 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Signal Decomposition Using Masked Proximal Operators
Feb 18, 2022
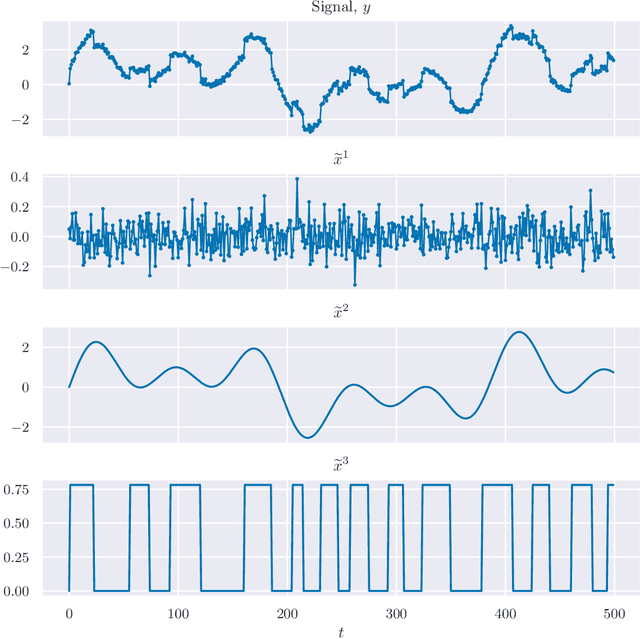
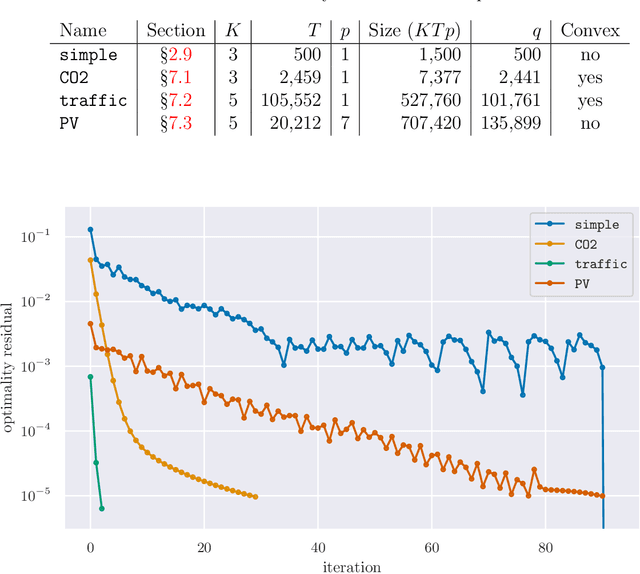
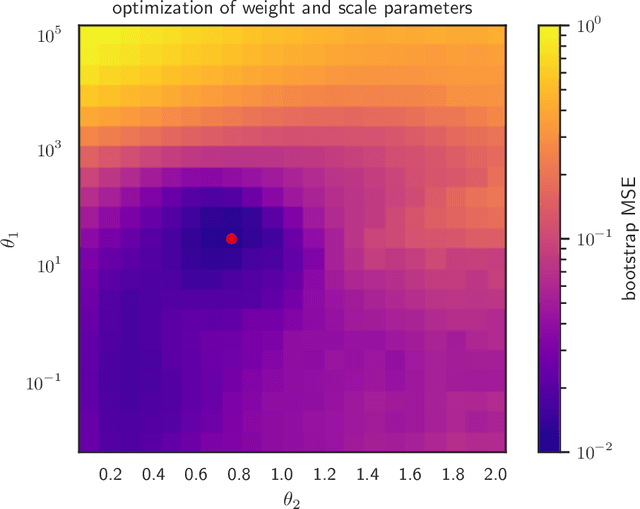
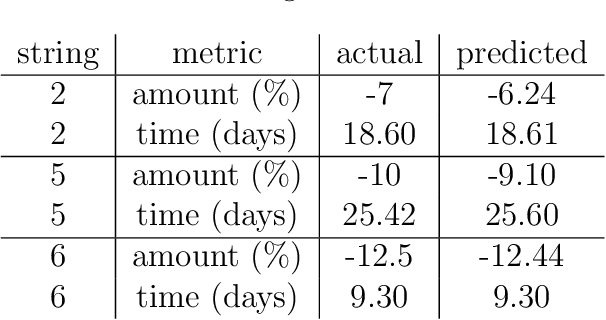
We consider the well-studied problem of decomposing a vector time series signal into components with different characteristics, such as smooth, periodic, nonnegative, or sparse. We propose a simple and general framework in which the components are defined by loss functions (which include constraints), and the signal decomposition is carried out by minimizing the sum of losses of the components (subject to the constraints). When each loss function is the negative log-likelihood of a density for the signal component, our method coincides with maximum a posteriori probability (MAP) estimation; but it also includes many other interesting cases. We give two distributed optimization methods for computing the decomposition, which find the optimal decomposition when the component class loss functions are convex, and are good heuristics when they are not. Both methods require only the masked proximal operator of each of the component loss functions, a generalization of the well-known proximal operator that handles missing entries in its argument. Both methods are distributed, i.e., handle each component separately. We derive tractable methods for evaluating the masked proximal operators of some loss functions that, to our knowledge, have not appeared in the literature.
A Real-World Implementation of Unbiased Lift-based Bidding System
Feb 23, 2022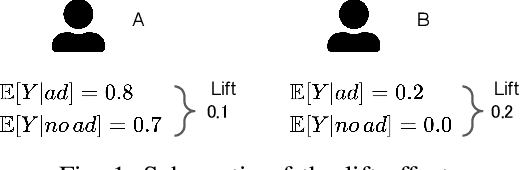
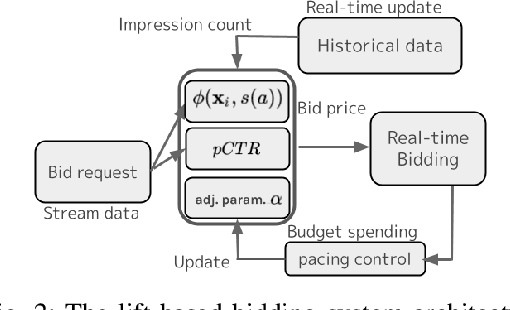
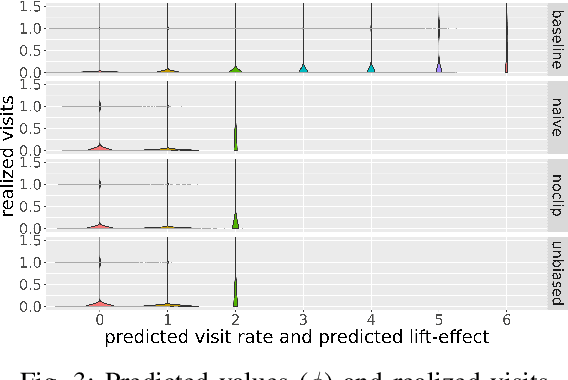
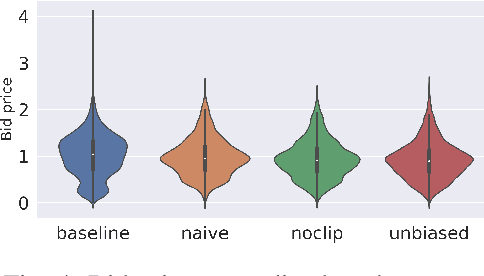
In display ad auctions of Real-Time Bid-ding (RTB), a typical Demand-Side Platform (DSP)bids based on the predicted probability of click and conversion right after an ad impression. Recent studies find such a strategy is suboptimal and propose a better bidding strategy named lift-based bidding.Lift-based bidding simply bids the price according to the lift effect of the ad impression and achieves maximization of target metrics such as sales. Despiteits superiority, lift-based bidding has not yet been widely accepted in the advertising industry. For one reason, lift-based bidding is less profitable for DSP providers under the current billing rule. Second, thepractical usefulness of lift-based bidding is not widely understood in the online advertising industry due to the lack of a comprehensive investigation of its impact.We here propose a practically-implementable lift-based bidding system that perfectly fits the current billing rules. We conduct extensive experiments usinga real-world advertising campaign and examine the performance under various settings. We find that lift-based bidding, especially unbiased lift-based bidding is most profitable for both DSP providers and advertisers. Our ablation study highlights that lift-based bidding has a good property for currently dominant first price auctions. The results will motivate the online
Iterative Knowledge Exchange Between Deep Learning and Space-Time Spectral Clustering for Unsupervised Segmentation in Videos
Dec 13, 2020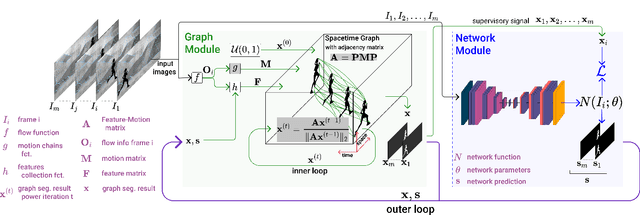
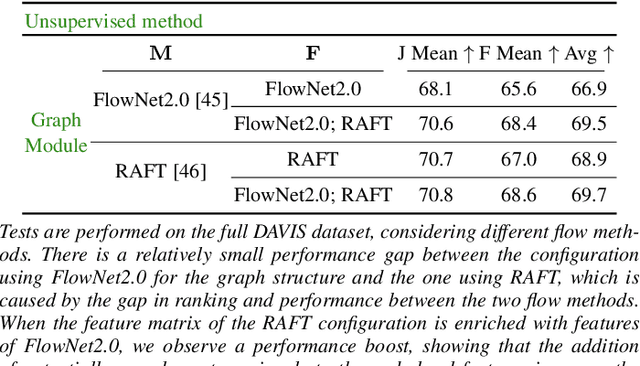
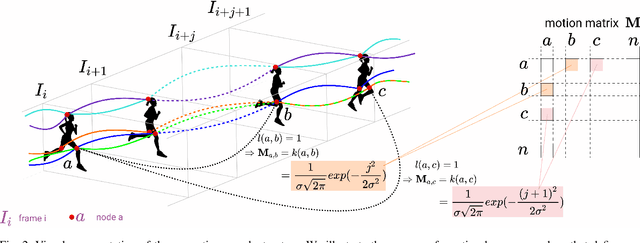
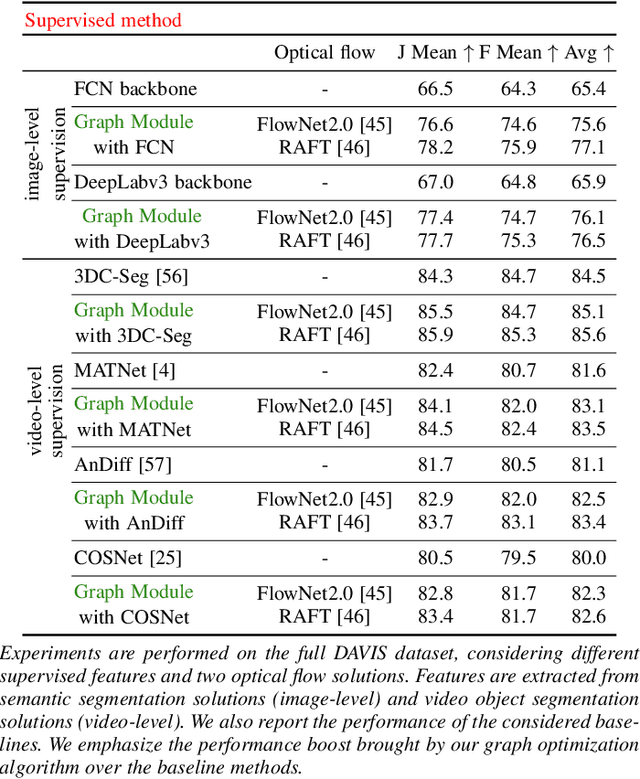
We propose a dual system for unsupervised object segmentation in video, which brings together two modules with complementary properties: a space-time graph that discovers objects in videos and a deep network that learns powerful object features. The system uses an iterative knowledge exchange policy. A novel spectral space-time clustering process on the graph produces unsupervised segmentation masks passed to the network as pseudo-labels. The net learns to segment in single frames what the graph discovers in video and passes back to the graph strong image-level features that improve its node-level features in the next iteration. Knowledge is exchanged for several cycles until convergence. The graph has one node per each video pixel, but the object discovery is fast. It uses a novel power iteration algorithm computing the main space-time cluster as the principal eigenvector of a special Feature-Motion matrix without actually computing the matrix. The thorough experimental analysis validates our theoretical claims and proves the effectiveness of the cyclical knowledge exchange. We also perform experiments on the supervised scenario, incorporating features pretrained with human supervision. We achieve state-of-the-art level on unsupervised and supervised scenarios on four challenging datasets: DAVIS, SegTrack, YouTube-Objects, and DAVSOD.
MLProxy: SLA-Aware Reverse Proxy for Machine Learning Inference Serving on Serverless Computing Platforms
Feb 23, 2022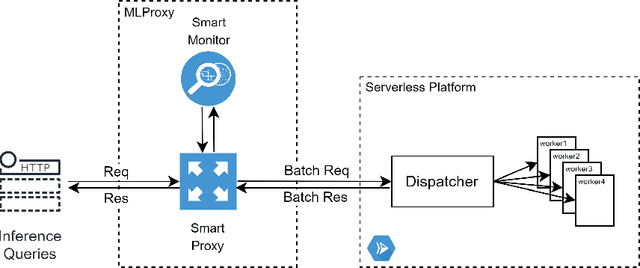
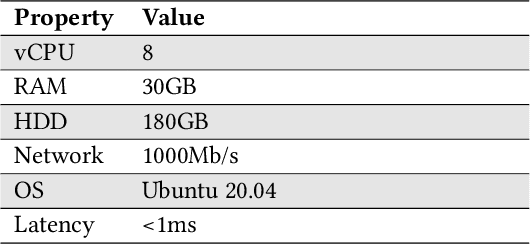
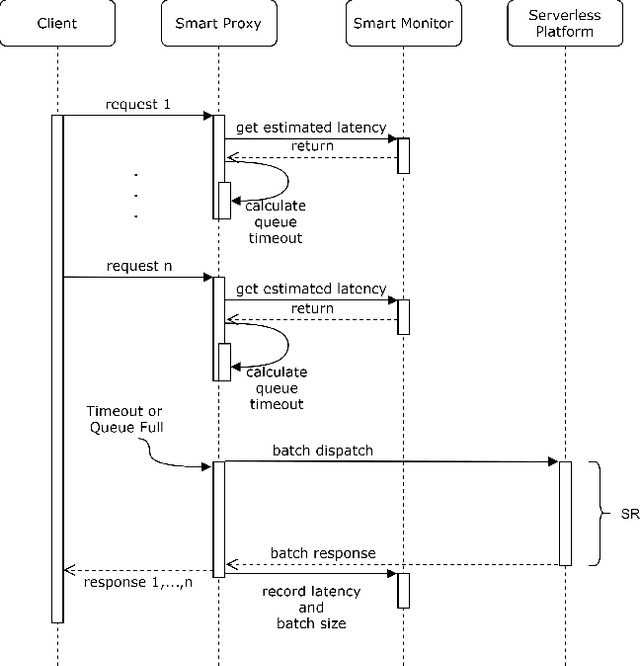

Serving machine learning inference workloads on the cloud is still a challenging task on the production level. Optimal configuration of the inference workload to meet SLA requirements while optimizing the infrastructure costs is highly complicated due to the complex interaction between batch configuration, resource configurations, and variable arrival process. Serverless computing has emerged in recent years to automate most infrastructure management tasks. Workload batching has revealed the potential to improve the response time and cost-effectiveness of machine learning serving workloads. However, it has not yet been supported out of the box by serverless computing platforms. Our experiments have shown that for various machine learning workloads, batching can hugely improve the system's efficiency by reducing the processing overhead per request. In this work, we present MLProxy, an adaptive reverse proxy to support efficient machine learning serving workloads on serverless computing systems. MLProxy supports adaptive batching to ensure SLA compliance while optimizing serverless costs. We performed rigorous experiments on Knative to demonstrate the effectiveness of MLProxy. We showed that MLProxy could reduce the cost of serverless deployment by up to 92% while reducing SLA violations by up to 99% that can be generalized across state-of-the-art model serving frameworks.
STformer: A Noise-Aware Efficient Spatio-Temporal Transformer Architecture for Traffic Forecasting
Dec 06, 2021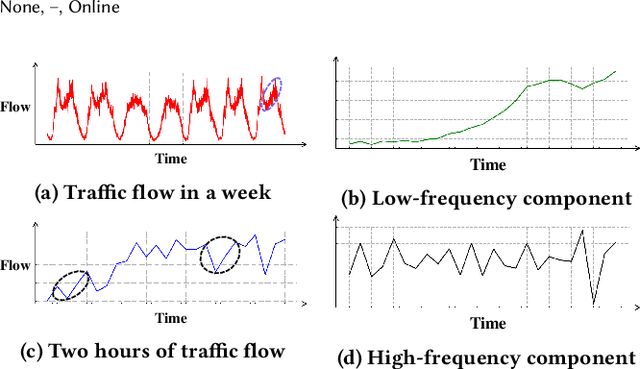
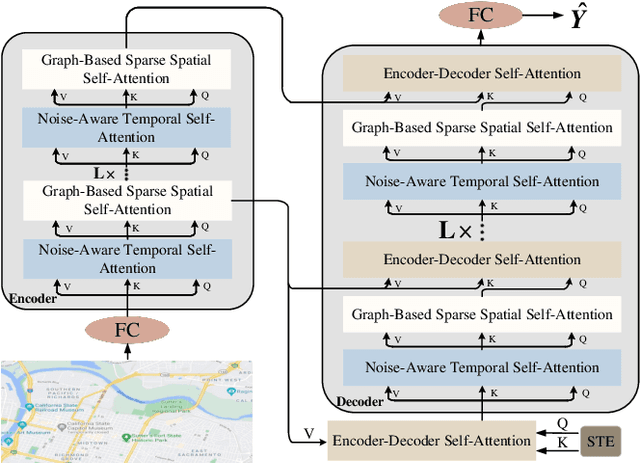
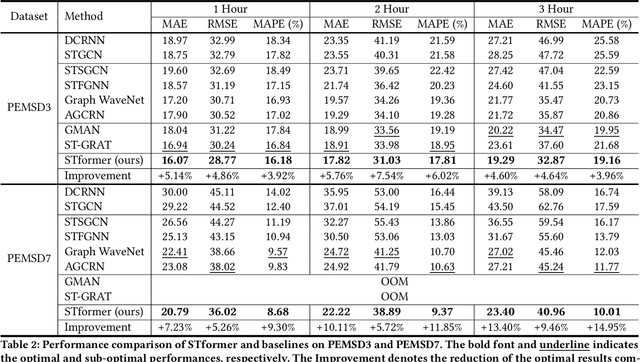
Traffic forecasting plays an indispensable role in the intelligent transportation system, which makes daily travel more convenient and safer. However, the dynamic evolution of spatio-temporal correlations makes accurate traffic forecasting very difficult. Existing work mainly employs graph neural netwroks (GNNs) and deep time series models (e.g., recurrent neural networks) to capture complex spatio-temporal patterns in the dynamic traffic system. For the spatial patterns, it is difficult for GNNs to extract the global spatial information, i.e., remote sensors information in road networks. Although we can use the self-attention to extract global spatial information as in the previous work, it is also accompanied by huge resource consumption. For the temporal patterns, traffic data have not only easy-to-recognize daily and weekly trends but also difficult-to-recognize short-term noise caused by accidents (e.g., car accidents and thunderstorms). Prior traffic models are difficult to distinguish intricate temporal patterns in time series and thus hard to get accurate temporal dependence. To address above issues, we propose a novel noise-aware efficient spatio-temporal Transformer architecture for accurate traffic forecasting, named STformer. STformer consists of two components, which are the noise-aware temporal self-attention (NATSA) and the graph-based sparse spatial self-attention (GBS3A). NATSA separates the high-frequency component and the low-frequency component from the time series to remove noise and capture stable temporal dependence by the learnable filter and the temporal self-attention, respectively. GBS3A replaces the full query in vanilla self-attention with the graph-based sparse query to decrease the time and memory usage. Experiments on four real-world traffic datasets show that STformer outperforms state-of-the-art baselines with lower computational cost.
Training (Overparametrized) Neural Networks in Near-Linear Time
Jun 20, 2020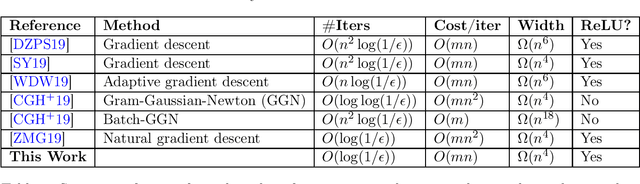
The slow convergence rate and pathological curvature issues of first-order gradient methods for training deep neural networks, initiated an ongoing effort for developing faster $\mathit{second}$-$\mathit{order}$ optimization algorithms beyond SGD, without compromising the generalization error. Despite their remarkable convergence rate ($\mathit{independent}$ of the training batch size $n$), second-order algorithms incur a daunting slowdown in the $\mathit{cost}$ $\mathit{per}$ $\mathit{iteration}$ (inverting the Hessian matrix of the loss function), which renders them impractical. Very recently, this computational overhead was mitigated by the works of [ZMG19, CGH+19], yielding an $O(Mn^2)$-time second-order algorithm for training overparametrized neural networks with $M$ parameters. We show how to speed up the algorithm of [CGH+19], achieving an $\tilde{O}(Mn)$-time backpropagation algorithm for training (mildly overparametrized) ReLU networks, which is near-linear in the dimension ($Mn$) of the full gradient (Jacobian) matrix. The centerpiece of our algorithm is to reformulate the Gauss-Newton iteration as an $\ell_2$-regression problem, and then use a Fast-JL type dimension reduction to $\mathit{precondition} $ the underlying Gram matrix in time independent of $M$, allowing to find a sufficiently good approximate solution via $\mathit{first}$-$\mathit{order}$ conjugate gradient. Our result provides a proof-of-concept that advanced machinery from randomized linear algebra-which led to recent breakthroughs in $\mathit{convex}$ $\mathit{optimization}$ (ERM, LPs, Regression)-can be carried over to the realm of deep learning as well.
Needs and Artificial Intelligence
Feb 18, 2022Throughout their history, homo sapiens have used technologies to better satisfy their needs. The relation between needs and technology is so fundamental that the US National Research Council defined the distinguishing characteristic of technology as its goal "to make modifications in the world to meet human needs". Artificial intelligence (AI) is one of the most promising emerging technologies of our time. Similar to other technologies, AI is expected "to meet [human] needs". In this article, we reflect on the relationship between needs and AI, and call for the realisation of needs-aware AI systems. We argue that re-thinking needs for, through, and by AI can be a very useful means towards the development of realistic approaches for Sustainable, Human-centric, Accountable, Lawful, and Ethical (HALE) AI systems. We discuss some of the most critical gaps, barriers, enablers, and drivers of co-creating future AI-based socio-technical systems in which [human] needs are well considered and met. Finally, we provide an overview of potential threats and HALE considerations that should be carefully taken into account, and call for joint, immediate, and interdisciplinary efforts and collaborations.
Energy-Aware Multi-Robot Task Allocation in Persistent Tasks
Dec 31, 2021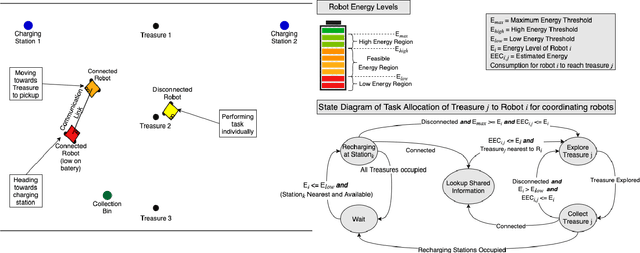
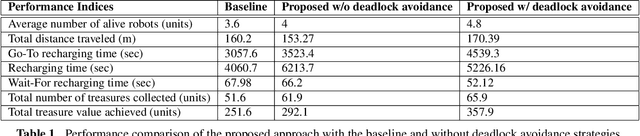

The applicability of the swarm robots to perform foraging tasks is inspired by their compact size and cost. A considerable amount of energy is required to perform such tasks, especially if the tasks are continuous and/or repetitive. Real-world situations in which robots perform tasks continuously while staying alive (survivability) and maximizing production (performance) require energy awareness. This paper proposes an energy-conscious distributed task allocation algorithm to solve continuous tasks (e.g., unlimited foraging) for cooperative robots to achieve highly effective missions. We consider efficiency as a function of the energy consumed by the robot during exploration and collection when food is returned to the collection bin. Finally, the proposed energy-efficient algorithm minimizes the total transit time to the charging station and time consumed while recharging and maximizes the robot's lifetime to perform maximum tasks to enhance the overall efficiency of collaborative robots. We evaluated the proposed solution against a typical greedy benchmarking strategy (assigning the closest collection bin to the available robot and recharging the robot at maximum) for efficiency and performance in various scenarios. The proposed approach significantly improved performance and efficiency over the baseline approach.
What Can Machine Vision Do for Lymphatic Histopathology Image Analysis: A Comprehensive Review
Jan 21, 2022
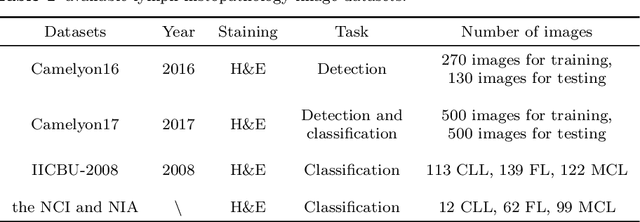
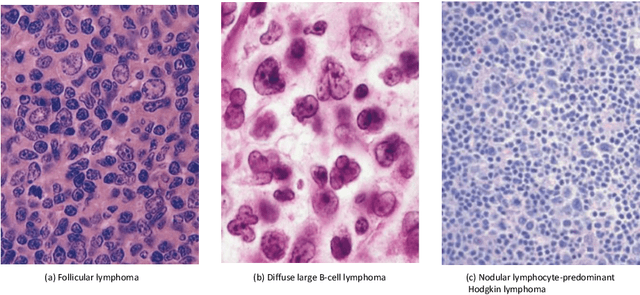
In the past ten years, the computing power of machine vision (MV) has been continuously improved, and image analysis algorithms have developed rapidly. At the same time, histopathological slices can be stored as digital images. Therefore, MV algorithms can provide doctors with diagnostic references. In particular, the continuous improvement of deep learning algorithms has further improved the accuracy of MV in disease detection and diagnosis. This paper reviews the applications of image processing technology based on MV in lymphoma histopathological images in recent years, including segmentation, classification and detection. Finally, the current methods are analyzed, some more potential methods are proposed, and further prospects are made.
A New Generation of Perspective API: Efficient Multilingual Character-level Transformers
Feb 22, 2022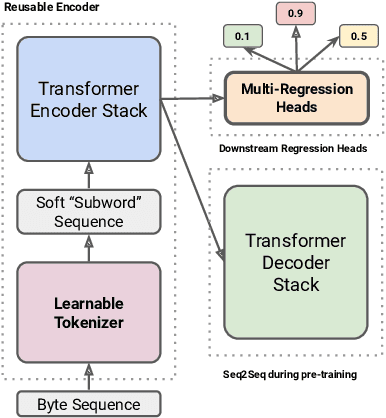
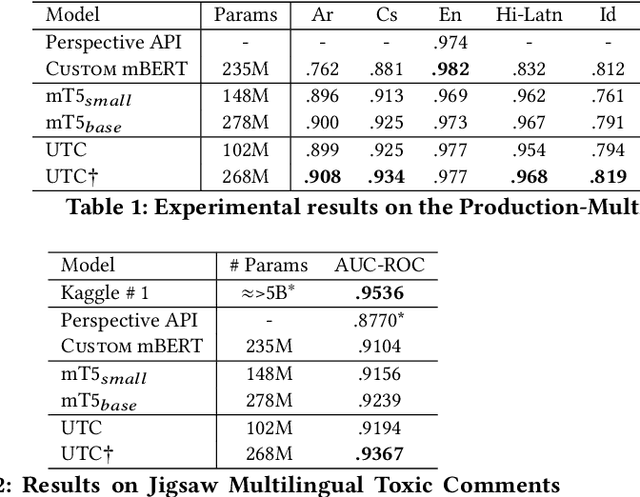
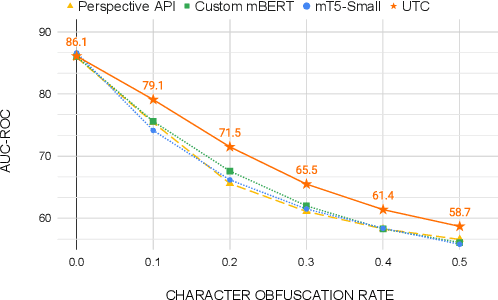
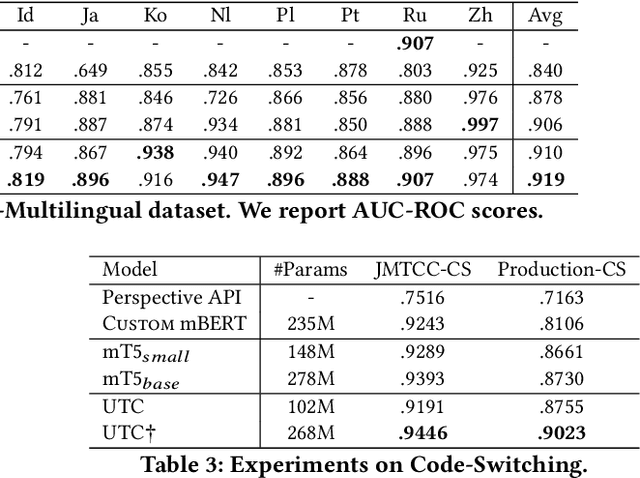
On the world wide web, toxic content detectors are a crucial line of defense against potentially hateful and offensive messages. As such, building highly effective classifiers that enable a safer internet is an important research area. Moreover, the web is a highly multilingual, cross-cultural community that develops its own lingo over time. As such, it is crucial to develop models that are effective across a diverse range of languages, usages, and styles. In this paper, we present the fundamentals behind the next version of the Perspective API from Google Jigsaw. At the heart of the approach is a single multilingual token-free Charformer model that is applicable across a range of languages, domains, and tasks. We demonstrate that by forgoing static vocabularies, we gain flexibility across a variety of settings. We additionally outline the techniques employed to make such a byte-level model efficient and feasible for productionization. Through extensive experiments on multilingual toxic comment classification benchmarks derived from real API traffic and evaluation on an array of code-switching, covert toxicity, emoji-based hate, human-readable obfuscation, distribution shift, and bias evaluation settings, we show that our proposed approach outperforms strong baselines. Finally, we present our findings from deploying this system in production.