 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossVL: Complexity-Aware Feature Routing and Paired Curriculum for Cross-View Vision-Language Detection
May 10, 2026Vision-language models (VLMs) enable text-guided object detection but degrade severely under cross-view scenarios where ground and aerial viewpoints differ in altitude, scale, and spatial layout. These geometric changes introduce systematic complexity variations between viewpoints, e.g., ground view images contain dense and highly occluded structures, while aerial images are sparse and globally organized. Fixed VLM fusion mechanisms cannot handle this discrepancy. We propose CrossVL, a framework combining Complexity-Aware Pathway Aggregation (CPA) and Paired Curriculum Learning (PCL) for enhanced cross-view detection for VLM. CPA estimates scene complexity from multimodal statistics and routes visual features through multiple pathways to obtain view-specific representations. PCL leverages semantic consistency of synchronized ground-aerial pairs to provide stable early supervision and then gradually shifts toward randomized sampling. On MAVREC, CrossVL improves Florence-2's aerial mAP from 58.66% to 61.03% and reduces the ground-aerial performance gap from 8.63pp to 6.65pp, while also achieving a 3.3x reduction in variance across random seeds. CPA provides stable complexity-aware feature aggregation, and PCL enhances optimization dynamics. Together, they demonstrate that coordinated architectural and training adaptations are crucial for robust cross-view VLM detection.
PDMP: Rethinking Balanced Multimodal Learning via Performance-Dominant Modality Prioritization
Apr 07, 2026Multimodal learning has attracted increasing attention due to its practicality. However, it often suffers from insufficient optimization, where the multimodal model underperforms even compared to its unimodal counterparts. Existing methods attribute this problem to the imbalanced learning between modalities and solve it by gradient modulation. This paper argues that balanced learning is not the optimal setting for multimodal learning. On the contrary, imbalanced learning driven by the performance-dominant modality that has superior unimodal performance can contribute to better multimodal performance. And the under-optimization problem is caused by insufficient learning of the performance-dominant modality. To this end, we propose the Performance-Dominant Modality Prioritization (PDMP) strategy to assist multimodal learning. Specifically, PDMP firstly mines the performance-dominant modality via the performance ranking of the independently trained unimodal model. Then PDMP introduces asymmetric coefficients to modulate the gradients of each modality, enabling the performance-dominant modality to dominate the optimization. Since PDMP only relies on the unimodal performance ranking, it is independent of the structures and fusion methods of the multimodal model and has great potential for practical scenarios. Finally, extensive experiments on various datasets validate the superiority of PDMP.
OilSAM2: Memory-Augmented SAM2 for Scalable SAR Oil Spill Detection
Mar 10, 2026Segmenting oil spills from Synthetic Aperture Radar (SAR) imagery remains challenging due to severe appearance variability, scale heterogeneity, and the absence of temporal continuity in real world monitoring scenarios. While foundation models such as Segment Anything (SAM) enable prompt driven segmentation, existing SAM based approaches operate on single images and cannot effectively reuse information across scenes. Memory augmented variants (e.g., SAM2) further assume temporal coherence, making them prone to semantic drift when applied to unordered SAR image collections. We propose OilSAM2, a memory augmented segmentation framework tailored for unordered SAR oil spill monitoring. OilSAM2 introduces a hierarchical feature aware multi scale memory bank that explicitly models texture, structure, and semantic level representations, enabling robust cross image information reuse. To mitigate memory drift, we further propose a structure semantic consistent memory update strategy that selectively refreshes memory based on semantic discrepancy and structural variation.Experiments on two public SAR oil spill datasets demonstrate that OilSAM2 achieves state of the art segmentation performance, delivering stable and accurate results under noisy SAR monitoring scenarios. The source code is available at https://github.com/Chenshuaiyu1120/OILSAM2.
Beyond Segmentation: An Oil Spill Change Detection Framework Using Synthetic SAR Imagery
Jan 05, 2026Marine oil spills are urgent environmental hazards that demand rapid and reliable detection to minimise ecological and economic damage. While Synthetic Aperture Radar (SAR) imagery has become a key tool for large-scale oil spill monitoring, most existing detection methods rely on deep learning-based segmentation applied to single SAR images. These static approaches struggle to distinguish true oil spills from visually similar oceanic features (e.g., biogenic slicks or low-wind zones), leading to high false positive rates and limited generalizability, especially under data-scarce conditions. To overcome these limitations, we introduce Oil Spill Change Detection (OSCD), a new bi-temporal task that focuses on identifying changes between pre- and post-spill SAR images. As real co-registered pre-spill imagery is not always available, we propose the Temporal-Aware Hybrid Inpainting (TAHI) framework, which generates synthetic pre-spill images from post-spill SAR data. TAHI integrates two key components: High-Fidelity Hybrid Inpainting for oil-free reconstruction, and Temporal Realism Enhancement for radiometric and sea-state consistency. Using TAHI, we construct the first OSCD dataset and benchmark several state-of-the-art change detection models. Results show that OSCD significantly reduces false positives and improves detection accuracy compared to conventional segmentation, demonstrating the value of temporally-aware methods for reliable, scalable oil spill monitoring in real-world scenarios.
Achieving Equilibrium under Utility Heterogeneity: An Agent-Attention Framework for Multi-Agent Multi-Objective Reinforcement Learning
Nov 12, 2025


Multi-agent multi-objective systems (MAMOS) have emerged as powerful frameworks for modelling complex decision-making problems across various real-world domains, such as robotic exploration, autonomous traffic management, and sensor network optimisation. MAMOS offers enhanced scalability and robustness through decentralised control and more accurately reflects inherent trade-offs between conflicting objectives. In MAMOS, each agent uses utility functions that map return vectors to scalar values. Existing MAMOS optimisation methods face challenges in handling heterogeneous objective and utility function settings, where training non-stationarity is intensified due to private utility functions and the associated policies. In this paper, we first theoretically prove that direct access to, or structured modeling of, global utility functions is necessary for the Bayesian Nash Equilibrium under decentralised execution constraints. To access the global utility functions while preserving the decentralised execution, we propose an Agent-Attention Multi-Agent Multi-Objective Reinforcement Learning (AA-MAMORL) framework. Our approach implicitly learns a joint belief over other agents' utility functions and their associated policies during centralised training, effectively mapping global states and utilities to each agent's policy. In execution, each agent independently selects actions based on local observations and its private utility function to approximate a BNE, without relying on inter-agent communication. We conduct comprehensive experiments in both a custom-designed MAMO Particle environment and the standard MOMALand benchmark. The results demonstrate that access to global preferences and our proposed AA-MAMORL significantly improve performance and consistently outperform state-of-the-art methods.
Gaze Into the Abyss -- Planning to Seek Entropy When Reward is Scarce
May 22, 2025Model-based reinforcement learning (MBRL) offers an intuitive way to increase the sample efficiency of model-free RL methods by simultaneously training a world model that learns to predict the future. MBRL methods have progressed by largely prioritising the actor; optimising the world model learning has been neglected meanwhile. Improving the fidelity of the world model and reducing its time to convergence can yield significant downstream benefits, one of which is improving the ensuing performance of any actor it may train. We propose a novel approach that anticipates and actively seeks out high-entropy states using short-horizon latent predictions generated by the world model, offering a principled alternative to traditional curiosity-driven methods that chase once-novel states well after they were stumbled into. While many model predictive control (MPC) based methods offer similar alternatives, they typically lack commitment, synthesising multi step plans after every step. To mitigate this, we present a hierarchical planner that dynamically decides when to replan, planning horizon length, and the weighting between reward and entropy. While our method can theoretically be applied to any model that trains its own actors with solely model generated data, we have applied it to just Dreamer as a proof of concept. Our method finishes the Miniworld procedurally generated mazes 50% faster than base Dreamer at convergence and the policy trained in imagination converges in only 60% of the environment steps that base Dreamer needs.
REOBench: Benchmarking Robustness of Earth Observation Foundation Models
May 22, 2025Earth observation foundation models have shown strong generalization across multiple Earth observation tasks, but their robustness under real-world perturbations remains underexplored. To bridge this gap, we introduce REOBench, the first comprehensive benchmark for evaluating the robustness of Earth observation foundation models across six tasks and twelve types of image corruptions, including both appearance-based and geometric perturbations. To ensure realistic and fine-grained evaluation, our benchmark focuses on high-resolution optical remote sensing images, which are widely used in critical applications such as urban planning and disaster response. We conduct a systematic evaluation of a broad range of models trained using masked image modeling, contrastive learning, and vision-language pre-training paradigms. Our results reveal that (1) existing Earth observation foundation models experience significant performance degradation when exposed to input corruptions. (2) The severity of degradation varies across tasks, model architectures, backbone sizes, and types of corruption, with performance drop varying from less than 1% to over 20%. (3) Vision-language models show enhanced robustness, particularly in multimodal tasks. REOBench underscores the vulnerability of current Earth observation foundation models to real-world corruptions and provides actionable insights for developing more robust and reliable models.
AE-DENet: Enhancement for Deep Learning-based Channel Estimation in OFDM Systems
Nov 13, 2024



Deep learning (DL)-based methods have demonstrated remarkable achievements in addressing orthogonal frequency division multiplexing (OFDM) channel estimation challenges. However, existing DL-based methods mainly rely on separate real and imaginary inputs while ignoring the inherent correlation between the two streams, such as amplitude and phase information that are fundamental in communication signal processing. This paper proposes AE-DENet, a novel autoencoder(AE)-based data enhancement network to improve the performance of existing DL-based channel estimation methods. AE-DENet focuses on enriching the classic least square (LS) estimation input commonly used in DL-based methods by employing a learning-based data enhancement method, which extracts interaction features from the real and imaginary components and fuses them with the original real/imaginary streams to generate an enhanced input for better channel inference. Experimental findings in terms of the mean square error (MSE) results demonstrate that the proposed method enhances the performance of all state-of-the-art DL-based channel estimators with negligible added complexity. Furthermore, the proposed approach is shown to be robust to channel variations and high user mobility.
Robust Multimodal Learning via Representation Decoupling
Jul 05, 2024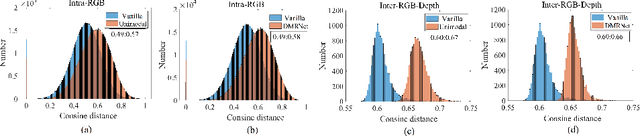
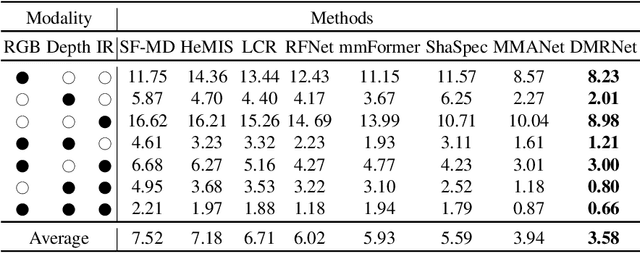
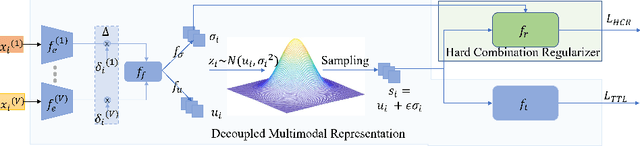
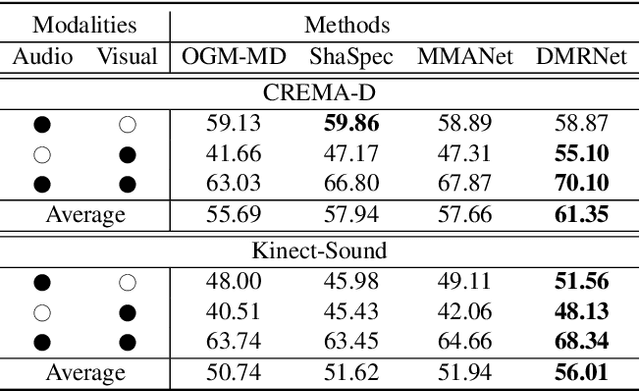
Multimodal learning robust to missing modality has attracted increasing attention due to its practicality. Existing methods tend to address it by learning a common subspace representation for different modality combinations. However, we reveal that they are sub-optimal due to their implicit constraint on intra-class representation. Specifically, the sample with different modalities within the same class will be forced to learn representations in the same direction. This hinders the model from capturing modality-specific information, resulting in insufficient learning. To this end, we propose a novel Decoupled Multimodal Representation Network (DMRNet) to assist robust multimodal learning. Specifically, DMRNet models the input from different modality combinations as a probabilistic distribution instead of a fixed point in the latent space, and samples embeddings from the distribution for the prediction module to calculate the task loss. As a result, the direction constraint from the loss minimization is blocked by the sampled representation. This relaxes the constraint on the inference representation and enables the model to capture the specific information for different modality combinations. Furthermore, we introduce a hard combination regularizer to prevent DMRNet from unbalanced training by guiding it to pay more attention to hard modality combinations. Finally, extensive experiments on multimodal classification and segmentation tasks demonstrate that the proposed DMRNet outperforms the state-of-the-art significantly.
Intelligent Reflecting Surfaces vs. Full-Duplex Relays: A Comparison in the Air
Mar 14, 2024This letter aims to provide a fundamental analytical comparison for the two major types of relaying methods: intelligent reflecting surfaces and full-duplex relays, particularly focusing on unmanned aerial vehicle communication scenarios. Both amplify-and-forward and decode-and-forward relaying schemes are included in the comparison. In addition, optimal 3D UAV deployment and minimum transmit power under the quality of service constraint are derived. Our numerical results show that IRSs of medium size exhibit comparable performance to AF relays, meanwhile outperforming DF relays under extremely large surface size and high data rates.