 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive Information Belief Space Planning
Jan 28, 2022
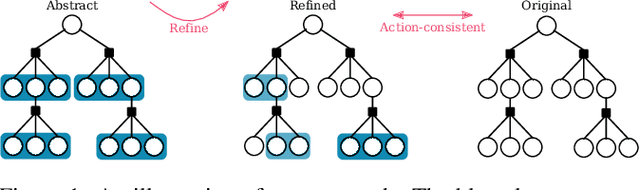
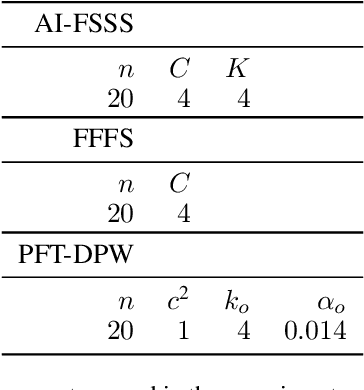
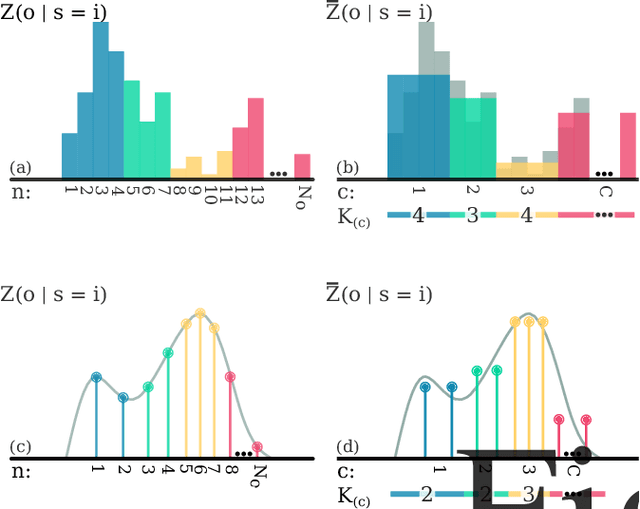
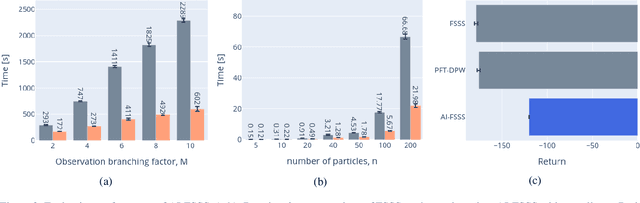
Reasoning about uncertainty is vital in many real-life autonomous systems. However, current state-of-the-art planning algorithms cannot either reason about uncertainty explicitly, or do so with a high computational burden. Here, we focus on making informed decisions efficiently, using reward functions that explicitly deal with uncertainty. We formulate an approximation, namely an abstract observation model, that uses an aggregation scheme to alleviate computational costs. We derive bounds on the expected information-theoretic reward function and, as a consequence, on the value function. We then propose a method to refine aggregation to achieve identical action selection with a fraction of the computational time.
Elastica Models for Color Image Regularization
Mar 18, 2022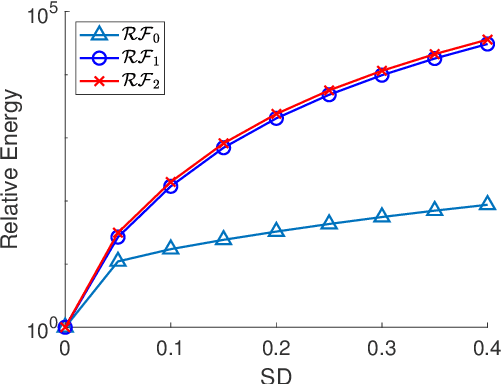
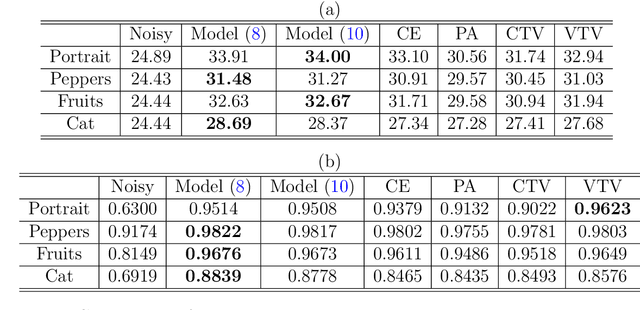

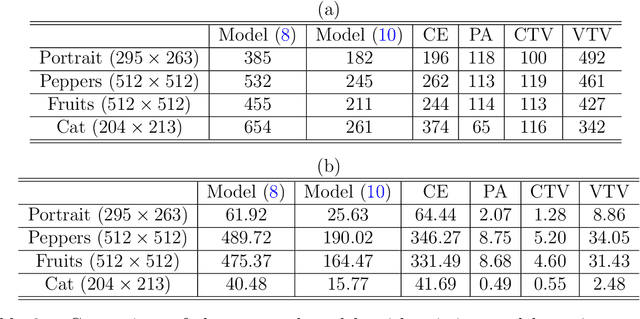
One classical approach to regularize color is to tream them as two dimensional surfaces embedded in a five dimensional spatial-chromatic space. In this case, a natural regularization term arises as the image surface area. Choosing the chromatic coordinates as dominating over the spatial ones, the image spatial coordinates could be thought of as a paramterization of the image surface manifold in a three dimensional color space. Minimizing the area of the image manifold leads to the Beltrami flow or mean curvature flow of the image surface in the 3D color space, while minimizing the elastica of the image surface yields an additional interesting regularization. Recently, the authors proposed a color elastica model, which minimizes both the surface area and elastica of the image manifold. In this paper, we propose to modify the color elastica and introduce two new models for color image regularization. The revised measures are motivated by the relations between the color elastica model, Euler's elastica model and the total variation model for gray level images. Compared to our previous color elastica model, the new models are direct extensions of Euler's elastica model to color images. The proposed models are nonlinear and challenging to minimize. To overcome this difficulty, two operator-splitting methods are suggested. Specifically, nonlinearities are decoupled by introducing new vector- and matrix-valued variables. Then, the minimization problems are converted to solving initial value problems which are time-discretized by operator splitting. Each subproblem, after splitting either, has a closed-form solution or can be solved efficiently. The effectiveness and advantages of the proposed models are demonstrated by comprehensive experiments. The benefits of incorporating the elastica of the image surface as regularization terms compared to common alternatives are empirically validated.
Conceptual Modeling of Time for Computational Ontologies
Jul 16, 2020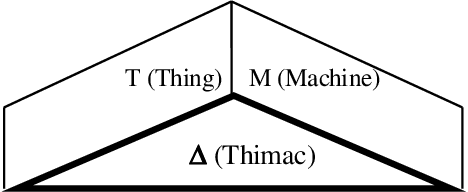
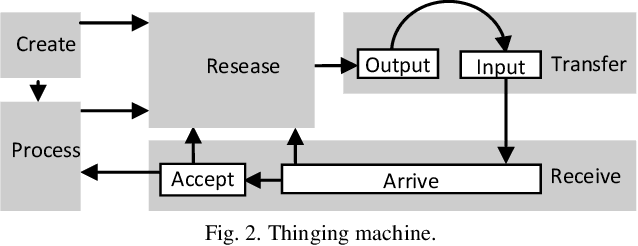
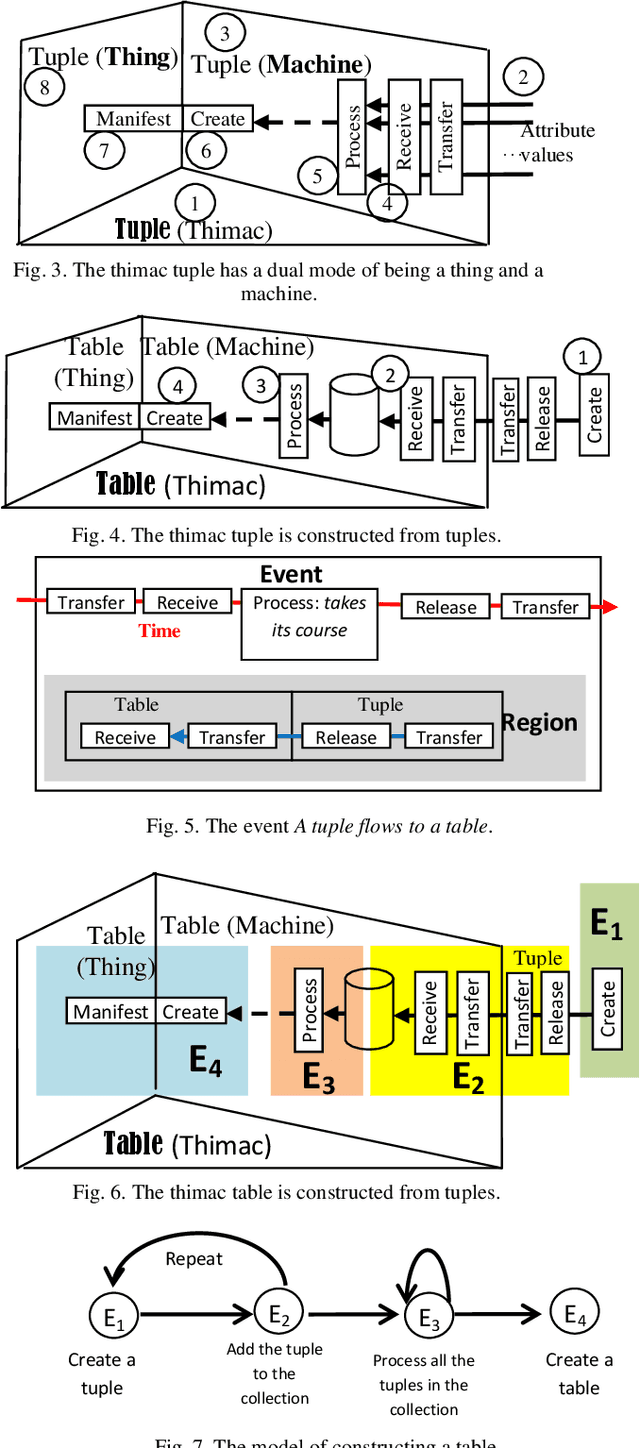
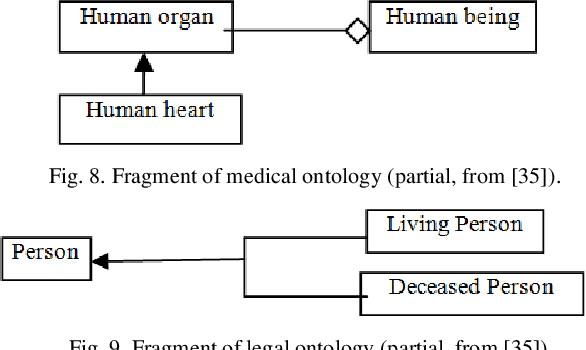
To provide a foundation for conceptual modeling, ontologies have been introduced to specify the entities, the existences of which are acknowledged in the model. Ontologies are essential components as mechanisms to model a portion of reality in software engineering. In this context, a model refers to a description of objects and processes that populate a system. Developing such a description constrains and directs the design, development, and use of the corresponding system, thus avoiding such difficulties as conflicts and lack of a common understanding. In this cross-area research between modeling and ontology, there has been a growing interest in the development and use of domain ontologies (e.g., Resource Description Framework, Ontology Web Language). This paper contributes to the establishment of a broad ontological foundation for conceptual modeling in a specific domain through proposing a workable ontology (abbreviated as TM). A TM is a one-category ontology called a thimac (things/machines) that is used to elaborate the design and analysis of ontological presumptions. The focus of the study is on such notions as change, event, and time. Several current ontological difficulties are reviewed and remodeled in the TM. TM modeling is also contrasted with time representation in SysML. The results demonstrate that a TM is a useful tool for addressing these ontological problems.
* 14 pages, 27 figures
A Multidisciplinary Approach to Optimal Communication and Flight Operation of High Altitude Long Endurance Platform
Mar 01, 2022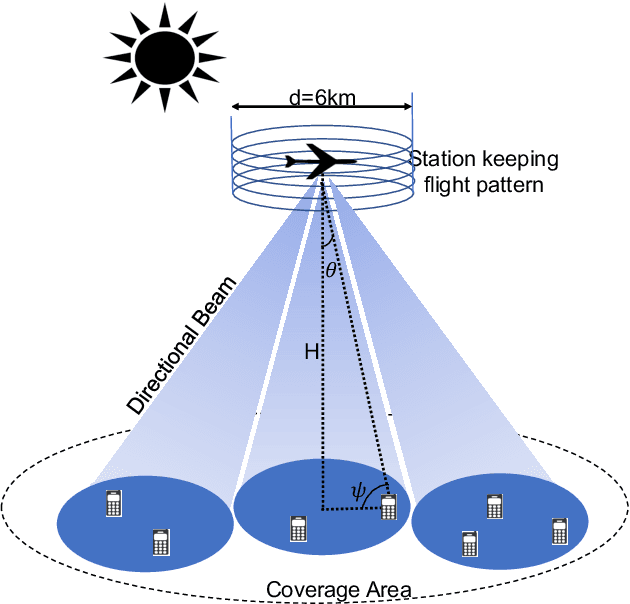
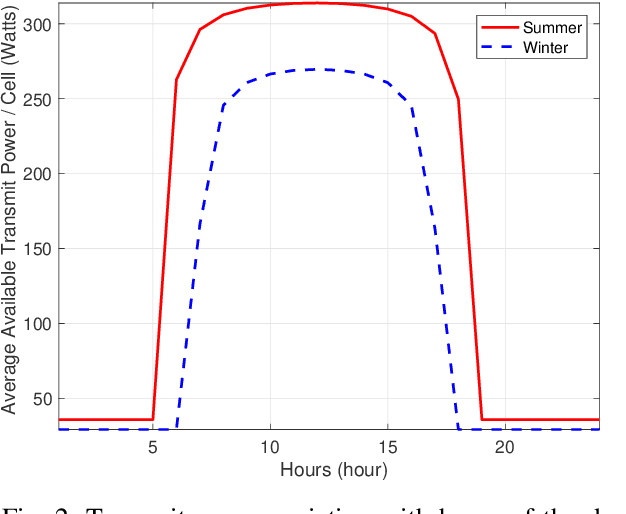
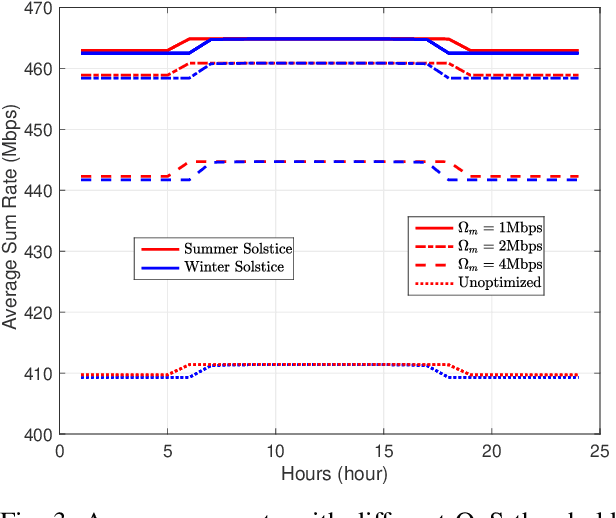
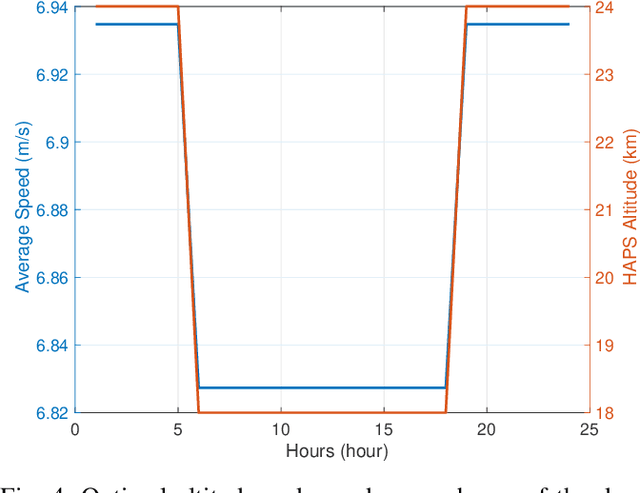
Aerial communication platforms especially stratospheric high altitude pseudo-satellite (HAPS) has the potential to provide/catalyze advanced mobile wireless communication services with its ubiquitous connectivity and ultra-wide coverage radius. Recently, HAPS has gained immense popularity - achieved primarily through self-sufficient energy systems - to render long endurance characteristics. The photo voltaic cells mounted on the aircraft harvest solar energy during the day, which is partially used for communication and station keeping, whereas, the excess is stored in the rechargeable batteries for the night time operation. We carried out an adroit power budgeting to ascertain if the available solar power can simultaneously and efficiently self-sustain the requisite propulsion and communication power expense. We propose an energy optimum trajectory for station-keeping flight and non-orthogonal multiple access (NOMA) for users in multicells served by the directional beams from HAPS communication system. We design optimal power allocation for downlink (DL) NOMA users along with the ideal position and speed of flight with the aim to maximize sum data rate during the day and minimize power expenditure during the night while ensuring quality of service. Our findings reveal the significance of joint design of communication and aerodynamics parameters for optimum energy utilization and resource allocation.
Continual Learning from Demonstration of Robotic Skills
Feb 15, 2022
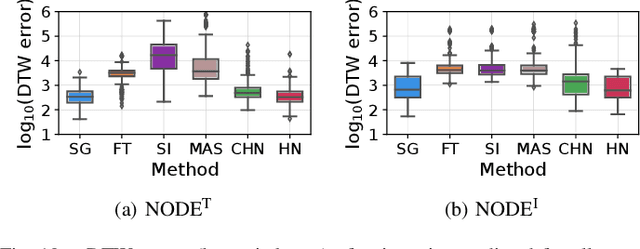

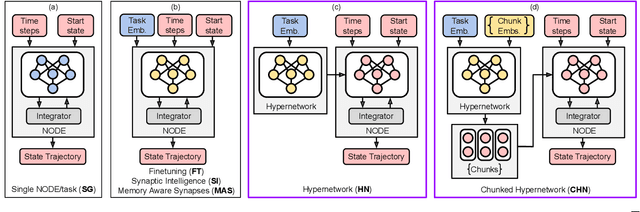
Methods for teaching motion skills to robots focus on training for a single skill at a time. Robots capable of learning from demonstration can considerably benefit from the added ability to learn new movements without forgetting past knowledge. To this end, we propose an approach for continual learning from demonstration using hypernetworks and neural ordinary differential equation solvers. We empirically demonstrate the effectiveness of our approach in remembering long sequences of trajectory learning tasks without the need to store any data from past demonstrations. Our results show that hypernetworks outperform other state-of-the-art regularization-based continual learning approaches for learning from demonstration. In our experiments, we use the popular LASA trajectory benchmark, and a new dataset of kinesthetic demonstrations that we introduce in this paper called the HelloWorld dataset. We evaluate our approach using both trajectory error metrics and continual learning metrics, and we propose two new continual learning metrics. Our code, along with the newly collected dataset, is available at https://github.com/sayantanauddy/clfd.
ViNTER: Image Narrative Generation with Emotion-Arc-Aware Transformer
Feb 15, 2022
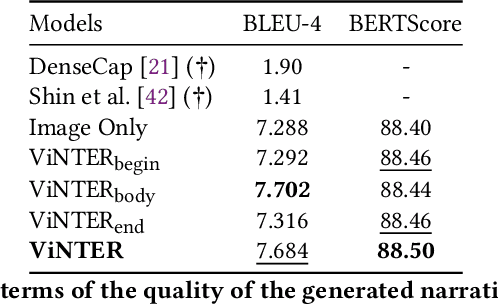
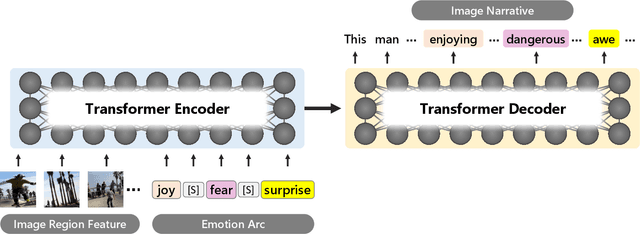
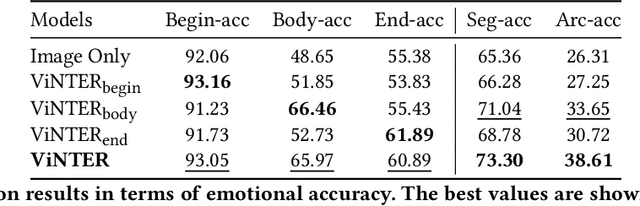
Image narrative generation describes the creation of stories regarding the content of image data from a subjective viewpoint. Given the importance of the subjective feelings of writers, characters, and readers in storytelling, image narrative generation methods must consider human emotion, which is their major difference from descriptive caption generation tasks. The development of automated methods to generate story-like text associated with images may be considered to be of considerable social significance, because stories serve essential functions both as entertainment and also for many practical purposes such as education and advertising. In this study, we propose a model called ViNTER (Visual Narrative Transformer with Emotion arc Representation) to generate image narratives that focus on time series representing varying emotions as "emotion arcs," to take advantage of recent advances in multimodal Transformer-based pre-trained models. We present experimental results of both manual and automatic evaluations, which demonstrate the effectiveness of the proposed emotion-aware approach to image narrative generation.
Effect of Active and Passive Protective Soft Skins on Collision Forces in Human-robot Collaboration
Mar 18, 2022
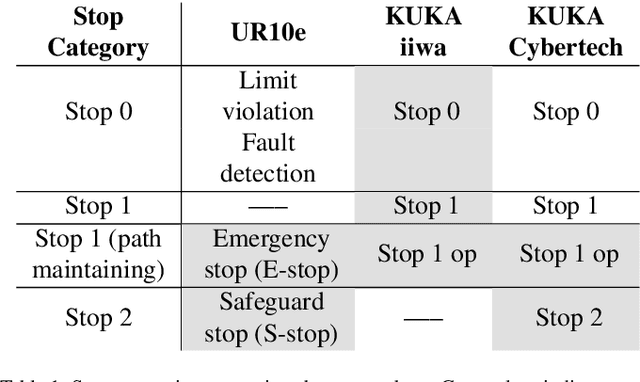
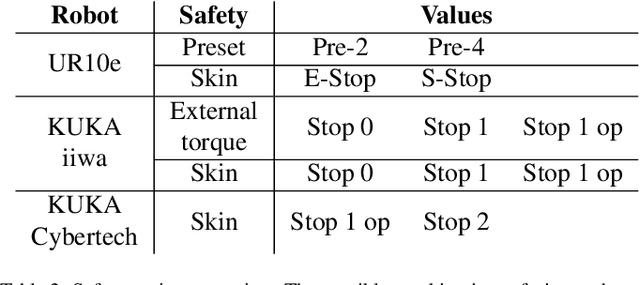
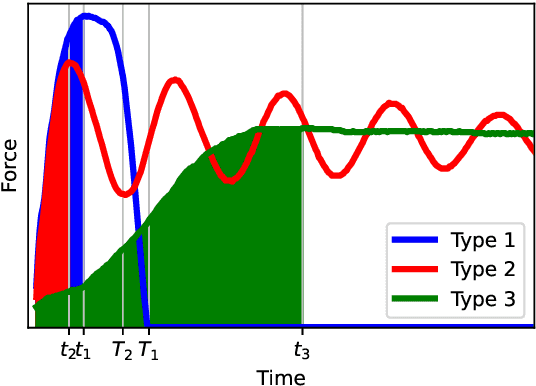
Soft electronic skins are one of the means to turn an industrial manipulator into a collaborative robot. For manipulators that are already fit for physical human-robot collaboration, soft skins can make them safer. In this work, we study the after impact behavior of two collaborative manipulators (UR10e and KUKA LBR iiwa) and one classical industrial manipulator (KUKA Cybertech), in the presence or absence of an industrial protective skin (AIRSKIN). In addition, we isolate the effects of the passive padding and the active contribution of the sensor to robot reaction. We present a total of 2250 collision measurements and study the impact force, contact duration, clamping force, and impulse. The dataset is publicly available. We summarize our results as follows. For transient collisions, the passive skin properties lowered the impact forces by about 40 %. During quasi-static contact, the effect of skin covers -- active or passive -- cannot be isolated from the collision detection and reaction by the collaborative robots. Important effects of the stop categories triggered by the active protective skin were found. We systematically compare the different settings and the empirically established safe velocities with prescriptions by the ISO/TS 15066. In some cases, up to the quadruple of the ISO/TS 15066 prescribed velocity can comply with the impact force limits and thus be considered safe. We propose an extension of the formulas relating impact force and permissible velocity that take into account the stiffness and compressible thickness of the protective cover, leading to better predictions of the collision forces. At the same time, this work emphasizes the need for in situ measurements as all the factors we studied -- presence of active/passive skin, safety stop settings, robot collision reaction, impact direction, and, of course, velocity -- have effects on the force evolution after impact.
TimeConvNets: A Deep Time Windowed Convolution Neural Network Design for Real-time Video Facial Expression Recognition
Mar 03, 2020
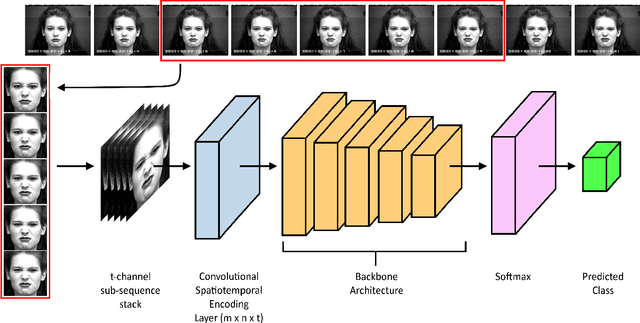
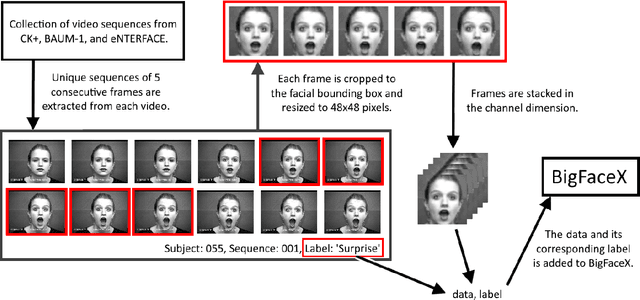
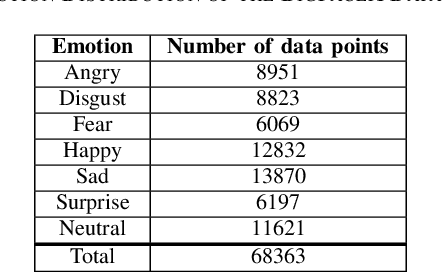
A core challenge faced by the majority of individuals with Autism Spectrum Disorder (ASD) is an impaired ability to infer other people's emotions based on their facial expressions. With significant recent advances in machine learning, one potential approach to leveraging technology to assist such individuals to better recognize facial expressions and reduce the risk of possible loneliness and depression due to social isolation is the design of computer vision-driven facial expression recognition systems. Motivated by this social need as well as the low latency requirement of such systems, this study explores a novel deep time windowed convolutional neural network design (TimeConvNets) for the purpose of real-time video facial expression recognition. More specifically, we explore an efficient convolutional deep neural network design for spatiotemporal encoding of time windowed video frame sub-sequences and study the respective balance between speed and accuracy. Furthermore, to evaluate the proposed TimeConvNet design, we introduce a more difficult dataset called BigFaceX, composed of a modified aggregation of the extended Cohn-Kanade (CK+), BAUM-1, and the eNTERFACE public datasets. Different variants of the proposed TimeConvNet design with different backbone network architectures were evaluated using BigFaceX alongside other network designs for capturing spatiotemporal information, and experimental results demonstrate that TimeConvNets can better capture the transient nuances of facial expressions and boost classification accuracy while maintaining a low inference time.
Imbedding Deep Neural Networks
Feb 15, 2022
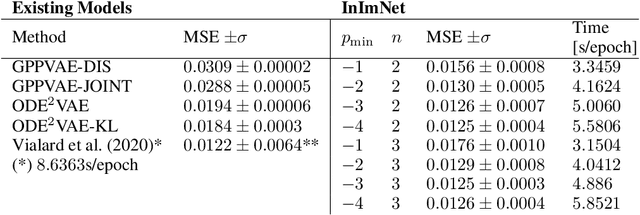
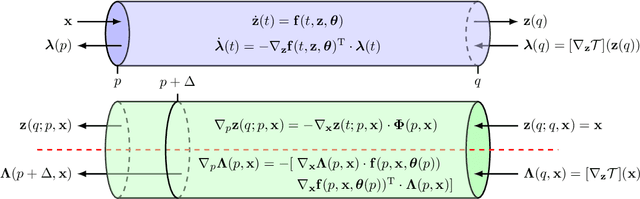
Continuous-depth neural networks, such as Neural ODEs, have refashioned the understanding of residual neural networks in terms of non-linear vector-valued optimal control problems. The common solution is to use the adjoint sensitivity method to replicate a forward-backward pass optimisation problem. We propose a new approach which explicates the network's `depth' as a fundamental variable, thus reducing the problem to a system of forward-facing initial value problems. This new method is based on the principle of `Invariant Imbedding' for which we prove a general solution, applicable to all non-linear, vector-valued optimal control problems with both running and terminal loss. Our new architectures provide a tangible tool for inspecting the theoretical--and to a great extent unexplained--properties of network depth. They also constitute a resource of discrete implementations of Neural ODEs comparable to classes of imbedded residual neural networks. Through a series of experiments, we show the competitive performance of the proposed architectures for supervised learning and time series prediction.
LAVARNET: Neural Network Modeling of Causal Variable Relationships for Multivariate Time Series Forecasting
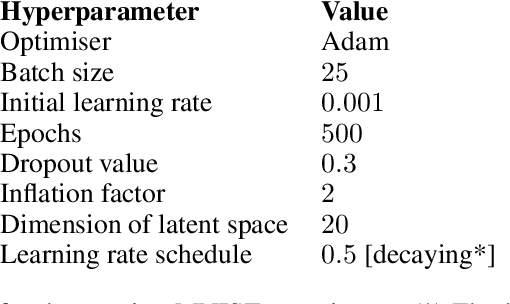
Sep 02, 2020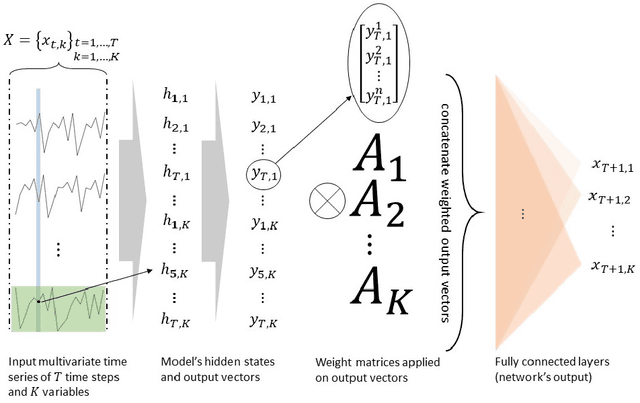
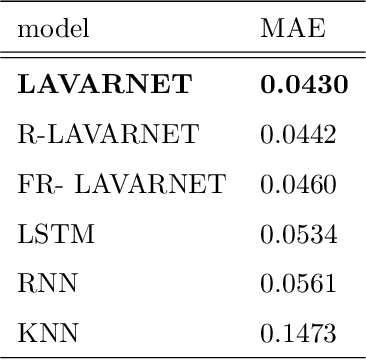
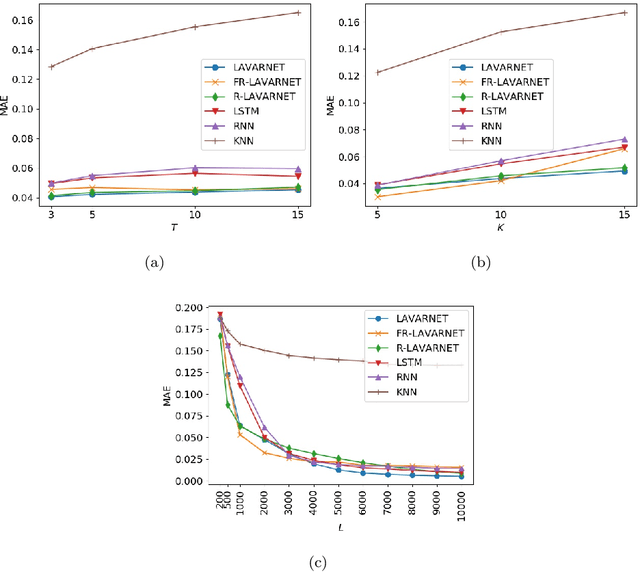
Multivariate time series forecasting is of great importance to many scientific disciplines and industrial sectors. The evolution of a multivariate time series depends on the dynamics of its variables and the connectivity network of causal interrelationships among them. Most of the existing time series models do not account for the causal effects among the system's variables and even if they do they rely just on determining the between-variables causality network. Knowing the structure of such a complex network and even more specifically knowing the exact lagged variables that contribute to the underlying process is crucial for the task of multivariate time series forecasting. The latter is a rather unexplored source of information to leverage. In this direction, here a novel neural network-based architecture is proposed, termed LAgged VAriable Representation NETwork (LAVARNET), which intrinsically estimates the importance of lagged variables and combines high dimensional latent representations of them to predict future values of time series. Our model is compared with other baseline and state of the art neural network architectures on one simulated data set and four real data sets from meteorology, music, solar activity, and finance areas. The proposed architecture outperforms the competitive architectures in most of the experiments.