 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Soft Robotic Finger with Variable Effective Length enabled by an Antagonistic Constraint Mechanism
Dec 28, 2021
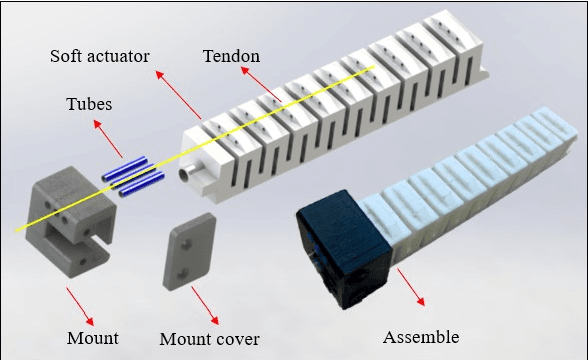
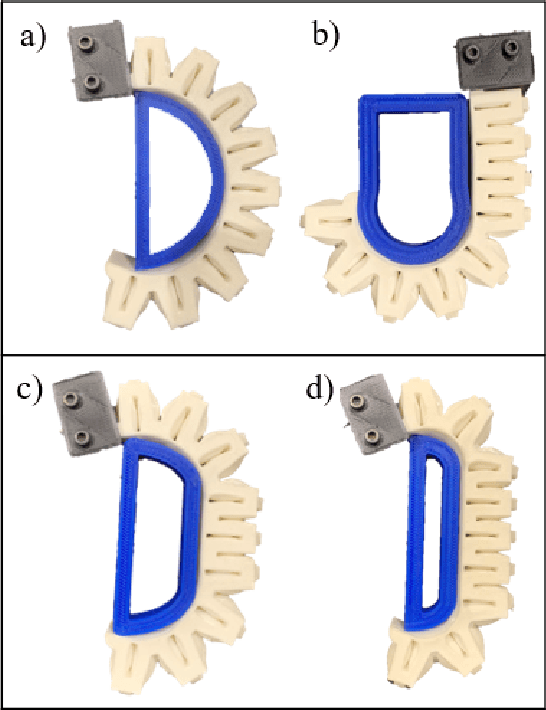


Compared to traditional rigid robotics, soft robotics has attracted increasing attention due to its advantages as compliance, safety, and low cost. As an essential part of soft robotics, the soft robotic gripper also shows its superior while grasping the objects with irregular shapes. Recent research has been conducted to improve its grasping performance by adjusting the variable effective length (VEL). However, the VEL achieved by multi-chamber design or tunable stiffness shape memory material requires complex pneumatic circuit design or a time-consuming phase-changing process. This work proposes a fold-based soft robotic actuator made from 3D printed filament, NinjaFlex. It is experimentally tested and represented by the hyperelastic model. Mathematic and finite element modelling is conducted to study the bending behaviour of the proposed soft actuator. Besides, an antagonistic constraint mechanism is proposed to achieve the VEL, and the experiments demonstrate that better conformity is achieved. Finally, a two-mode gripper is designed and evaluated to demonstrate the advances of VEL on grasping performance.
AGMI: Attention-Guided Multi-omics Integration for Drug Response Prediction with Graph Neural Networks
Dec 15, 2021



Accurate drug response prediction (DRP) is a crucial yet challenging task in precision medicine. This paper presents a novel Attention-Guided Multi-omics Integration (AGMI) approach for DRP, which first constructs a Multi-edge Graph (MeG) for each cell line, and then aggregates multi-omics features to predict drug response using a novel structure, called Graph edge-aware Network (GeNet). For the first time, our AGMI approach explores gene constraint based multi-omics integration for DRP with the whole-genome using GNNs. Empirical experiments on the CCLE and GDSC datasets show that our AGMI largely outperforms state-of-the-art DRP methods by 8.3%--34.2% on four metrics. Our data and code are available at https://github.com/yivan-WYYGDSG/AGMI.
Model-Size Reduction for Reservoir Computing by Concatenating Internal States Through Time
Jun 11, 2020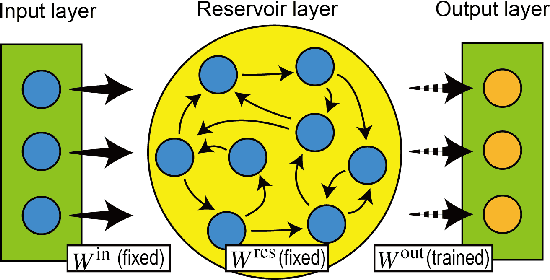
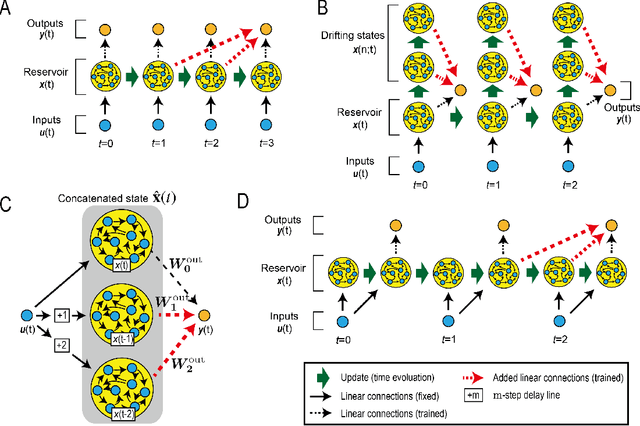
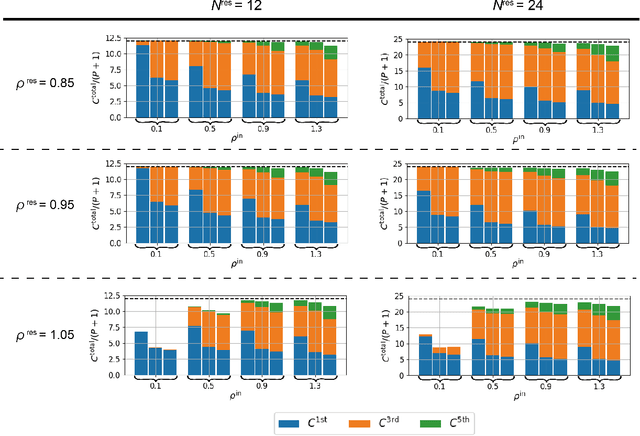
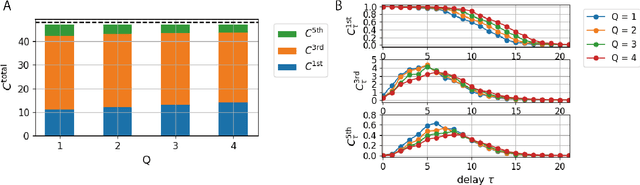
Reservoir computing (RC) is a machine learning algorithm that can learn complex time series from data very rapidly based on the use of high-dimensional dynamical systems, such as random networks of neurons, called "reservoirs." To implement RC in edge computing, it is highly important to reduce the amount of computational resources that RC requires. In this study, we propose methods that reduce the size of the reservoir by inputting the past or drifting states of the reservoir to the output layer at the current time step. These proposed methods are analyzed based on information processing capacity, which is a performance measure of RC proposed by Dambre et al. (2012). In addition, we evaluate the effectiveness of the proposed methods on time-series prediction tasks: the generalized Henon-map and NARMA. On these tasks, we found that the proposed methods were able to reduce the size of the reservoir up to one tenth without a substantial increase in regression error. Because the applications of the proposed methods are not limited to a specific network structure of the reservoir, the proposed methods could further improve the energy efficiency of RC-based systems, such as FPGAs and photonic systems.
Learning with latent group sparsity via heat flow dynamics on networks
Jan 20, 2022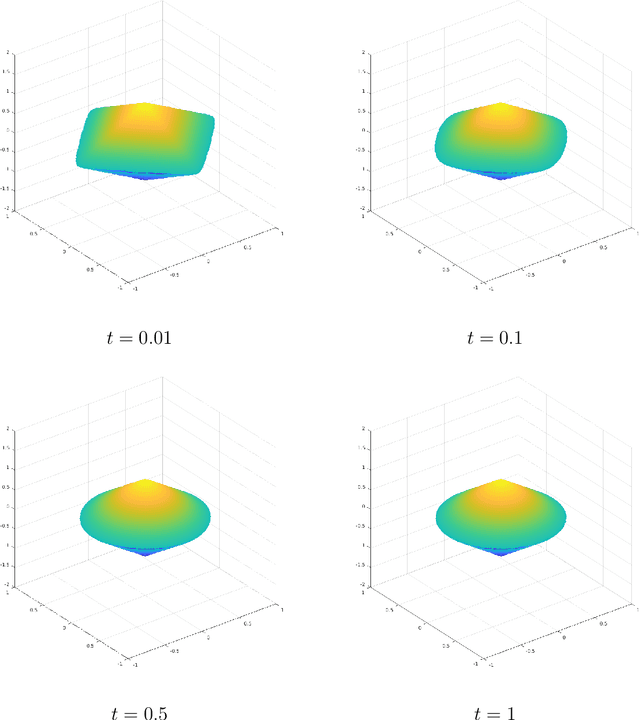
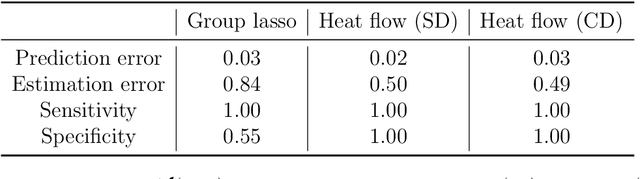
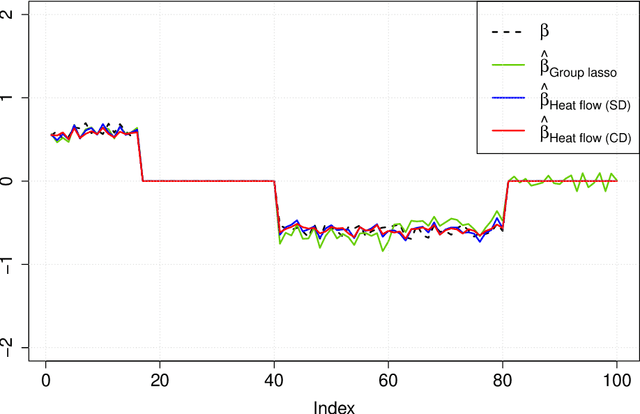
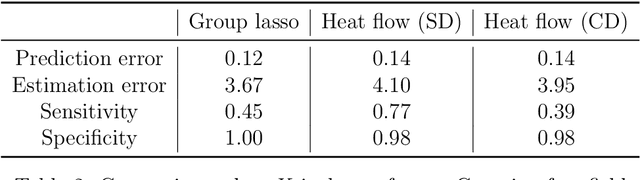
Group or cluster structure on explanatory variables in machine learning problems is a very general phenomenon, which has attracted broad interest from practitioners and theoreticians alike. In this work we contribute an approach to learning under such group structure, that does not require prior information on the group identities. Our paradigm is motivated by the Laplacian geometry of an underlying network with a related community structure, and proceeds by directly incorporating this into a penalty that is effectively computed via a heat flow-based local network dynamics. In fact, we demonstrate a procedure to construct such a network based on the available data. Notably, we dispense with computationally intensive pre-processing involving clustering of variables, spectral or otherwise. Our technique is underpinned by rigorous theorems that guarantee its effective performance and provide bounds on its sample complexity. In particular, in a wide range of settings, it provably suffices to run the heat flow dynamics for time that is only logarithmic in the problem dimensions. We explore in detail the interfaces of our approach with key statistical physics models in network science, such as the Gaussian Free Field and the Stochastic Block Model. We validate our approach by successful applications to real-world data from a wide array of application domains, including computer science, genetics, climatology and economics. Our work raises the possibility of applying similar diffusion-based techniques to classical learning tasks, exploiting the interplay between geometric, dynamical and stochastic structures underlying the data.
Optimal Trajectory Generation for Autonomous Vehicles Under Centripetal Acceleration Constraints for In-lane Driving Scenarios
Dec 03, 2021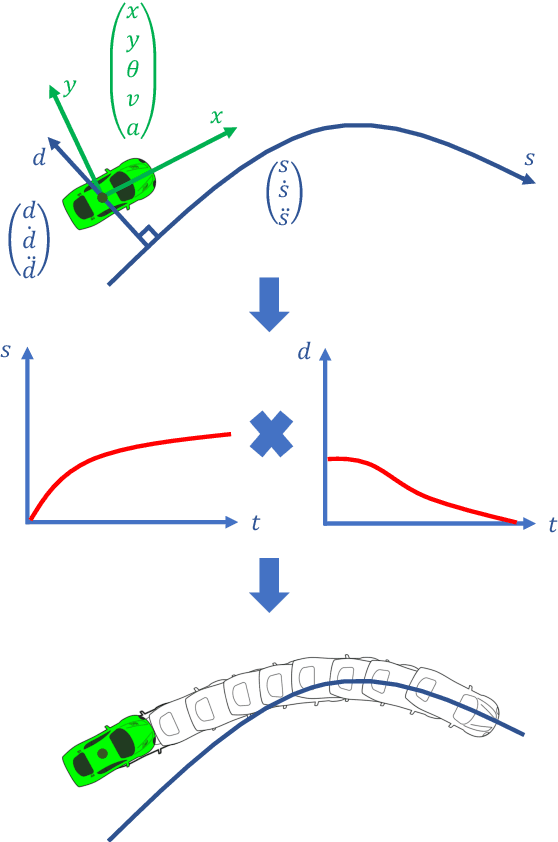
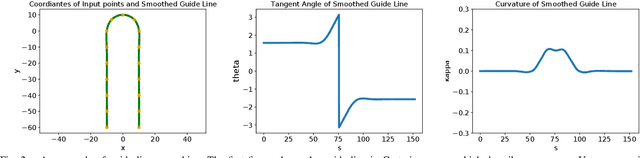
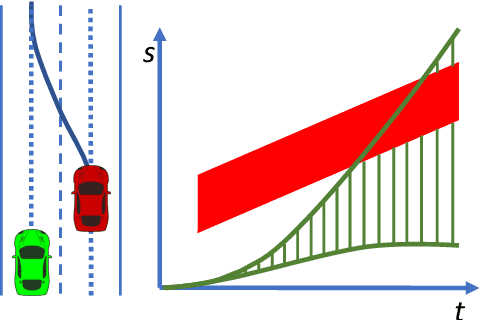
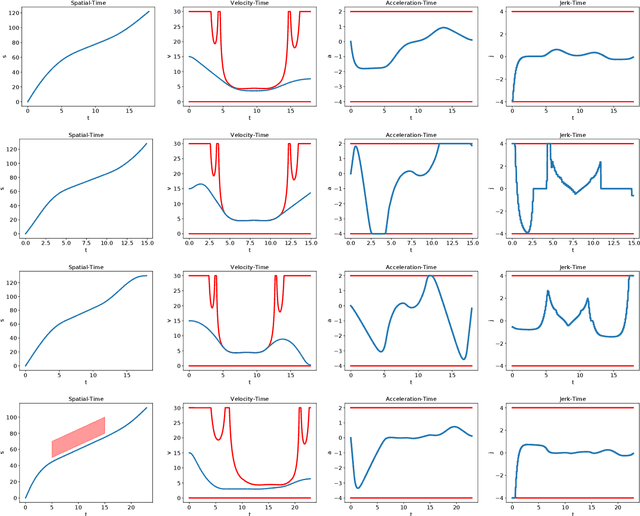
This paper presents a noval method that generates optimal trajectories for autonomous vehicles for in-lane driving scenarios. The method computes a trajectory using a two-phase optimization procedure. In the first phase, the optimization procedure generates a close-form driving guide line with differetiable curvatures. In the second phase, the procedure takes the driving guide line as input, and outputs dynamically feasible, jerk and time optimal trajectories for vehicles driving along the guide line. This method is especially useful for generating trajectories at curvy road where the vehicles need to apply frequent accelerations and decelerations to accommodate centripetal acceleration limits.
Audio representations for deep learning in sound synthesis: A review
Jan 07, 2022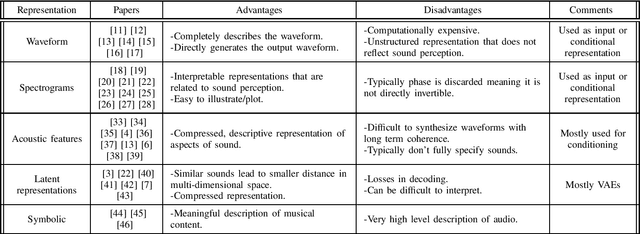
The rise of deep learning algorithms has led many researchers to withdraw from using classic signal processing methods for sound generation. Deep learning models have achieved expressive voice synthesis, realistic sound textures, and musical notes from virtual instruments. However, the most suitable deep learning architecture is still under investigation. The choice of architecture is tightly coupled to the audio representations. A sound's original waveform can be too dense and rich for deep learning models to deal with efficiently - and complexity increases training time and computational cost. Also, it does not represent sound in the manner in which it is perceived. Therefore, in many cases, the raw audio has been transformed into a compressed and more meaningful form using upsampling, feature-extraction, or even by adopting a higher level illustration of the waveform. Furthermore, conditional on the form chosen, additional conditioning representations, different model architectures, and numerous metrics for evaluating the reconstructed sound have been investigated. This paper provides an overview of audio representations applied to sound synthesis using deep learning. Additionally, it presents the most significant methods for developing and evaluating a sound synthesis architecture using deep learning models, always depending on the audio representation.
A Shadowcasting-Based Next-Best-View Planner for Autonomous 3D Exploration
Sep 20, 2021
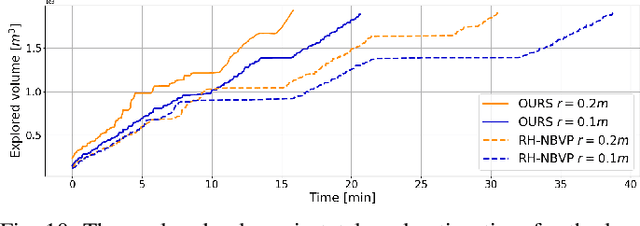
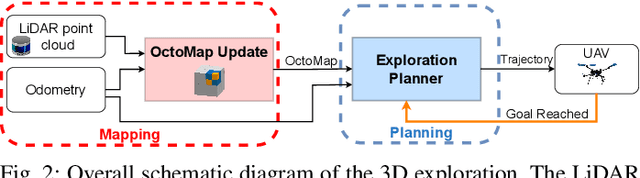
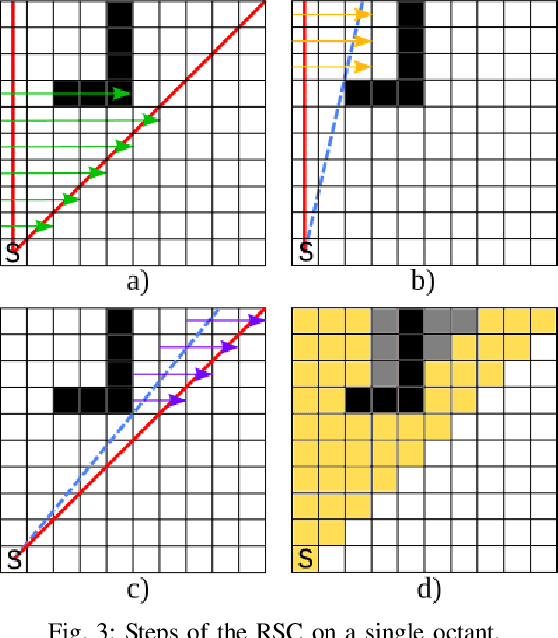
In this paper, we address the problem of autonomous exploration of unknown environments with an aerial robot equipped with a sensory set that produces large point clouds, such as LiDARs. The main goal is to gradually explore an area while planning paths and calculating information gain in short computation time, suitable for implementation on an on-board computer. To this end, we present a planner that randomly samples viewpoints in the environment map. It relies on a novel and efficient gain calculation based on the Recursive Shadowcasting algorithm. To determine the Next-Best-View (NBV), our planner uses a cuboid-based evaluation method that results in an enviably short computation time. To reduce the overall exploration time, we also use a dead end resolving strategy that allows us to quickly recover from dead ends in a challenging environment. Comparative experiments in simulation have shown that our approach outperforms the current state-of-the-art in terms of computational efficiency and total exploration time. The video of our approach can be found at https://www.youtube.com/playlist?list=PLC0C6uwoEQ8ZDhny1VdmFXLeTQOSBibQl.
Profile Guided Optimization without Profiles: A Machine Learning Approach
Dec 24, 2021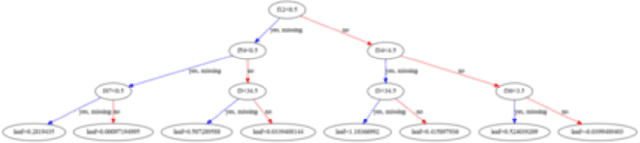

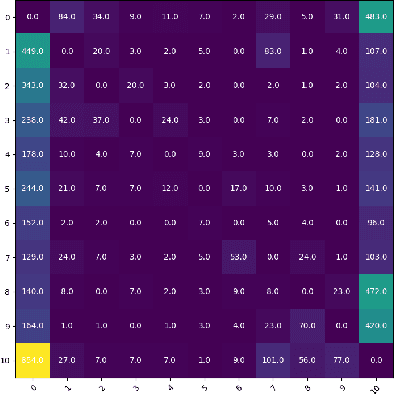
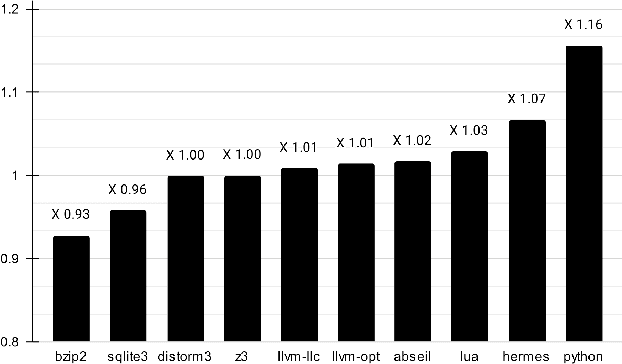
Profile guided optimization is an effective technique for improving the optimization ability of compilers based on dynamic behavior, but collecting profile data is expensive, cumbersome, and requires regular updating to remain fresh. We present a novel statistical approach to inferring branch probabilities that improves the performance of programs that are compiled without profile guided optimizations. We perform offline training using information that is collected from a large corpus of binaries that have branch probabilities information. The learned model is used by the compiler to predict the branch probabilities of regular uninstrumented programs, which the compiler can then use to inform optimization decisions. We integrate our technique directly in LLVM, supplementing the existing human-engineered compiler heuristics. We evaluate our technique on a suite of benchmarks, demonstrating some gains over compiling without profile information. In deployment, our technique requires no profiling runs and has negligible effect on compilation time.
Sentence Embeddings and High-speed Similarity Search for Fast Computer Assisted Annotation of Legal Documents
Dec 21, 2021
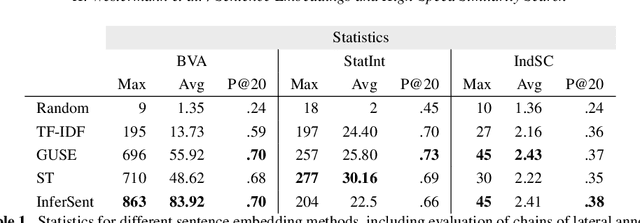
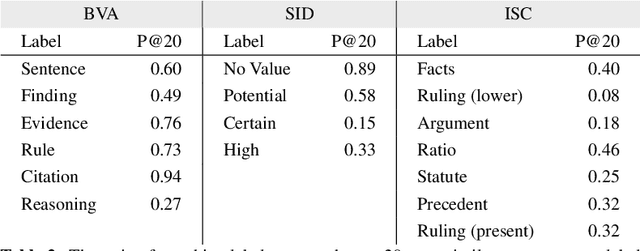
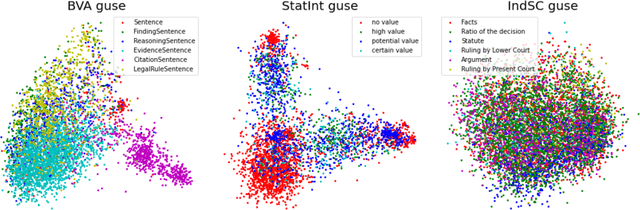
Human-performed annotation of sentences in legal documents is an important prerequisite to many machine learning based systems supporting legal tasks. Typically, the annotation is done sequentially, sentence by sentence, which is often time consuming and, hence, expensive. In this paper, we introduce a proof-of-concept system for annotating sentences "laterally." The approach is based on the observation that sentences that are similar in meaning often have the same label in terms of a particular type system. We use this observation in allowing annotators to quickly view and annotate sentences that are semantically similar to a given sentence, across an entire corpus of documents. Here, we present the interface of the system and empirically evaluate the approach. The experiments show that lateral annotation has the potential to make the annotation process quicker and more consistent.
Continuous-time system identification with neural networks: model structures and fitting criteria
Jun 03, 2020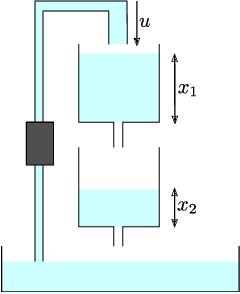
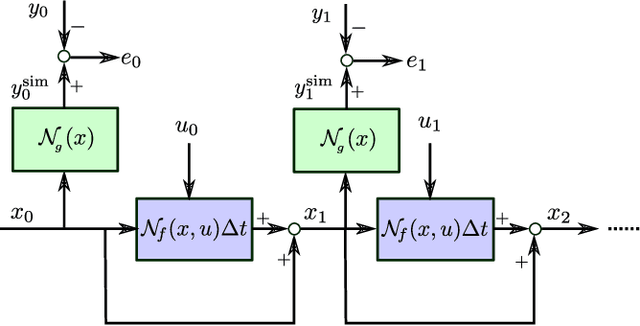
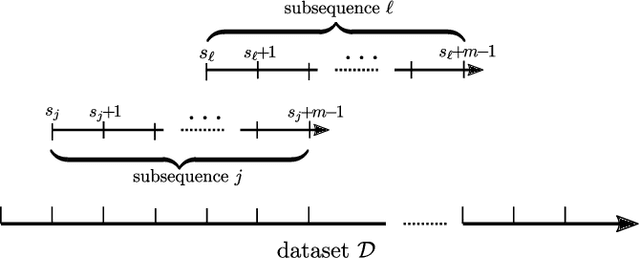
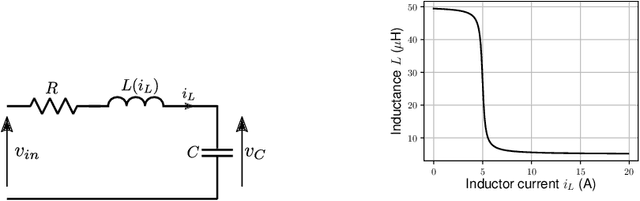
This paper presents tailor-made neural model structures and two custom fitting criteria for learning dynamical systems. The proposed framework is based on a representation of the system behavior in terms of continuous-time state-space models. The sequence of hidden states is optimized along with the neural network parameters in order to minimize the difference between measured and estimated outputs, and at the same time to guarantee that the optimized state sequence is consistent with the estimated system dynamics. The effectiveness of the approach is demonstrated through three case studies, including two public system identification benchmarks based on experimental data.