 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Benchmark Comparison of Learned Control Policies for Agile Quadrotor Flight
Feb 22, 2022
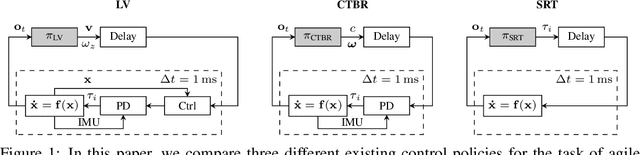
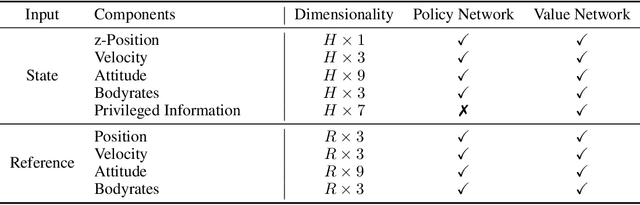
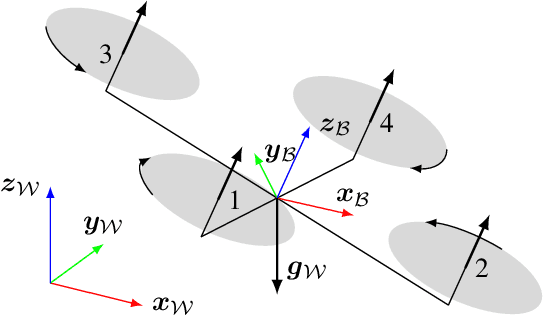

Quadrotors are highly nonlinear dynamical systems that require carefully tuned controllers to be pushed to their physical limits. Recently, learning-based control policies have been proposed for quadrotors, as they would potentially allow learning direct mappings from high-dimensional raw sensory observations to actions. Due to sample inefficiency, training such learned controllers on the real platform is impractical or even impossible. Training in simulation is attractive but requires to transfer policies between domains, which demands trained policies to be robust to such domain gap. In this work, we make two contributions: (i) we perform the first benchmark comparison of existing learned control policies for agile quadrotor flight and show that training a control policy that commands body-rates and thrust results in more robust sim-to-real transfer compared to a policy that directly specifies individual rotor thrusts, (ii) we demonstrate for the first time that such a control policy trained via deep reinforcement learning can control a quadrotor in real-world experiments at speeds over 45km/h.
* 6 pages (+1 references)
$\text{ISS}_2$: An Extension of Iterative Source Steering Algorithm for Majorization-Minimization-Based Independent Vector Analysis
Feb 02, 2022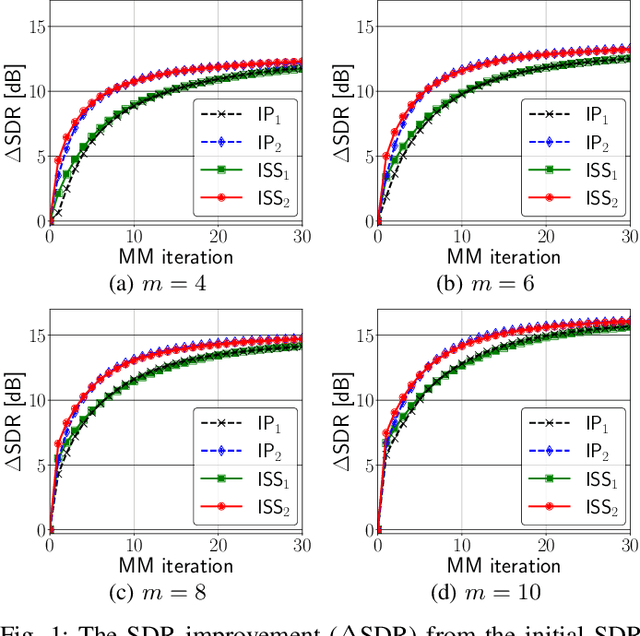
A majorization-minimization (MM) algorithm for independent vector analysis optimizes a separation matrix $W = [w_1, \ldots, w_m]^h \in \mathbb{C}^{m \times m}$ by minimizing a surrogate function of the form $\mathcal{L}(W) = \sum_{i = 1}^m w_i^h V_i w_i - \log | \det W |^2$, where $m \in \mathbb{N}$ is the number of sensors and positive definite matrices $V_1,\ldots,V_m \in \mathbb{C}^{m \times m}$ are constructed in each MM iteration. For $m \geq 3$, no algorithm has been found to obtain a global minimum of $\mathcal{L}(W)$. Instead, block coordinate descent (BCD) methods with closed-form update formulas have been developed for minimizing $\mathcal{L}(W)$ and shown to be effective. One such BCD is called iterative projection (IP) that updates one or two rows of $W$ in each iteration. Another BCD is called iterative source steering (ISS) that updates one column of the mixing matrix $A = W^{-1}$ in each iteration. Although the time complexity per iteration of ISS is $m$ times smaller than that of IP, the conventional ISS converges slower than the current fastest IP (called $\text{IP}_2$) that updates two rows of $W$ in each iteration. We here extend this ISS to $\text{ISS}_2$ that can update two columns of $A$ in each iteration while maintaining its small time complexity. To this end, we provide a unified way for developing new ISS type methods from which $\text{ISS}_2$ as well as the conventional ISS can be immediately obtained in a systematic manner. Numerical experiments to separate reverberant speech mixtures show that our $\text{ISS}_2$ converges in fewer MM iterations than the conventional ISS, and is comparable to $\text{IP}_2$.
Last-Iterate Convergence of Saddle Point Optimizers via High-Resolution Differential Equations
Dec 27, 2021
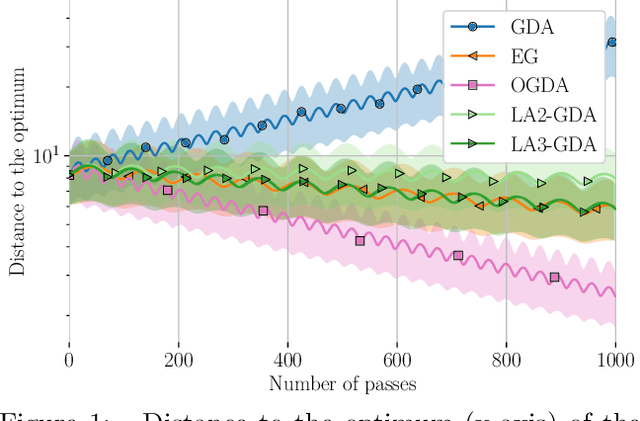

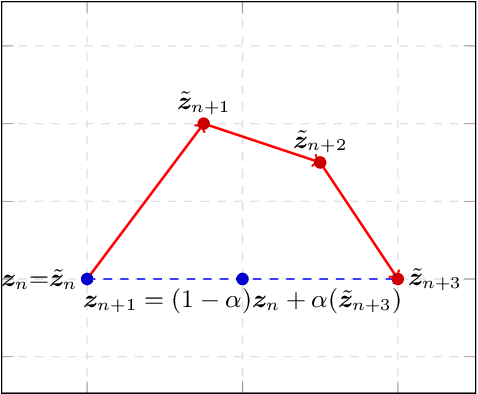
Several widely-used first-order saddle point optimization methods yield an identical continuous-time ordinary differential equation (ODE) to that of the Gradient Descent Ascent (GDA) method when derived naively. However, their convergence properties are very different even on simple bilinear games. We use a technique from fluid dynamics called High-Resolution Differential Equations (HRDEs) to design ODEs of several saddle point optimization methods. On bilinear games, the convergence properties of the derived HRDEs correspond to that of the starting discrete methods. Using these techniques, we show that the HRDE of Optimistic Gradient Descent Ascent (OGDA) has last-iterate convergence for general monotone variational inequalities. To our knowledge, this is the first continuous-time dynamics shown to converge for such a general setting. Moreover, we provide the rates for the best-iterate convergence of the OGDA method, relying solely on the first-order smoothness of the monotone operator.
An analysis of deep neural networks for predicting trends in time series data
Sep 16, 2020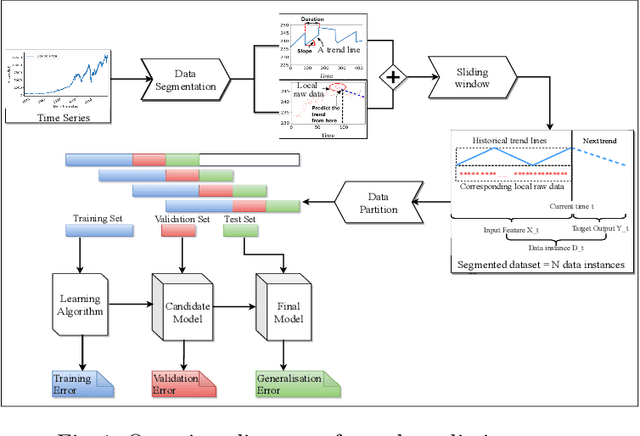

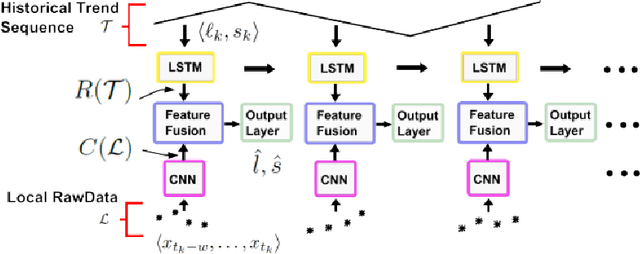
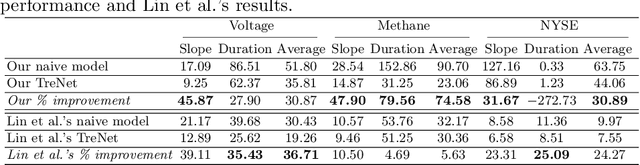
The emergence of small and portable smart sensors have opened up new opportunities for many applications, including automated factories, smart cities and connected healthcare, broadly referred to as the "Internet of Things (IoT)". These devices produce time series data. While deep neural networks (DNNs) has been widely applied to computer vision, natural language processing and speech recognition, there is limited research on DNNs for time series prediction. Machine learning (ML) applications for time series prediction has traditionally involved predicting the next value in the series. However, in certain applications, segmenting the time series into a sequence of trends and predicting the next trend is preferred. Recently, a hybrid DNN algorithm, TreNet was proposed for trend prediction. TreNet, which combines an LSTM that takes in trendlines and a CNN that takes in point data was shown to have superior performance for trend prediction when compared to other approaches. However, the study used a standard cross-validation method which does not take into account the sequential nature of time series. In this work, we reproduce TreNet using a walk-forward validation method, which is more appropriate to time series data. We compare the performance of the hybrid TreNet algorithm, on the same three data sets used in the original study, to vanilla MLP, LSTM, and CNN that take in point data, and also to traditional ML algorithms, i.e. the Random Forest (RF), Support Vector Regression and Gradient Boosting Machine. Our results differ significantly from those reported for the original TreNet. In general TreNet still performs better than the vanilla DNN models, but not substantially so as reported for the original TreNet. Furthermore, our results show that the RF algorithm performed substantially better than TreNet on the methane data set.
A hybrid 2-stage vision transformer for AI-assisted 5 class pathologic diagnosis of gastric endoscopic biopsies
Feb 17, 2022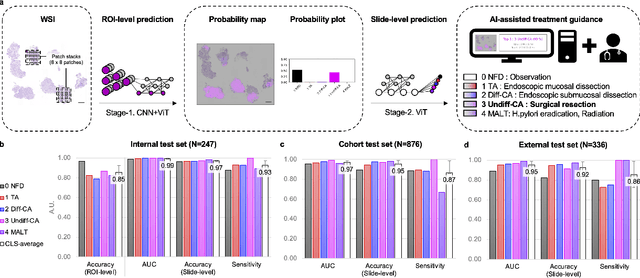
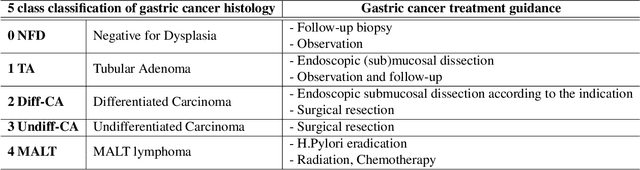
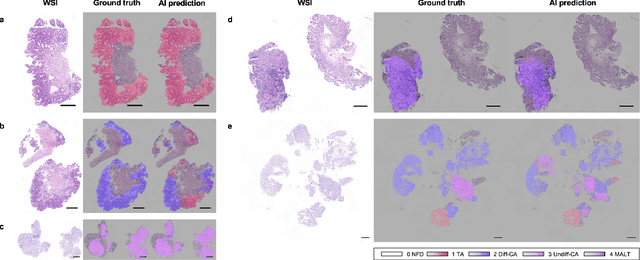
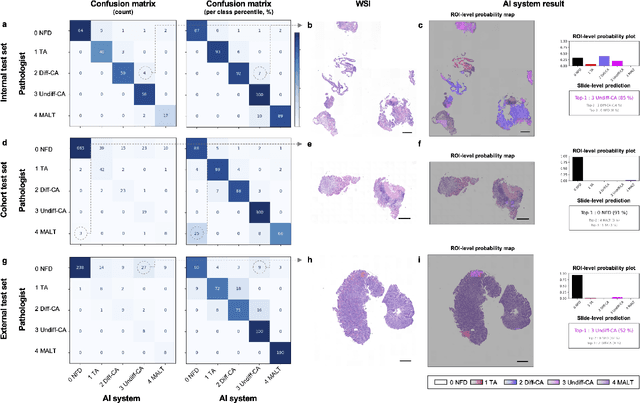
Gastric endoscopic screening is an effective way to decide appropriate gastric cancer (GC) treatment at an early stage, reducing GC-associated mortality rate. Although artificial intelligence (AI) has brought a great promise to assist pathologist to screen digitalized whole slide images, automatic classification systems for guiding proper GC treatment based on clinical guideline are still lacking. Here, we propose an AI system classifying 5 classes of GC histology, which can be perfectly matched to general treatment guidance. The AI system, mimicking the way pathologist understand slides through multi-scale self-attention mechanism using a 2-stage Vision Transformer, demonstrates clinical capability by achieving diagnostic sensitivity of above 85% for both internal and external cohort analysis. Furthermore, AI-assisted pathologists showed significantly improved diagnostic sensitivity by 10% within 18% saved screening time compared to human pathologists. Our AI system has a great potential for providing presumptive pathologic opinion for deciding proper treatment for early GC patients.
Disentangling modes with crossover instantaneous frequencies by synchrosqueezed chirplet transforms, from theory to application
Dec 03, 2021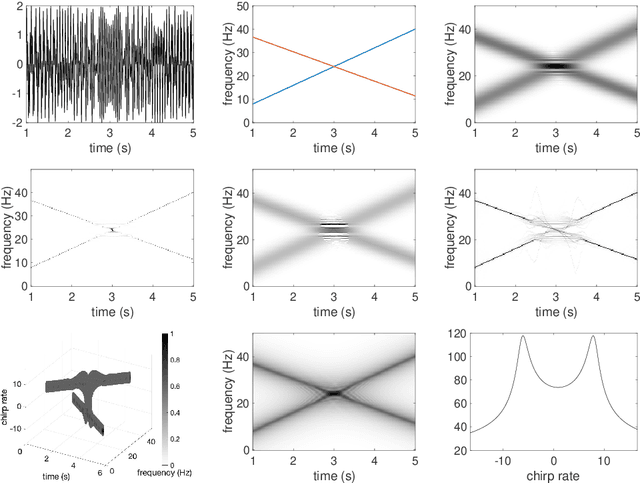
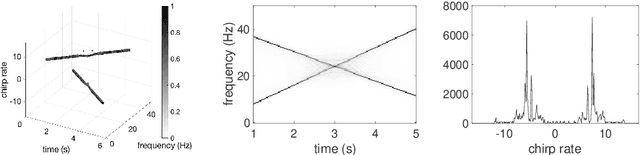
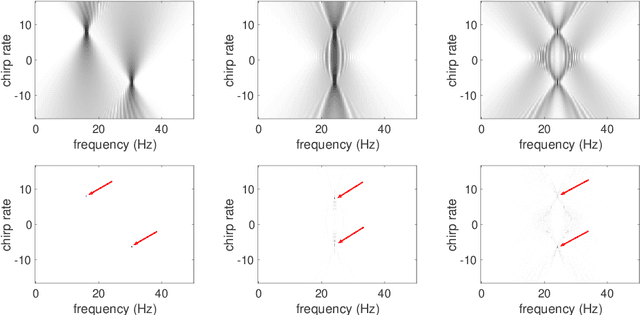
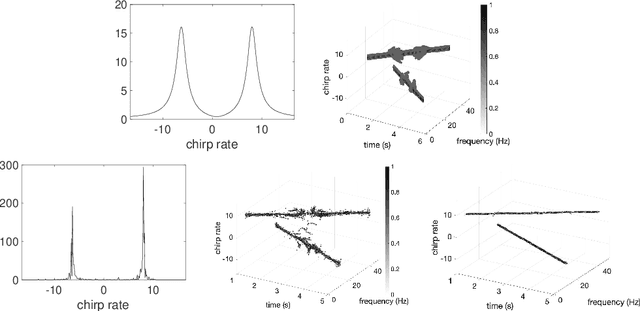
Analysis of signals with oscillatory modes with crossover instantaneous frequencies is a challenging problem in time series analysis. One way to handle this problem is lifting the 2-dimensional time-frequency representation to a 3-dimensional representation, called time-frequency-chirp rate (TFC) representation, by adding one extra chirp rate parameter so that crossover frequencies are disentangles in higher dimension. The chirplet transform is an algorithm for this lifting idea. However, in practice we found that it has a stronger "blurring" effect in the chirp rate axis, which limits its application in real world data. Moreover, to our knowledge, we have limited mathematical understanding of the chirplet transform in the literature. Motivated by real world data challenges, in this paper, we propose the synchrosqueezed chirplet transform (SCT) that gives a concentrated TFC representation that the contrast is enhanced so that one can distinguish different modes even with crossover instantaneous frequencies. We also analyze chirplet transform and provide theoretical guarantee of SCT.
Deep Learning based Virtual Point Tracking for Real-Time Target-less Dynamic Displacement Measurement in Railway Applications
Jan 20, 2021
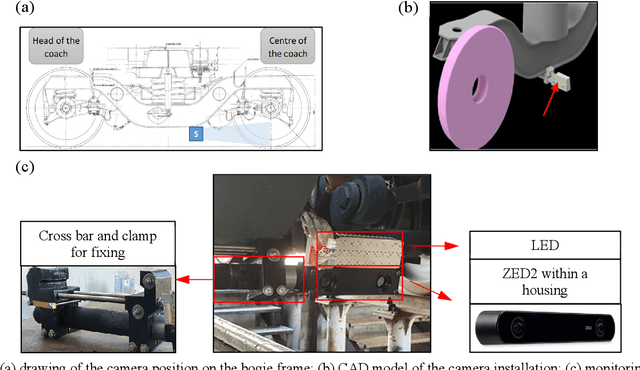
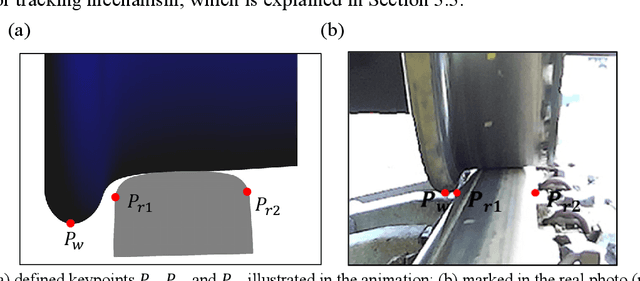
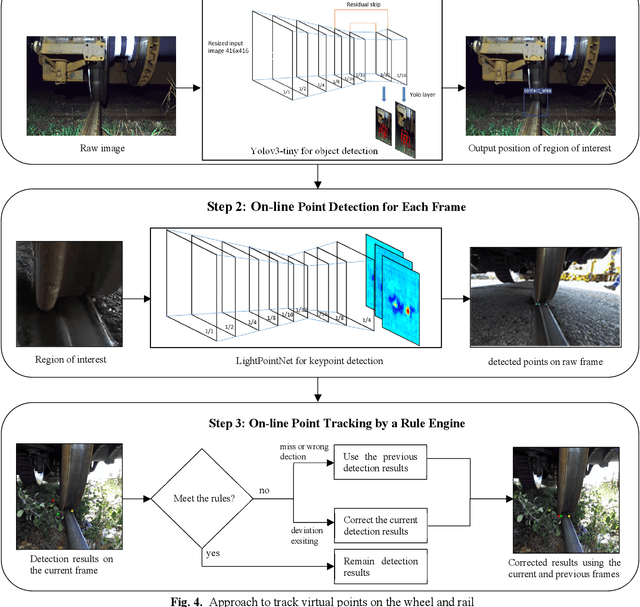
In the application of computer-vision based displacement measurement, an optical target is usually required to prove the reference. In the case that the optical target cannot be attached to the measuring objective, edge detection, feature matching and template matching are the most common approaches in target-less photogrammetry. However, their performance significantly relies on parameter settings. This becomes problematic in dynamic scenes where complicated background texture exists and varies over time. To tackle this issue, we propose virtual point tracking for real-time target-less dynamic displacement measurement, incorporating deep learning techniques and domain knowledge. Our approach consists of three steps: 1) automatic calibration for detection of region of interest; 2) virtual point detection for each video frame using deep convolutional neural network; 3) domain-knowledge based rule engine for point tracking in adjacent frames. The proposed approach can be executed on an edge computer in a real-time manner (i.e. over 30 frames per second). We demonstrate our approach for a railway application, where the lateral displacement of the wheel on the rail is measured during operation. We also implement an algorithm using template matching and line detection as the baseline for comparison. The numerical experiments have been performed to evaluate the performance and the latency of our approach in the harsh railway environment with noisy and varying backgrounds.
Speaker Representation Learning using Global Context Guided Channel and Time-Frequency Transformations
Sep 09, 2020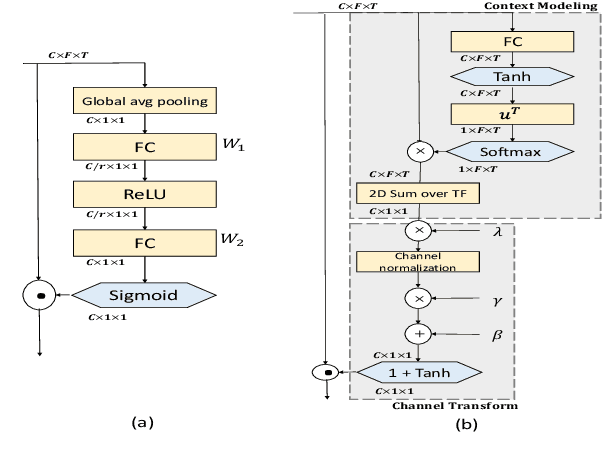
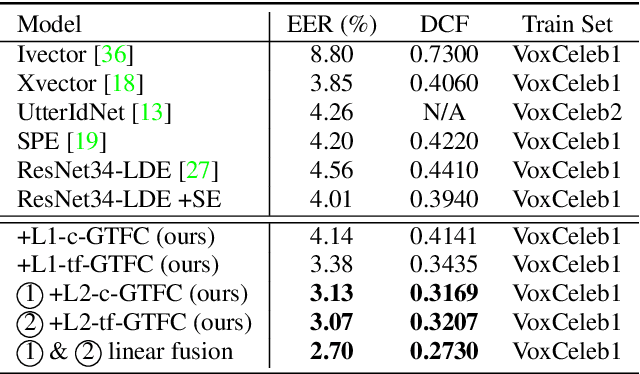
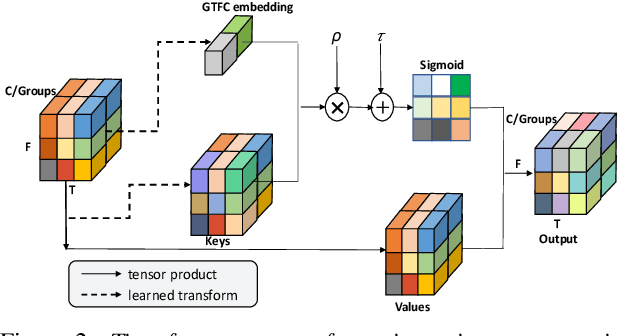
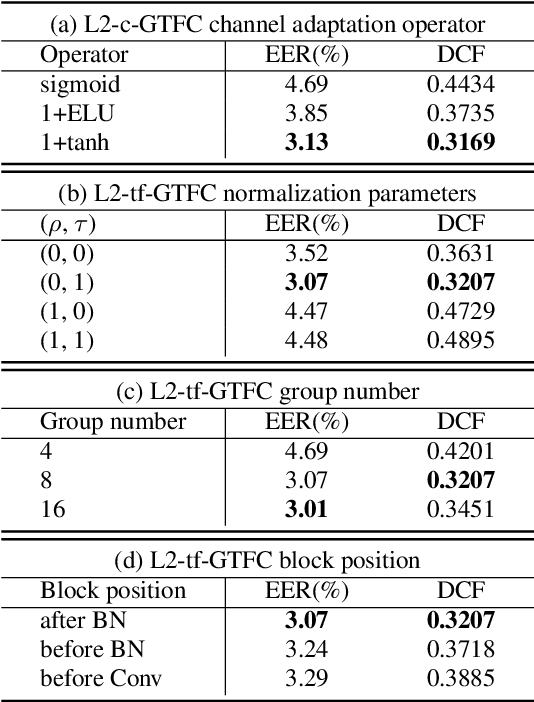
In this study, we propose the global context guided channel and time-frequency transformations to model the long-range, non-local time-frequency dependencies and channel variances in speaker representations. We use the global context information to enhance important channels and recalibrate salient time-frequency locations by computing the similarity between the global context and local features. The proposed modules, together with a popular ResNet based model, are evaluated on the VoxCeleb1 dataset, which is a large scale speaker verification corpus collected in the wild. This lightweight block can be easily incorporated into a CNN model with little additional computational costs and effectively improves the speaker verification performance compared to the baseline ResNet-LDE model and the Squeeze&Excitation block by a large margin. Detailed ablation studies are also performed to analyze various factors that may impact the performance of the proposed modules. We find that by employing the proposed L2-tf-GTFC transformation block, the Equal Error Rate decreases from 4.56% to 3.07%, a relative 32.68% reduction, and a relative 27.28% improvement in terms of the DCF score. The results indicate that our proposed global context guided transformation modules can efficiently improve the learned speaker representations by achieving time-frequency and channel-wise feature recalibration.
Meta-learning with GANs for anomaly detection, with deployment in high-speed rail inspection system
Feb 11, 2022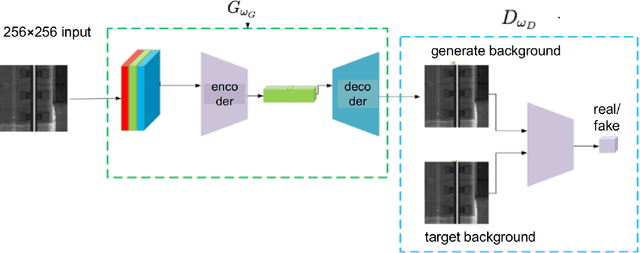
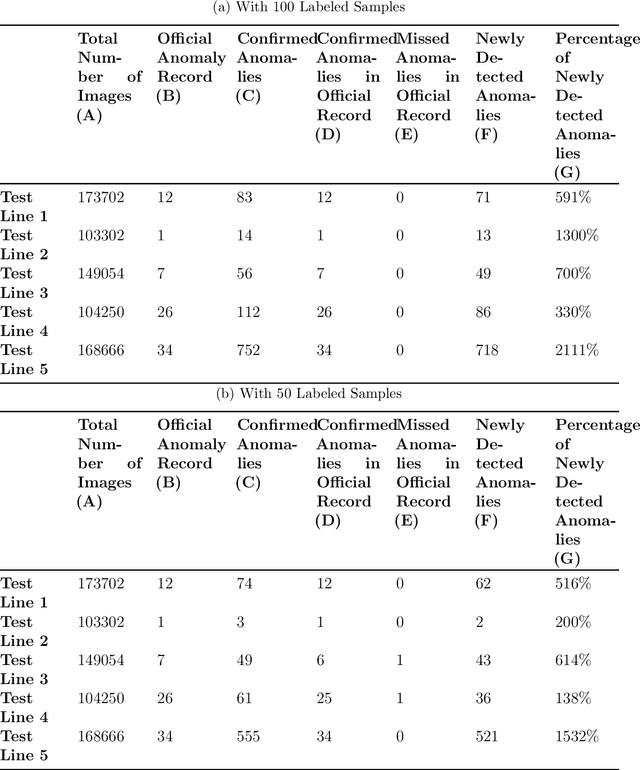
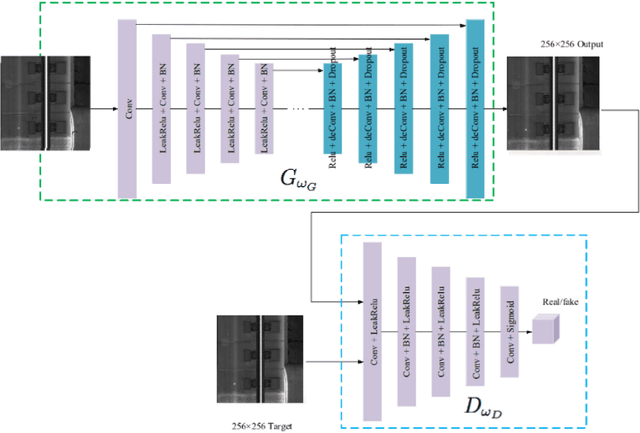
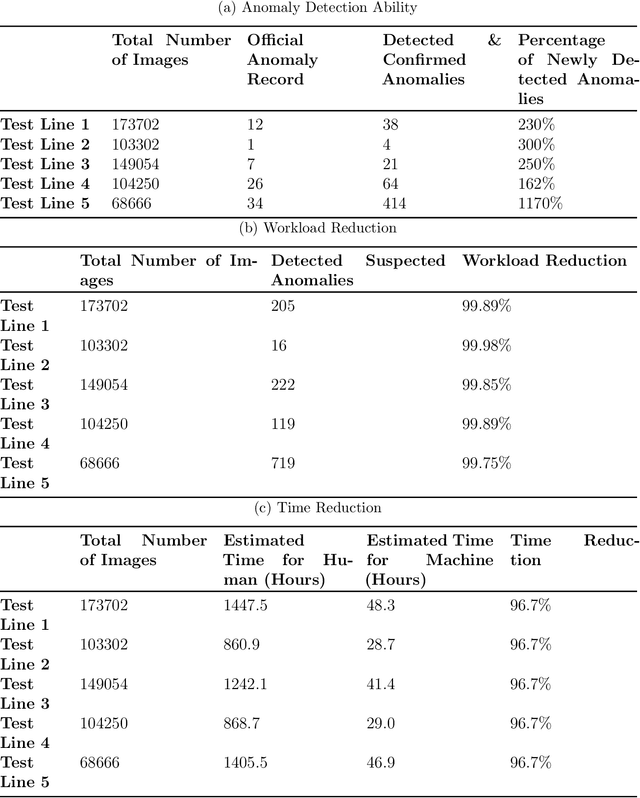
Anomaly detection has been an active research area with a wide range of potential applications. Key challenges for anomaly detection in the AI era with big data include lack of prior knowledge of potential anomaly types, highly complex and noisy background in input data, scarce abnormal samples, and imbalanced training dataset. In this work, we propose a meta-learning framework for anomaly detection to deal with these issues. Within this framework, we incorporate the idea of generative adversarial networks (GANs) with appropriate choices of loss functions including structural similarity index measure (SSIM). Experiments with limited labeled data for high-speed rail inspection demonstrate that our meta-learning framework is sharp and robust in identifying anomalies. Our framework has been deployed in five high-speed railways of China since 2021: it has reduced more than 99.7% workload and saved 96.7% inspection time.
Emotion-Inspired Deep Structure (EiDS) for EEG Time Series Forecasting
May 23, 2020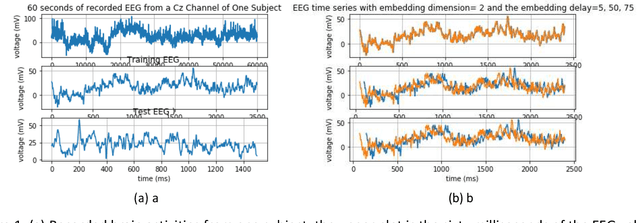
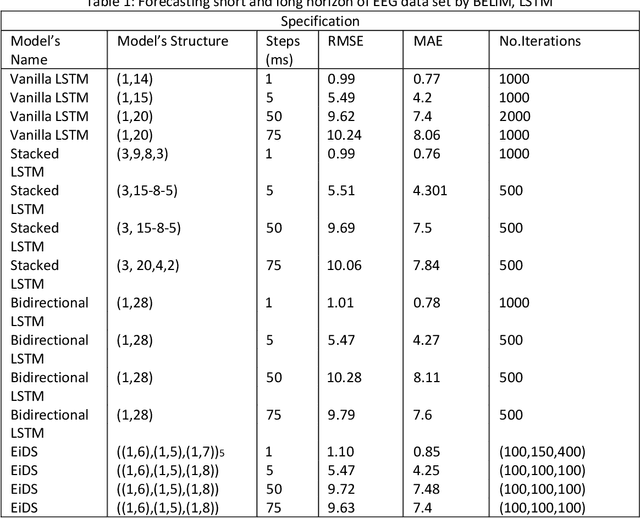

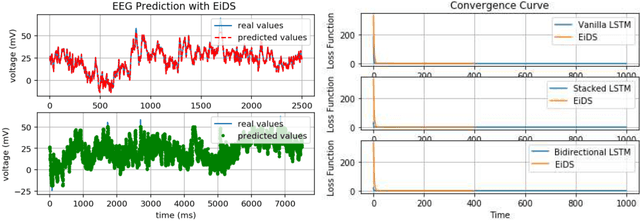
Accurate forecasting of an electroencephalogram (EEG) time series is crucial for the correct diagnosis of neurological disorders such as seizures and epilepsy. Since the EEG time series is chaotic, most traditional machine learning algorithms have failed to forecast its next steps accurately. Thus, we suggest a model, which has formed by taking inspiration from the neural structures that underlie feelings (emotional states), to forecast EEG time series. The model, which is referred to as emotion-inspired deep structure (EiDS), can be used to predict both short- and long-term of EEG time series. This paper also compares the performance of EiDS with other variations of long short-term memory (LSTM) networks.