 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-of-art minibatches via novel DPP kernels: discretization, wavelets, and rough objectives
May 13, 2026Determinantal point processes (DPPs) have emerged as a kernelized alternative to vanilla independent sampling for generating efficient minibatches, coresets and other parsimonious representations of large-scale datasets. While theoretical foundations and promising empirical performance have been demonstrated, there are two challenges for current proposals for DPP-based coresets or minibatches. The first is the need for families of DPPs with certain key variance reduction properties, usually constructed in a continuous setting, of which there are few known examples. The second is the need for an ad-hoc construction of a discrete DPP defined on a given dataset, that inherits such variance reduction. In this work, we contribute to the programme of establishing DPPs as a subsampling toolbox for ML by advancing on these two fronts. First, we propose new DPPs on the Euclidean space based on wavelets, with provably better accuracy guarantees than the best known rates. Second, we introduce a general method to convert such continuous DPPs, which are more amenable to proving analytical statements, into discrete kernels, which are pertinent for subsampling tasks such as minibatch and coreset constructions. This conversion mechanism simultaneously preserves the desired variance decay and reveals a low-rank decomposition of the discrete kernel, which makes sampling the corresponding DPP computationally inexpensive. En route, we enlarge the class of ML tasks amenable to improvements via DPP-based minibatches and coresets to include objective functions with arbitrarily low regularity, and rate guarantees that explicitly adapt to this regularity.
Gaussian mixtures and non-parametric likelihoods through the lens of statistical mechanics
Mar 24, 2026In this work, we investigate Gaussian Mixture Models ({\it abbrv} GMM) and the related problem of non parametric maximum likelihood estimation ({\it abbrv} NPMLE) from the perspective of statistical mechanics. In particular, we establish stability guarantees for the NPMLE procedure that extend well beyond the state of the art. Crucially, we obtain guarantees on the Kullback-Leibler divergence between NPMLE estimators and the ground truth, a type of result which has been known to be challenging in the literature on this problem. In particular, we provide high probability upper bounds on the KL divergence between the NPMLE and the true density that are of the order of $\min\big\{\frac{(\log n)^{d+2}}{n} , \frac{\log n}{\sqrt n}\big\}$, which cover a wide range of scenarios for the comparative sizes of $n$ and $d$. We obtain similar guarantees for approximate solutions to the NPMLE problem, addressing realistic situations wherein optimization algorithms need to be stopped in finite time, allowing access only to approximations to the true NPMLE. A technical cornerstone of our approach is an analysis of the function class complexity of logarithms of gaussian mixture densities, which is able to handle their unboundedness, and could be of wider interest. We also establish correspondences between stability phenomena in the NPMLE problem and concepts from chaos and multiple valleys in random energy landscapes of statistical mechanics models. We believe that these correspondences may be useful for a wide variety of random optimization problems in statistics and machine learning, especially the connections to the the technical ingredients of concentration phenomena and Langevin dynamics for these models.
On the Statistical Optimality of Optimal Decision Trees
Mar 05, 2026While globally optimal empirical risk minimization (ERM) decision trees have become computationally feasible and empirically successful, rigorous theoretical guarantees for their statistical performance remain limited. In this work, we develop a comprehensive statistical theory for ERM trees under random design in both high-dimensional regression and classification. We first establish sharp oracle inequalities that bound the excess risk of the ERM estimator relative to the best possible approximation achievable by any tree with at most $L$ leaves, thereby characterizing the interpretability-accuracy trade-off. We derive these results using a novel uniform concentration framework based on empirically localized Rademacher complexity. Furthermore, we derive minimax optimal rates over a novel function class: the piecewise sparse heterogeneous anisotropic Besov (PSHAB) space. This space explicitly captures three key structural features encountered in practice: sparsity, anisotropic smoothness, and spatial heterogeneity. While our main results are established under sub-Gaussianity, we also provide robust guarantees that hold under heavy-tailed noise settings. Together, these findings provide a principled foundation for the optimality of ERM trees and introduce empirical process tools broadly applicable to other highly adaptive, data-driven procedures.
Filtering through a topological lens: homology for point processes on the time-frequency plane
Apr 10, 2025



We introduce a very general approach to the analysis of signals from their noisy measurements from the perspective of Topological Data Analysis (TDA). While TDA has emerged as a powerful analytical tool for data with pronounced topological structures, here we demonstrate its applicability for general problems of signal processing, without any a-priori geometric feature. Our methods are well-suited to a wide array of time-dependent signals in different scientific domains, with acoustic signals being a particularly important application. We invoke time-frequency representations of such signals, focusing on their zeros which are gaining salience as a signal processing tool in view of their stability properties. Leveraging state-of-the-art topological concepts, such as stable and minimal volumes, we develop a complete suite of TDA-based methods to explore the delicate stochastic geometry of these zeros, capturing signals based on the disruption they cause to this rigid, hyperuniform spatial structure. Unlike classical spatial data tools, TDA is able to capture the full spectrum of the stochastic geometry of the zeros, thereby leading to powerful inferential outcomes that are underpinned by a principled statistical foundation. This is reflected in the power and versatility of our applications, which include competitive performance in processing. a wide variety of audio signals (esp. in low SNR regimes), effective detection and reconstruction of gravitational wave signals (a reputed signal processing challenge with non-Gaussian noise), and medical time series data from EEGs, indicating a wide horizon for the approach and methods introduced in this paper.
Negative Dependence as a toolbox for machine learning : review and new developments
Feb 11, 2025



Negative dependence is becoming a key driver in advancing learning capabilities beyond the limits of traditional independence. Recent developments have evidenced support towards negatively dependent systems as a learning paradigm in a broad range of fundamental machine learning challenges including optimization, sampling, dimensionality reduction and sparse signal recovery, often surpassing the performance of current methods based on statistical independence. The most popular negatively dependent model has been that of determinantal point processes (DPPs), which have their origins in quantum theory. However, other models, such as perturbed lattice models, strongly Rayleigh measures, zeros of random functions have gained salience in various learning applications. In this article, we review this burgeoning field of research, as it has developed over the past two decades or so. We also present new results on applications of DPPs to the parsimonious representation of neural networks. In the limited scope of the article, we mostly focus on aspects of this area to which the authors contributed over the recent years, including applications to Monte Carlo methods, coresets and stochastic gradient descent, stochastic networks, signal processing and connections to quantum computation. However, starting from basics of negative dependence for the uninitiated reader, extensive references are provided to a broad swath of related developments which could not be covered within our limited scope. While existing works and reviews generally focus on specific negatively dependent models (e.g. DPPs), a notable feature of this article is that it addresses negative dependence as a machine learning methodology as a whole. In this vein, it covers within its span an array of negatively dependent models and their applications well beyond DPPs, thereby putting forward a very general and rather unique perspective.
Small coresets via negative dependence: DPPs, linear statistics, and concentration
Nov 01, 2024

Determinantal point processes (DPPs) are random configurations of points with tunable negative dependence. Because sampling is tractable, DPPs are natural candidates for subsampling tasks, such as minibatch selection or coreset construction. A \emph{coreset} is a subset of a (large) training set, such that minimizing an empirical loss averaged over the coreset is a controlled replacement for the intractable minimization of the original empirical loss. Typically, the control takes the form of a guarantee that the average loss over the coreset approximates the total loss uniformly across the parameter space. Recent work has provided significant empirical support in favor of using DPPs to build randomized coresets, coupled with interesting theoretical results that are suggestive but leave some key questions unanswered. In particular, the central question of whether the cardinality of a DPP-based coreset is fundamentally smaller than one based on independent sampling remained open. In this paper, we answer this question in the affirmative, demonstrating that \emph{DPPs can provably outperform independently drawn coresets}. In this vein, we contribute a conceptual understanding of coreset loss as a \emph{linear statistic} of the (random) coreset. We leverage this structural observation to connect the coresets problem to a more general problem of concentration phenomena for linear statistics of DPPs, wherein we obtain \emph{effective concentration inequalities that extend well-beyond the state-of-the-art}, encompassing general non-projection, even non-symmetric kernels. The latter have been recently shown to be of interest in machine learning beyond coresets, but come with a limited theoretical toolbox, to the extension of which our result contributes. Finally, we are also able to address the coresets problem for vector-valued objective functions, a novelty in the coresets literature.
Dictionary Learning under Symmetries via Group Representations
May 31, 2023The dictionary learning problem can be viewed as a data-driven process to learn a suitable transformation so that data is sparsely represented directly from example data. In this paper, we examine the problem of learning a dictionary that is invariant under a pre-specified group of transformations. Natural settings include Cryo-EM, multi-object tracking, synchronization, pose estimation, etc. We specifically study this problem under the lens of mathematical representation theory. Leveraging the power of non-abelian Fourier analysis for functions over compact groups, we prescribe an algorithmic recipe for learning dictionaries that obey such invariances. We relate the dictionary learning problem in the physical domain, which is naturally modelled as being infinite dimensional, with the associated computational problem, which is necessarily finite dimensional. We establish that the dictionary learning problem can be effectively understood as an optimization instance over certain matrix orbitopes having a particular block-diagonal structure governed by the irreducible representations of the group of symmetries. This perspective enables us to introduce a band-limiting procedure which obtains dimensionality reduction in applications. We provide guarantees for our computational ansatz to provide a desirable dictionary learning outcome. We apply our paradigm to investigate the dictionary learning problem for the groups SO(2) and SO(3). While the SO(2) orbitope admits an exact spectrahedral description, substantially less is understood about the SO(3) orbitope. We describe a tractable spectrahedral outer approximation of the SO(3) orbitope, and contribute an alternating minimization paradigm to perform optimization in this setting. We provide numerical experiments to highlight the efficacy of our approach in learning SO(3) invariant dictionaries, both on synthetic and on real world data.
Generative Principal Component Analysis
Mar 18, 2022
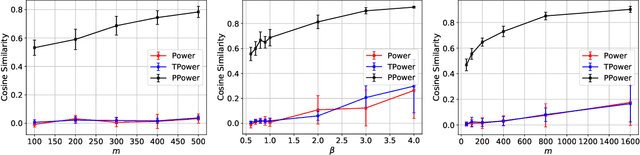


In this paper, we study the problem of principal component analysis with generative modeling assumptions, adopting a general model for the observed matrix that encompasses notable special cases, including spiked matrix recovery and phase retrieval. The key assumption is that the underlying signal lies near the range of an $L$-Lipschitz continuous generative model with bounded $k$-dimensional inputs. We propose a quadratic estimator, and show that it enjoys a statistical rate of order $\sqrt{\frac{k\log L}{m}}$, where $m$ is the number of samples. We also provide a near-matching algorithm-independent lower bound. Moreover, we provide a variant of the classic power method, which projects the calculated data onto the range of the generative model during each iteration. We show that under suitable conditions, this method converges exponentially fast to a point achieving the above-mentioned statistical rate. We perform experiments on various image datasets for spiked matrix and phase retrieval models, and illustrate performance gains of our method to the classic power method and the truncated power method devised for sparse principal component analysis.
Learning with latent group sparsity via heat flow dynamics on networks
Jan 20, 2022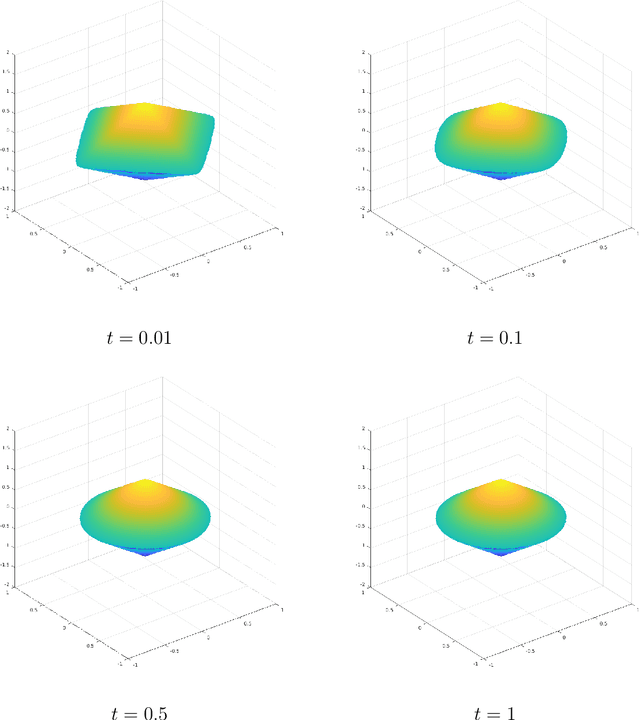
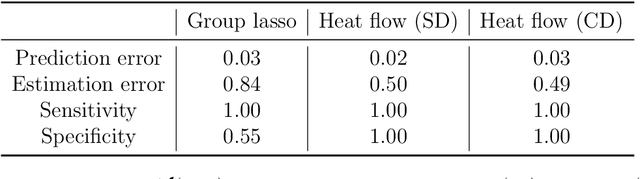
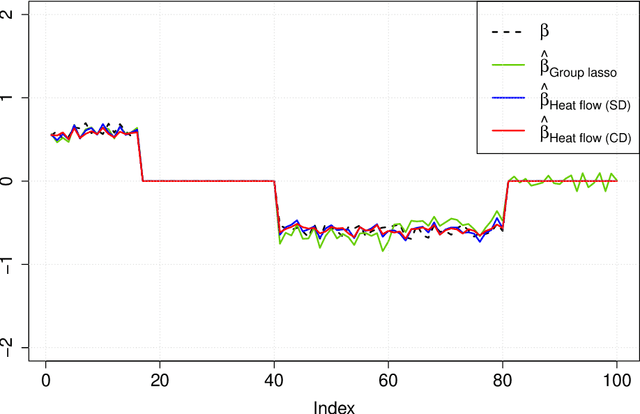
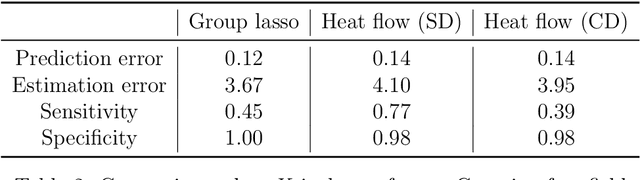
Group or cluster structure on explanatory variables in machine learning problems is a very general phenomenon, which has attracted broad interest from practitioners and theoreticians alike. In this work we contribute an approach to learning under such group structure, that does not require prior information on the group identities. Our paradigm is motivated by the Laplacian geometry of an underlying network with a related community structure, and proceeds by directly incorporating this into a penalty that is effectively computed via a heat flow-based local network dynamics. In fact, we demonstrate a procedure to construct such a network based on the available data. Notably, we dispense with computationally intensive pre-processing involving clustering of variables, spectral or otherwise. Our technique is underpinned by rigorous theorems that guarantee its effective performance and provide bounds on its sample complexity. In particular, in a wide range of settings, it provably suffices to run the heat flow dynamics for time that is only logarithmic in the problem dimensions. We explore in detail the interfaces of our approach with key statistical physics models in network science, such as the Gaussian Free Field and the Stochastic Block Model. We validate our approach by successful applications to real-world data from a wide array of application domains, including computer science, genetics, climatology and economics. Our work raises the possibility of applying similar diffusion-based techniques to classical learning tasks, exploiting the interplay between geometric, dynamical and stochastic structures underlying the data.
Robust 1-bit Compressive Sensing with Partial Gaussian Circulant Matrices and Generative Priors
Aug 08, 2021

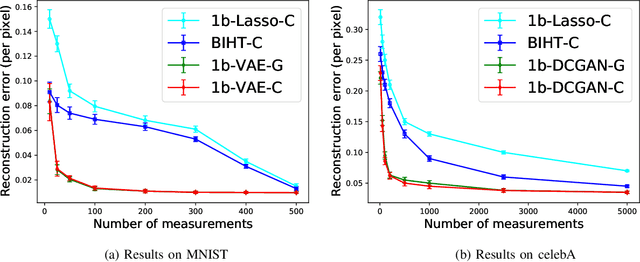

In 1-bit compressive sensing, each measurement is quantized to a single bit, namely the sign of a linear function of an unknown vector, and the goal is to accurately recover the vector. While it is most popular to assume a standard Gaussian sensing matrix for 1-bit compressive sensing, using structured sensing matrices such as partial Gaussian circulant matrices is of significant practical importance due to their faster matrix operations. In this paper, we provide recovery guarantees for a correlation-based optimization algorithm for robust 1-bit compressive sensing with randomly signed partial Gaussian circulant matrices and generative models. Under suitable assumptions, we match guarantees that were previously only known to hold for i.i.d.~Gaussian matrices that require significantly more computation. We make use of a practical iterative algorithm, and perform numerical experiments on image datasets to corroborate our theoretical results.