 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Distributional Reduction via Optimal Transport and Dependence Maximization
May 26, 2026Learning representations that capture both intrinsic data geometry and target-relevant structure remains a fundamental challenge, particularly in settings where data reduction must balance compression with predictive fidelity. While distributional reduction-encompassing joint clustering and dimensionality reduction-offers a principled way to summarize data, its supervised variants remain relatively under-explored, despite the importance of retaining task-relevant signal for downstream prediction and decision-making. We propose Supervised Distributional Reduction (SDR), an algorithm for learning target-aware representations by combining optimal transport with explicit dependence maximization. SDR builds on the Fused Gromov-Wasserstein (FGW) objective to align the relational structure of the input distribution with a set of representative points, while augmenting it with a direct dependence term that encourages the learned embeddings to capture predictive signal more explicitly. This results in compact representations that reflect both geometric structure and supervision. Beyond representation learning, SDR naturally induces a data-dependent, non-stationary geometry that can be leveraged for settings such as Gaussian Process (GP) modelling. By redefining distances through target-aware distributional alignment, SDR enables the construction of adaptive kernels that respond to local variations in both data geometry and supervision, offering an optimal transport-based perspective on non-stationary kernel design.
Boosting Inference with Guided Reasoning: Stochastic Exploration for Recursive Models
May 26, 2026Recent work on recursive architectures has shown that tiny neural networks can be surprisingly powerful on structured reasoning tasks. The trick is to model reasoning trajectories with a latent dynamical system. We argue that the inference-time behaviour of these architectures is best understood as approximate inference over latent reasoning trajectories, with deterministic recursion as the one-particle, zero-noise limit. We make this view operational through guided stochastic exploration: stochastic perturbations of the reasoning dynamics propose neighbouring trajectories, and the model's existing early-stopping head reweights them online. The framework yields three label-free diagnostics: local stability, guide alignment, and cloud-token entropy. These predict, from inference traces alone, whether the procedure will help and which of its outputs to trust. On Sudoku-Extreme it lifts exact-solve accuracy from $85.9\%$ to $98.0\%$ without retraining; on Maze-Hard the diagnostics flag a misaligned guide, as validation performance later confirms. The same machinery thus characterises both when recursive reasoning has room to improve at the trajectory level and when the model's internal guide can recover it.
Imbedding Deep Neural Networks
Feb 15, 2022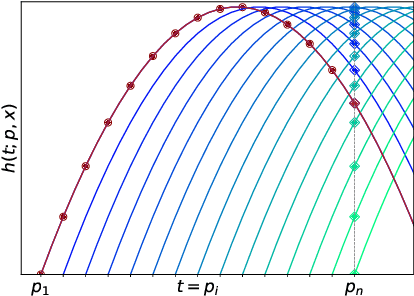
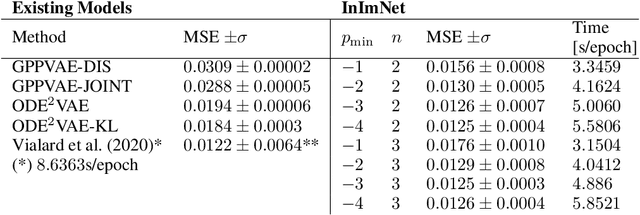
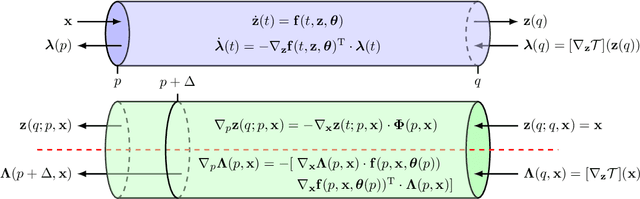
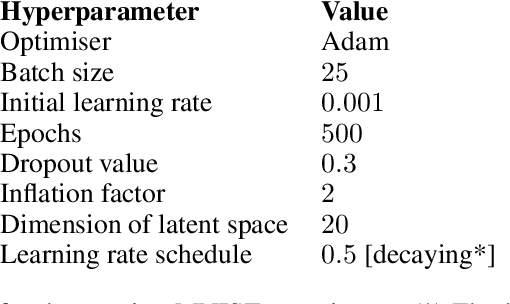
Continuous-depth neural networks, such as Neural ODEs, have refashioned the understanding of residual neural networks in terms of non-linear vector-valued optimal control problems. The common solution is to use the adjoint sensitivity method to replicate a forward-backward pass optimisation problem. We propose a new approach which explicates the network's `depth' as a fundamental variable, thus reducing the problem to a system of forward-facing initial value problems. This new method is based on the principle of `Invariant Imbedding' for which we prove a general solution, applicable to all non-linear, vector-valued optimal control problems with both running and terminal loss. Our new architectures provide a tangible tool for inspecting the theoretical--and to a great extent unexplained--properties of network depth. They also constitute a resource of discrete implementations of Neural ODEs comparable to classes of imbedded residual neural networks. Through a series of experiments, we show the competitive performance of the proposed architectures for supervised learning and time series prediction.