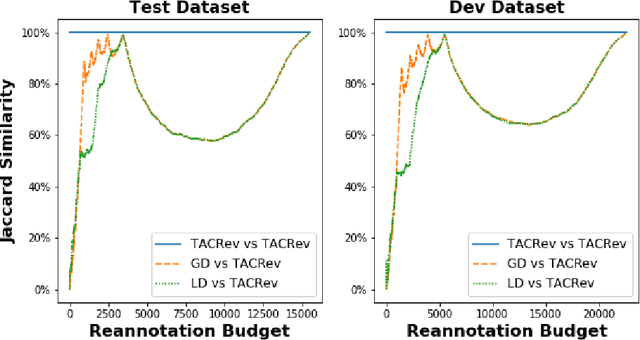
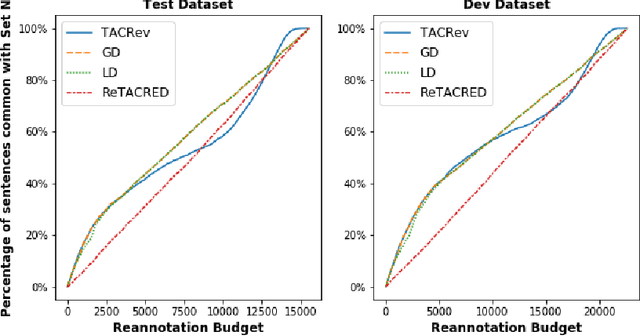
Large crowd-sourced datasets are often noisy and relation classification (RC) datasets are no exception. Reannotating the entire dataset is one probable solution however it is not always viable due to time and budget constraints. This paper addresses the problem of efficient reannotation of a large noisy dataset for the RC. Our goal is to catch more annotation errors in the dataset while reannotating fewer instances. Existing work on RC dataset reannotation lacks the flexibility about how much data to reannotate. We introduce the concept of a reannotation budget to overcome this limitation. The immediate follow-up problem is: Given a specific reannotation budget, which subset of the data should we reannotate? To address this problem, we present two strategies to selectively reannotate RC datasets. Our strategies utilize the taxonomic hierarchy of relation labels. The intuition of our work is to rely on the graph distance between actual and predicted relation labels in the label hierarchy graph. We evaluate our reannotation strategies on the well-known TACRED dataset. We design our experiments to answer three specific research questions. First, does our strategy select novel candidates for reannotation? Second, for a given reannotation budget is our reannotation strategy more efficient at catching annotation errors? Third, what is the impact of data reannotation on RC model performance measurement? Experimental results show that our both reannotation strategies are novel and efficient. Our analysis indicates that the current reported performance of RC models on noisy TACRED data is inflated.
Optimizing for In-memory Deep Learning with Emerging Memory Technology
Dec 01, 2021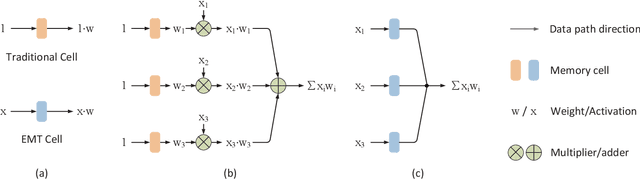
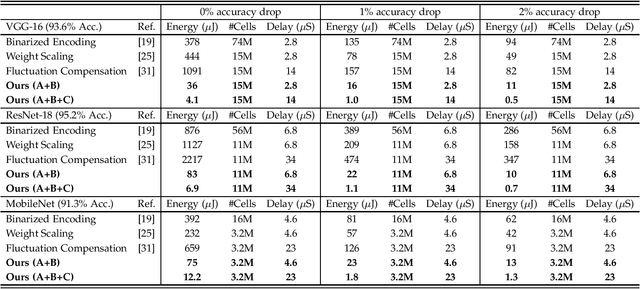
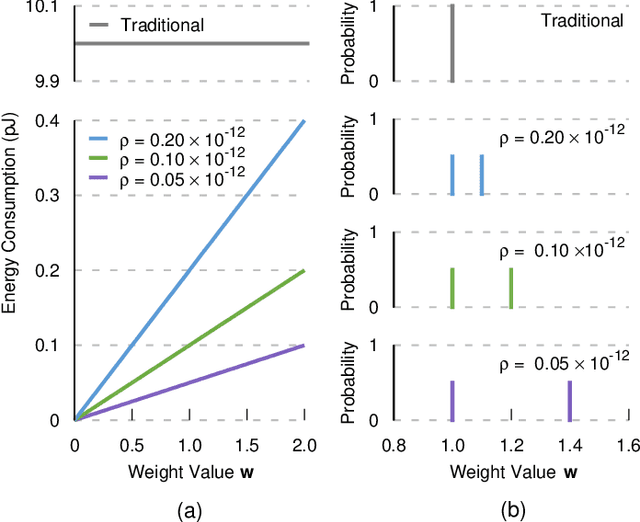
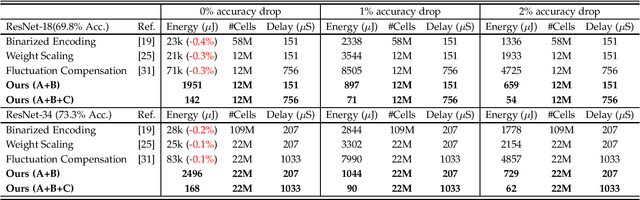
In-memory deep learning computes neural network models where they are stored, thus avoiding long distance communication between memory and computation units, resulting in considerable savings in energy and time. In-memory deep learning has already demonstrated orders of magnitude higher performance density and energy efficiency. The use of emerging memory technology promises to increase the gains in density, energy, and performance even further. However, emerging memory technology is intrinsically unstable, resulting in random fluctuations of data reads. This can translate to non-negligible accuracy loss, potentially nullifying the gains. In this paper, we propose three optimization techniques that can mathematically overcome the instability problem of emerging memory technology. They can improve the accuracy of the in-memory deep learning model while maximizing its energy efficiency. Experiments show that our solution can fully recover most models' state-of-the-art accuracy, and achieves at least an order of magnitude higher energy efficiency than the state-of-the-art.
Quadrupedal Robotic Guide Dog with Vocal Human-Robot Interaction
Nov 05, 2021
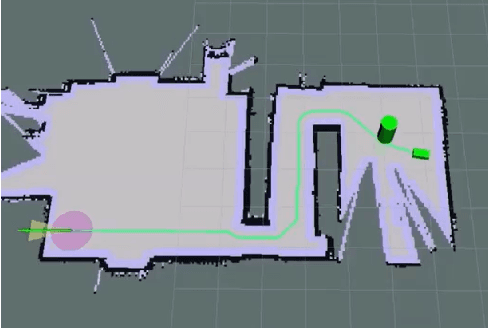
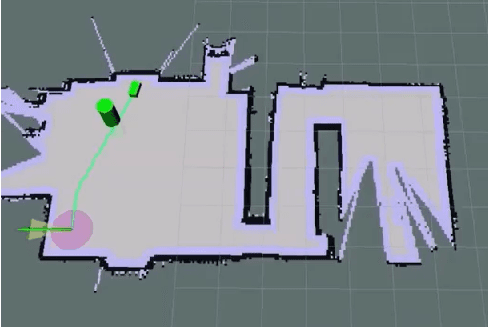
Guide dogs play a critical role in the lives of many, however training them is a time- and labor-intensive process. We are developing a method to allow an autonomous robot to physically guide humans using direct human-robot communication. The proposed algorithm will be deployed on a Unitree A1 quadrupedal robot and will autonomously navigate the person to their destination while communicating with the person using a speech interface compatible with the robot. This speech interface utilizes cloud based services such as Amazon Polly and Google Cloud to serve as the text-to-speech and speech-to-text engines.
An Efficient Deep Learning Model for Automatic Modulation Recognition Based on Parameter Estimation and Transformation
Oct 11, 2021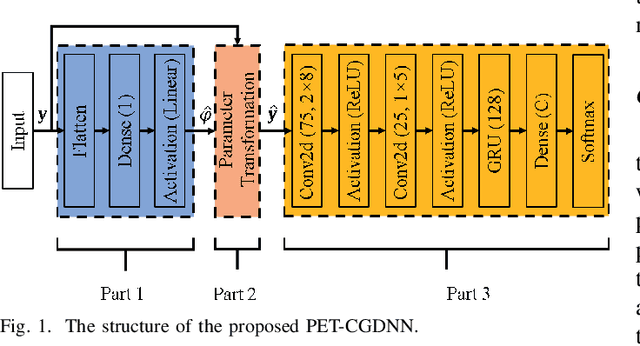
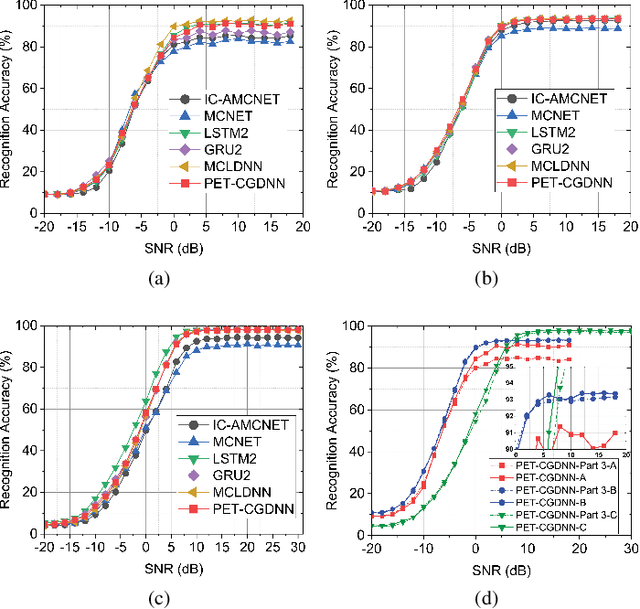
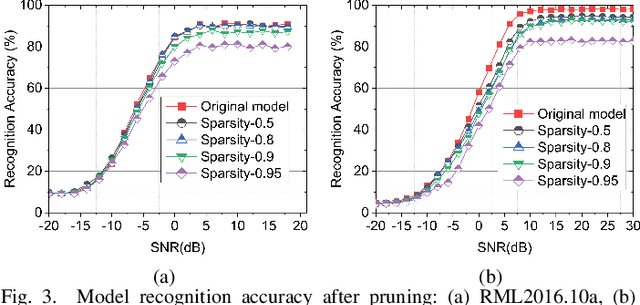
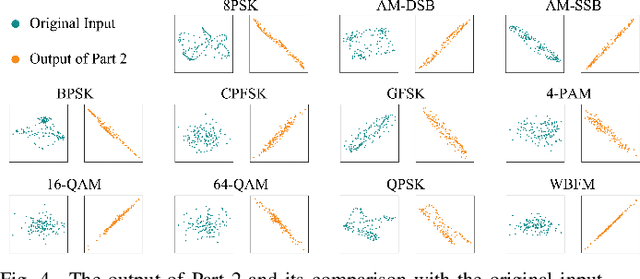
Automatic modulation recognition (AMR) is a promising technology for intelligent communication receivers to detect signal modulation schemes. Recently, the emerging deep learning (DL) research has facilitated high-performance DL-AMR approaches. However, most DL-AMR models only focus on recognition accuracy, leading to huge model sizes and high computational complexity, while some lightweight and low-complexity models struggle to meet the accuracy requirements. This letter proposes an efficient DL-AMR model based on phase parameter estimation and transformation, with convolutional neural network (CNN) and gated recurrent unit (GRU) as the feature extraction layers, which can achieve high recognition accuracy equivalent to the existing state-of-the-art models but reduces more than a third of the volume of their parameters. Meanwhile, our model is more competitive in training time and test time than the benchmark models with similar recognition accuracy. Moreover, we further propose to compress our model by pruning, which maintains the recognition accuracy higher than 90% while has less than 1/8 of the number of parameters comparing with state-of-the-art models.
Towards Fair Recommendation in Two-Sided Platforms
Dec 26, 2021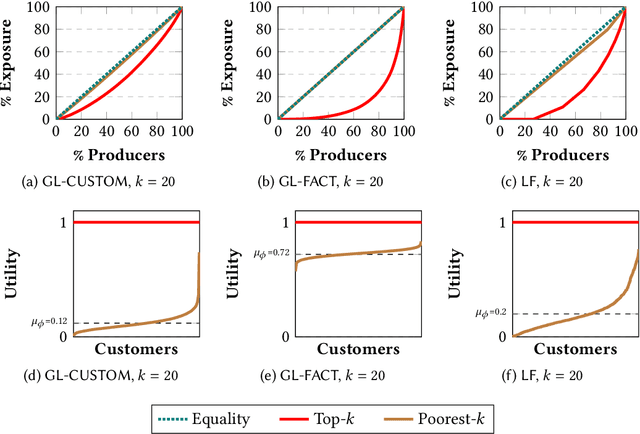
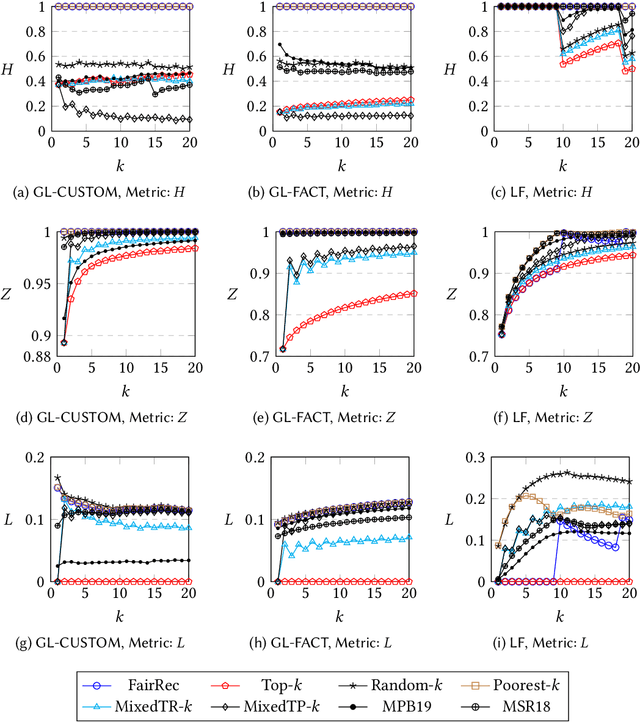
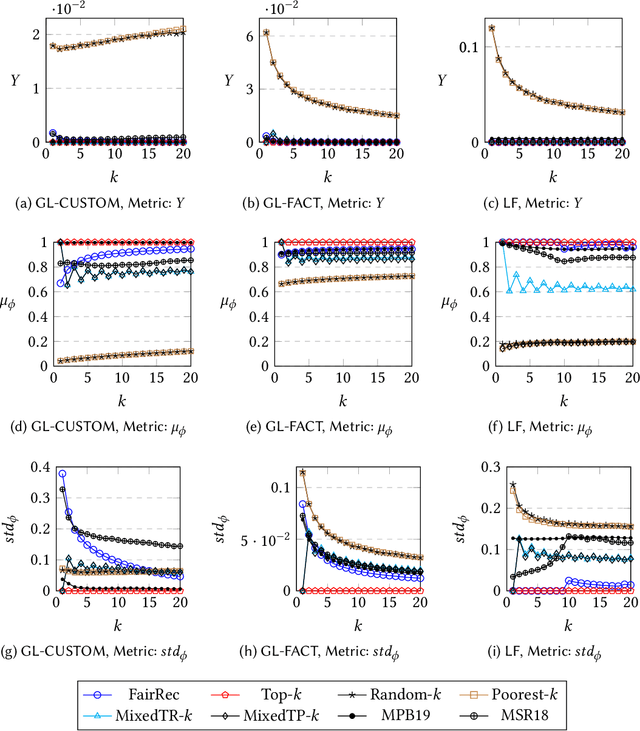
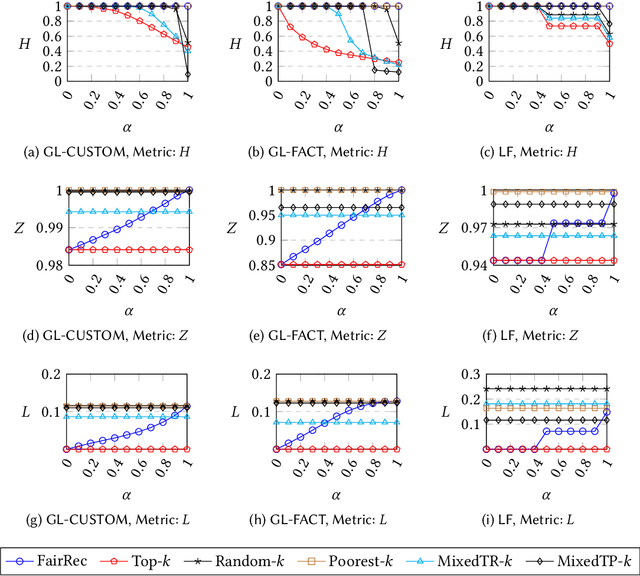
Many online platforms today (such as Amazon, Netflix, Spotify, LinkedIn, and AirBnB) can be thought of as two-sided markets with producers and customers of goods and services. Traditionally, recommendation services in these platforms have focused on maximizing customer satisfaction by tailoring the results according to the personalized preferences of individual customers. However, our investigation reinforces the fact that such customer-centric design of these services may lead to unfair distribution of exposure to the producers, which may adversely impact their well-being. On the other hand, a pure producer-centric design might become unfair to the customers. As more and more people are depending on such platforms to earn a living, it is important to ensure fairness to both producers and customers. In this work, by mapping a fair personalized recommendation problem to a constrained version of the problem of fairly allocating indivisible goods, we propose to provide fairness guarantees for both sides. Formally, our proposed {\em FairRec} algorithm guarantees Maxi-Min Share ($\alpha$-MMS) of exposure for the producers, and Envy-Free up to One Item (EF1) fairness for the customers. Extensive evaluations over multiple real-world datasets show the effectiveness of {\em FairRec} in ensuring two-sided fairness while incurring a marginal loss in overall recommendation quality. Finally, we present a modification of FairRec (named as FairRecPlus) that at the cost of additional computation time, improves the recommendation performance for the customers, while maintaining the same fairness guarantees.
What to Prioritize? Natural Language Processing for the Development of a Modern Bug Tracking Solution in Hardware Development
Sep 28, 2021


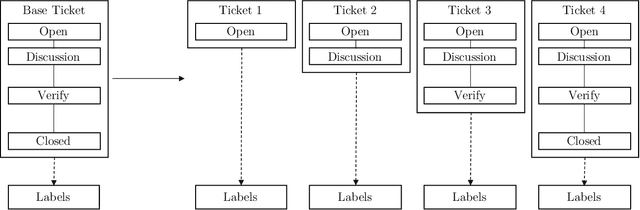
Managing large numbers of incoming bug reports and finding the most critical issues in hardware development is time consuming, but crucial in order to reduce development costs. In this paper, we present an approach to predict the time to fix, the risk and the complexity of debugging and resolution of a bug report using different supervised machine learning algorithms, namely Random Forest, Naive Bayes, SVM, MLP and XGBoost. Further, we investigate the effect of the application of active learning and we evaluate the impact of different text representation techniques, namely TF-IDF, Word2Vec, Universal Sentence Encoder and XLNet on the model's performance. The evaluation shows that a combination of text embeddings generated through the Universal Sentence Encoder and MLP as classifier outperforms all other methods, and is well suited to predict the risk and complexity of bug tickets.